
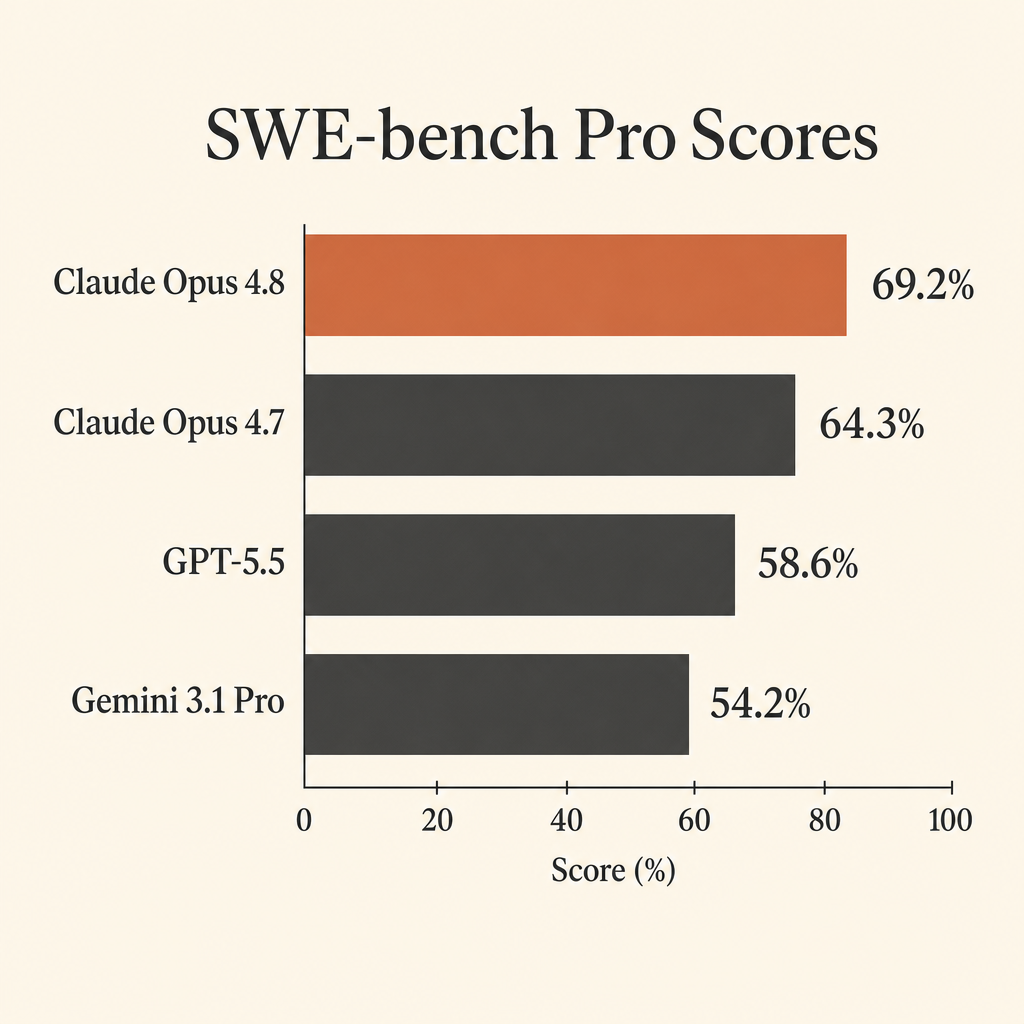
Claude Opus 4.8에서 코딩에 가장 쓸모 있는 숫자는 거의 포화 상태에 가까운 SWE-bench Verified 점수가 아니다. SWE-bench Pro의 69.2%다.
이게 중요한 이유는 SWE-bench Pro가 개발자들이 자율 에이전트에게 실제로 기대하는 일에 맞춰 만들어졌기 때문이다. 진짜 저장소를 열고, 이슈를 이해하고, 여러 파일을 수정하고, 테스트를 돌리고, 잘못된 가정에서 회복한 뒤, 패치를 내놓는 일 말이다. Anthropic의 Claude Opus 4.8 시스템 카드에서 Opus 4.8은 SWE-bench Pro 69.2%를 기록해, 58.6%의 GPT-5.5와 54.2%의 Gemini 3.1 Pro를 앞선다 (Anthropic system card PDF).
이 격차는 에이전트형 코딩에서 모델 선택을 바꿀 만큼 크다. 저장소 컨텍스트, 도구 호출, 테스트 실패, 긴 수정 루프에 돈을 태우는 모델이라면, 벤치마크 10점 차이는 잡음이 아니다. “계속 옆에서 봐줘야 함”과 “진짜 일을 맡겨볼 만함”의 차이다.
벤치마크 비교 (Benchmark)
이번 주 모든 코딩 에이전트 평가 문서에 들어가야 할 간결한 비교는 이렇다.
| Model | SWE-bench Pro | SWE-bench Verified | Terminal-Bench 2.1 | API price, input/output |
|---|---|---|---|---|
| Claude Opus 4.8 | 69.2% | 88.6% | 74.6% | $5 / $25 per 1M tokens |
| Claude Opus 4.7 | 64.3% | 87.6% | 66.1% | not compared here |
| GPT-5.5 | 58.6% | not listed | 78.2% | $5 / $30 per 1M tokens |
| Gemini 3.1 Pro Preview | 54.2% | 80.6% | 70.3% | $2 / $12 <=200k prompt, $4 / $18 >200k prompt |
위 벤치마크 점수는 Anthropic의 Opus 4.8 시스템 카드 표에서 가져왔다 (Anthropic system card PDF). Anthropic 제품 페이지에 따르면 Opus 4.8은 2026년 5월 28일 출시되었고, “serious coding and AI agents”를 위해 만들어졌으며, 1M 컨텍스트 윈도우를 지원하고, 가격은 입력 토큰 100만 개당 $5, 출력 토큰 100만 개당 $25부터 시작한다 (Anthropic). OpenAI는 GPT-5.5를 입력 100만 토큰당 $5, 출력 100만 토큰당 $30로 제시하며, 1,050,000 토큰 컨텍스트 윈도우와 gpt-5.5-2026-04-23 스냅샷을 제공한다 (OpenAI). Google은 Gemini 3.1 Pro Preview 가격을 프롬프트 200k 토큰 이하에서는 100만 토큰당 $2/$12, 200k 초과에서는 $4/$18로 제시한다 (Google AI).
레포 수리 벤치마크에서는 Opus가 이긴다. 이 표에서 Terminal-Bench 2.1은 GPT-5.5가 이긴다. Gemini는 특히 200k 프롬프트 임계값 아래에서 토큰당 더 저렴하지만, SWE-bench Pro에서는 뒤처진다.
결정의 윤곽은 이렇다.
SWE-bench Pro가 실제로 측정하는 것
SWE-bench Pro는 또 하나의 “프롬프트를 보고 함수를 작성하라” 테스트가 아니다. 논문은 이를 활발히 유지보수되는 41개 저장소의 1,865개 문제로 구성된 벤치마크라고 설명하며, 여기에는 비즈니스 애플리케이션, B2B 서비스, 개발자 도구가 포함된다 (arXiv). 작업은 공개 세트, 비공개 보류 세트, 그리고 비공개 스타트업 저장소로 만든 상업용 세트로 나뉜다.
중요한 건 작업의 모양이다. SWE-bench Pro 문제는 긴 호흡의 소프트웨어 엔지니어링 작업이다. 저자들은 이런 작업이 전문 엔지니어에게도 몇 시간 또는 며칠이 걸릴 수 있고, 여러 파일에 걸친 패치가 필요한 경우가 많으며, 상당한 코드 변경을 포함한다고 말한다 (arXiv). 이 벤치마크는 사소한 수정도 걸러낸다. 논문에 따르면 평균 참조 해법은 4.1개 파일에 걸쳐 107.4줄이다.
개발자가 에이전트에게 맡기는 일에 더 가깝다.
git grep "billing status"
npm test -- --runInBand
git diff
pytest tests/billing/test_invoices.py어려운 부분은 문법적으로 유효한 코드를 만드는 것이 아니다. 버그를 책임지는 레이어가 어디인지 파악하고, 주변 코드를 충분히 읽고, 인접 동작을 망가뜨리지 않게 수정하고, 테스트 출력을 이용해 방향을 바로잡는 것이다.
SWE-bench Verified도 여전히 가치가 있지만, 최상위권은 이미 붐빈다. Anthropic의 표에서 Opus 4.8은 SWE-bench Verified 88.6%, Opus 4.7은 87.6%다. 1점 차이는 비싼 자율 레포 작업에 쓸 모델을 고르기엔 부족하다. SWE-bench Pro에서는 Opus 4.8과 Opus 4.7의 차이가 4.9점이다. GPT-5.5와 비교하면 10.6점. Gemini 3.1 Pro와 비교하면 15.0점이다.
이건 신호다.
달러당 성능은 표시 가격보다 더 복잡하다
토큰 가격은 여전히 중요하다. 에이전트는 많이 먹는다. 실제 레포 실행 한 번에도 긴 초기 컨텍스트, 반복적인 파일 읽기, 테스트 로그, 실패한 패치, 요약, 그리고 제공자 과금 방식에 따라 숨겨진 추론 또는 사고 토큰이 들어갈 수 있다.
대략적인 동일 조건 비교를 위해, 입력 토큰 800k와 출력 토큰 200k가 드는 가상의 긴 컨텍스트 코딩 실행을 보자. 보편적인 워크로드라는 뜻은 아니다. 큰 레포 작업에서 공개된 API 가격을 깔끔하게 비교하기 위한 방법일 뿐이다.
| Model | Pricing assumption | Cost for 800k in / 200k out | SWE-bench Pro | Score points per $ |
|---|---|---|---|---|
| Claude Opus 4.8 | $5 in / $25 out | $9.00 | 69.2 | 7.69 |
| GPT-5.5 | $5 in / $30 out | $10.00 | 58.6 | 5.86 |
| Gemini 3.1 Pro Preview | >200k prompt: $4 in / $18 out | $6.80 | 54.2 | 7.97 |
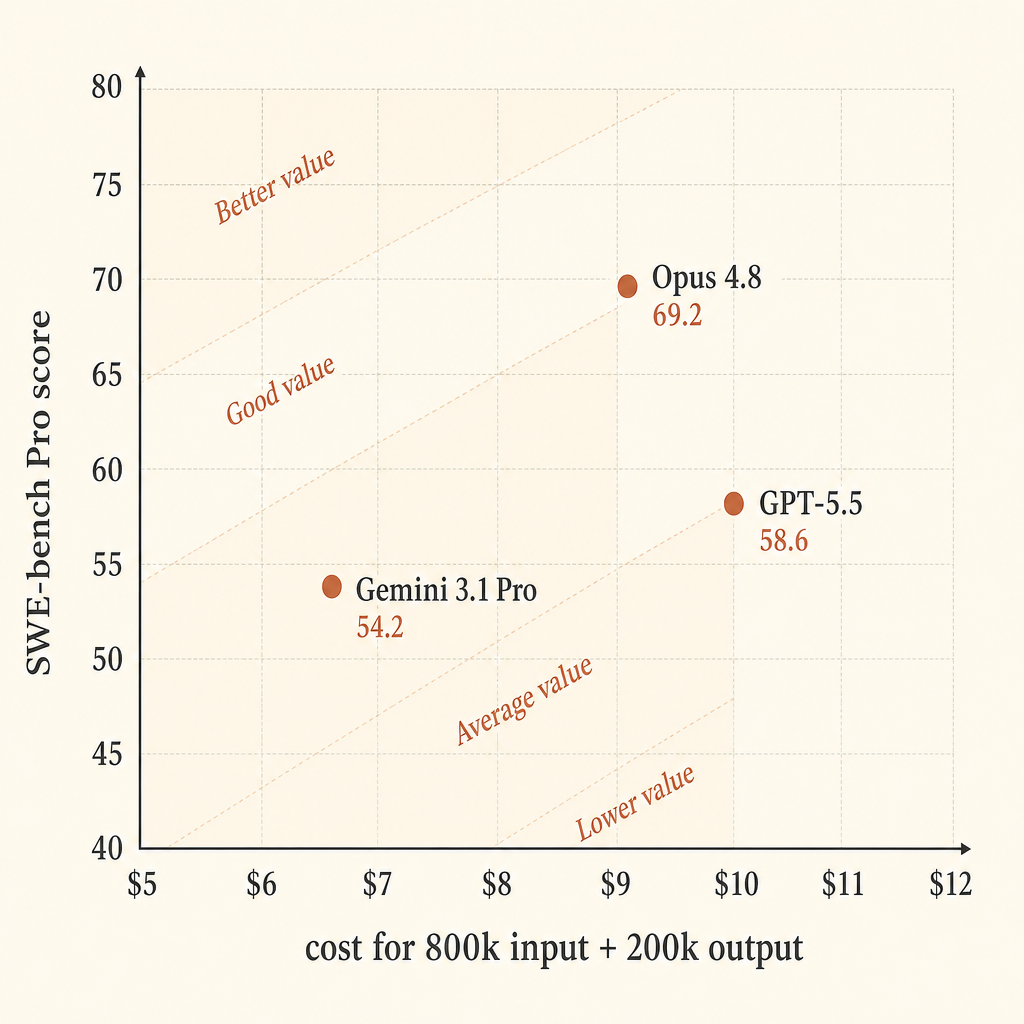
이 단순 계산에서는 Gemini가 순수 가격 효율 측면에서 강해 보인다. 통과율을 우선한다면 Opus가 가장 강해 보인다. 이 정확한 구간에서 GPT-5.5는 비싼 중간 지대다. Opus보다 출력 가격은 높고, SWE-bench Pro 점수는 낮지만, Anthropic 표에서는 Terminal-Bench 2.1 점수가 가장 좋다.
자율 코딩에서는 “달러당 벤치마크 점수”만으로 최적화하지 않을 것이다. 실패한 에이전트 실행의 비용은 토큰 청구서만이 아니다. 리뷰 시간, 컨텍스트 전환, 나쁜 패치, 흔들리는 후속 프롬프트, 전체 루프를 다시 돌리는 비용도 있다. Opus 4.8의 더 높은 통과율이 당신의 코드베이스에서 재시작 횟수를 줄여준다면, 가상 실행에서 Gemini와의 $2.20 차이는 금방 사라질 수 있다.
공정한 결정 방식은 직접 레포 하네스를 돌리는 것이다.
agent-eval run \
--model claude-opus-4-8 \
--tasks evals/repo_tasks.jsonl \
--max-cost-usd 50 \
--record patches,tests,tokens승인된 패치, 사람의 리뷰 시간, 총비용, 롤백률을 추적하라. 벤치마크 점수는 후보군을 정하는 데 써야 한다. 프로덕션 선택은 당신의 레포가 해야 한다.
Opus 4.8이 이 특정 신호에서 이기는 이유
Opus 4.8의 이야기는 막연히 “Claude가 코드에 더 좋다”가 아니다. 그건 너무 넓고, 적어도 하나의 벤치마크에서는 대개 틀리다. 더 날카로운 주장은 이렇다. Anthropic이 보고한 SWE-bench Pro 설정에서 Opus 4.8은 자율적인 저장소 이슈 해결에서 앞선다.
이는 세 가지 실용적인 강점으로 이어진다.
첫째, 쉬운 천장 위에 아직 여지가 있다. SWE-bench Verified는 유용하지만, 모델들이 이미 80%대 후반에 있으면 작은 차이는 구매 결정에 잡음이 된다. SWE-bench Pro는 다시 격차를 벌린다.
둘째, 레포 규모의 행동을 압박한다. SWE-bench Pro 논문은 오염 저항성, 상업용/비공개 코드베이스, 다중 파일 변경, 사람 검증, 엔터프라이즈 스타일 작업을 강조한다 (arXiv). 이는 “이 Python 함수를 완성하라”보다 “우리 결제 서비스의 이 회귀를 고쳐라”에 더 가깝다.
셋째, Anthropic은 Opus 4.8을 단순 채팅이 아니라 오래 실행되는 코딩과 에이전트 중심으로 포지셔닝했다. Opus 페이지는 이 모델이 Claude Code와 API에서 제공되고, 1M 컨텍스트를 지원하며, 복잡한 코딩, 에이전트형 워크플로, 전문 작업을 겨냥한다고 말한다 (Anthropic). 마케팅 문구가 증거는 아니지만, 벤치마크 표는 제품 방향과 맞아떨어진다.
레포 에이전트용 모델을 고른다면
에이전트가 얕은 수정, 코드 스니펫, IDE 자동완성을 한다면 SWE-bench Pro만 봐서는 안 된다. 지연 시간, 스트리밍 품질, 로컬 도구 통합, 가격이 더 중요할 것이다.
에이전트가 레포 작업을 처음부터 끝까지 맡아야 한다면, 이 순위에서 시작하겠다.
- 어려운 자율 레포 작업의 품질 기준선으로 Claude Opus 4.8을 사용한다.
- 터미널 중심 작업 실행이 중요할 때 GPT-5.5를 테스트한다. Anthropic의 표에서는 Terminal-Bench 2.1 선두가 GPT-5.5이기 때문이다.
- 비용 압박이 크고 작업이 실패 비용 임계값 아래에 머문다면 Gemini 3.1 Pro Preview를 테스트한다.
- 분류, 파일 검색 요약, 저위험 수정에는 더 저렴한 모델을 루프에 둔다.
가장 신뢰할 만한 프로덕션 패턴은 모든 일을 하나의 거대한 모델에 맡기는 것이 아니다. 빠르고 저렴한 모델로 이슈를 분류하고 컨텍스트를 모은다. 어려운 패치는 Opus 4.8로 에스컬레이션한다. 테스트를 실행한다. 두 번째 모델, 때로는 GPT-5.5나 Gemini를 최종 diff 리뷰어로 쓴다. 테스트 스위트와 사람 리뷰어가 모두 동의할 때만 배포한다.
“자율 엔지니어”라는 말보다 덜 마법처럼 들린다. 좋다. 덕분에 팀은 인증을 깨뜨린 아름다운 패치를 다음 날 아침 마주하는 일을 피할 수 있다.
결론
Claude Opus 4.8의 SWE-bench Pro 69.2%는 또 하나의 높은 SWE-bench Verified 숫자보다 개발자에게 더 나은 신호다. 에이전트가 해야 한다고 여겨지는 일, 즉 레포 탐색, 다중 파일 변경, 테스트 기반 수정, 긴 호흡의 실행에 더 가깝게 측정한다.
Opus 4.8은 이 비교에서 가장 저렴한 모델이 아니다. Anthropic 자신의 표에서도 모든 벤치마크를 이기지는 않는다. 하지만 자율 레포 작업에서는 SWE-bench Pro 격차가 충분히 커서, 내가 가장 먼저 평가할 모델이다.
공개 숫자로 후보군을 만들라. 그런 다음 직접 작업을 돌리고, 달러당 승인된 패치를 측정하고, 사람 리뷰 시간을 비용에 포함하라. 벤치마크의 승리가 엔지니어링 레버리지로 바뀌는지, 아니면 사라지는지는 거기서 결정된다.
Claude Fable 5를 직접 써보고 싶은 독자는 OneHop을 통해 사용할 수 있다. 드롭인 엔드포인트, 정가보다 약 30% 낮은 가격, 신규 계정 $10 무료, 카드 불필요다. OneHop의 Claude Fable 5 또는 $10 무료로 시작하기를 참고하라.
더 읽기: Claude Fable 5 시작하기.

