
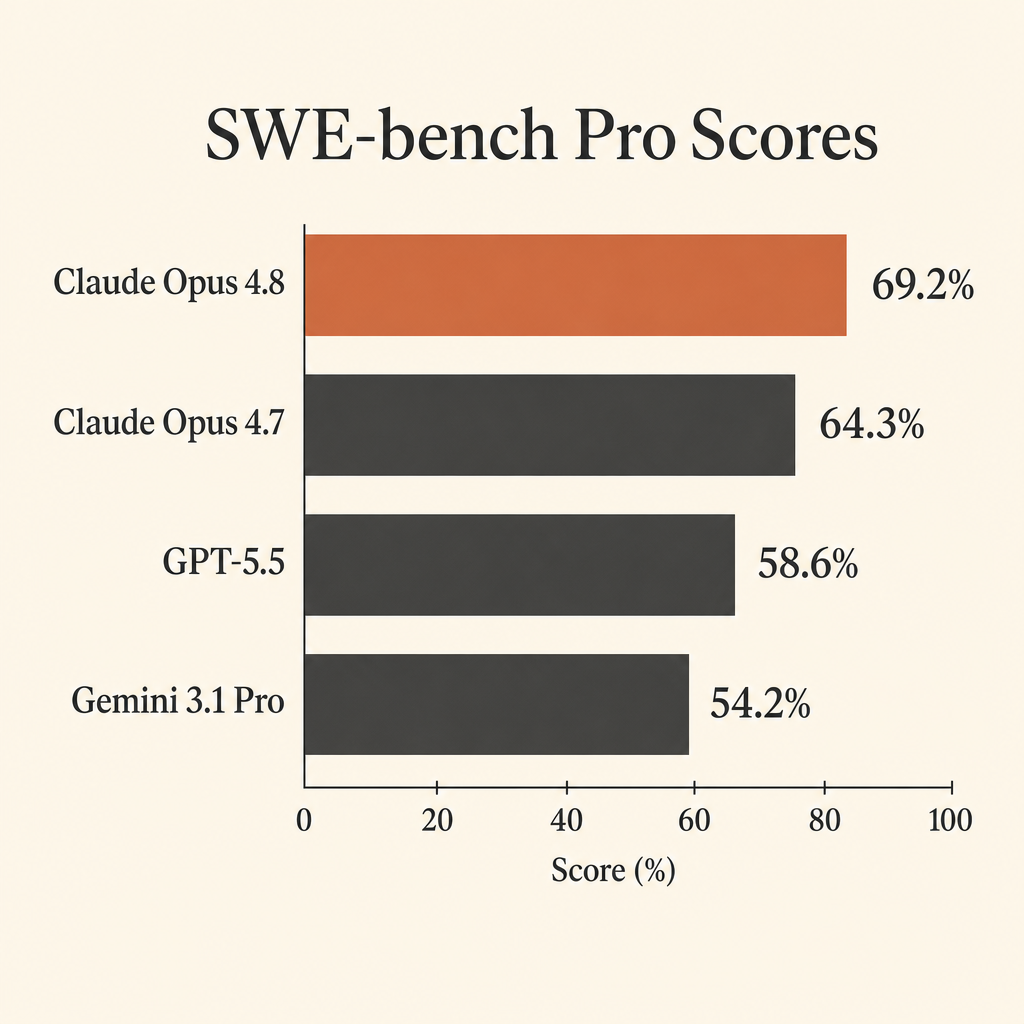
La cifra de programación más útil de Claude Opus 4.8 no es su puntuación casi saturada en SWE-bench Verified. Es el 69,2% en SWE-bench Pro.
Eso importa porque SWE-bench Pro se creó para el tipo de trabajo que los desarrolladores de verdad quieren de los agentes autónomos: abrir un repositorio real, entender el problema, editar varios archivos, ejecutar tests, recuperarse de suposiciones equivocadas y entregar un patch. En la system card de Claude Opus 4.8 de Anthropic, Opus 4.8 consigue un 69,2% en SWE-bench Pro, por delante de GPT-5.5 con 58,6% y Gemini 3.1 Pro con 54,2% (Anthropic system card PDF).
Esa diferencia es lo bastante grande como para cambiar la elección de modelo en programación agéntica. Si estás pagando a un modelo para devorar contexto de repositorio, llamadas a herramientas, fallos de tests y largos bucles de reparación, una brecha de diez puntos en un benchmark no es una anécdota. Es la diferencia entre “necesita mucha vigilancia” y “merece que le encargues una tarea real”.
Comparativa de benchmarks
Aquí está la comparación compacta que debería estar en todos los documentos de evaluación de agentes de código esta semana.
| Model | SWE-bench Pro | SWE-bench Verified | Terminal-Bench 2.1 | API price, input/output |
|---|---|---|---|---|
| Claude Opus 4.8 | 69.2% | 88.6% | 74.6% | $5 / $25 per 1M tokens |
| Claude Opus 4.7 | 64.3% | 87.6% | 66.1% | not compared here |
| GPT-5.5 | 58.6% | not listed | 78.2% | $5 / $30 per 1M tokens |
| Gemini 3.1 Pro Preview | 54.2% | 80.6% | 70.3% | $2 / $12 <=200k prompt, $4 / $18 >200k prompt |
Las puntuaciones anteriores vienen de la tabla de la system card de Opus 4.8 de Anthropic (Anthropic system card PDF). La página de producto de Anthropic dice que Opus 4.8 se lanzó el 28 de mayo de 2026, que está pensado para “programación seria y agentes de IA”, que soporta una ventana de contexto de 1M y que parte de $5 por millón de tokens de entrada y $25 por millón de tokens de salida (Anthropic). OpenAI lista GPT-5.5 a $5 de entrada y $30 de salida por millón de tokens, con una ventana de contexto de 1.050.000 tokens y un snapshot gpt-5.5-2026-04-23 (OpenAI). Google lista el precio de Gemini 3.1 Pro Preview en $2/$12 por millón de tokens para prompts de hasta 200k tokens, y $4/$18 por encima de 200k (Google AI).
Opus gana el benchmark de reparación de repositorios. GPT-5.5 gana Terminal-Bench 2.1 en esta tabla. Gemini es más barato por token, especialmente por debajo del umbral de 200k en el prompt, pero queda por detrás en SWE-bench Pro.
Esa es la forma de la decisión.
Qué mide realmente SWE-bench Pro
SWE-bench Pro no es otro test de “escribe una función a partir de un prompt”. El paper lo describe como un benchmark de 1.865 problemas repartidos en 41 repositorios mantenidos activamente, incluidos aplicaciones de negocio, servicios B2B y herramientas para desarrolladores (arXiv). Divide las tareas en un conjunto público, un conjunto retenido y un conjunto comercial construido a partir de repositorios privados de startups.
El detalle importante es la forma de las tareas. Los problemas de SWE-bench Pro son tareas de ingeniería de software de largo recorrido. Los autores dicen que pueden llevar a un ingeniero profesional horas o días, que a menudo requieren patches en varios archivos y que incluyen cambios sustanciales de código (arXiv). El benchmark también filtra las ediciones triviales. El paper reporta soluciones de referencia promedio de 107,4 líneas en 4,1 archivos.
Eso se parece más al trabajo que los desarrolladores delegan en agentes:
git grep "billing status"
npm test -- --runInBand
git diff
pytest tests/billing/test_invoices.pyLo difícil no es producir código sintácticamente válido. Es averiguar qué capa es dueña del bug, leer suficiente código alrededor, editar sin romper comportamiento adyacente y usar la salida de los tests para corregir el rumbo.
SWE-bench Verified sigue teniendo valor, pero arriba empieza a estar saturado. La tabla de Anthropic sitúa a Opus 4.8 en 88,6% y a Opus 4.7 en 87,6% en SWE-bench Verified. Una diferencia de un punto no basta para elegir un modelo para trabajo autónomo caro en repositorios. En SWE-bench Pro, la brecha entre Opus 4.8 y Opus 4.7 es de 4,9 puntos. Frente a GPT-5.5, es de 10,6 puntos. Frente a Gemini 3.1 Pro, es de 15,0 puntos.
Eso sí es señal.
El rendimiento por dólar es más complicado que el precio de etiqueta
El precio de los tokens sigue importando. Los agentes tienen hambre. Una sola ejecución real en un repositorio puede incluir un contexto inicial largo, lecturas repetidas de archivos, logs de tests, patches fallidos, resúmenes y tokens ocultos de razonamiento o pensamiento, según la facturación del proveedor.
Para una cifra aproximada comparable, tomemos una ejecución hipotética de programación con contexto largo: 800k tokens de entrada y 200k tokens de salida. No es una carga de trabajo universal; solo es una forma limpia de comparar precios de API publicados para una tarea grande de repositorio.
| Model | Pricing assumption | Cost for 800k in / 200k out | SWE-bench Pro | Score points per $ |
|---|---|---|---|---|
| Claude Opus 4.8 | $5 in / $25 out | $9.00 | 69.2 | 7.69 |
| GPT-5.5 | $5 in / $30 out | $10.00 | 58.6 | 5.86 |
| Gemini 3.1 Pro Preview | >200k prompt: $4 in / $18 out | $6.80 | 54.2 | 7.97 |
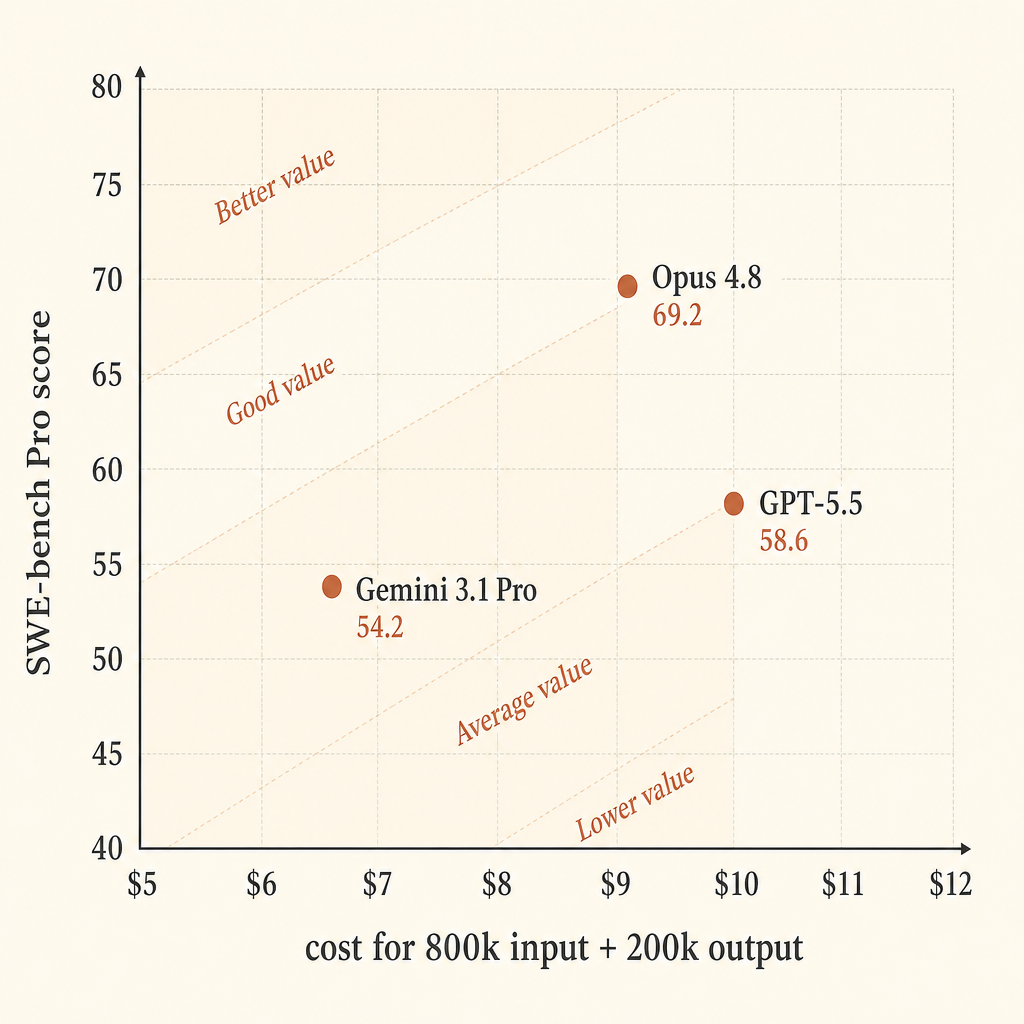
Gemini sale fuerte en eficiencia bruta de precio en este cálculo simplificado. Opus sale más fuerte si lo primero que te importa es la tasa de éxito. GPT-5.5 queda como el punto medio caro en este corte exacto: precio de salida más alto que Opus, puntuación más baja en SWE-bench Pro, pero mejor puntuación en Terminal-Bench 2.1 dentro de la tabla de Anthropic.
Para programación autónoma, yo no optimizaría solo por “puntos de benchmark por dólar”. Una ejecución fallida de un agente no es solo la factura de tokens. También es tiempo de revisión, cambio de contexto, patches malos, prompts de seguimiento frágiles y el coste de volver a ejecutar todo el bucle. Si la mayor tasa de éxito de Opus 4.8 se traduce en menos reinicios en tu base de código, la diferencia hipotética de $2,20 frente a Gemini puede desaparecer rápido.
La forma justa de decidir es ejecutar tu propio harness de repositorio:
agent-eval run \
--model claude-opus-4-8 \
--tasks evals/repo_tasks.jsonl \
--max-cost-usd 50 \
--record patches,tests,tokensMide patches aceptados, minutos de revisión humana, coste total y tasa de rollback. Las puntuaciones de benchmark deberían elegir tu shortlist. Tu repositorio debería elegir producción.
Por qué Opus 4.8 gana esta señal concreta
La historia de Opus 4.8 no es “Claude es mejor programando” en sentido genérico. Eso es demasiado amplio y normalmente falso en al menos un benchmark. La afirmación más precisa es esta: en la configuración de SWE-bench Pro reportada por Anthropic, Opus 4.8 va por delante en resolución autónoma de incidencias de repositorio.
Eso se traduce en tres fortalezas prácticas.
Primero, tiene margen por encima del techo fácil. SWE-bench Verified es útil, pero cuando los modelos ya están en los altos 80, las pequeñas diferencias se vuelven ruidosas para decisiones de compra. SWE-bench Pro vuelve a abrir la distancia.
Segundo, presiona el comportamiento a escala de repositorio. El paper de SWE-bench Pro destaca resistencia a la contaminación, bases de código comerciales/privadas, cambios multiarchivo, verificación humana y tareas de estilo empresarial (arXiv). Eso se parece más a “arregla esta regresión en nuestro servicio de facturación” que a “completa esta función de Python”.
Tercero, Anthropic ha posicionado Opus 4.8 alrededor de programación de larga duración y agentes, no solo chat. Su página de Opus dice que el modelo está disponible en Claude Code y la API, soporta contexto de 1M y está pensado para programación compleja, flujos de trabajo agénticos y trabajo profesional (Anthropic). El lenguaje de marketing no es prueba, pero la tabla de benchmark encaja con la dirección del producto.
Cómo elegiría un modelo para agentes de repositorio
Si tu agente hace ediciones superficiales, snippets de código o autocompletado en el IDE, SWE-bench Pro no debería ser tu única lente. La latencia, la calidad del streaming, la integración con herramientas locales y el precio pesarán más.
Si esperas que tu agente se haga cargo de tareas de repositorio de principio a fin, empieza con este ranking:
- Usa Claude Opus 4.8 como baseline de calidad para trabajo autónomo difícil en repositorios.
- Prueba GPT-5.5 cuando importe la ejecución intensiva en terminal, ya que la tabla de Anthropic le da el liderazgo en Terminal-Bench 2.1.
- Prueba Gemini 3.1 Pro Preview cuando la presión de costes sea alta y tus tareas se mantengan por debajo de los umbrales donde fallar sale caro.
- Mantén un modelo más barato en el bucle para triage, resúmenes de búsqueda de archivos y ediciones de bajo riesgo.
El patrón de producción más fiable no es un único modelo gigante para todo. Usa un modelo rápido y más barato para clasificar incidencias y reunir contexto. Escala el patch difícil a Opus 4.8. Ejecuta tests. Usa un segundo modelo, a veces GPT-5.5 o Gemini, como revisor del diff final. Entrega solo cuando la suite de tests y el revisor humano estén de acuerdo.
Eso suena menos mágico que “ingeniero autónomo”. Bien. También es la forma en que los equipos evitan despertarse con un patch precioso que rompió auth.
La conclusión
La puntuación de 69,2% de Claude Opus 4.8 en SWE-bench Pro es una señal mejor para desarrolladores que otro número alto en SWE-bench Verified. Mide algo más cercano al trabajo que se supone que hacen los agentes: navegación por repositorios, cambios multiarchivo, reparación guiada por tests y ejecución de largo recorrido.
Opus 4.8 no es el modelo más barato de la comparación. Tampoco gana todos los benchmarks en la propia tabla de Anthropic. Pero para trabajo autónomo en repositorios, la brecha en SWE-bench Pro es lo bastante grande como para convertirlo en el primer modelo que evaluaría.
Usa los números públicos para construir la shortlist. Luego ejecuta tus propias tareas, mide patches aceptados por dólar e incluye el tiempo de revisión humana en el coste. Ahí es donde las victorias de benchmark se convierten en palanca de ingeniería o desaparecen.
Los lectores que quieran probar Claude Fable 5 por su cuenta pueden usarlo a través de OneHop: un endpoint compatible, alrededor de un 30% por debajo del precio de lista, con $10 gratis para cuentas nuevas y sin tarjeta requerida. Mira Claude Fable 5 en OneHop o empieza con $10 gratis.
Lectura adicional: Primeros pasos con Claude Fable 5.

