
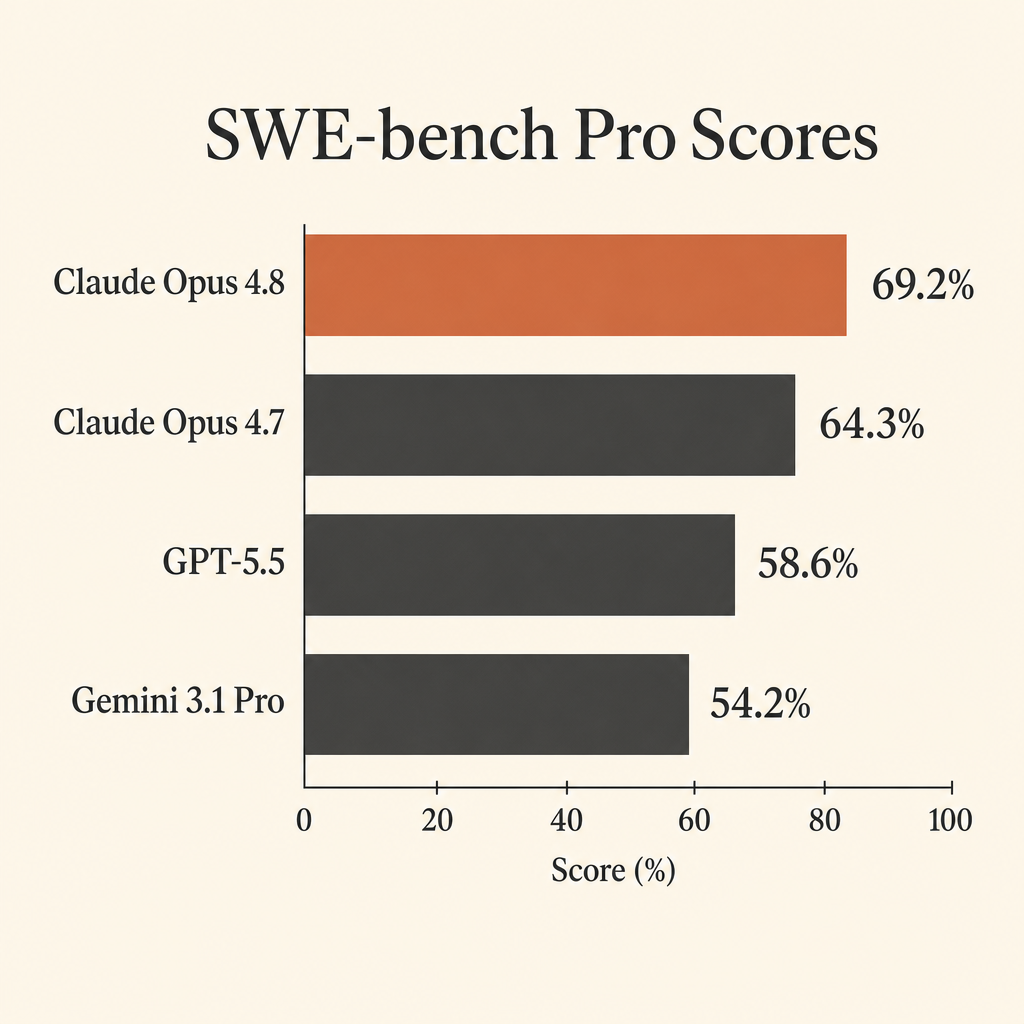
Le chiffre le plus utile de Claude Opus 4.8 pour le code, ce n’est pas son score presque saturé sur SWE-bench Verified. C’est ses 69,2 % sur SWE-bench Pro.
Et ça compte, parce que SWE-bench Pro a été conçu pour le genre de travail que les développeurs attendent vraiment des agents autonomes : ouvrir un vrai dépôt, comprendre le problème, modifier plusieurs fichiers, lancer les tests, se remettre de mauvaises hypothèses, et livrer un patch. Dans la system card de Claude Opus 4.8 publiée par Anthropic, Opus 4.8 obtient 69,2 % sur SWE-bench Pro, devant GPT-5.5 à 58,6 % et Gemini 3.1 Pro à 54,2 % (Anthropic system card PDF).
L’écart est assez large pour changer le choix du modèle en codage agentique. Si vous payez un modèle pour avaler du contexte de dépôt, des appels d’outils, des échecs de tests et de longues boucles de réparation, dix points d’écart sur un benchmark, ce n’est pas un détail. C’est la différence entre « demande beaucoup de baby-sitting » et « mérite qu’on lui confie une vraie tâche ».
Comparaison des benchmarks (Benchmark)
Voici la comparaison compacte qui devrait figurer cette semaine dans chaque doc d’évaluation d’agents de code.
| Model | SWE-bench Pro | SWE-bench Verified | Terminal-Bench 2.1 | API price, input/output |
|---|---|---|---|---|
| Claude Opus 4.8 | 69.2% | 88.6% | 74.6% | $5 / $25 per 1M tokens |
| Claude Opus 4.7 | 64.3% | 87.6% | 66.1% | not compared here |
| GPT-5.5 | 58.6% | not listed | 78.2% | $5 / $30 per 1M tokens |
| Gemini 3.1 Pro Preview | 54.2% | 80.6% | 70.3% | $2 / $12 <=200k prompt, $4 / $18 >200k prompt |
Les scores de benchmark ci-dessus viennent du tableau de la system card d’Opus 4.8 publiée par Anthropic (Anthropic system card PDF). La page produit d’Anthropic indique qu’Opus 4.8 a été lancé le 28 mai 2026, qu’il est conçu pour le « codage sérieux et les agents IA », qu’il prend en charge une fenêtre de contexte de 1M, et qu’il démarre à $5 par million de tokens d’entrée et $25 par million de tokens de sortie (Anthropic). OpenAI liste GPT-5.5 à $5 en entrée et $30 en sortie par million de tokens, avec une fenêtre de contexte de 1 050 000 tokens et un snapshot gpt-5.5-2026-04-23 (OpenAI). Google liste les prix de Gemini 3.1 Pro Preview à $2/$12 par million de tokens pour les prompts jusqu’à 200k tokens, puis $4/$18 au-delà de 200k (Google AI).
Opus gagne le benchmark de réparation de dépôt. GPT-5.5 gagne Terminal-Bench 2.1 dans ce tableau. Gemini coûte moins cher par token, surtout sous le seuil de prompt de 200k, mais reste derrière sur SWE-bench Pro.
Voilà la forme réelle de la décision.
Ce que SWE-bench Pro mesure vraiment
SWE-bench Pro n’est pas un test de plus du type « écris une fonction à partir d’un prompt ». L’article le décrit comme un benchmark de 1 865 problèmes répartis sur 41 dépôts activement maintenus, incluant des applications métier, des services B2B et des outils pour développeurs (arXiv). Il divise les tâches en un ensemble public, un ensemble retenu à part, et un ensemble commercial construit à partir de dépôts privés de startups.
Le détail important, c’est la forme des tâches. Les problèmes de SWE-bench Pro sont des tâches d’ingénierie logicielle à horizon long. Les auteurs disent qu’elles peuvent prendre des heures ou des jours à un ingénieur professionnel, qu’elles exigent souvent des patchs dans plusieurs fichiers, et qu’elles incluent des changements de code substantiels (arXiv). Le benchmark filtre aussi les modifications triviales. L’article rapporte des solutions de référence moyennes de 107,4 lignes sur 4,1 fichiers.
C’est beaucoup plus proche du travail que les développeurs donnent aux agents :
git grep "billing status"
npm test -- --runInBand
git diff
pytest tests/billing/test_invoices.pyLa difficulté n’est pas de produire du code syntaxiquement valide. C’est de comprendre quelle couche possède le bug, de lire assez de code autour, de modifier sans casser les comportements voisins, et d’utiliser la sortie des tests pour corriger la trajectoire.
SWE-bench Verified garde de la valeur, mais le haut du classement commence à être encombré. Le tableau d’Anthropic place Opus 4.8 à 88,6 % et Opus 4.7 à 87,6 % sur SWE-bench Verified. Un point d’écart ne suffit pas pour choisir un modèle destiné à du travail autonome coûteux sur dépôt. Sur SWE-bench Pro, l’écart entre Opus 4.8 et Opus 4.7 est de 4,9 points. Face à GPT-5.5, il est de 10,6 points. Face à Gemini 3.1 Pro, il est de 15,0 points.
Ça, c’est un signal.
La performance par dollar est plus compliquée que le prix affiché
Le prix des tokens compte toujours. Les agents sont voraces. Une seule exécution sur un vrai dépôt peut inclure un long contexte initial, des lectures de fichiers répétées, des logs de tests, des patchs ratés, des résumés, et des tokens de raisonnement ou de pensée cachés selon la facturation du fournisseur.
Pour une comparaison grossière à périmètre égal, prenons une exécution hypothétique de codage en long contexte avec 800k tokens d’entrée et 200k tokens de sortie. Ce n’est pas une charge de travail universelle ; c’est juste une manière propre de comparer les prix API affichés pour une grosse tâche sur dépôt.
| Model | Pricing assumption | Cost for 800k in / 200k out | SWE-bench Pro | Score points per $ |
|---|---|---|---|---|
| Claude Opus 4.8 | $5 in / $25 out | $9.00 | 69.2 | 7.69 |
| GPT-5.5 | $5 in / $30 out | $10.00 | 58.6 | 5.86 |
| Gemini 3.1 Pro Preview | >200k prompt: $4 in / $18 out | $6.80 | 54.2 | 7.97 |
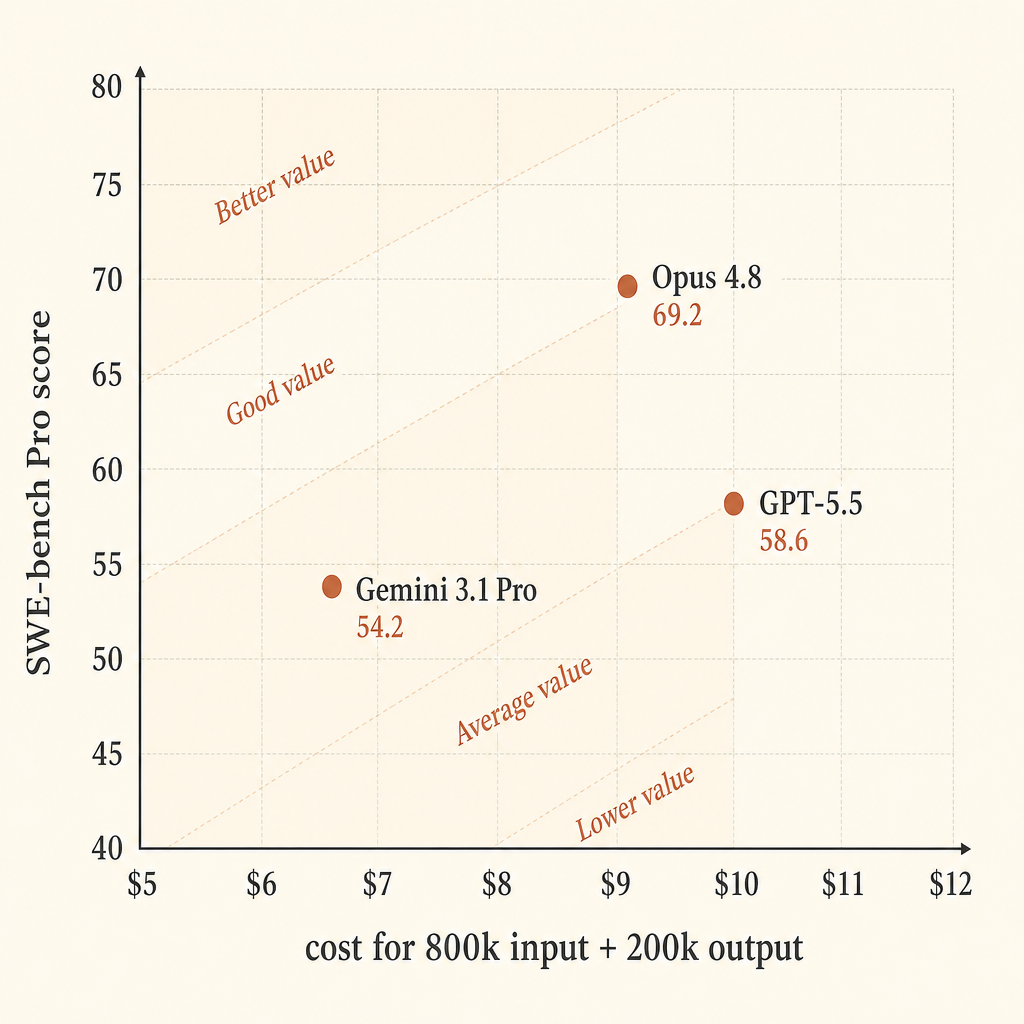
Gemini paraît solide en efficacité prix brute dans ce calcul simplifié. Opus paraît le plus fort si votre priorité est d’abord le taux de réussite. GPT-5.5 occupe le milieu coûteux dans cette tranche précise : prix de sortie plus élevé qu’Opus, score SWE-bench Pro plus bas, mais meilleur score Terminal-Bench 2.1 dans le tableau d’Anthropic.
Pour le codage autonome, je n’optimiserais pas uniquement les « points de benchmark par dollar ». Une exécution d’agent ratée, ce n’est pas seulement la facture de tokens. C’est aussi du temps de revue, du changement de contexte, de mauvais patchs, des prompts de suivi bancals, et le coût de relancer toute la boucle. Si le meilleur taux de réussite d’Opus 4.8 se traduit par moins de redémarrages dans votre base de code, les $2.20 d’écart face à Gemini dans l’exécution hypothétique peuvent disparaître vite.
La bonne façon de trancher, c’est de lancer votre propre harnais d’évaluation sur dépôt :
agent-eval run \
--model claude-opus-4-8 \
--tasks evals/repo_tasks.jsonl \
--max-cost-usd 50 \
--record patches,tests,tokensMesurez les patchs acceptés, les minutes de revue humaine, le coût total et le taux de rollback. Les scores de benchmark doivent choisir votre shortlist. Votre dépôt doit choisir la production.
Pourquoi Opus 4.8 gagne sur ce signal précis
L’histoire d’Opus 4.8 n’est pas « Claude est meilleur en code » au sens générique. C’est trop large, et généralement faux pour au moins un benchmark. L’affirmation plus nette est celle-ci : dans la configuration SWE-bench Pro rapportée par Anthropic, Opus 4.8 est devant sur la résolution autonome d’issues de dépôt.
Cela correspond à trois forces pratiques.
D’abord, il reste de la marge au-dessus du plafond facile. SWE-bench Verified est utile, mais quand les modèles sont déjà dans les hauts 80 %, les petits écarts deviennent bruyants pour les décisions d’achat. SWE-bench Pro rouvre l’écart.
Ensuite, il met sous pression les comportements à l’échelle d’un dépôt. L’article SWE-bench Pro insiste sur la résistance à la contamination, les bases de code commerciales/privées, les changements multi-fichiers, la vérification humaine et les tâches de style entreprise (arXiv). C’est plus proche de « corrige cette régression dans notre service de facturation » que de « complète cette fonction Python ».
Enfin, Anthropic positionne Opus 4.8 autour du codage longue durée et des agents, pas seulement du chat. Sa page Opus indique que le modèle est disponible dans Claude Code et l’API, prend en charge un contexte de 1M, et vise le codage complexe, les workflows agentiques et le travail professionnel (Anthropic). Le marketing ne prouve rien, mais le tableau de benchmark colle à la direction produit.
Comment je choisirais un modèle pour des agents de dépôt
Si votre agent fait des modifications superficielles, des extraits de code ou de l’autocomplétion dans l’IDE, SWE-bench Pro ne doit pas être votre seul prisme. La latence, la qualité du streaming, l’intégration avec les outils locaux et le prix compteront davantage.
Si votre agent doit prendre en charge des tâches de dépôt de bout en bout, commencez avec ce classement :
- Utilisez Claude Opus 4.8 comme référence qualité pour le travail autonome difficile sur dépôt.
- Testez GPT-5.5 quand l’exécution de tâches très terminal compte, puisque le tableau d’Anthropic lui donne l’avantage sur Terminal-Bench 2.1.
- Testez Gemini 3.1 Pro Preview quand la pression sur les coûts est forte et que vos tâches restent sous les seuils où l’échec coûte cher.
- Gardez un modèle moins cher dans la boucle pour le triage, les résumés de recherche de fichiers et les modifications à faible risque.
Le schéma de production le plus fiable, ce n’est pas un modèle géant pour tout. Utilisez un modèle rapide et moins cher pour classer les issues et rassembler le contexte. Escaladez le patch difficile vers Opus 4.8. Lancez les tests. Utilisez un second modèle, parfois GPT-5.5 ou Gemini, comme relecteur du diff final. Ne livrez que lorsque la suite de tests et le relecteur humain sont d’accord.
Ça sonne moins magique que « ingénieur autonome ». Très bien. C’est aussi comme ça que les équipes évitent de se réveiller avec un magnifique patch qui a cassé l’auth.
L’essentiel
Le score de 69,2 % de Claude Opus 4.8 sur SWE-bench Pro est un meilleur signal développeur qu’un énième gros chiffre sur SWE-bench Verified. Il mesure quelque chose de plus proche du travail que les agents sont censés faire : navigation dans un dépôt, changements multi-fichiers, réparation pilotée par les tests, et exécution à horizon long.
Opus 4.8 n’est pas le modèle le moins cher de la comparaison. Il ne gagne pas non plus tous les benchmarks dans le propre tableau d’Anthropic. Mais pour le travail autonome sur dépôt, l’écart sur SWE-bench Pro est assez grand pour en faire le premier modèle que j’évaluerais.
Utilisez les chiffres publics pour construire la shortlist. Puis lancez vos propres tâches, mesurez les patchs acceptés par dollar, et intégrez le temps de revue humaine dans le coût. C’est là que les victoires de benchmark deviennent un levier d’ingénierie — ou disparaissent.
Les lecteurs qui veulent essayer Claude Fable 5 eux-mêmes peuvent le faire via OneHop : un endpoint drop-in, environ 30 % sous le prix catalogue, avec $10 offerts aux nouveaux comptes et aucune carte requise. Voir Claude Fable 5 sur OneHop ou commencer avec $10 gratuits.
À lire aussi : Bien démarrer avec Claude Fable 5.

