
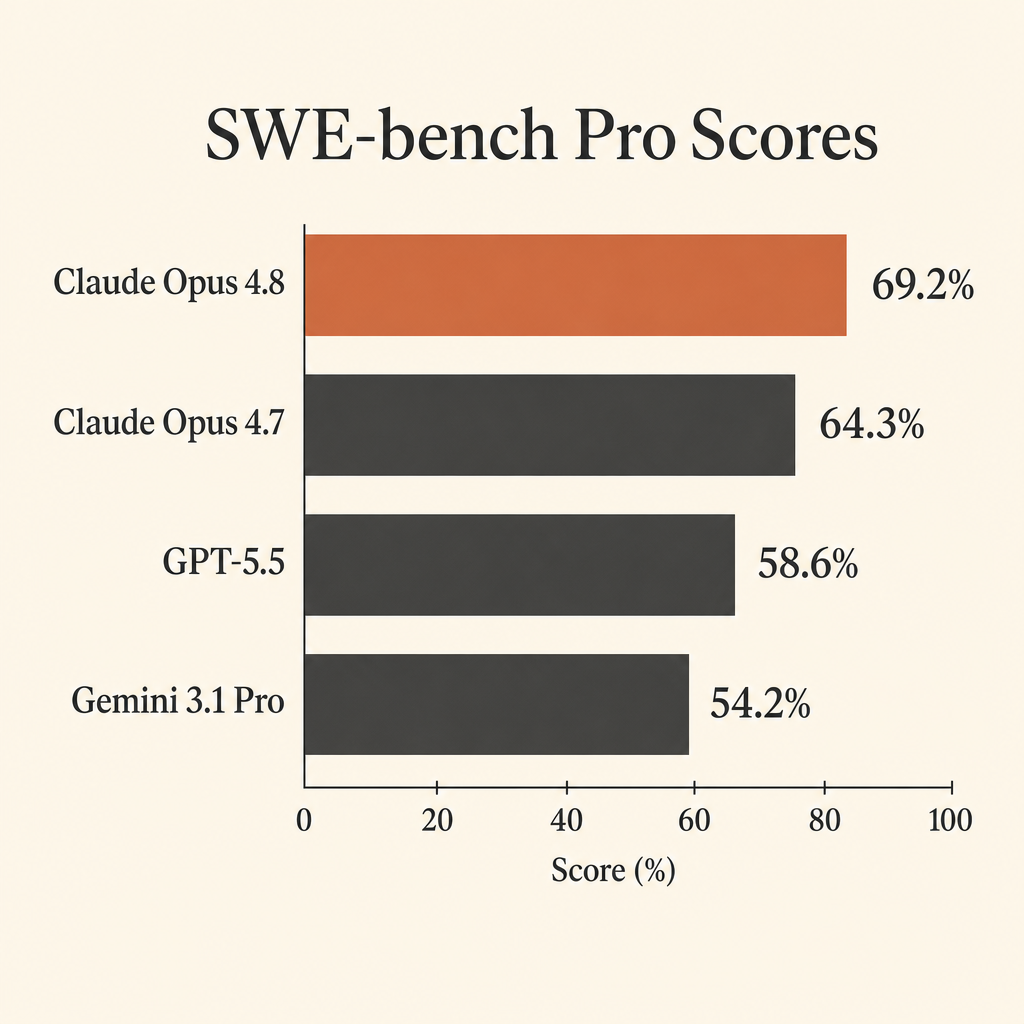
أهم رقم برمجي في Claude Opus 4.8 ليس نتيجته شبه المشبعة في SWE-bench Verified. الرقم الأهم هو 69.2% في SWE-bench Pro.
وهذا مهم لأن SWE-bench Pro صُمّم لنوع العمل الذي يريده المطوّرون فعلًا من الوكلاء المستقلين: فتح مستودع حقيقي، فهم المشكلة، تعديل عدة ملفات، تشغيل الاختبارات، التعافي من الافتراضات الخاطئة، وتسليم تصحيح صالح. في بطاقة نظام Claude Opus 4.8 من Anthropic، يسجّل Opus 4.8 نسبة 69.2% في SWE-bench Pro، متقدمًا على GPT-5.5 عند 58.6% وGemini 3.1 Pro عند 54.2% (Anthropic system card PDF).
هذه الفجوة كبيرة بما يكفي لتغيير اختيار النموذج في البرمجة الوكيلية. إذا كنت تدفع لنموذج كي يلتهم سياق المستودع، واستدعاءات الأدوات، وفشل الاختبارات، وحلقات الإصلاح الطويلة، ففارق عشر نقاط في معيار قياس ليس تفصيلة عابرة. إنه الفرق بين «يحتاج إلى مراقبة دائمة» و«يستحق أن تعطيه مهمة حقيقية».
مقارنة معيارية (Benchmark)
هذه هي المقارنة المختصرة التي يفترض أن تكون في كل وثيقة تقييم لوكلاء البرمجة هذا الأسبوع.
| Model | SWE-bench Pro | SWE-bench Verified | Terminal-Bench 2.1 | API price, input/output |
|---|---|---|---|---|
| Claude Opus 4.8 | 69.2% | 88.6% | 74.6% | $5 / $25 per 1M tokens |
| Claude Opus 4.7 | 64.3% | 87.6% | 66.1% | not compared here |
| GPT-5.5 | 58.6% | not listed | 78.2% | $5 / $30 per 1M tokens |
| Gemini 3.1 Pro Preview | 54.2% | 80.6% | 70.3% | $2 / $12 <=200k prompt, $4 / $18 >200k prompt |
درجات المعايير أعلاه مأخوذة من جدول بطاقة نظام Opus 4.8 لدى Anthropic (Anthropic system card PDF). تقول صفحة المنتج لدى Anthropic إن Opus 4.8 أُطلق في 28 مايو 2026، وهو مبني لـ«البرمجة الجادة ووكلاء الذكاء الاصطناعي»، ويدعم نافذة سياق بحجم 1M، ويبدأ سعره من $5 لكل مليون رمز إدخال و$25 لكل مليون رمز إخراج (Anthropic). تسعّر OpenAI نموذج GPT-5.5 عند $5 للإدخال و$30 للإخراج لكل مليون رمز، مع نافذة سياق من 1,050,000 رمز ولقطة gpt-5.5-2026-04-23 (OpenAI). وتعرض Google تسعير Gemini 3.1 Pro Preview عند $2/$12 لكل مليون رمز للمطالبات حتى 200k رمز، و$4/$18 لما فوق 200k (Google AI).
Opus يفوز في معيار إصلاح المستودعات. GPT-5.5 يفوز في Terminal-Bench 2.1 ضمن هذا الجدول. Gemini أرخص لكل رمز، خصوصًا تحت عتبة مطالبة 200k، لكنه يتأخر في SWE-bench Pro.
هذا هو شكل القرار.
ما الذي يقيسه SWE-bench Pro فعلًا
SWE-bench Pro ليس اختبارًا آخر من نوع «اكتب دالة من مطالبة». تصفه الورقة البحثية بأنه معيار يضم 1,865 مشكلة عبر 41 مستودعًا تتم صيانتها بنشاط، بما في ذلك تطبيقات أعمال، وخدمات B2B، وأدوات للمطوّرين (arXiv). ويقسّم المهام إلى مجموعة عامة، ومجموعة محجوبة، ومجموعة تجارية مبنية من مستودعات خاصة لشركات ناشئة.
التفصيلة المهمة هي شكل المهمة. مسائل SWE-bench Pro هي مهام هندسة برمجيات طويلة الأفق. يقول المؤلفون إنها قد تستغرق من مهندس محترف ساعات أو أيامًا، وغالبًا تتطلب تصحيحات عبر عدة ملفات، وتشمل تغييرات كبيرة في الكود (arXiv). كما يستبعد المعيار التعديلات التافهة. وتشير الورقة إلى أن متوسط حلول المرجع يبلغ 107.4 أسطر عبر 4.1 ملفات.
هذا أقرب إلى العمل الذي يسلّمه المطوّرون للوكلاء:
git grep "billing status"
npm test -- --runInBand
git diff
pytest tests/billing/test_invoices.pyالصعب ليس إنتاج كود صحيح نحويًا. الصعب هو معرفة أي طبقة تملك الخطأ، وقراءة ما يكفي من الكود المحيط، والتعديل من دون كسر السلوك المجاور، واستخدام مخرجات الاختبارات لتصحيح المسار.
ما زال SWE-bench Verified مفيدًا، لكنه أصبح مزدحمًا في القمة. يضع جدول Anthropic نموذج Opus 4.8 عند 88.6% وOpus 4.7 عند 87.6% في SWE-bench Verified. فارق نقطة واحدة لا يكفي لاختيار نموذج لعمل مستودعات مستقل ومكلف. في SWE-bench Pro، الفارق بين Opus 4.8 وOpus 4.7 هو 4.9 نقاط. أمام GPT-5.5 هو 10.6 نقاط. وأمام Gemini 3.1 Pro هو 15.0 نقطة.
هذه إشارة حقيقية.
الأداء مقابل الدولار أعقد من سعر الملصق
سعر الرموز ما زال مهمًا. الوكلاء جائعون. تشغيل واحد حقيقي على مستودع قد يتضمن سياقًا أوليًا طويلًا، وقراءات متكررة للملفات، وسجلات اختبارات، وتصحيحات فاشلة، وملخصات، ورموز استدلال أو تفكير مخفية بحسب طريقة فوترة المزوّد.
لرقم تقريبي قابل للمقارنة، خذ تشغيلًا افتراضيًا لبرمجة بسياق طويل يتضمن 800k رمز إدخال و200k رمز إخراج. هذا ليس حمل عمل عالميًا؛ إنه فقط طريقة نظيفة لمقارنة أسعار API المعلنة لمهمة مستودع كبيرة.
| Model | Pricing assumption | Cost for 800k in / 200k out | SWE-bench Pro | Score points per $ |
|---|---|---|---|---|
| Claude Opus 4.8 | $5 in / $25 out | $9.00 | 69.2 | 7.69 |
| GPT-5.5 | $5 in / $30 out | $10.00 | 58.6 | 5.86 |
| Gemini 3.1 Pro Preview | >200k prompt: $4 in / $18 out | $6.80 | 54.2 | 7.97 |
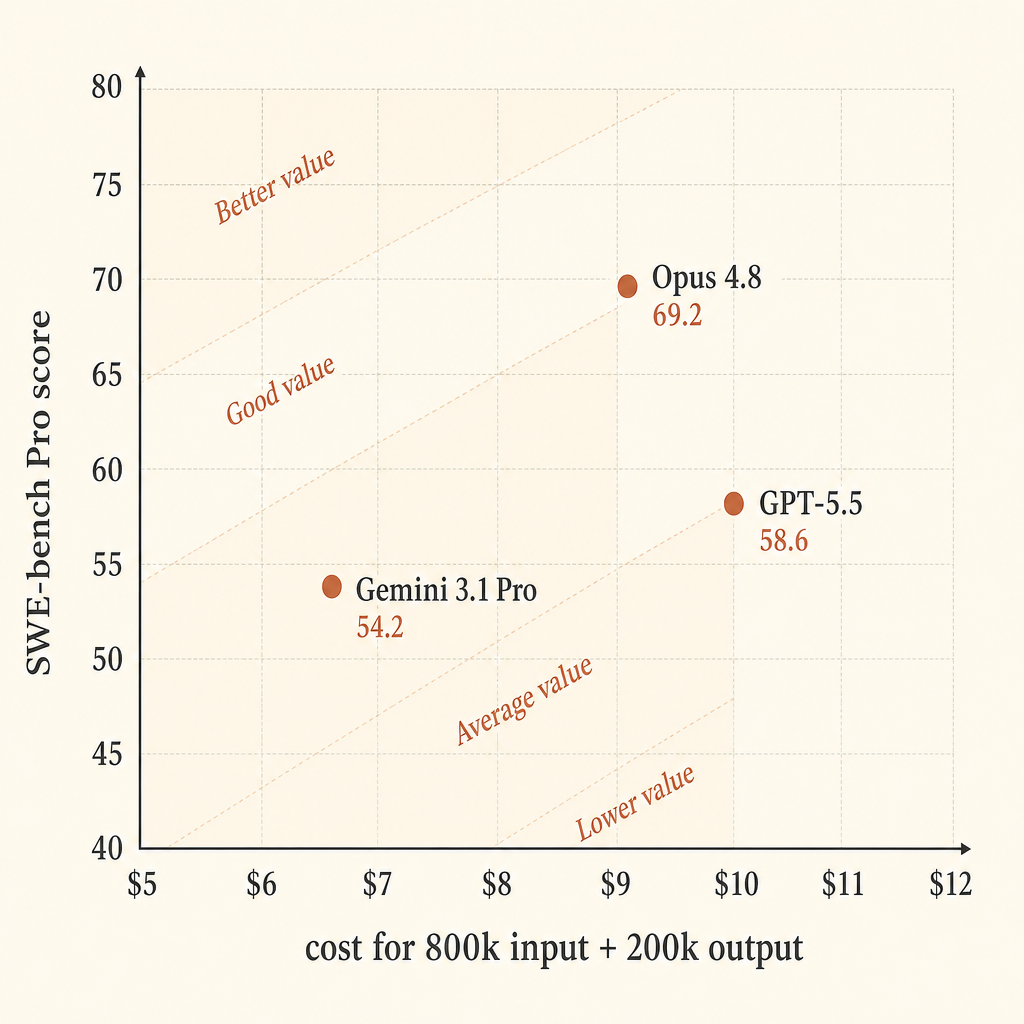
يبدو Gemini قويًا في كفاءة السعر الخام ضمن هذا الحساب المبسّط. ويبدو Opus الأقوى إذا كانت نسبة النجاح هي الأولوية. أما GPT-5.5 فهو الوسط المكلف في هذه الشريحة بالضبط: سعر إخراج أعلى من Opus، ودرجة SWE-bench Pro أقل، لكنه صاحب أفضل نتيجة Terminal-Bench 2.1 في جدول Anthropic.
في البرمجة المستقلة، لن أحسّن فقط من أجل «نقاط معيار لكل دولار». فشل تشغيل الوكيل ليس فاتورة الرموز وحدها. هناك أيضًا وقت المراجعة، وتبديل السياق، والتصحيحات السيئة، ومطالبات المتابعة الهشة، وكلفة إعادة تشغيل الحلقة كلها. إذا تحوّلت نسبة نجاح Opus 4.8 الأعلى إلى عدد أقل من الإعادات في قاعدة كودك، فقد تختفي فجوة $2.20 أمام Gemini في التشغيل الافتراضي بسرعة.
الطريقة العادلة لاتخاذ القرار هي تشغيل حزمة تقييمك على مستودعك:
agent-eval run \
--model claude-opus-4-8 \
--tasks evals/repo_tasks.jsonl \
--max-cost-usd 50 \
--record patches,tests,tokensتتبّع التصحيحات المقبولة، ودقائق المراجعة البشرية، والتكلفة الإجمالية، ومعدل التراجع. درجات المعايير يجب أن تختار قائمتك المختصرة. مستودعك هو ما يجب أن يختار الإنتاج.
لماذا يفوز Opus 4.8 في هذه الإشارة تحديدًا
قصة Opus 4.8 ليست «Claude أفضل في الكود» بالمعنى العام. هذا ادعاء واسع أكثر من اللازم وغالبًا سيكون خاطئًا في معيار واحد على الأقل. الادعاء الأدق هو هذا: في إعداد SWE-bench Pro الذي أبلغت عنه Anthropic، يتقدّم Opus 4.8 في حل مشكلات المستودعات بشكل مستقل.
وهذا يترجم إلى ثلاث نقاط قوة عملية.
أولًا، لديه مساحة فوق السقف السهل. SWE-bench Verified مفيد، لكن عندما تكون النماذج أصلًا في أواخر الثمانينات، تصبح الفروق الصغيرة ضوضاء عند اتخاذ قرار الشراء. SWE-bench Pro يفتح الفارق من جديد.
ثانيًا، يضغط على سلوك مستوى المستودع. تشير ورقة SWE-bench Pro إلى مقاومة التلوث، وقواعد الكود التجارية/الخاصة، والتغييرات متعددة الملفات، والتحقق البشري، والمهام ذات الطابع المؤسسي (arXiv). هذا أقرب إلى «أصلح هذا الانحدار في خدمة الفوترة لدينا» من «أكمل دالة Python هذه».
ثالثًا، وضعت Anthropic نموذج Opus 4.8 حول البرمجة طويلة التشغيل والوكلاء، لا حول الدردشة فقط. تقول صفحة Opus إن النموذج متاح في Claude Code وAPI، ويدعم سياق 1M، ومصمم للبرمجة المعقدة، وسير العمل الوكيلي، والعمل الاحترافي (Anthropic). لغة التسويق ليست دليلًا، لكن جدول المعايير منسجم مع اتجاه المنتج.
كيف أختار نموذجًا لوكلاء المستودعات
إذا كان وكيلك يقوم بتعديلات سطحية، أو مقاطع كود، أو إكمال تلقائي داخل IDE، فلا ينبغي أن يكون SWE-bench Pro عدستك الوحيدة. زمن الاستجابة، وجودة البث، وتكامل الأدوات المحلية، والسعر ستكون أهم.
إذا كان من المتوقع أن يتولى وكيلك مهام المستودع من البداية إلى النهاية، فابدأ بهذا الترتيب:
- استخدم Claude Opus 4.8 كخط أساس للجودة في عمل المستودعات المستقل والصعب.
- اختبر GPT-5.5 عندما يكون تنفيذ المهام الثقيلة في الطرفية مهمًا، لأن جدول Anthropic يمنحه صدارة Terminal-Bench 2.1.
- اختبر Gemini 3.1 Pro Preview عندما يكون ضغط التكلفة عاليًا وتبقى مهامك تحت عتبات كلفة الفشل.
- أبقِ نموذجًا أرخص داخل الحلقة للفرز، وملخصات البحث في الملفات، والتعديلات منخفضة المخاطر.
أوثق نمط إنتاج ليس نموذجًا عملاقًا واحدًا لكل شيء. استخدم نموذجًا سريعًا وأرخص لتصنيف المشكلات وجمع السياق. صعّد التصحيح الصعب إلى Opus 4.8. شغّل الاختبارات. استخدم نموذجًا ثانيًا، أحيانًا GPT-5.5 أو Gemini، كمراجع للفرق النهائي. لا تشحن إلا عندما تتفق حزمة الاختبارات والمراجع البشري.
هذا يبدو أقل سحرًا من «مهندس مستقل». جيد. وهو أيضًا ما يمنع الفرق من الاستيقاظ على تصحيح جميل كسر المصادقة.
الخلاصة
نتيجة Claude Opus 4.8 البالغة 69.2% في SWE-bench Pro هي إشارة أفضل للمطوّرين من رقم عالٍ آخر في SWE-bench Verified. إنها تقيس ما يفترض أن يفعله الوكلاء بصورة أقرب: التنقل داخل المستودع، والتغييرات متعددة الملفات، والإصلاح المدفوع بالاختبارات، والتنفيذ طويل الأفق.
Opus 4.8 ليس أرخص نموذج في المقارنة. ولا يفوز أيضًا بكل معيار في جدول Anthropic نفسه. لكن في عمل المستودعات المستقل، فجوة SWE-bench Pro كبيرة بما يكفي لتجعله أول نموذج سأقيّمه.
استخدم الأرقام العامة لبناء القائمة المختصرة. ثم شغّل مهامك الخاصة، وقِس التصحيحات المقبولة لكل دولار، وأدخل وقت المراجعة البشرية ضمن التكلفة. هناك فقط تتحول انتصارات المعايير إلى قوة هندسية، أو تختفي.
يمكن للقراء الذين يريدون تجربة Claude Fable 5 بأنفسهم استخدامه عبر OneHop: نقطة نهاية بديلة مباشرة، بحوالي 30% أقل من السعر الرسمي، مع $10 مجانًا للحسابات الجديدة ومن دون الحاجة إلى بطاقة. راجع Claude Fable 5 على OneHop أو ابدأ مع $10 مجانًا.
قراءة إضافية: البدء مع Claude Fable 5.

