
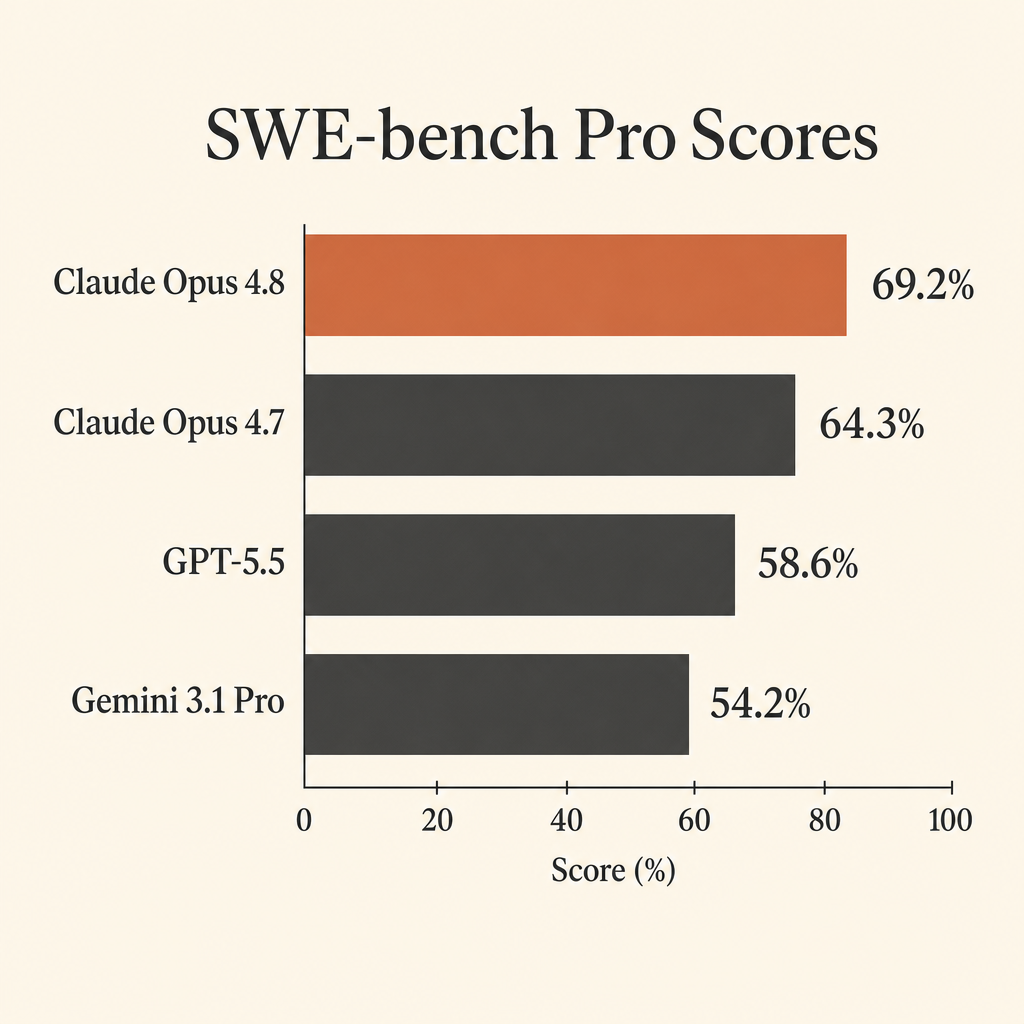
Самая полезная цифра Claude Opus 4.8 для кодинга — не почти упершийся в потолок результат на SWE-bench Verified. Это 69,2% на SWE-bench Pro.
Это важно, потому что SWE-bench Pro сделан под ту работу, которую разработчики на самом деле хотят отдавать автономным агентам: открыть настоящий репозиторий, понять issue, править несколько файлов, запускать тесты, отступать от неверных предположений и доводить патч до готовности. В system card Claude Opus 4.8 от Anthropic Opus 4.8 набирает 69,2% на SWE-bench Pro, опережая GPT-5.5 с 58,6% и Gemini 3.1 Pro с 54,2% (Anthropic system card PDF).
Разрыв достаточно большой, чтобы влиять на выбор модели для агентного кодинга. Если вы платите модели за то, чтобы она прожигала контекст репозитория, вызовы инструментов, падения тестов и длинные циклы исправлений, десять пунктов в бенчмарке — не мелочь. Это разница между «нужен постоянный присмотр» и «можно дать настоящую задачу».
Сравнение бенчмарков (Benchmark)
Вот компактное сравнение, которое на этой неделе должно быть в каждом документе по оценке coding-agent.
| Модель | SWE-bench Pro | SWE-bench Verified | Terminal-Bench 2.1 | Цена API, ввод/вывод |
|---|---|---|---|---|
| Claude Opus 4.8 | 69.2% | 88.6% | 74.6% | $5 / $25 за 1M токенов |
| Claude Opus 4.7 | 64.3% | 87.6% | 66.1% | здесь не сравнивается |
| GPT-5.5 | 58.6% | не указано | 78.2% | $5 / $30 за 1M токенов |
| Gemini 3.1 Pro Preview | 54.2% | 80.6% | 70.3% | $2 / $12 <=200k prompt, $4 / $18 >200k prompt |
Оценки бенчмарков выше взяты из таблицы system card Opus 4.8 от Anthropic (Anthropic system card PDF). На продуктовой странице Anthropic сказано, что Opus 4.8 вышел 28 мая 2026 года, создан для “serious coding and AI agents,” поддерживает контекстное окно 1M и стоит от $5 за миллион входных токенов и $25 за миллион выходных токенов (Anthropic). OpenAI указывает для GPT-5.5 цену $5 за ввод и $30 за вывод за миллион токенов, контекстное окно на 1,050,000 токенов и snapshot gpt-5.5-2026-04-23 (OpenAI). Google указывает цены Gemini 3.1 Pro Preview: $2/$12 за миллион токенов для prompts до 200k токенов и $4/$18 выше 200k (Google AI).
Opus выигрывает бенчмарк по ремонту репозиториев. GPT-5.5 выигрывает Terminal-Bench 2.1 в этой таблице. Gemini дешевле за токен, особенно ниже порога prompt в 200k, но отстает на SWE-bench Pro.
Вот такая форма у решения.
Что на самом деле измеряет SWE-bench Pro
SWE-bench Pro — это не очередной тест «напиши функцию по prompt». В статье он описан как бенчмарк из 1 865 задач по 41 активно поддерживаемому репозиторию, включая бизнес-приложения, B2B-сервисы и инструменты для разработчиков (arXiv). Задачи разделены на публичный набор, отложенный набор и коммерческий набор, собранный из приватных репозиториев стартапов.
Важная деталь — форма задач. Проблемы SWE-bench Pro — это длинные software engineering задачи. Авторы пишут, что профессиональному инженеру на них могут понадобиться часы или дни, что они часто требуют патчей в нескольких файлах и включают существенные изменения кода (arXiv). Бенчмарк также отфильтровывает тривиальные правки. В статье указано, что среднее эталонное решение занимает 107,4 строки в 4,1 файлах.
Это ближе к той работе, которую разработчики отдают агентам:
git grep "billing status"
npm test -- --runInBand
git diff
pytest tests/billing/test_invoices.pyСложность не в том, чтобы выдать синтаксически корректный код. Сложность в том, чтобы понять, какой слой отвечает за баг, прочитать достаточно соседнего кода, внести правку и не сломать прилегающее поведение, а затем использовать вывод тестов, чтобы скорректировать курс.
SWE-bench Verified все еще полезен, но наверху становится тесно. В таблице Anthropic у Opus 4.8 — 88,6%, у Opus 4.7 — 87,6% на SWE-bench Verified. Разрыв в один пункт — слабая основа для выбора модели под дорогую автономную работу с репозиториями. На SWE-bench Pro разрыв между Opus 4.8 и Opus 4.7 — 4,9 пункта. Против GPT-5.5 — 10,6 пункта. Против Gemini 3.1 Pro — 15,0 пункта.
Вот это уже сигнал.
Производительность за доллар сложнее, чем цена на витрине
Цена токенов все еще важна. Агенты прожорливы. Один реальный прогон по репозиторию может включать длинный начальный контекст, повторные чтения файлов, логи тестов, неудачные патчи, summary, а также скрытые reasoning или thinking токены — в зависимости от того, как провайдер выставляет счет.
Для грубого сравнения «яблоки к яблокам» возьмем гипотетический long-context прогон кодинга с 800k входных токенов и 200k выходных. Это не универсальная нагрузка; просто чистый способ сравнить указанные цены API для большой задачи в репозитории.
| Модель | Допущение по цене | Стоимость 800k in / 200k out | SWE-bench Pro | Пункты результата за $ |
|---|---|---|---|---|
| Claude Opus 4.8 | $5 in / $25 out | $9.00 | 69.2 | 7.69 |
| GPT-5.5 | $5 in / $30 out | $10.00 | 58.6 | 5.86 |
| Gemini 3.1 Pro Preview | >200k prompt: $4 in / $18 out | $6.80 | 54.2 | 7.97 |
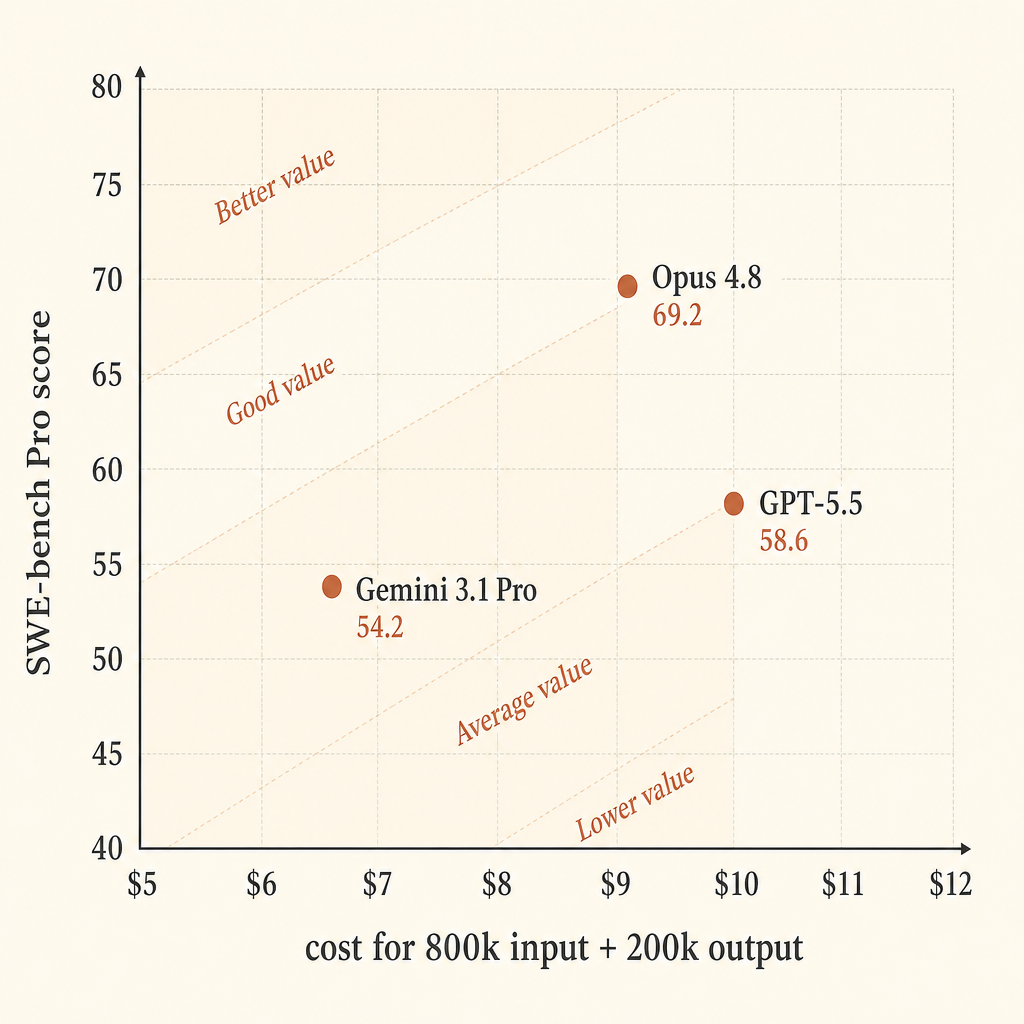
Gemini выглядит сильным по сырой ценовой эффективности в этом упрощенном расчете. Opus выглядит сильнее всех, если на первом месте вероятность прохождения. GPT-5.5 в этом конкретном срезе — дорогая середина: более высокая цена вывода, чем у Opus, более низкий результат SWE-bench Pro, но лучший результат Terminal-Bench 2.1 в таблице Anthropic.
Для автономного кодинга я бы не оптимизировал только “benchmark points per dollar.” Проваленный прогон агента — это не только счет за токены. Это еще время ревью, переключение контекста, плохие патчи, шаткие follow-up prompts и стоимость повторного запуска всего цикла. Если более высокий pass rate Opus 4.8 означает меньше рестартов в вашей кодовой базе, разница $2.20 против Gemini в гипотетическом прогоне может быстро испариться.
Честный способ выбрать — прогнать собственный harness на своем репозитории:
agent-eval run \
--model claude-opus-4-8 \
--tasks evals/repo_tasks.jsonl \
--max-cost-usd 50 \
--record patches,tests,tokensОтслеживайте принятые патчи, минуты человеческого ревью, общую стоимость и rollback rate. Бенчмарки должны формировать shortlist. Production должна выбирать ваша кодовая база.
Почему Opus 4.8 выигрывает именно этот сигнал
История Opus 4.8 — не “Claude лучше пишет код” в общем смысле. Это слишком широкое утверждение, и почти наверняка неверное хотя бы для одного бенчмарка. Более точная формулировка такая: в reported setup SWE-bench Pro от Anthropic Opus 4.8 впереди по автономному решению issue в репозиториях.
Это ложится на три практические сильные стороны.
Во-первых, у него есть пространство выше легкого потолка. SWE-bench Verified полезен, но когда модели уже в верхних 80%, малые дельты становятся шумом для решений о покупке. SWE-bench Pro снова раскрывает разрыв.
Во-вторых, он нагружает поведение на масштабе репозитория. В статье SWE-bench Pro отдельно отмечены устойчивость к contamination, коммерческие/приватные кодовые базы, изменения в нескольких файлах, человеческая верификация и enterprise-style задачи (arXiv). Это ближе к “почини регрессию в нашем billing service”, чем к “допиши эту Python-функцию.”
В-третьих, Anthropic позиционирует Opus 4.8 вокруг долгих задач кодинга и агентов, а не просто чата. На странице Opus сказано, что модель доступна в Claude Code и API, поддерживает 1M контекста и предназначена для сложного кодинга, agentic workflows и профессиональной работы (Anthropic). Маркетинговый текст — не доказательство, но таблица бенчмарков совпадает с направлением продукта.
Как бы я выбирал модель для repo agents
Если ваш агент делает поверхностные правки, code snippets или IDE autocomplete, SWE-bench Pro не должен быть вашей единственной линзой. Задержка, качество streaming, интеграция с локальными инструментами и цена будут важнее.
Если от агента ждут, что он будет вести задачи в репозитории от начала до конца, я бы начал с такого ранжирования:
- Используйте Claude Opus 4.8 как quality baseline для сложной автономной работы с репозиториями.
- Тестируйте GPT-5.5, когда важна terminal-heavy execution, поскольку таблица Anthropic отдает ему лидерство в Terminal-Bench 2.1.
- Тестируйте Gemini 3.1 Pro Preview, когда давление стоимости высокое и ваши задачи остаются ниже порога, где цена провала становится существенной.
- Держите более дешевую модель в цикле для triage, summary по поиску файлов и low-risk правок.
Самый надежный production-паттерн — не одна гигантская модель для всего. Используйте быструю дешевую модель, чтобы классифицировать issue и собрать контекст. Передавайте сложный патч в Opus 4.8. Запускайте тесты. Используйте вторую модель — иногда GPT-5.5 или Gemini — как reviewer финального diff. Отправляйте в ship только когда test suite и человеческий reviewer согласны.
Звучит менее магически, чем “autonomous engineer.” Отлично. Зато так команды не просыпаются рядом с красивым патчем, который сломал auth.
Итог
Результат Claude Opus 4.8 в 69,2% на SWE-bench Pro — более полезный сигнал для разработчиков, чем очередная высокая цифра SWE-bench Verified. Он измеряет то, что ближе к работе, которую должны делать агенты: навигацию по репозиторию, изменения в нескольких файлах, test-driven исправление и длинное выполнение задач.
Opus 4.8 — не самая дешевая модель в сравнении. И она не выигрывает каждый бенчмарк даже в собственной таблице Anthropic. Но для автономной работы с репозиториями разрыв на SWE-bench Pro достаточно большой, чтобы именно ее я оценивал первой.
Используйте публичные цифры, чтобы собрать shortlist. Затем прогоняйте собственные задачи, измеряйте принятые патчи на доллар и включайте время человеческого ревью в стоимость. Именно там победы в бенчмарках либо превращаются в инженерный рычаг, либо исчезают.
Читатели, которые хотят сами попробовать Claude Fable 5, могут использовать его через OneHop: drop-in endpoint, примерно на 30% ниже list price, $10 бесплатно для новых аккаунтов и без карты. Смотрите Claude Fable 5 on OneHop или start with $10 free.
Дальше: Getting started with Claude Fable 5.

