
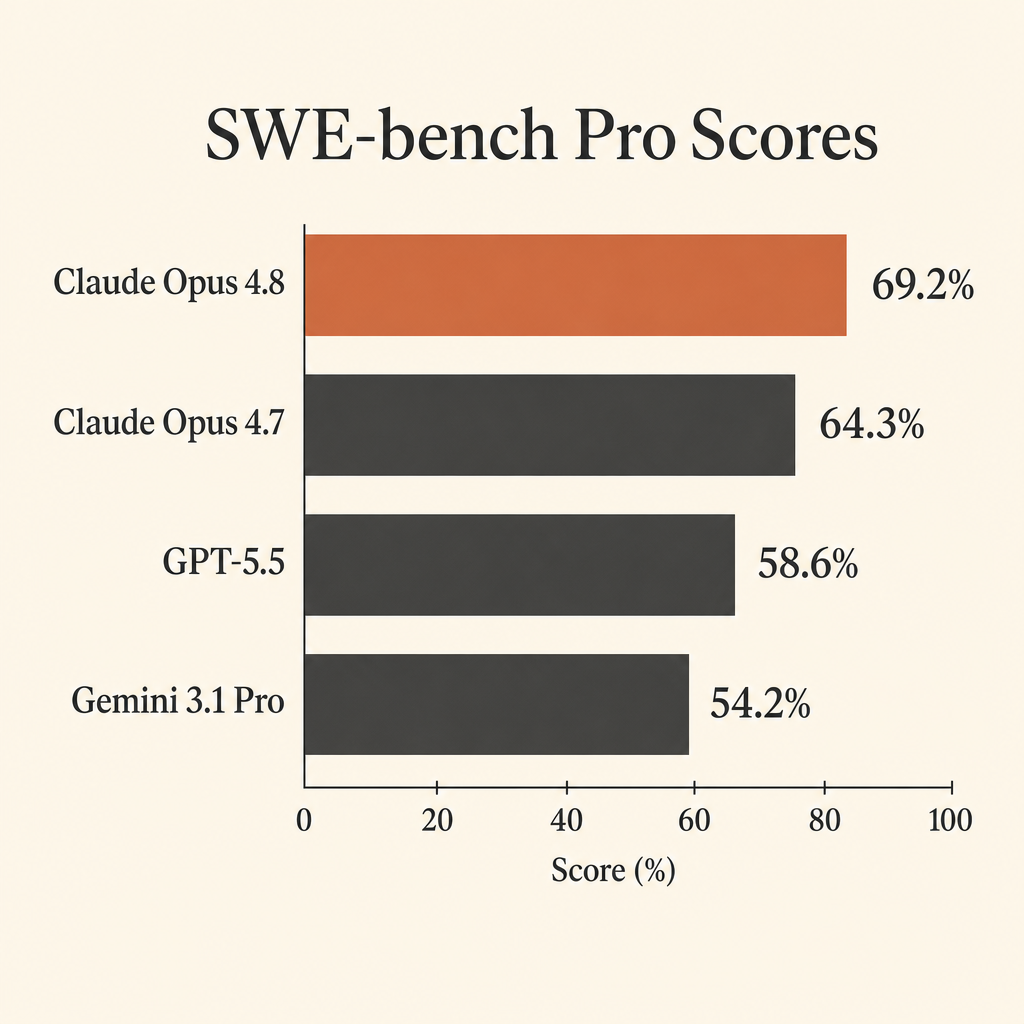
Claude Opus 4.8 最有用的程式能力數字,不是它幾乎飽和的 SWE-bench Verified 分數,而是在 SWE-bench Pro 上的 69.2%。
這很重要,因為 SWE-bench Pro 測的正是開發者真正希望自主代理能做的工作:打開一個真實 repository、理解 issue、編輯多個檔案、跑測試、從錯誤假設中修正方向,最後交出 patch。在 Anthropic 的 Claude Opus 4.8 system card 裡,Opus 4.8 在 SWE-bench Pro 拿到 69.2%,領先 GPT-5.5 的 58.6% 與 Gemini 3.1 Pro 的 54.2%(Anthropic system card PDF)。
這個差距大到足以改變 agentic coding 的模型選擇。如果你付錢讓模型消耗 repo context、tool calls、測試失敗和漫長修補迴圈,十分的 benchmark 差距不是冷知識。那是「需要一直盯著」和「值得交付真任務」之間的差別。
評測對比(Benchmark)
這是本週每份 coding-agent 評估文件都該放上的精簡比較。
| Model | SWE-bench Pro | SWE-bench Verified | Terminal-Bench 2.1 | API 價格,輸入/輸出 |
|---|---|---|---|---|
| Claude Opus 4.8 | 69.2% | 88.6% | 74.6% | 每 1M tokens $5 / $25 |
| Claude Opus 4.7 | 64.3% | 87.6% | 66.1% | 此處未比較 |
| GPT-5.5 | 58.6% | 未列出 | 78.2% | 每 1M tokens $5 / $30 |
| Gemini 3.1 Pro Preview | 54.2% | 80.6% | 70.3% | <=200k prompt 為 $2 / $12,>200k prompt 為 $4 / $18 |
上面的 benchmark 分數來自 Anthropic 的 Opus 4.8 system card 表格(Anthropic system card PDF)。Anthropic 的產品頁面表示 Opus 4.8 於 2026 年 5 月 28 日推出,為「嚴肅 coding 和 AI agents」打造,支援 1M context window,價格從每百萬 input tokens $5、每百萬 output tokens $25 起(Anthropic)。OpenAI 列出的 GPT-5.5 價格為每百萬 tokens input $5、output $30,context window 為 1,050,000 tokens,snapshot 為 gpt-5.5-2026-04-23(OpenAI)。Google 列出的 Gemini 3.1 Pro Preview 定價為:prompt 最多 200k tokens 時,每百萬 tokens $2/$12;高於 200k 時為 $4/$18(Google AI)。
Opus 贏下 repo 修補 benchmark。GPT-5.5 在這張表裡贏下 Terminal-Bench 2.1。Gemini 每 token 較便宜,尤其在低於 200k prompt 門檻時,但在 SWE-bench Pro 落後。
決策輪廓就是這樣。
SWE-bench Pro 實際測的是什麼
SWE-bench Pro 不是另一個「照 prompt 寫一個函式」的測試。論文把它描述為一個涵蓋 41 個活躍維護 repository、共 1,865 個問題的 benchmark,包含商業應用、B2B 服務與開發者工具(arXiv)。它把任務分成公開集、保留集,以及由私人新創 repository 建立的商業集。
重點在任務形態。SWE-bench Pro 的問題是長週期軟體工程任務。作者表示,這些任務可能要專業工程師花上數小時或數天,通常需要跨多個檔案 patch,並包含實質的程式碼變更(arXiv)。這個 benchmark 也會濾掉瑣碎編輯。論文指出,參考解法平均為 107.4 行、橫跨 4.1 個檔案。
這更接近開發者會交給 agents 的工作:
git grep "billing status"
npm test -- --runInBand
git diff
pytest tests/billing/test_invoices.py難的不是產出語法正確的程式碼。難的是判斷 bug 屬於哪一層、讀夠周邊程式碼、修改時不破壞相鄰行為,並利用測試輸出修正路線。
SWE-bench Verified 仍然有價值,但頂端已經太擁擠。Anthropic 的表格顯示,Opus 4.8 在 SWE-bench Verified 為 88.6%,Opus 4.7 為 87.6%。一分差距不足以用來為昂貴的自主 repo 工作選模型。但在 SWE-bench Pro 上,Opus 4.8 對 Opus 4.7 的差距是 4.9 分。對 GPT-5.5 是 10.6 分。對 Gemini 3.1 Pro 是 15.0 分。
這才是訊號。
每一美元的效能比標價更複雜
Token 價格仍然重要。Agents 很吃資源。一次真實 repo 執行可能包含很長的初始 context、反覆讀檔、測試 log、失敗 patch、摘要,以及依供應商計費方式而定的隱藏 reasoning 或 thinking tokens。
粗略做個同類比較,假設一次長 context coding 執行使用 800k input tokens 和 200k output tokens。這不是通用工作負載;只是用來乾淨比較大型 repo 任務公開 API 價格的一種方式。
| Model | 價格假設 | 800k input / 200k output 成本 | SWE-bench Pro | 每 $ 得分 |
|---|---|---|---|---|
| Claude Opus 4.8 | $5 input / $25 output | $9.00 | 69.2 | 7.69 |
| GPT-5.5 | $5 input / $30 output | $10.00 | 58.6 | 5.86 |
| Gemini 3.1 Pro Preview | >200k prompt:$4 input / $18 output | $6.80 | 54.2 | 7.97 |
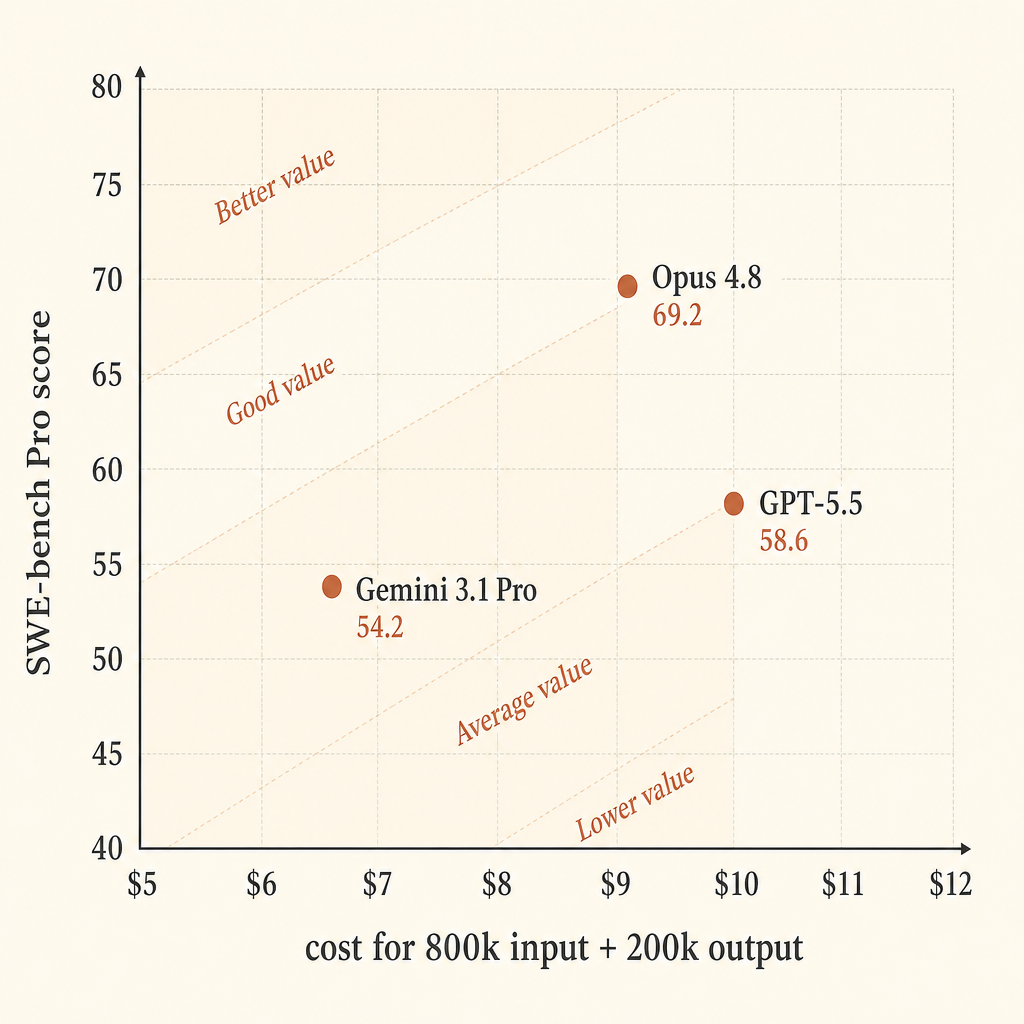
在這個簡化計算裡,Gemini 的原始價格效率看起來很強。如果你最在意通過率,Opus 看起來最強。GPT-5.5 在這個切片中是昂貴的中間選項:output 價格高於 Opus,SWE-bench Pro 分數較低,但在 Anthropic 表格裡 Terminal-Bench 2.1 分數最高。
對自主 coding 來說,我不會只優化「每美元 benchmark 分數」。一次失敗的 agent 執行不只是 token 帳單。還有 review 時間、context switching、爛 patch、不穩的後續 prompt,以及重跑整個迴圈的成本。如果 Opus 4.8 較高的通過率能在你的 codebase 裡轉化成更少重啟,那麼假設執行中它相對 Gemini 多出的 $2.20 很快就會消失。
公平的做法是跑你自己的 repo harness:
agent-eval run \
--model claude-opus-4-8 \
--tasks evals/repo_tasks.jsonl \
--max-cost-usd 50 \
--record patches,tests,tokens追蹤被接受的 patches、人工 review 分鐘數、總成本和 rollback 率。Benchmark 分數應該決定你的 shortlist。你的 repo 應該決定 production。
為什麼 Opus 4.8 贏下這個特定訊號
Opus 4.8 的故事不是泛泛而談的「Claude 比較會寫 code」。那太寬,而且通常至少會被某個 benchmark 打臉。更精準的說法是:在 Anthropic 回報的 SWE-bench Pro 設定中,Opus 4.8 在自主 repository issue 解決上領先。
這對應到三個實務強項。
第一,它在簡單天花板之上還有空間。SWE-bench Verified 有用,但當模型已經進入高 80 分區間,小幅差距對採購決策來說會變得很吵。SWE-bench Pro 重新拉開了差距。
第二,它強調 repo 規模的行為。SWE-bench Pro 論文點出抗污染、商業/私有 codebase、多檔案變更、人工驗證和企業型任務(arXiv)。這更接近「修掉我們 billing service 裡的這個 regression」,而不是「完成這個 Python 函式」。
第三,Anthropic 把 Opus 4.8 定位在長時間 coding 和 agents,而不只是聊天。它的 Opus 頁面表示模型可在 Claude Code 和 API 使用,支援 1M context,並針對複雜 coding、agentic workflows 和專業工作設計(Anthropic)。行銷文案不是證據,但 benchmark 表格和產品方向一致。
我會如何為 Repo Agents 選模型
如果你的 agent 做的是淺層編輯、程式碼片段或 IDE 自動補全,SWE-bench Pro 不該是唯一視角。Latency、streaming 品質、本機工具整合和價格會更重要。
如果你的 agent 被期待端到端承擔 repo 任務,可以從這個排序開始:
- 用 Claude Opus 4.8 作為困難自主 repo 工作的品質基準。
- 當終端機重度任務執行很重要時,測 GPT-5.5,因為 Anthropic 的表格給了它 Terminal-Bench 2.1 領先。
- 當成本壓力高,而且你的任務保持在失敗成本門檻以下時,測 Gemini 3.1 Pro Preview。
- 在迴圈裡保留一個較便宜的模型,用於 triage、檔案搜尋摘要和低風險編輯。
最可靠的 production 模式不是所有事情都交給一個巨大模型。用快速便宜的模型分類 issues 並收集 context。把困難 patch 升級給 Opus 4.8。跑測試。用第二個模型,有時是 GPT-5.5 或 Gemini,作為最終 diff 的 reviewer。只有在 test suite 和人工 reviewer 都同意時才 ship。
這聽起來不像「自主工程師」那麼魔幻。很好。這也是團隊避免一覺醒來看到漂亮 patch 卻發現 auth 壞掉的方法。
結論
Claude Opus 4.8 的 69.2% SWE-bench Pro 分數,比另一個高 SWE-bench Verified 數字更能反映開發者需要的訊號。它更接近 agents 應該做的工作:repo navigation、多檔案變更、測試驅動修補,以及長週期執行。
Opus 4.8 不是比較中最便宜的模型。它也不是在 Anthropic 自家表格裡贏下每個 benchmark。但對自主 repo 工作來說,SWE-bench Pro 的差距已經大到足以讓它成為我會優先評估的第一個模型。
用公開數字建立 shortlist。然後跑你自己的任務,衡量每美元可接受 patches,並把人工 review 時間算進成本。Benchmark 勝利要嘛變成工程槓桿,要嘛就會消失。
想親自試 Claude Fable 5 的讀者可以透過 OneHop 使用:一個 drop-in endpoint,約低於標價 30%,新帳號有 $10 免費額度且不需信用卡。請看 Claude Fable 5 on OneHop 或 start with $10 free。

