
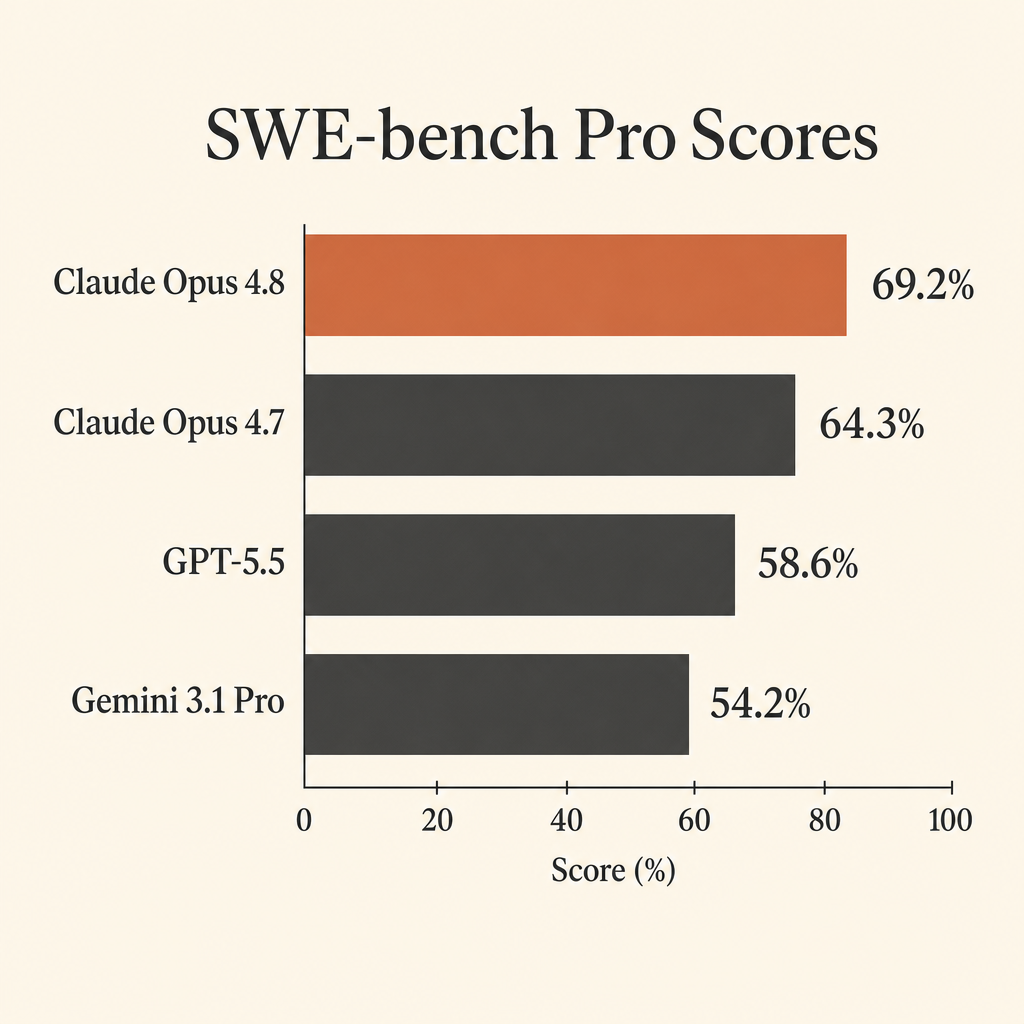
Die nützlichste Coding-Zahl von Claude Opus 4.8 ist nicht der fast ausgereizte SWE-bench-Verified-Wert. Es sind 69,2 % auf SWE-bench Pro.
Das ist wichtig, weil SWE-bench Pro für genau die Arbeit gebaut wurde, die Entwickler tatsächlich von autonomen Agents erwarten: ein echtes Repository öffnen, das Issue verstehen, mehrere Dateien bearbeiten, Tests ausführen, falsche Annahmen korrigieren und einen Patch liefern. In Anthropic’s Claude Opus 4.8 system card erreicht Opus 4.8 auf SWE-bench Pro 69,2 % und liegt damit vor GPT-5.5 mit 58,6 % und Gemini 3.1 Pro mit 54,2 % (Anthropic system card PDF).
Dieser Abstand ist groß genug, um die Modellwahl für agentisches Coding zu verändern. Wenn du ein Modell dafür bezahlst, Repo-Kontext, Tool-Calls, Testfehler und lange Reparaturschleifen durchzuarbeiten, ist ein Benchmark-Abstand von zehn Punkten keine Nebensache. Es ist der Unterschied zwischen „braucht dauernd Aufsicht“ und „bekommt eine echte Aufgabe“.
Benchmark-Vergleich (Benchmark)
Hier ist der kompakte Vergleich, der diese Woche in jedes Evaluationsdokument für Coding-Agents gehört.
| Modell | SWE-bench Pro | SWE-bench Verified | Terminal-Bench 2.1 | API-Preis, Input/Output |
|---|---|---|---|---|
| Claude Opus 4.8 | 69.2% | 88.6% | 74.6% | $5 / $25 pro 1 Mio. Token |
| Claude Opus 4.7 | 64.3% | 87.6% | 66.1% | hier nicht verglichen |
| GPT-5.5 | 58.6% | nicht aufgeführt | 78.2% | $5 / $30 pro 1 Mio. Token |
| Gemini 3.1 Pro Preview | 54.2% | 80.6% | 70.3% | $2 / $12 <=200k Prompt, $4 / $18 >200k Prompt |
Die Benchmark-Werte oben stammen aus der Tabelle in Anthropic’s Opus 4.8 system card (Anthropic system card PDF). Anthropic’s Produktseite sagt, dass Opus 4.8 am 28. Mai 2026 gestartet ist, für „serious coding and AI agents“ gebaut wurde, ein Kontextfenster von 1 Mio. unterstützt und bei $5 pro Million Input-Token und $25 pro Million Output-Token beginnt (Anthropic). OpenAI listet GPT-5.5 mit $5 Input und $30 Output pro Million Token, einem Kontextfenster von 1.050.000 Token und einem gpt-5.5-2026-04-23-Snapshot (OpenAI). Google listet die Preise für Gemini 3.1 Pro Preview mit $2/$12 pro Million Token für Prompts bis 200k Token und $4/$18 oberhalb von 200k (Google AI).
Opus gewinnt den Repo-Reparatur-Benchmark. GPT-5.5 gewinnt in dieser Tabelle Terminal-Bench 2.1. Gemini ist pro Token günstiger, besonders unterhalb der 200k-Prompt-Schwelle, liegt bei SWE-bench Pro aber zurück.
So sieht die Entscheidung aus.
Was SWE-bench Pro wirklich misst
SWE-bench Pro ist kein weiterer „schreib eine Funktion aus einem Prompt“-Test. Das Paper beschreibt es als Benchmark mit 1.865 Problemen aus 41 aktiv gepflegten Repositories, darunter Business-Anwendungen, B2B-Services und Developer-Tools (arXiv). Die Aufgaben sind in ein öffentliches Set, ein zurückgehaltenes Set und ein kommerzielles Set aus privaten Startup-Repositories aufgeteilt.
Das wichtige Detail ist die Form der Aufgaben. SWE-bench-Pro-Probleme sind Software-Engineering-Aufgaben mit langem Horizont. Die Autoren sagen, dass sie für professionelle Engineers Stunden oder Tage dauern können, oft Patches über mehrere Dateien hinweg erfordern und umfangreiche Codeänderungen enthalten (arXiv). Der Benchmark filtert außerdem triviale Edits heraus. Das Paper berichtet von durchschnittlichen Referenzlösungen mit 107,4 Zeilen über 4,1 Dateien hinweg.
Das ist näher an der Arbeit, die Entwickler Agents übergeben:
git grep "billing status"
npm test -- --runInBand
git diff
pytest tests/billing/test_invoices.pyDer harte Teil ist nicht, syntaktisch gültigen Code zu erzeugen. Der harte Teil ist herauszufinden, welche Schicht den Bug besitzt, genug umgebenden Code zu lesen, zu editieren, ohne benachbartes Verhalten zu brechen, und Testausgaben zu nutzen, um den Kurs zu korrigieren.
SWE-bench Verified hat weiterhin Wert, aber an der Spitze wird es eng. Anthropic’s Tabelle setzt Opus 4.8 bei 88,6 % und Opus 4.7 bei 87,6 % auf SWE-bench Verified. Ein Abstand von einem Punkt reicht nicht, um ein Modell für teure autonome Repo-Arbeit auszuwählen. Auf SWE-bench Pro beträgt der Abstand zwischen Opus 4.8 und Opus 4.7 4,9 Punkte. Gegen GPT-5.5 sind es 10,6 Punkte. Gegen Gemini 3.1 Pro sind es 15,0 Punkte.
Das ist ein Signal.
Performance pro Dollar ist komplizierter als der Listenpreis
Der Tokenpreis zählt trotzdem. Agents sind hungrig. Ein einzelner echter Repo-Lauf kann einen langen initialen Kontext, wiederholte Datei-Lesevorgänge, Testlogs, fehlgeschlagene Patches, Zusammenfassungen und je nach Anbieterabrechnung versteckte Reasoning- oder Thinking-Token enthalten.
Für eine grobe Äpfel-mit-Äpfeln-Zahl nehmen wir einen hypothetischen Long-Context-Coding-Lauf mit 800k Input-Token und 200k Output-Token. Das ist kein universeller Workload; es ist nur eine saubere Art, gelistete API-Preise für eine große Repo-Aufgabe zu vergleichen.
| Modell | Preisannahme | Kosten für 800k rein / 200k raus | SWE-bench Pro | Score-Punkte pro $ |
|---|---|---|---|---|
| Claude Opus 4.8 | $5 rein / $25 raus | $9.00 | 69.2 | 7.69 |
| GPT-5.5 | $5 rein / $30 raus | $10.00 | 58.6 | 5.86 |
| Gemini 3.1 Pro Preview | >200k Prompt: $4 rein / $18 raus | $6.80 | 54.2 | 7.97 |
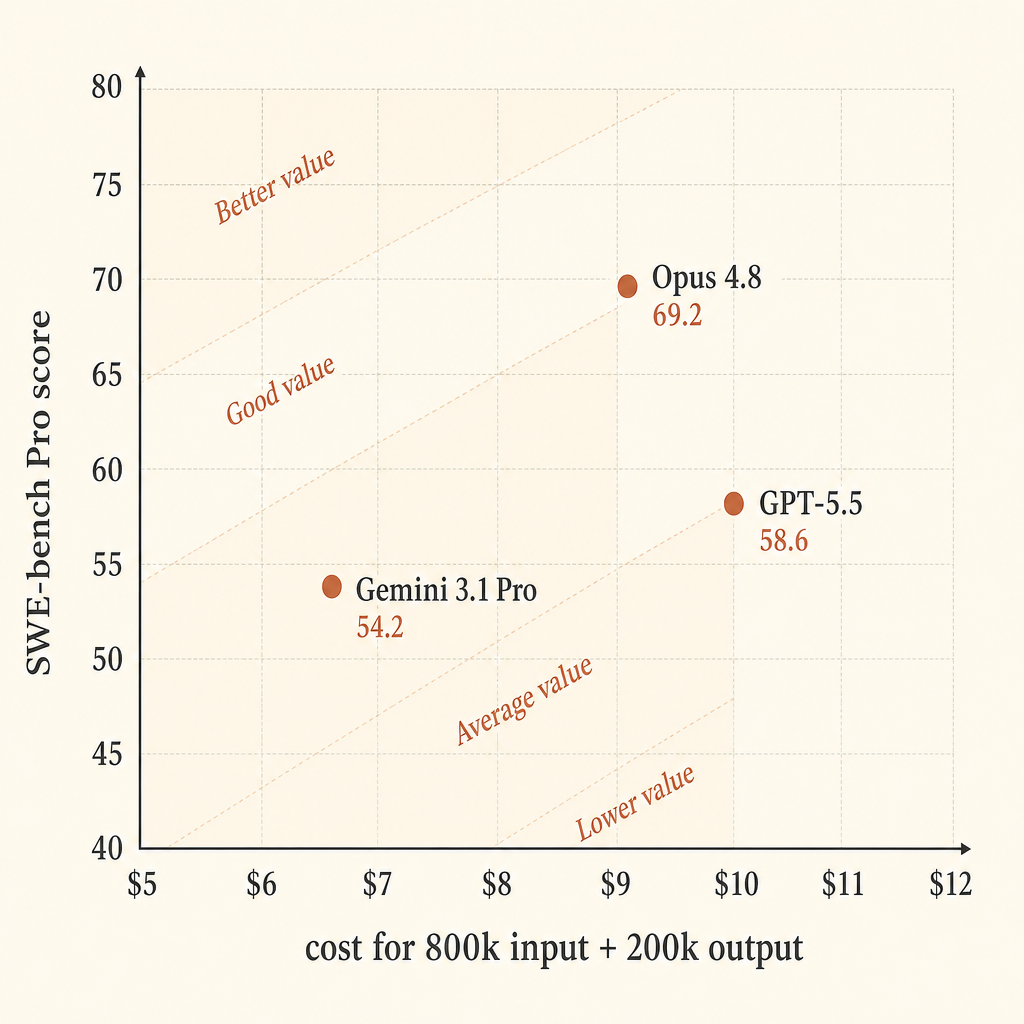
Gemini sieht in dieser vereinfachten Rechnung bei der reinen Preiseffizienz stark aus. Opus sieht am stärksten aus, wenn dir die Erfolgsrate zuerst wichtig ist. GPT-5.5 ist in genau diesem Ausschnitt die teure Mitte: höherer Output-Preis als Opus, niedrigerer SWE-bench-Pro-Wert, aber bester Terminal-Bench-2.1-Wert in Anthropic’s Tabelle.
Für autonomes Coding würde ich nicht nur auf „Benchmark-Punkte pro Dollar“ optimieren. Ein fehlgeschlagener Agent-Lauf ist nicht nur die Tokenrechnung. Es sind auch Review-Zeit, Kontextwechsel, schlechte Patches, wackelige Folgeprompts und die Kosten, die ganze Schleife erneut zu starten. Wenn die höhere Erfolgsrate von Opus 4.8 in deiner Codebase zu weniger Neustarts führt, kann der Abstand von $2,20 gegenüber Gemini im hypothetischen Lauf schnell verschwinden.
Der faire Weg zur Entscheidung ist ein eigener Repo-Harness:
agent-eval run \
--model claude-opus-4-8 \
--tasks evals/repo_tasks.jsonl \
--max-cost-usd 50 \
--record patches,tests,tokensTracke akzeptierte Patches, menschliche Review-Minuten, Gesamtkosten und Rollback-Rate. Benchmark-Werte sollten deine Shortlist bestimmen. Dein Repo sollte Production bestimmen.
Warum Opus 4.8 bei genau diesem Signal gewinnt
Die Opus-4.8-Story ist nicht „Claude ist besser bei Code“ im generischen Sinn. Das ist zu breit und bei mindestens einem Benchmark meistens falsch. Die präzisere Aussage lautet: In Anthropic’s berichtetem SWE-bench-Pro-Setup liegt Opus 4.8 bei autonomer Repository-Issue-Lösung vorn.
Das passt zu drei praktischen Stärken.
Erstens hat es Luft oberhalb der einfachen Decke. SWE-bench Verified ist nützlich, aber wenn Modelle schon in den hohen Achtzigern liegen, werden kleine Deltas für Kaufentscheidungen verrauscht. SWE-bench Pro öffnet den Abstand wieder.
Zweitens stresst es Verhalten auf Repo-Ebene. Das SWE-bench-Pro-Paper hebt Kontaminationsresistenz, kommerzielle/private Codebases, Multi-File-Änderungen, menschliche Verifikation und Enterprise-artige Aufgaben hervor (arXiv). Das ist näher an „fix diesen Regression in unserem Billing-Service“ als an „vervollständige diese Python-Funktion“.
Drittens hat Anthropic Opus 4.8 um lang laufendes Coding und Agents herum positioniert, nicht nur Chat. Die Opus-Seite sagt, dass das Modell in Claude Code und der API verfügbar ist, 1M Kontext unterstützt und für komplexes Coding, agentische Workflows und professionelle Arbeit gedacht ist (Anthropic). Marketing-Sprache ist kein Beweis, aber die Benchmark-Tabelle passt zur Produktrichtung.
Wie ich ein Modell für Repo-Agents auswählen würde
Wenn dein Agent flache Edits, Code-Snippets oder IDE-Autocomplete macht, sollte SWE-bench Pro nicht deine einzige Linse sein. Latenz, Streaming-Qualität, lokale Tool-Integration und Preis werden wichtiger sein.
Wenn dein Agent Repo-Aufgaben Ende zu Ende übernehmen soll, starte mit diesem Ranking:
- Nutze Claude Opus 4.8 als Qualitäts-Baseline für harte autonome Repo-Arbeit.
- Teste GPT-5.5, wenn terminal-lastige Task-Ausführung zählt, weil Anthropic’s Tabelle ihm die Führung bei Terminal-Bench 2.1 gibt.
- Teste Gemini 3.1 Pro Preview, wenn der Kostendruck hoch ist und deine Aufgaben unterhalb der Failure-Cost-Schwellen bleiben.
- Behalte ein günstigeres Modell in der Schleife für Triage, Datei-Suchzusammenfassungen und risikoarme Edits.
Das verlässlichste Production-Muster ist nicht ein riesiges Modell für alles. Nutze ein schnelles, günstigeres Modell, um Issues zu klassifizieren und Kontext zu sammeln. Eskaliere den harten Patch an Opus 4.8. Führe Tests aus. Nutze ein zweites Modell, manchmal GPT-5.5 oder Gemini, als Reviewer für den finalen Diff. Shippe nur, wenn Testsuite und menschlicher Reviewer zustimmen.
Das klingt weniger magisch als „autonomer Engineer“. Gut. So vermeiden Teams auch, mit einem wunderschönen Patch aufzuwachen, der Auth kaputt gemacht hat.
Fazit
Claude Opus 4.8s SWE-bench-Pro-Wert von 69,2 % ist ein besseres Entwicklersignal als noch eine hohe SWE-bench-Verified-Zahl. Er misst näher an der Arbeit, die Agents leisten sollen: Repo-Navigation, Multi-File-Änderungen, testgetriebene Reparatur und Ausführung über lange Horizonte.
Opus 4.8 ist nicht das günstigste Modell im Vergleich. Es gewinnt auch nicht jeden Benchmark in Anthropic’s eigener Tabelle. Aber für autonome Repo-Arbeit ist der SWE-bench-Pro-Abstand groß genug, um es zum ersten Modell zu machen, das ich evaluieren würde.
Nutze die öffentlichen Zahlen, um die Shortlist zu bauen. Dann führe deine eigenen Tasks aus, miss akzeptierte Patches pro Dollar und rechne menschliche Review-Zeit in die Kosten ein. Dort werden Benchmark-Siege entweder zu Engineering-Hebel — oder sie verschwinden.
Leser, die Claude Fable 5 selbst ausprobieren möchten, können es über OneHop nutzen: ein Drop-in-Endpunkt, etwa 30 % unter Listenpreis, mit $10 gratis für neue Accounts und ohne Karte. Siehe Claude Fable 5 auf OneHop oder mit $10 gratis starten.
Weiterführende Lektüre: Erste Schritte mit Claude Fable 5.

