
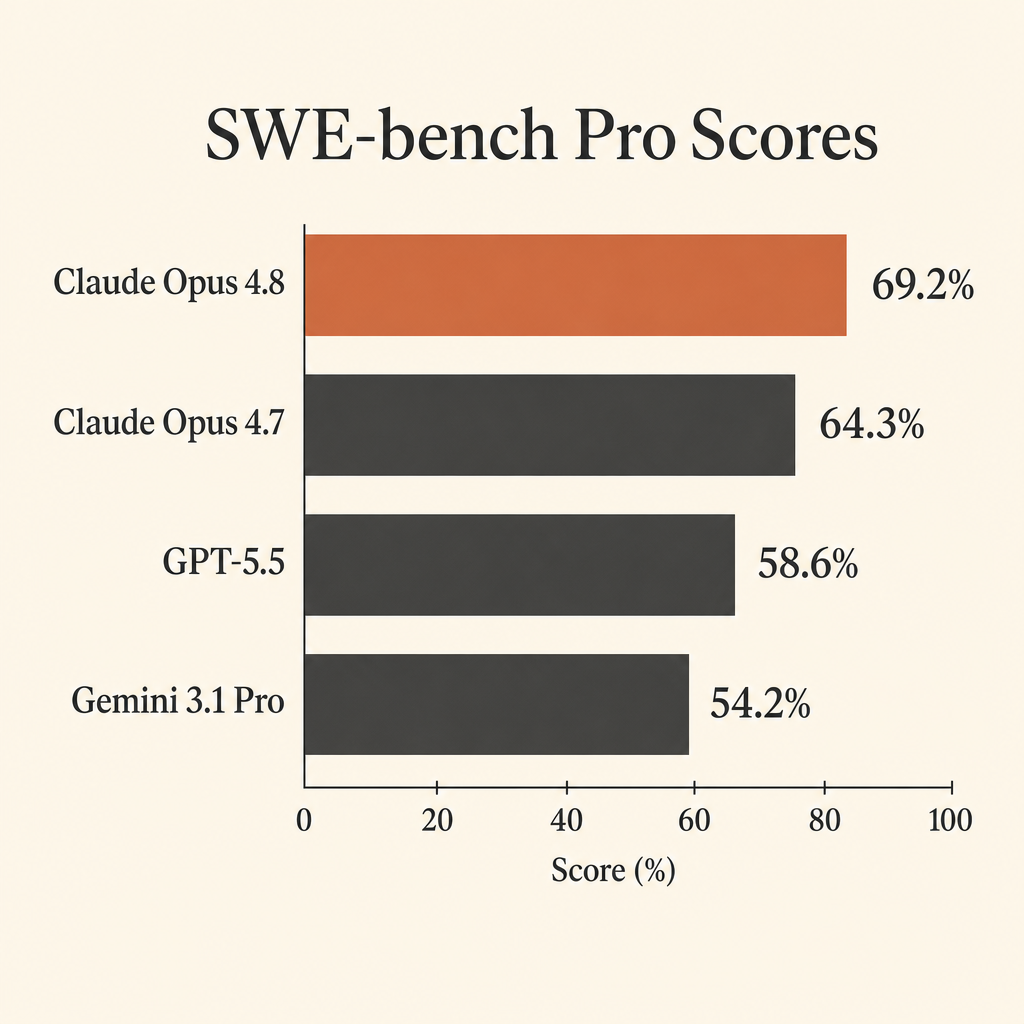
O número mais útil do Claude Opus 4.8 em programação não é sua pontuação quase saturada no SWE-bench Verified. É 69,2% no SWE-bench Pro.
Isso importa porque o SWE-bench Pro foi criado para o tipo de trabalho que desenvolvedores realmente querem de agentes autônomos: abrir um repositório real, entender a issue, editar vários arquivos, rodar testes, se recuperar de premissas ruins e entregar um patch. No system card do Claude Opus 4.8 da Anthropic, o Opus 4.8 faz 69,2% no SWE-bench Pro, à frente do GPT-5.5 com 58,6% e do Gemini 3.1 Pro com 54,2% (Anthropic system card PDF).
Essa diferença é grande o bastante para mudar a escolha de modelo em programação agentic. Se você está pagando um modelo para atravessar contexto de repositório, chamadas de ferramenta, falhas de teste e longos ciclos de correção, uma diferença de dez pontos em benchmark não é detalhe. É a diferença entre “precisa de muita babá” e “vale receber uma tarefa de verdade.”
Comparativo de Benchmark
Aqui está a comparação compacta que deveria estar em todo documento de avaliação de agentes de programação nesta semana.
| Model | SWE-bench Pro | SWE-bench Verified | Terminal-Bench 2.1 | API price, input/output |
|---|---|---|---|---|
| Claude Opus 4.8 | 69.2% | 88.6% | 74.6% | $5 / $25 per 1M tokens |
| Claude Opus 4.7 | 64.3% | 87.6% | 66.1% | not compared here |
| GPT-5.5 | 58.6% | not listed | 78.2% | $5 / $30 per 1M tokens |
| Gemini 3.1 Pro Preview | 54.2% | 80.6% | 70.3% | $2 / $12 <=200k prompt, $4 / $18 >200k prompt |
As pontuações de benchmark acima vêm da tabela do system card do Opus 4.8 da Anthropic (Anthropic system card PDF). A página de produto da Anthropic diz que o Opus 4.8 foi lançado em 28 de maio de 2026, foi criado para “programação séria e agentes de IA”, suporta uma janela de contexto de 1M e começa em US$ 5 por milhão de tokens de entrada e US$ 25 por milhão de tokens de saída (Anthropic). A OpenAI lista o GPT-5.5 a US$ 5 de entrada e US$ 30 de saída por milhão de tokens, com uma janela de contexto de 1.050.000 tokens e um snapshot gpt-5.5-2026-04-23 (OpenAI). O Google lista o preço do Gemini 3.1 Pro Preview em US$ 2/US$ 12 por milhão de tokens para prompts de até 200k tokens, e US$ 4/US$ 18 acima de 200k (Google AI).
Opus vence o benchmark de reparo de repositórios. GPT-5.5 vence o Terminal-Bench 2.1 nesta tabela. Gemini é mais barato por token, especialmente abaixo do limite de prompt de 200k, mas fica atrás no SWE-bench Pro.
Esse é o formato da decisão.
O Que o SWE-bench Pro Mede de Verdade
SWE-bench Pro não é mais um teste de “escreva uma função a partir de um prompt”. O artigo o descreve como um benchmark com 1.865 problemas em 41 repositórios mantidos ativamente, incluindo aplicações de negócio, serviços B2B e ferramentas para desenvolvedores (arXiv). Ele divide as tarefas em um conjunto público, um conjunto reservado e um conjunto comercial construído a partir de repositórios privados de startups.
O detalhe importante é o formato da tarefa. Os problemas do SWE-bench Pro são tarefas de engenharia de software de horizonte longo. Os autores dizem que elas podem levar horas ou dias para um engenheiro profissional, frequentemente exigem patches em vários arquivos e incluem mudanças substanciais de código (arXiv). O benchmark também filtra edições triviais. O artigo relata soluções de referência com média de 107,4 linhas em 4,1 arquivos.
Isso chega mais perto do trabalho que desenvolvedores passam para agentes:
git grep "billing status"
npm test -- --runInBand
git diff
pytest tests/billing/test_invoices.pyA parte difícil não é produzir código sintaticamente válido. É descobrir qual camada é dona do bug, ler código suficiente ao redor, editar sem quebrar comportamentos adjacentes e usar a saída dos testes para corrigir o rumo.
SWE-bench Verified ainda tem valor, mas o topo está ficando lotado. A tabela da Anthropic coloca o Opus 4.8 em 88,6% e o Opus 4.7 em 87,6% no SWE-bench Verified. Uma diferença de um ponto não basta para escolher um modelo para trabalho autônomo caro em repositórios. No SWE-bench Pro, a diferença entre Opus 4.8 e Opus 4.7 é de 4,9 pontos. Contra GPT-5.5, é de 10,6 pontos. Contra Gemini 3.1 Pro, é de 15,0 pontos.
Isso é sinal.
Desempenho por Dólar É Mais Complicado Que o Preço de Tabela
Preço de token ainda importa. Agentes têm fome. Uma única execução real em repositório pode incluir um contexto inicial longo, leituras repetidas de arquivos, logs de teste, patches fracassados, resumos e tokens ocultos de raciocínio ou pensamento, dependendo da cobrança do provedor.
Para um cálculo aproximado e comparável, pegue uma execução hipotética de programação com contexto longo, com 800k tokens de entrada e 200k tokens de saída. Isso não é uma carga de trabalho universal; é só uma forma limpa de comparar preços de API listados para uma tarefa grande em repositório.
| Model | Pricing assumption | Cost for 800k in / 200k out | SWE-bench Pro | Score points per $ |
|---|---|---|---|---|
| Claude Opus 4.8 | $5 in / $25 out | $9.00 | 69.2 | 7.69 |
| GPT-5.5 | $5 in / $30 out | $10.00 | 58.6 | 5.86 |
| Gemini 3.1 Pro Preview | >200k prompt: $4 in / $18 out | $6.80 | 54.2 | 7.97 |
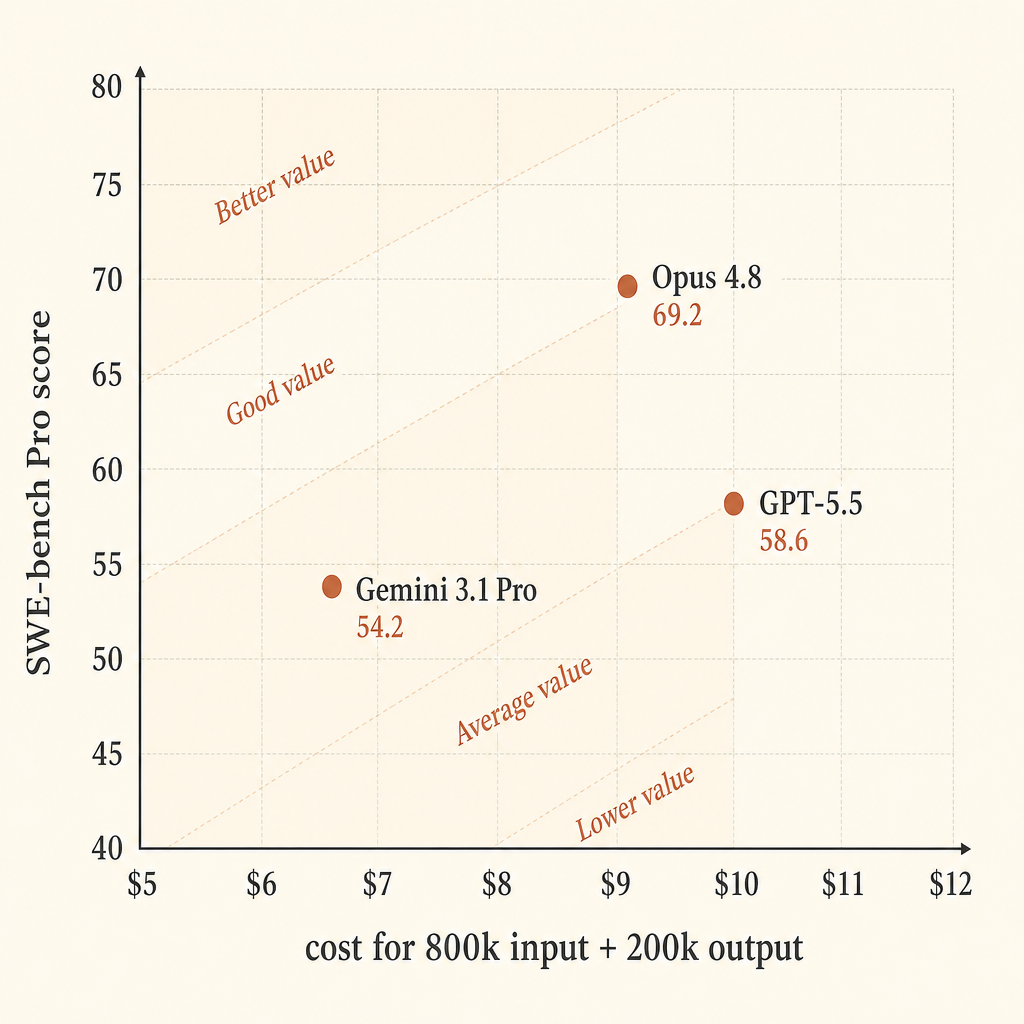
Gemini parece forte em eficiência bruta de preço neste cálculo simplificado. Opus parece o mais forte se você se importa primeiro com taxa de sucesso. GPT-5.5 é o meio caro neste recorte exato: preço de saída maior que o do Opus, pontuação menor no SWE-bench Pro, mas a melhor pontuação no Terminal-Bench 2.1 na tabela da Anthropic.
Para programação autônoma, eu não otimizaria só por “pontos de benchmark por dólar”. Uma execução fracassada de agente não é só a conta de tokens. Também é tempo de revisão, troca de contexto, patches ruins, prompts de acompanhamento instáveis e o custo de rodar o ciclo inteiro de novo. Se a taxa de sucesso maior do Opus 4.8 se traduzir em menos reinícios no seu codebase, a diferença de US$ 2,20 contra o Gemini na execução hipotética pode sumir rápido.
O jeito justo de decidir é rodar seu próprio harness de repositório:
agent-eval run \
--model claude-opus-4-8 \
--tasks evals/repo_tasks.jsonl \
--max-cost-usd 50 \
--record patches,tests,tokensAcompanhe patches aceitos, minutos de revisão humana, custo total e taxa de rollback. Pontuações de benchmark devem escolher sua shortlist. Seu repositório deve escolher produção.
Por Que o Opus 4.8 Vence Neste Sinal Específico
A história do Opus 4.8 não é “Claude é melhor em código” de forma genérica. Isso é amplo demais e costuma ser falso em pelo menos um benchmark. A afirmação mais precisa é esta: na configuração de SWE-bench Pro reportada pela Anthropic, o Opus 4.8 está à frente em resolução autônoma de issues em repositórios.
Isso se traduz em três forças práticas.
Primeiro, ele tem espaço acima do teto fácil. SWE-bench Verified é útil, mas quando os modelos já estão na casa dos 80 e tantos, pequenas diferenças ficam ruidosas para decisões de compra. SWE-bench Pro abre a distância de novo.
Segundo, ele estressa comportamento em escala de repositório. O artigo do SWE-bench Pro destaca resistência a contaminação, codebases comerciais/privados, mudanças em vários arquivos, verificação humana e tarefas em estilo enterprise (arXiv). Isso fica mais perto de “corrija esta regressão no nosso serviço de billing” do que de “complete esta função em Python.”
Terceiro, a Anthropic posicionou o Opus 4.8 em torno de programação de longa duração e agentes, não só chat. A página do Opus diz que o modelo está disponível no Claude Code e na API, suporta contexto de 1M e é voltado a programação complexa, fluxos agentic e trabalho profissional (Anthropic). Linguagem de marketing não é prova, mas a tabela de benchmark está alinhada com a direção do produto.
Como Eu Escolheria um Modelo para Agentes de Repositório
Se seu agente faz edições superficiais, snippets de código ou autocomplete em IDE, SWE-bench Pro não deve ser sua única lente. Latência, qualidade de streaming, integração com ferramentas locais e preço vão importar mais.
Se seu agente deve assumir tarefas de repositório de ponta a ponta, comece com este ranking:
- Use Claude Opus 4.8 como baseline de qualidade para trabalho autônomo difícil em repositórios.
- Teste GPT-5.5 quando execução de tarefas pesadas no terminal importar, já que a tabela da Anthropic dá a ele a liderança no Terminal-Bench 2.1.
- Teste Gemini 3.1 Pro Preview quando a pressão de custo for alta e suas tarefas ficarem abaixo dos limites de custo de falha.
- Mantenha um modelo mais barato no loop para triagem, resumos de busca em arquivos e edições de baixo risco.
O padrão de produção mais confiável não é um modelo gigante para tudo. Use um modelo rápido e mais barato para classificar issues e coletar contexto. Escale o patch difícil para o Opus 4.8. Rode testes. Use um segundo modelo, às vezes GPT-5.5 ou Gemini, como revisor do diff final. Só envie quando a suíte de testes e o revisor humano concordarem.
Isso soa menos mágico do que “engenheiro autônomo”. Ótimo. Também é assim que equipes evitam acordar com um patch lindo que quebrou auth.
O Resumo Final
A pontuação de 69,2% do Claude Opus 4.8 no SWE-bench Pro é um sinal melhor para desenvolvedores do que mais um número alto no SWE-bench Verified. Ela mede algo mais próximo do trabalho que agentes deveriam fazer: navegação em repositório, mudanças em vários arquivos, reparo guiado por testes e execução de horizonte longo.
Opus 4.8 não é o modelo mais barato da comparação. Ele também não vence todos os benchmarks na própria tabela da Anthropic. Mas, para trabalho autônomo em repositórios, a vantagem no SWE-bench Pro é grande o bastante para torná-lo o primeiro modelo que eu avaliaria.
Use os números públicos para montar a shortlist. Depois rode suas próprias tarefas, meça patches aceitos por dólar e inclua tempo de revisão humana no custo. É aí que vitórias em benchmark viram alavanca de engenharia ou desaparecem.
Leitores que quiserem testar Claude Fable 5 por conta própria podem usá-lo pela OneHop: um endpoint drop-in, cerca de 30% abaixo do preço de tabela, com US$ 10 grátis para novas contas e sem cartão obrigatório. Veja Claude Fable 5 on OneHop ou comece com US$ 10 grátis.
Leitura complementar: Primeiros passos com Claude Fable 5.

