
Claude Opus 4.8’s most useful coding number is not its near-saturated SWE-bench Verified score. It is 69.2% on SWE-bench Pro.
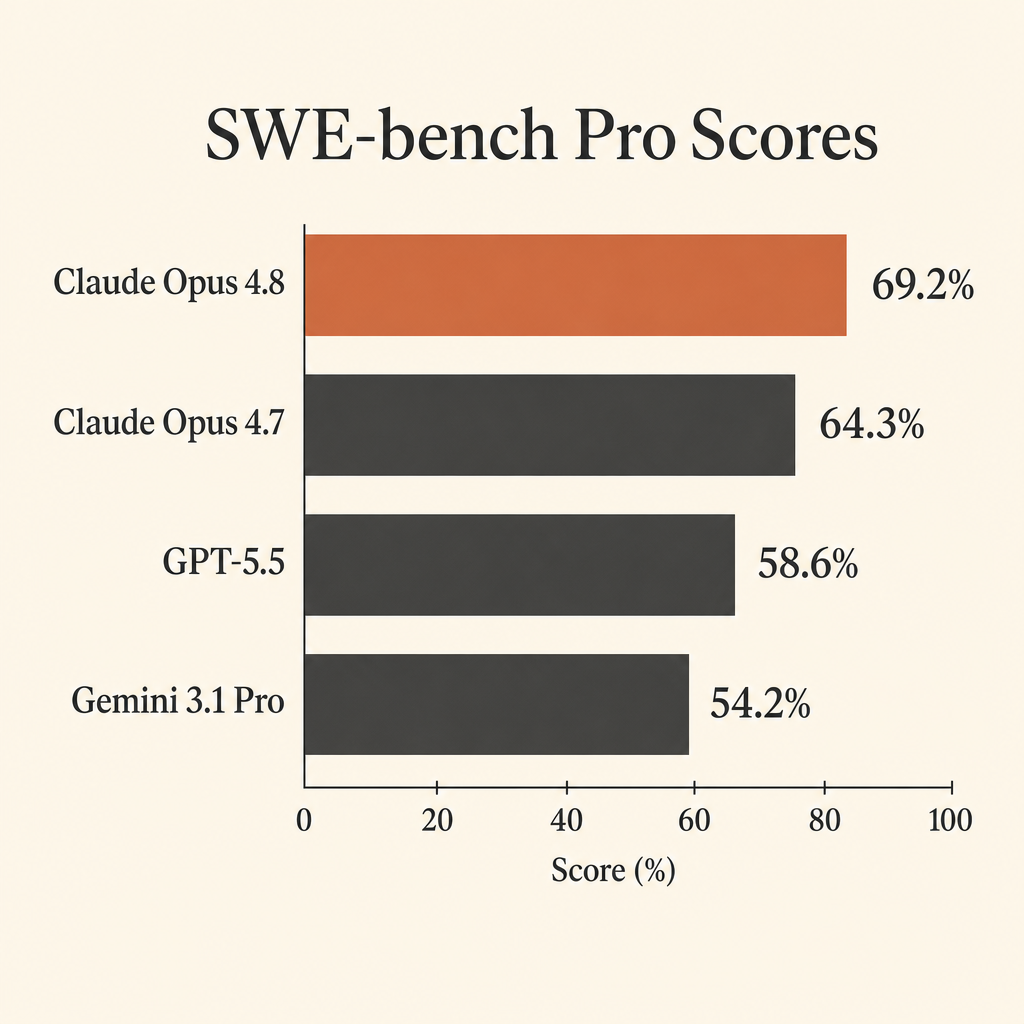
That matters because SWE-bench Pro was built for the kind of work developers actually want from autonomous agents: open a real repository, understand the issue, edit multiple files, run tests, recover from bad assumptions, and ship a patch. In Anthropic’s Claude Opus 4.8 system card, Opus 4.8 scores 69.2% on SWE-bench Pro, ahead of GPT-5.5 at 58.6% and Gemini 3.1 Pro at 54.2% (Anthropic system card PDF).
That gap is large enough to change model choice for agentic coding. If you are paying a model to burn through repo context, tool calls, test failures, and long repair loops, a ten-point benchmark spread is not trivia. It is the difference between “needs a lot of babysitting” and “worth giving a real task.”
评测对比 (Benchmark)
Here is the compact comparison that should be on every coding-agent evaluation doc this week.
| Model | SWE-bench Pro | SWE-bench Verified | Terminal-Bench 2.1 | API price, input/output |
|---|---|---|---|---|
| Claude Opus 4.8 | 69.2% | 88.6% | 74.6% | $5 / $25 per 1M tokens |
| Claude Opus 4.7 | 64.3% | 87.6% | 66.1% | not compared here |
| GPT-5.5 | 58.6% | not listed | 78.2% | $5 / $30 per 1M tokens |
| Gemini 3.1 Pro Preview | 54.2% | 80.6% | 70.3% | $2 / $12 <=200k prompt, $4 / $18 >200k prompt |
The benchmark scores above come from Anthropic’s Opus 4.8 system card table (Anthropic system card PDF). Anthropic’s product page says Opus 4.8 launched May 28, 2026, is built for “serious coding and AI agents,” supports a 1M context window, and starts at $5 per million input tokens and $25 per million output tokens (Anthropic). OpenAI lists GPT-5.5 at $5 input and $30 output per million tokens, with a 1,050,000-token context window and a gpt-5.5-2026-04-23 snapshot (OpenAI). Google lists Gemini 3.1 Pro Preview pricing at $2/$12 per million tokens for prompts up to 200k tokens, and $4/$18 above 200k (Google AI).
Opus wins the repo-repair benchmark. GPT-5.5 wins Terminal-Bench 2.1 in this table. Gemini is cheaper per token, especially below the 200k prompt threshold, but trails on SWE-bench Pro.
That is the shape of the decision.
What SWE-bench Pro Actually Measures
SWE-bench Pro is not another “write a function from a prompt” test. The paper describes it as a benchmark of 1,865 problems across 41 actively maintained repositories, including business applications, B2B services, and developer tools (arXiv). It splits tasks into a public set, a held-out set, and a commercial set built from private startup repositories.
The important detail is task shape. SWE-bench Pro problems are long-horizon software engineering tasks. The authors say they may take a professional engineer hours or days, often require patches across multiple files, and include substantial code changes (arXiv). The benchmark also filters out trivial edits. The paper reports average reference solutions of 107.4 lines across 4.1 files.
That is closer to the work developers hand to agents:
git grep "billing status"
npm test -- --runInBand
git diff
pytest tests/billing/test_invoices.pyThe hard part is not producing syntactically valid code. It is figuring out which layer owns the bug, reading enough surrounding code, editing without breaking adjacent behavior, and using test output to correct course.
SWE-bench Verified still has value, but it is getting crowded at the top. Anthropic’s table puts Opus 4.8 at 88.6% and Opus 4.7 at 87.6% on SWE-bench Verified. A one-point spread is not enough to pick a model for expensive autonomous repo work. On SWE-bench Pro, the Opus 4.8 versus Opus 4.7 spread is 4.9 points. Against GPT-5.5 it is 10.6 points. Against Gemini 3.1 Pro it is 15.0 points.
That is signal.
Performance Per Dollar Is More Complicated Than Sticker Price
Token price still matters. Agents are hungry. A single real repo run can include a long initial context, repeated file reads, test logs, failed patches, summaries, and hidden reasoning or thinking tokens depending on provider billing.
For a rough apples-to-apples figure, take a hypothetical long-context coding run with 800k input tokens and 200k output tokens. This is not a universal workload; it is just a clean way to compare listed API prices for a large repo task.
| Model | Pricing assumption | Cost for 800k in / 200k out | SWE-bench Pro | Score points per $ |
|---|---|---|---|---|
| Claude Opus 4.8 | $5 in / $25 out | $9.00 | 69.2 | 7.69 |
| GPT-5.5 | $5 in / $30 out | $10.00 | 58.6 | 5.86 |
| Gemini 3.1 Pro Preview | >200k prompt: $4 in / $18 out | $6.80 | 54.2 | 7.97 |
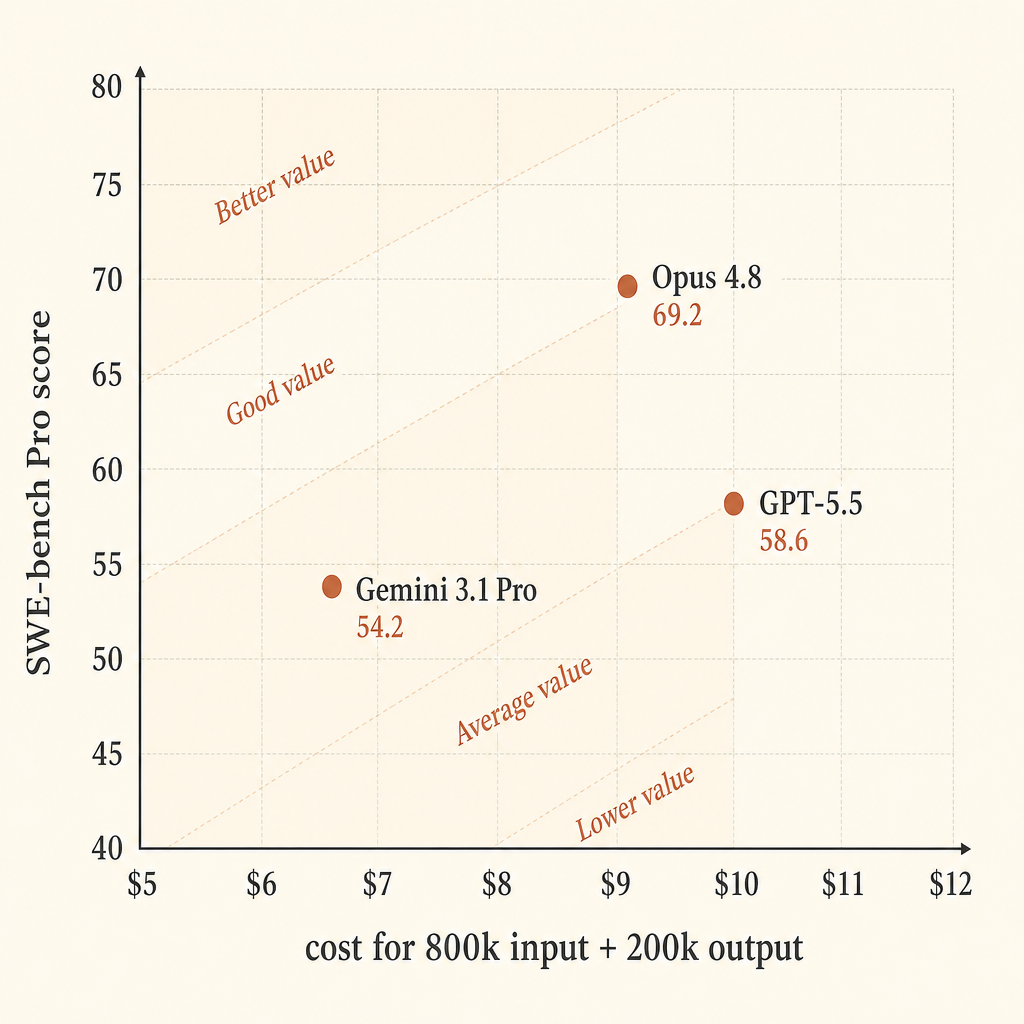
Gemini looks strong on raw price efficiency in this simplified calculation. Opus looks strongest if you care about pass rate first. GPT-5.5 is the expensive middle in this exact slice: higher output price than Opus, lower SWE-bench Pro score, but best Terminal-Bench 2.1 score in Anthropic’s table.
For autonomous coding, I would not optimize only for “benchmark points per dollar.” A failed agent run is not just the token bill. It is also review time, context switching, bad patches, flaky follow-up prompts, and the cost of rerunning the whole loop. If Opus 4.8’s higher pass rate translates to fewer restarts in your codebase, the $2.20 gap versus Gemini in the hypothetical run can disappear fast.
The fair way to decide is to run your own repo harness:
agent-eval run \
--model claude-opus-4-8 \
--tasks evals/repo_tasks.jsonl \
--max-cost-usd 50 \
--record patches,tests,tokensTrack accepted patches, human review minutes, total cost, and rollback rate. Benchmark scores should choose your shortlist. Your repo should choose production.
Why Opus 4.8 Wins This Particular Signal
The Opus 4.8 story is not “Claude is better at code” in the generic sense. That is too broad and usually false for at least one benchmark. The sharper claim is this: on Anthropic’s reported SWE-bench Pro setup, Opus 4.8 is ahead on autonomous repository issue resolution.
That maps to three practical strengths.
First, it has room above the easy ceiling. SWE-bench Verified is useful, but when models are already in the high 80s, small deltas become noisy for buyer decisions. SWE-bench Pro opens the spread again.
Second, it stresses repo-scale behavior. The SWE-bench Pro paper calls out contamination resistance, commercial/private codebases, multi-file changes, human verification, and enterprise-style tasks (arXiv). That is closer to “fix this regression in our billing service” than “complete this Python function.”
Third, Anthropic has positioned Opus 4.8 around long-running coding and agents, not just chat. Its Opus page says the model is available in Claude Code and the API, supports 1M context, and is intended for complex coding, agentic workflows, and professional work (Anthropic). Marketing language is not proof, but the benchmark table is aligned with the product direction.
How I’d Pick a Model for Repo Agents
If your agent is doing shallow edits, code snippets, or IDE autocomplete, SWE-bench Pro should not be your only lens. Latency, streaming quality, local tool integration, and price will matter more.
If your agent is expected to own repo tasks end to end, start with this ranking:
- Use Claude Opus 4.8 as the quality baseline for hard autonomous repo work.
- Test GPT-5.5 when terminal-heavy task execution matters, since Anthropic’s table gives it the Terminal-Bench 2.1 lead.
- Test Gemini 3.1 Pro Preview when cost pressure is high and your tasks stay below failure-cost thresholds.
- Keep a cheaper model in the loop for triage, file search summaries, and low-risk edits.
The most reliable production pattern is not one giant model for everything. Use a fast cheaper model to classify issues and gather context. Escalate the hard patch to Opus 4.8. Run tests. Use a second model, sometimes GPT-5.5 or Gemini, as a reviewer for the final diff. Ship only when the test suite and human reviewer agree.
That sounds less magical than “autonomous engineer.” Good. It is also how teams avoid waking up to a beautiful patch that broke auth.
The Bottom Line
Claude Opus 4.8’s 69.2% SWE-bench Pro score is a better developer signal than another high SWE-bench Verified number. It measures closer to the work agents are supposed to do: repo navigation, multi-file changes, test-driven repair, and long-horizon execution.
Opus 4.8 is not the cheapest model in the comparison. It also does not win every benchmark in Anthropic’s own table. But for autonomous repo work, the SWE-bench Pro gap is big enough to make it the first model I would evaluate.
Use the public numbers to build the shortlist. Then run your own tasks, measure accepted patches per dollar, and include human review time in the cost. That is where benchmark wins either become engineering leverage or disappear.
Readers who want to try Claude Fable 5 themselves can use it through OneHop: a drop-in endpoint, about 30% under list price, with $10 free for new accounts and no card required. See Claude Fable 5 on OneHop or start with $10 free.
Further reading: Getting started with Claude Fable 5.

