
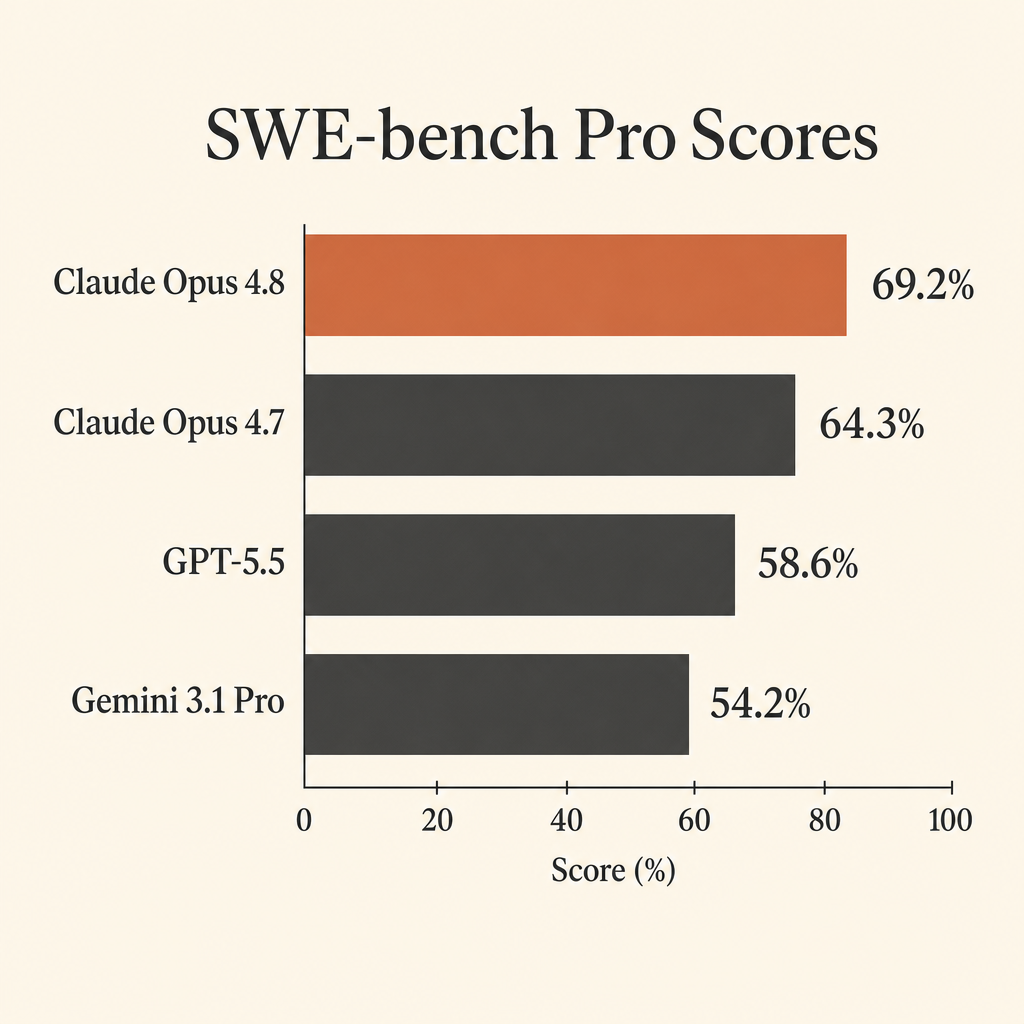
Claude Opus 4.8 最有用的编程指标,不是它在 SWE-bench Verified 上几乎刷满的分数,而是它在 SWE-bench Pro 上的 69.2%。
这很重要,因为 SWE-bench Pro 衡量的正是开发者真正希望自主代理完成的那类工作:打开一个真实代码库,理解问题,修改多个文件,运行测试,从错误假设里爬出来,然后交付补丁。在 Anthropic 的 Claude Opus 4.8 系统卡中,Opus 4.8 在 SWE-bench Pro 上得分 69.2%,领先 GPT-5.5 的 58.6% 和 Gemini 3.1 Pro 的 54.2%(Anthropic system card PDF)。
这个差距大到足以改变 agentic coding 的模型选择。如果你花钱让模型消耗代码库上下文、工具调用、测试失败和漫长的修复循环,10 个百分点的基准差距就不是花边数据。它意味着“需要大量盯着”与“值得交给它一个真实任务”之间的区别。
基准测试对比 (Benchmark)
下面这张紧凑对比表,本周应该出现在每一份 coding-agent 评估文档里。
| 模型 | SWE-bench Pro | SWE-bench Verified | Terminal-Bench 2.1 | API 价格,输入/输出 |
|---|---|---|---|---|
| Claude Opus 4.8 | 69.2% | 88.6% | 74.6% | 每 100 万 tokens $5 / $25 |
| Claude Opus 4.7 | 64.3% | 87.6% | 66.1% | 此处未比较 |
| GPT-5.5 | 58.6% | 未列出 | 78.2% | 每 100 万 tokens $5 / $30 |
| Gemini 3.1 Pro Preview | 54.2% | 80.6% | 70.3% | <=200k prompt 为 $2 / $12,>200k prompt 为 $4 / $18 |
上面的基准分数来自 Anthropic 的 Opus 4.8 系统卡表格(Anthropic system card PDF)。Anthropic 的产品页称,Opus 4.8 于 2026 年 5 月 28 日发布,面向“严肃编程和 AI agents”打造,支持 1M 上下文窗口,价格从每百万输入 tokens $5、每百万输出 tokens $25 起(Anthropic)。OpenAI 列出的 GPT-5.5 价格为每百万 tokens 输入 $5、输出 $30,上下文窗口为 1,050,000 tokens,并提供 gpt-5.5-2026-04-23 快照(OpenAI)。Google 列出的 Gemini 3.1 Pro Preview 价格为:prompt 不超过 200k tokens 时每百万 tokens $2/$12,超过 200k 时为 $4/$18(Google AI)。
Opus 赢下了代码库修复基准。GPT-5.5 在这张表里赢下 Terminal-Bench 2.1。Gemini 的单 token 成本更低,尤其是在 200k prompt 阈值以下,但在 SWE-bench Pro 上落后。
决策的轮廓就是这样。
SWE-bench Pro 实际测的是什么
SWE-bench Pro 不是又一个“根据提示写个函数”的测试。论文把它描述为一个覆盖 41 个活跃维护代码库、共 1,865 个问题的基准,范围包括商业应用、B2B 服务和开发者工具(arXiv)。它把任务拆成公开集、留出集,以及由私有创业公司代码库构建的商业集。
关键在于任务形态。SWE-bench Pro 的问题是长周期软件工程任务。作者表示,这些任务可能需要专业工程师花数小时甚至数天,通常需要跨多个文件打补丁,并包含实质性的代码改动(arXiv)。这个基准还过滤掉了琐碎编辑。论文报告的参考解法平均为 107.4 行,跨 4.1 个文件。
这更接近开发者交给 agents 的工作:
git grep "billing status"
npm test -- --runInBand
git diff
pytest tests/billing/test_invoices.py难点不是生成语法正确的代码。难点是判断哪个层负责这个 bug,阅读足够多的周边代码,在不破坏相邻行为的前提下修改,并利用测试输出纠正方向。
SWE-bench Verified 仍然有价值,但榜首已经很拥挤。Anthropic 的表格显示,Opus 4.8 在 SWE-bench Verified 上为 88.6%,Opus 4.7 为 87.6%。1 个百分点的差距,不足以支撑为昂贵的自主代码库任务选择模型。但在 SWE-bench Pro 上,Opus 4.8 与 Opus 4.7 的差距是 4.9 个百分点。相比 GPT-5.5 是 10.6 个百分点。相比 Gemini 3.1 Pro 是 15.0 个百分点。
这就是信号。
每美元性能比标价更复杂
token 价格仍然重要。Agents 很能吃。一次真实的代码库运行,可能包含很长的初始上下文、反复读文件、测试日志、失败补丁、摘要,以及取决于供应商计费方式的隐藏推理或思考 tokens。
为了做一个粗略的同口径比较,假设一次长上下文编程运行包含 800k 输入 tokens 和 200k 输出 tokens。这不是通用工作负载;只是用来比较大型代码库任务标价 API 的一种干净方式。
| 模型 | 价格假设 | 800k 输入 / 200k 输出成本 | SWE-bench Pro | 每美元得分点 |
|---|---|---|---|---|
| Claude Opus 4.8 | 输入 $5 / 输出 $25 | $9.00 | 69.2 | 7.69 |
| GPT-5.5 | 输入 $5 / 输出 $30 | $10.00 | 58.6 | 5.86 |
| Gemini 3.1 Pro Preview | >200k prompt:输入 $4 / 输出 $18 | $6.80 | 54.2 | 7.97 |
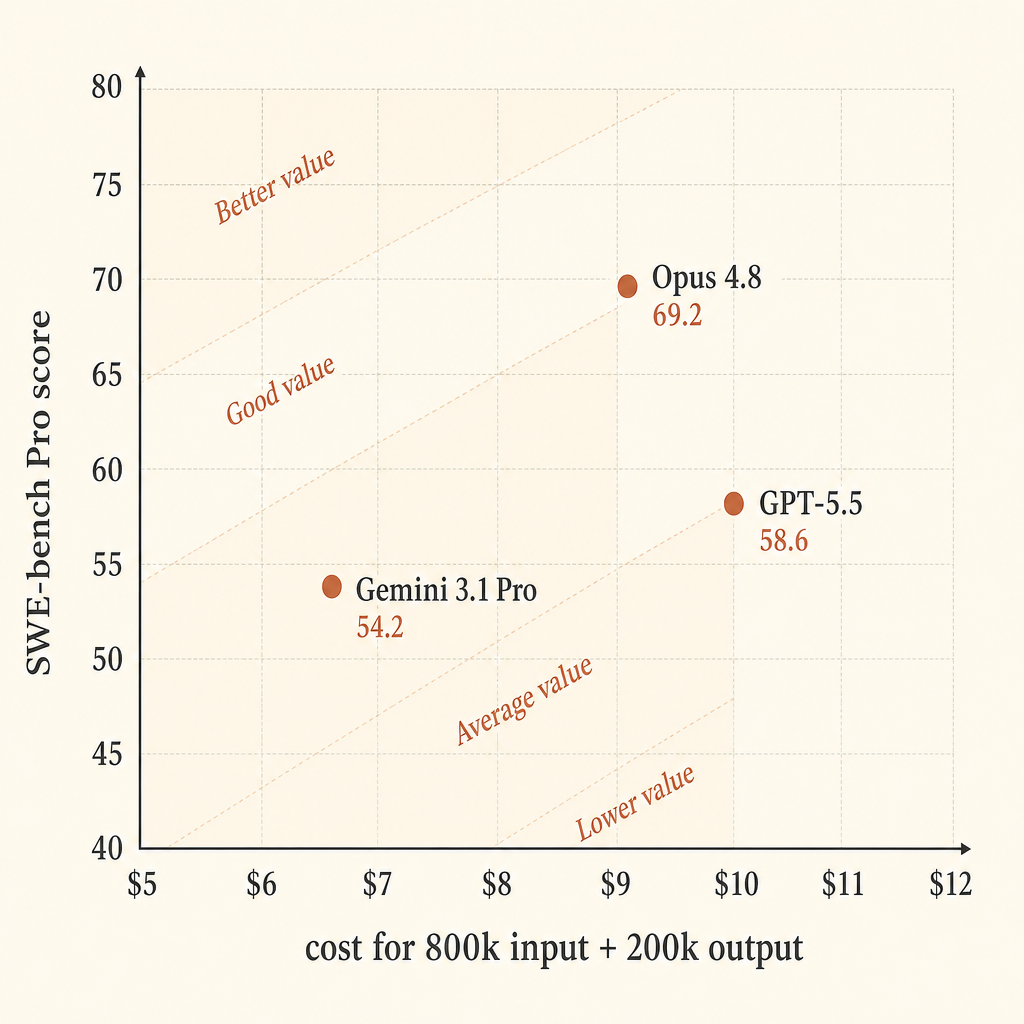
在这个简化计算里,Gemini 的原始价格效率看起来很强。如果你最在意通过率,Opus 看起来最强。GPT-5.5 在这个切片里是昂贵的中间项:输出价格高于 Opus,SWE-bench Pro 分数更低,但在 Anthropic 的表里 Terminal-Bench 2.1 分数最高。
对自主编程来说,我不会只优化“每美元基准得分”。一次失败的 agent 运行不只是 token 账单。它还包括评审时间、上下文切换、糟糕补丁、摇摇欲坠的后续提示,以及重跑整条循环的成本。如果 Opus 4.8 更高的通过率能在你的代码库里转化为更少的重启,那么这个假设运行里相对 Gemini 多出的 $2.20 很快就会消失。
公平的做法是跑你自己的代码库评测框架:
agent-eval run \
--model claude-opus-4-8 \
--tasks evals/repo_tasks.jsonl \
--max-cost-usd 50 \
--record patches,tests,tokens跟踪被接受的补丁、人工评审分钟数、总成本和回滚率。基准分数应该决定你的候选名单。你的代码库才应该决定生产选择。
为什么 Opus 4.8 赢下这个特定信号
Opus 4.8 的故事不是泛泛地说“Claude 更擅长代码”。这种说法太宽,而且通常至少会在某个基准上被打脸。更精准的说法是:在 Anthropic 报告的 SWE-bench Pro 设置下,Opus 4.8 在自主解决代码库 issue 上领先。
这对应三个实际优势。
第一,它在简单天花板之上还有区分度。SWE-bench Verified 很有用,但当模型已经都在 80 多分后段时,微小差异对采购决策会变得嘈杂。SWE-bench Pro 重新拉开了差距。
第二,它压测的是代码库规模的行为。SWE-bench Pro 论文明确提到抗污染、商业/私有代码库、多文件改动、人工验证和企业风格任务(arXiv)。这更接近“修一下我们计费服务里的这个回归”,而不是“补全这个 Python 函数”。
第三,Anthropic 对 Opus 4.8 的定位围绕长时间运行的编程和 agents,而不只是聊天。它的 Opus 页面称,该模型可在 Claude Code 和 API 中使用,支持 1M 上下文,并面向复杂编程、agentic workflows 和专业工作(Anthropic)。营销语言不是证据,但基准表与产品方向是对齐的。
我会如何为代码库 Agents 选模型
如果你的 agent 做的是浅层编辑、代码片段或 IDE 自动补全,SWE-bench Pro 不该是唯一视角。延迟、流式输出质量、本地工具集成和价格会更重要。
如果你的 agent 被期望端到端接管代码库任务,从这个排序开始:
- 把 Claude Opus 4.8 作为高难度自主代码库工作的质量基线。
- 当任务执行高度依赖终端时,测试 GPT-5.5,因为 Anthropic 的表格显示它在 Terminal-Bench 2.1 上领先。
- 当成本压力很高,且你的任务低于失败成本阈值时,测试 Gemini 3.1 Pro Preview。
- 在循环里保留一个更便宜的模型,用于分诊、文件搜索摘要和低风险编辑。
最可靠的生产模式,不是用一个巨型模型包打一切。用一个快而便宜的模型来分类 issue、收集上下文。把困难补丁升级给 Opus 4.8。运行测试。再用第二个模型,有时是 GPT-5.5 或 Gemini,来评审最终 diff。只有当测试套件和人工评审都同意时才发出去。
这听起来没有“自主工程师”那么魔法。很好。这也是团队避免一觉醒来发现漂亮补丁把 auth 搞坏的办法。
结论
Claude Opus 4.8 的 69.2% SWE-bench Pro 分数,比另一个高 SWE-bench Verified 分数更能说明开发者关心的问题。它衡量的更接近 agents 本应完成的工作:代码库导航、多文件改动、测试驱动修复和长周期执行。
Opus 4.8 不是这次对比里最便宜的模型。它也没有赢下 Anthropic 自己表格里的每一个基准。但对自主代码库工作来说,SWE-bench Pro 上的差距已经大到足以让它成为我会第一个评估的模型。
用公开数据建立候选名单。然后跑你自己的任务,衡量每美元被接受补丁数,并把人工评审时间计入成本。基准胜利要么在这里变成工程杠杆,要么在这里消失。
想亲自试试 Claude Fable 5 的读者,可以通过 OneHop 使用:一个可直接替换的端点,约比标价低 30%,新账户送 $10 且无需绑卡。查看 Claude Fable 5 on OneHop 或 start with $10 free。

