
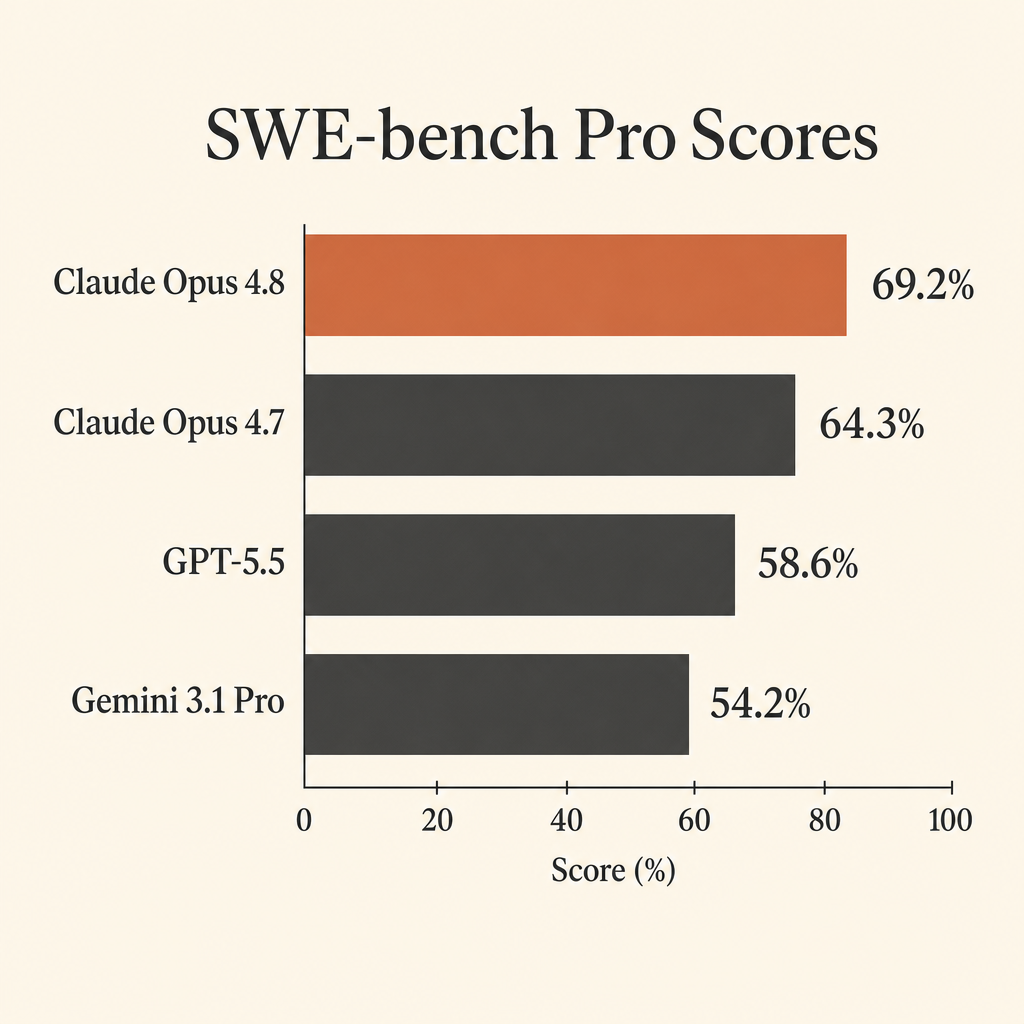
Claude Opus 4.8でいちばん使えるコーディング指標は、ほぼ飽和状態に近いSWE-bench Verifiedのスコアではない。SWE-bench Proでの69.2%だ。
これが重要なのは、SWE-bench Proが、開発者が自律エージェントに実際にやってほしい仕事のために作られているからだ。実リポジトリを開き、issueを理解し、複数ファイルを編集し、テストを走らせ、誤った前提から立て直し、パッチを出す。AnthropicのClaude Opus 4.8システムカードでは、Opus 4.8はSWE-bench Proで69.2%を記録し、GPT-5.5の58.6%、Gemini 3.1 Proの54.2%を上回っている(Anthropic system card PDF)。
この差は、エージェント型コーディングでどのモデルを選ぶかを変えるには十分に大きい。リポジトリのコンテキスト、ツール呼び出し、テスト失敗、長い修復ループにモデルを投入して料金を払うなら、10ポイントのベンチマーク差は豆知識ではない。「かなり面倒を見る必要がある」と「本物のタスクを任せる価値がある」の違いだ。
ベンチマーク比較 (Benchmark)
今週、すべてのコーディングエージェント評価ドキュメントに載せるべきコンパクトな比較がこれだ。
| モデル | SWE-bench Pro | SWE-bench Verified | Terminal-Bench 2.1 | API価格、入力/出力 |
|---|---|---|---|---|
| Claude Opus 4.8 | 69.2% | 88.6% | 74.6% | 100万トークンあたり$5 / $25 |
| Claude Opus 4.7 | 64.3% | 87.6% | 66.1% | ここでは比較対象外 |
| GPT-5.5 | 58.6% | 記載なし | 78.2% | 100万トークンあたり$5 / $30 |
| Gemini 3.1 Pro Preview | 54.2% | 80.6% | 70.3% | 200k以下のプロンプトは$2 / $12、200k超のプロンプトは$4 / $18 |
上のベンチマークスコアは、AnthropicのOpus 4.8システムカード表から来ている(Anthropic system card PDF)。Anthropicの製品ページによると、Opus 4.8は2026年5月28日に公開され、「本格的なコーディングとAIエージェント」向けに作られ、1Mコンテキストウィンドウをサポートし、入力100万トークンあたり$5、出力100万トークンあたり$25から始まる(Anthropic)。OpenAIはGPT-5.5を入力100万トークンあたり$5、出力100万トークンあたり$30、コンテキストウィンドウ1,050,000トークン、gpt-5.5-2026-04-23スナップショットとして掲載している(OpenAI)。GoogleはGemini 3.1 Pro Previewの価格を、200kトークンまでのプロンプトでは100万トークンあたり$2/$12、200k超では$4/$18としている(Google AI)。
リポジトリ修復ベンチマークではOpusが勝つ。この表ではTerminal-Bench 2.1でGPT-5.5が勝つ。Geminiはトークン単価が安く、特に200kプロンプトのしきい値未満では有利だが、SWE-bench Proでは後れを取っている。
意思決定の形は、こういうことだ。
SWE-bench Proが実際に測っているもの
SWE-bench Proは、また別の「プロンプトから関数を書く」テストではない。論文では、活発にメンテナンスされている41のリポジトリにまたがる1,865問のベンチマークとして説明されており、ビジネスアプリケーション、B2Bサービス、開発者ツールが含まれる(arXiv)。タスクは公開セット、ホールドアウトセット、そしてスタートアップの非公開リポジトリから作られた商用セットに分かれている。
重要なのはタスクの形だ。SWE-bench Proの問題は、長い時間軸のソフトウェアエンジニアリングタスクである。著者らは、プロのエンジニアでも数時間から数日かかる場合があり、複数ファイルにまたがるパッチや相当量のコード変更が必要になることが多いと述べている(arXiv)。このベンチマークは、些末な編集も除外している。論文によれば、参照解の平均は4.1ファイルにまたがる107.4行だ。
これは、開発者がエージェントに渡す仕事にかなり近い。
git grep "billing status"
npm test -- --runInBand
git diff
pytest tests/billing/test_invoices.py難しいのは、構文的に正しいコードを出すことではない。バグの責任を持つレイヤーを見極め、周辺コードを十分に読み、隣接する挙動を壊さずに編集し、テスト出力を使って軌道修正することだ。
SWE-bench Verifiedにはまだ価値があるが、上位は混み合ってきている。Anthropicの表では、SWE-bench VerifiedでOpus 4.8が88.6%、Opus 4.7が87.6%だ。1ポイント差では、高価な自律リポジトリ作業に使うモデルを選ぶには足りない。SWE-bench Proでは、Opus 4.8とOpus 4.7の差は4.9ポイント。GPT-5.5に対しては10.6ポイント。Gemini 3.1 Proに対しては15.0ポイントだ。
これはシグナルだ。
ドルあたり性能は表示価格ほど単純ではない
トークン価格はなお重要だ。エージェントは大食いだ。実リポジトリでの1回の実行には、長い初期コンテキスト、繰り返されるファイル読み取り、テストログ、失敗したパッチ、要約、そしてプロバイダーの課金方式によっては隠れた推論または思考トークンが含まれることがある。
ざっくりした同条件比較として、入力800kトークン、出力200kトークンの仮想的な長コンテキストのコーディング実行を考える。これは普遍的なワークロードではない。大きめのリポジトリタスクについて、掲載されているAPI価格を比較するためのきれいな切り口にすぎない。
| モデル | 価格前提 | 800k入力 / 200k出力のコスト | SWE-bench Pro | $あたりスコアポイント |
|---|---|---|---|---|
| Claude Opus 4.8 | 入力$5 / 出力$25 | $9.00 | 69.2 | 7.69 |
| GPT-5.5 | 入力$5 / 出力$30 | $10.00 | 58.6 | 5.86 |
| Gemini 3.1 Pro Preview | 200k超プロンプト:入力$4 / 出力$18 | $6.80 | 54.2 | 7.97 |
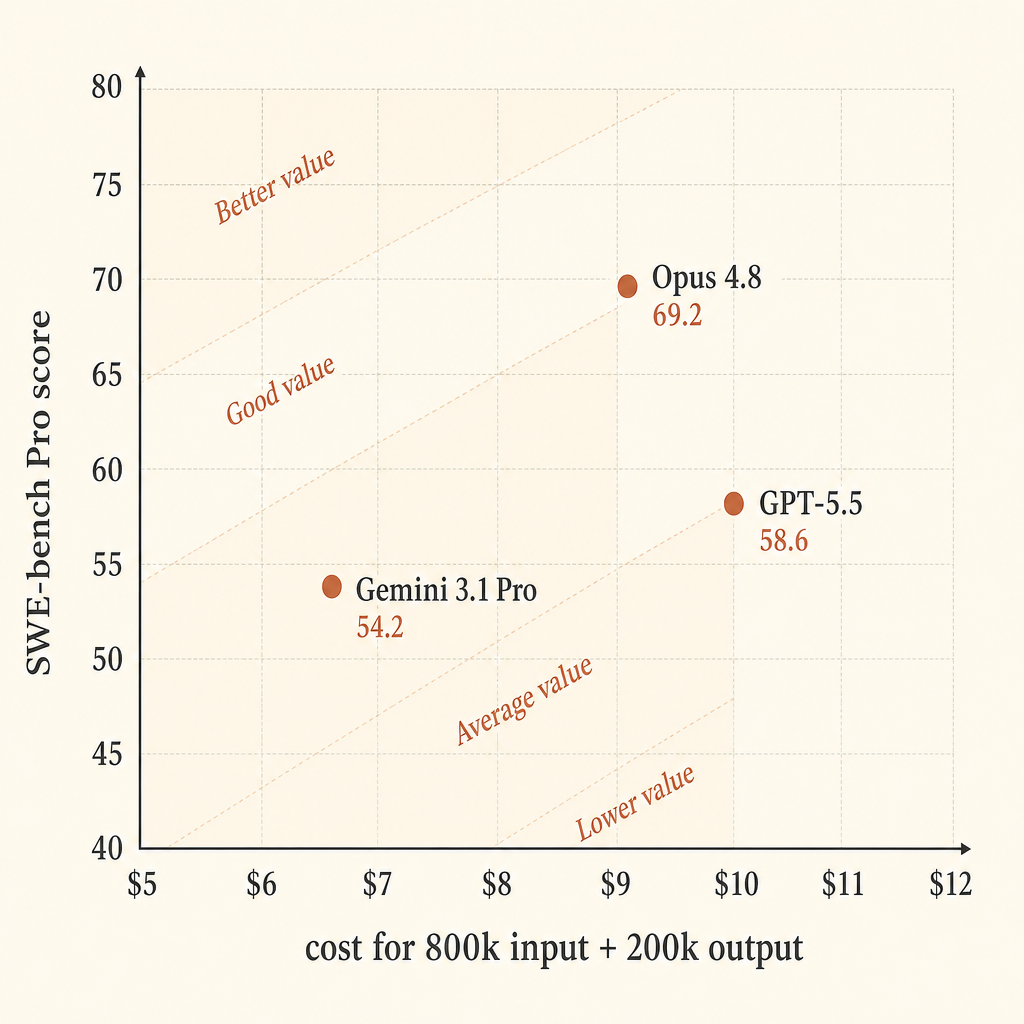
この単純化した計算では、Geminiは素の価格効率で強く見える。合格率を最優先するなら、Opusが最も強く見える。GPT-5.5はこの正確な切り口では高価な中間だ。出力価格はOpusより高く、SWE-bench Proスコアは低いが、Anthropicの表ではTerminal-Bench 2.1のスコアが最も高い。
自律コーディングでは、「ベンチマークポイントあたりのドル」だけで最適化するつもりはない。失敗したエージェント実行のコストは、トークン代だけではない。レビュー時間、コンテキストスイッチ、悪いパッチ、不安定な追加プロンプト、ループ全体をやり直すコストもある。Opus 4.8の高い合格率があなたのコードベースで再実行の少なさにつながるなら、仮想実行におけるGeminiとの差$2.20はすぐに消える。
公平な決め方は、自分のリポジトリ用ハーネスを走らせることだ。
agent-eval run \
--model claude-opus-4-8 \
--tasks evals/repo_tasks.jsonl \
--max-cost-usd 50 \
--record patches,tests,tokens採用されたパッチ、人間のレビュー分数、総コスト、ロールバック率を追跡する。ベンチマークスコアは候補リストを選ぶためのものだ。本番投入するモデルは、あなたのリポジトリが選ぶべきだ。
なぜOpus 4.8はこの指標で勝つのか
Opus 4.8の話は、一般論として「Claudeはコードが得意」ということではない。それは広すぎるし、たいてい少なくとも1つのベンチマークでは間違いになる。より鋭い主張はこうだ。Anthropicが報告したSWE-bench Proの設定では、Opus 4.8は自律的なリポジトリissue解決で先行している。
これは3つの実務上の強みに対応している。
第一に、簡単な天井の上にまだ差が出る余地がある。SWE-bench Verifiedは有用だが、モデルがすでに80%台後半にいると、小さな差分は購入判断にはノイズになりやすい。SWE-bench Proはもう一度スプレッドを広げてくれる。
第二に、リポジトリ規模の振る舞いに負荷をかける。SWE-bench Proの論文は、汚染耐性、商用/非公開コードベース、複数ファイル変更、人間による検証、エンタープライズ風タスクを強調している(arXiv)。これは「このPython関数を完成させて」よりも、「うちの課金サービスのこのリグレッションを直して」に近い。
第三に、AnthropicはOpus 4.8を単なるチャットではなく、長時間のコーディングとエージェント向けに位置づけている。Opusページによると、このモデルはClaude CodeとAPIで利用でき、1Mコンテキストをサポートし、複雑なコーディング、エージェント型ワークフロー、プロフェッショナルな作業を意図している(Anthropic)。マーケティング文言は証明ではないが、ベンチマーク表はその製品方向性と揃っている。
リポジトリエージェント用モデルを私ならどう選ぶか
エージェントが浅い編集、コードスニペット、IDEのオートコンプリートを行うだけなら、SWE-bench Proだけを見るべきではない。レイテンシ、ストリーミング品質、ローカルツール連携、価格のほうが重要になる。
エージェントにリポジトリタスクをエンドツーエンドで任せるなら、この順位から始める。
- 難しい自律リポジトリ作業の品質基準としてClaude Opus 4.8を使う。
- ターミナル重視のタスク実行が重要ならGPT-5.5をテストする。Anthropicの表ではTerminal-Bench 2.1でリードしているからだ。
- コスト圧力が高く、タスクが失敗コストのしきい値未満に収まるならGemini 3.1 Pro Previewをテストする。
- トリアージ、ファイル検索の要約、低リスク編集には、より安いモデルをループに残す。
本番で最も信頼できるパターンは、すべてに巨大な1モデルを使うことではない。高速で安いモデルにissueの分類とコンテキスト収集をさせる。難しいパッチはOpus 4.8にエスカレーションする。テストを走らせる。最終diffのレビュー役として、場合によってはGPT-5.5やGeminiといった第二のモデルを使う。テストスイートと人間のレビュアーが一致したときだけ出荷する。
「自律エンジニア」より魔法っぽく聞こえない。よいことだ。認証を壊した美しいパッチで朝起こされないために、チームがやっているのもこういうことだ。
結論
Claude Opus 4.8のSWE-bench Pro 69.2%というスコアは、また別の高いSWE-bench Verifiedの数字よりも、開発者にとって優れたシグナルだ。これは、エージェントが本来やるべき仕事により近いものを測っている。リポジトリ探索、複数ファイル変更、テスト駆動の修復、長い時間軸の実行だ。
Opus 4.8は、この比較で最も安いモデルではない。Anthropic自身の表でも、すべてのベンチマークに勝っているわけではない。それでも自律リポジトリ作業では、SWE-bench Proの差は、私なら最初に評価するモデルにするだけの大きさがある。
公開されている数字で候補リストを作る。そのうえで自分のタスクを走らせ、ドルあたりの採用パッチ数を測り、人間のレビュー時間もコストに含める。そこで初めて、ベンチマーク上の勝利がエンジニアリング上のレバレッジになるのか、それとも消えてなくなるのかが分かる。
Claude Fable 5を自分で試したい読者は、OneHop経由で使える。ドロップインのエンドポイントで、定価より約30%安く、新規アカウントには$10分が無料で付与され、カード登録も不要だ。Claude Fable 5 on OneHopまたは$10無料で始めるを参照。

