
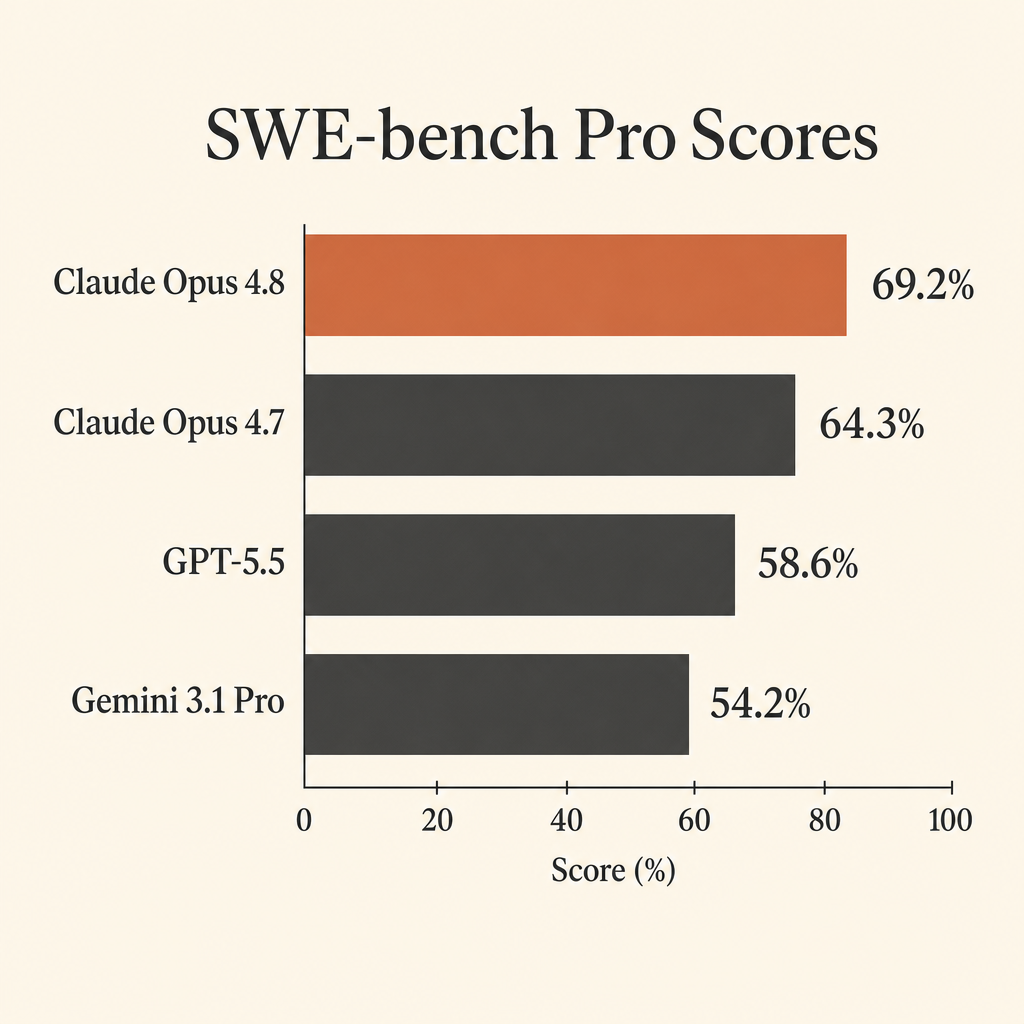
Claude Opus 4.8’in kodlama tarafındaki en işe yarar sayısı, neredeyse tavana vurmuş SWE-bench Verified skoru değil. SWE-bench Pro’daki %69,2 skoru.
Bu önemli, çünkü SWE-bench Pro geliştiricilerin otonom ajanlardan gerçekten istediği iş türü için tasarlandı: gerçek bir repository açmak, sorunu anlamak, birden fazla dosyayı düzenlemek, testleri çalıştırmak, hatalı varsayımlardan geri dönmek ve çalışan bir patch çıkarmak. Anthropic’in Claude Opus 4.8 system card’ında Opus 4.8, SWE-bench Pro’da %69,2 alıyor; GPT-5.5’in %58,6’sının ve Gemini 3.1 Pro’nun %54,2’sinin önünde (Anthropic system card PDF).
Bu fark, agentic coding için model seçimini değiştirecek kadar büyük. Bir modele repo bağlamı, tool call’lar, test hataları ve uzun onarım döngüleri tükettiriyorsanız, on puanlık benchmark farkı önemsiz bir detay değildir. “Sürekli başında durmak gerekiyor” ile “gerçek bir iş vermeye değer” arasındaki farktır.
Benchmark Karşılaştırması
Bu hafta her coding-agent değerlendirme dokümanında olması gereken kısa karşılaştırma şu.
| Model | SWE-bench Pro | SWE-bench Verified | Terminal-Bench 2.1 | API fiyatı, input/output |
|---|---|---|---|---|
| Claude Opus 4.8 | 69.2% | 88.6% | 74.6% | 1M token başına $5 / $25 |
| Claude Opus 4.7 | 64.3% | 87.6% | 66.1% | burada karşılaştırılmadı |
| GPT-5.5 | 58.6% | listelenmemiş | 78.2% | 1M token başına $5 / $30 |
| Gemini 3.1 Pro Preview | 54.2% | 80.6% | 70.3% | <=200k prompt için $2 / $12, >200k prompt için $4 / $18 |
Yukarıdaki benchmark skorları Anthropic’in Opus 4.8 system card tablosundan geliyor (Anthropic system card PDF). Anthropic’in ürün sayfası, Opus 4.8’in 28 Mayıs 2026’da çıktığını, “ciddi kodlama ve AI ajanları” için üretildiğini, 1M context window desteklediğini ve milyon input token başına $5, milyon output token başına $25’ten başladığını söylüyor (Anthropic). OpenAI, GPT-5.5’i milyon token başına $5 input ve $30 output olarak listeliyor; 1.050.000 token context window ve gpt-5.5-2026-04-23 snapshot’ı ile (OpenAI). Google ise Gemini 3.1 Pro Preview fiyatını 200k token’a kadar prompt’lar için milyon token başına $2/$12, 200k üzeri için $4/$18 olarak veriyor (Google AI).
Repo-onarım benchmark’ını Opus kazanıyor. Bu tabloda Terminal-Bench 2.1’i GPT-5.5 kazanıyor. Gemini token başına daha ucuz, özellikle 200k prompt eşiğinin altında, ama SWE-bench Pro’da geride kalıyor.
Kararın şekli bu.
SWE-bench Pro Aslında Neyi Ölçüyor
SWE-bench Pro başka bir “prompt’tan fonksiyon yaz” testi değil. Makale bunu, aktif olarak bakımı yapılan 41 repository genelinde 1.865 problemi kapsayan; iş uygulamaları, B2B servisleri ve geliştirici araçlarını içeren bir benchmark olarak tanımlıyor (arXiv). Görevleri herkese açık bir set, saklı tutulan bir set ve özel startup repository’lerinden oluşturulmuş ticari bir set olarak ayırıyor.
Önemli detay görevlerin biçimi. SWE-bench Pro problemleri uzun ufuklu yazılım mühendisliği görevleri. Yazarlar bunların profesyonel bir mühendisin saatlerini ya da günlerini alabileceğini, çoğu zaman birden fazla dosyada patch gerektirdiğini ve ciddi kod değişiklikleri içerdiğini söylüyor (arXiv). Benchmark ayrıca önemsiz düzenlemeleri de filtreliyor. Makale, referans çözümlerin ortalama 4,1 dosyada 107,4 satır olduğunu bildiriyor.
Bu, geliştiricilerin ajanlara verdiği işe daha yakın:
git grep "billing status"
npm test -- --runInBand
git diff
pytest tests/billing/test_invoices.pyZor kısım sözdizimsel olarak geçerli kod üretmek değil. Hatanın hangi katmana ait olduğunu anlamak, etraftaki kodu yeterince okumak, yan davranışları bozmadan düzenleme yapmak ve test çıktısını kullanarak rotayı düzeltmek.
SWE-bench Verified hâlâ değerli, ama tepe tarafı kalabalıklaşıyor. Anthropic’in tablosu Opus 4.8’i SWE-bench Verified’da %88,6, Opus 4.7’yi %87,6 gösteriyor. Bir puanlık fark, pahalı otonom repo işi için model seçmeye yetmez. SWE-bench Pro’da Opus 4.8 ile Opus 4.7 arasındaki fark 4,9 puan. GPT-5.5’e karşı 10,6 puan. Gemini 3.1 Pro’ya karşı 15,0 puan.
Sinyal budur.
Dolar Başına Performans Etiket Fiyatından Daha Karmaşık
Token fiyatı hâlâ önemli. Ajanlar açtır. Tek bir gerçek repo çalışması bile uzun bir başlangıç bağlamı, tekrar tekrar dosya okumaları, test logları, başarısız patch’ler, özetler ve sağlayıcının faturalamasına bağlı olarak gizli akıl yürütme ya da düşünme token’ları içerebilir.
Kabaca elma elma bir rakam için, 800k input token ve 200k output token içeren varsayımsal bir uzun bağlamlı kodlama çalışması düşünün. Bu evrensel bir iş yükü değil; sadece büyük bir repo görevi için listelenen API fiyatlarını karşılaştırmanın temiz bir yolu.
| Model | Fiyat varsayımı | 800k in / 200k out maliyeti | SWE-bench Pro | $ başına skor puanı |
|---|---|---|---|---|
| Claude Opus 4.8 | $5 in / $25 out | $9.00 | 69.2 | 7.69 |
| GPT-5.5 | $5 in / $30 out | $10.00 | 58.6 | 5.86 |
| Gemini 3.1 Pro Preview | >200k prompt: $4 in / $18 out | $6.80 | 54.2 | 7.97 |
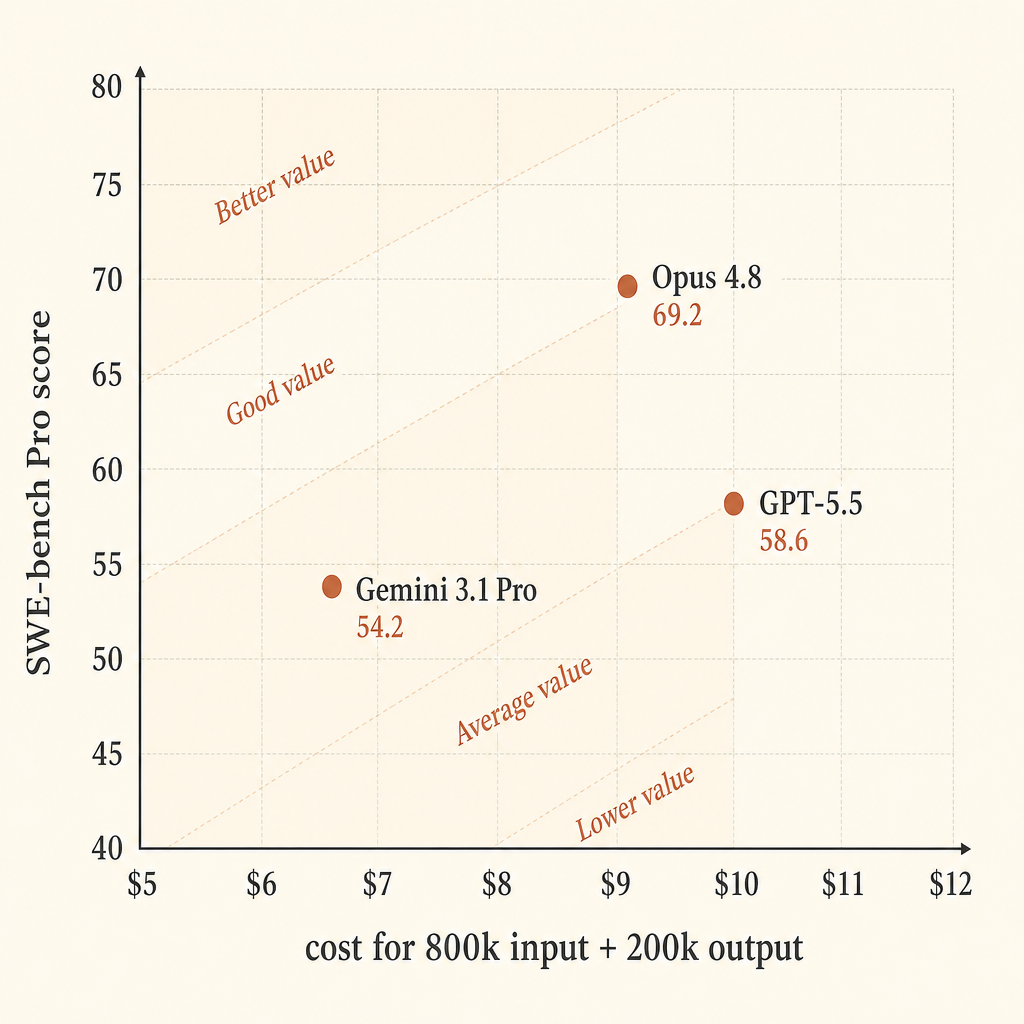
Gemini bu basitleştirilmiş hesapta ham fiyat verimliliği açısından güçlü görünüyor. Önceliğiniz geçme oranıysa Opus en güçlü görünüyor. Bu tam kesitte GPT-5.5 pahalı orta nokta: Opus’tan daha yüksek output fiyatı, daha düşük SWE-bench Pro skoru, ama Anthropic’in tablosundaki en iyi Terminal-Bench 2.1 skoru.
Otonom kodlama için sadece “dolar başına benchmark puanı”na göre optimizasyon yapmazdım. Başarısız bir ajan çalışması sadece token faturası değildir. Aynı zamanda inceleme süresi, bağlam değiştirme, kötü patch’ler, sorunlu takip prompt’ları ve tüm döngüyü yeniden çalıştırmanın maliyetidir. Opus 4.8’in daha yüksek geçme oranı sizin codebase’inizde daha az yeniden başlatmaya dönüşüyorsa, varsayımsal çalışmadaki Gemini’ye karşı $2,20 fark hızla eriyebilir.
Karar vermenin adil yolu kendi repo harness’inizi çalıştırmak:
agent-eval run \
--model claude-opus-4-8 \
--tasks evals/repo_tasks.jsonl \
--max-cost-usd 50 \
--record patches,tests,tokensKabul edilen patch’leri, insan inceleme dakikalarını, toplam maliyeti ve rollback oranını takip edin. Benchmark skorları kısa listenizi seçmeli. Üretim için seçimi repository’niz yapmalı.
Opus 4.8 Bu Sinyalde Neden Kazanıyor
Opus 4.8 hikâyesi genel anlamda “Claude kodda daha iyi” değil. Bu fazla geniş ve genelde en az bir benchmark için yanlış. Daha keskin iddia şu: Anthropic’in raporladığı SWE-bench Pro kurulumunda Opus 4.8, otonom repository issue çözümünde önde.
Bu, üç pratik güce denk düşüyor.
Birincisi, kolay tavanın üstünde alanı var. SWE-bench Verified faydalı, ama modeller zaten yüksek 80’lerdeyken küçük farklar alıcı kararları için gürültülü hale geliyor. SWE-bench Pro farkı yeniden açıyor.
İkincisi, repo ölçeğinde davranışı zorluyor. SWE-bench Pro makalesi contamination direnci, ticari/özel codebase’ler, çok dosyalı değişiklikler, insan doğrulaması ve enterprise tarzı görevleri özellikle vurguluyor (arXiv). Bu, “şu Python fonksiyonunu tamamla”dan çok “billing servisimizdeki şu regression’ı düzelt”e daha yakın.
Üçüncüsü, Anthropic Opus 4.8’i sadece chat etrafında değil, uzun süreli kodlama ve ajanlar etrafında konumlandırdı. Opus sayfası modelin Claude Code ve API içinde mevcut olduğunu, 1M context desteklediğini ve karmaşık kodlama, agentic workflow’lar ve profesyonel işler için tasarlandığını söylüyor (Anthropic). Pazarlama dili kanıt değildir, ama benchmark tablosu ürün yönüyle uyumlu.
Repo Ajanları İçin Modeli Nasıl Seçerdim
Ajanınız yüzeysel düzenlemeler, kod parçacıkları veya IDE autocomplete yapıyorsa, SWE-bench Pro tek merceğiniz olmamalı. Gecikme, streaming kalitesi, yerel araç entegrasyonu ve fiyat daha çok önem kazanır.
Ajanınızdan repo görevlerini baştan sona üstlenmesi bekleniyorsa, şu sıralamayla başlayın:
- Zor otonom repo işleri için kalite baseline’ı olarak Claude Opus 4.8 kullanın.
- Terminal ağırlıklı görev yürütme önemliyse GPT-5.5’i test edin; Anthropic’in tablosu Terminal-Bench 2.1 liderliğini ona veriyor.
- Maliyet baskısı yüksekse ve görevleriniz failure-cost eşiklerinin altında kalıyorsa Gemini 3.1 Pro Preview’ı test edin.
- Triage, dosya arama özetleri ve düşük riskli düzenlemeler için döngüde daha ucuz bir model tutun.
En güvenilir production deseni her şey için tek dev model kullanmak değil. Issue’ları sınıflandırmak ve bağlam toplamak için hızlı, daha ucuz bir model kullanın. Zor patch’i Opus 4.8’e yükseltin. Testleri çalıştırın. Final diff için ikinci bir modeli, bazen GPT-5.5 ya da Gemini’yi reviewer olarak kullanın. Sadece test suite ve insan reviewer aynı fikirde olduğunda ship edin.
Bu “otonom mühendis” lafından daha az büyülü geliyor. Güzel. Takımların auth’u bozan harika görünümlü bir patch’e uyanmamasını sağlayan şey de bu.
Sonuç
Claude Opus 4.8’in %69,2 SWE-bench Pro skoru, bir başka yüksek SWE-bench Verified sayısından daha iyi bir geliştirici sinyali. Ajanların yapması beklenen işe daha yakın şeyi ölçüyor: repo navigasyonu, çok dosyalı değişiklikler, test odaklı onarım ve uzun ufuklu yürütme.
Opus 4.8 bu karşılaştırmadaki en ucuz model değil. Anthropic’in kendi tablosundaki her benchmark’ı da kazanmıyor. Ama otonom repo işi için SWE-bench Pro farkı, değerlendirmeye ilk alacağım model yapacak kadar büyük.
Kısa listeyi oluşturmak için herkese açık sayıları kullanın. Sonra kendi görevlerinizi çalıştırın, dolar başına kabul edilen patch’leri ölçün ve insan inceleme süresini maliyete dahil edin. Benchmark galibiyetlerinin mühendislik kaldıracına dönüşüp dönüşmediği ya da buhar olup uçtuğu yer burası.
Claude Fable 5’i kendileri denemek isteyen okurlar OneHop üzerinden kullanabilir: drop-in endpoint, liste fiyatının yaklaşık %30 altında, yeni hesaplar için $10 ücretsiz ve kart gerekmiyor. OneHop’ta Claude Fable 5 veya $10 ücretsiz başlayın.
Ek okuma: Claude Fable 5 ile başlangıç.

