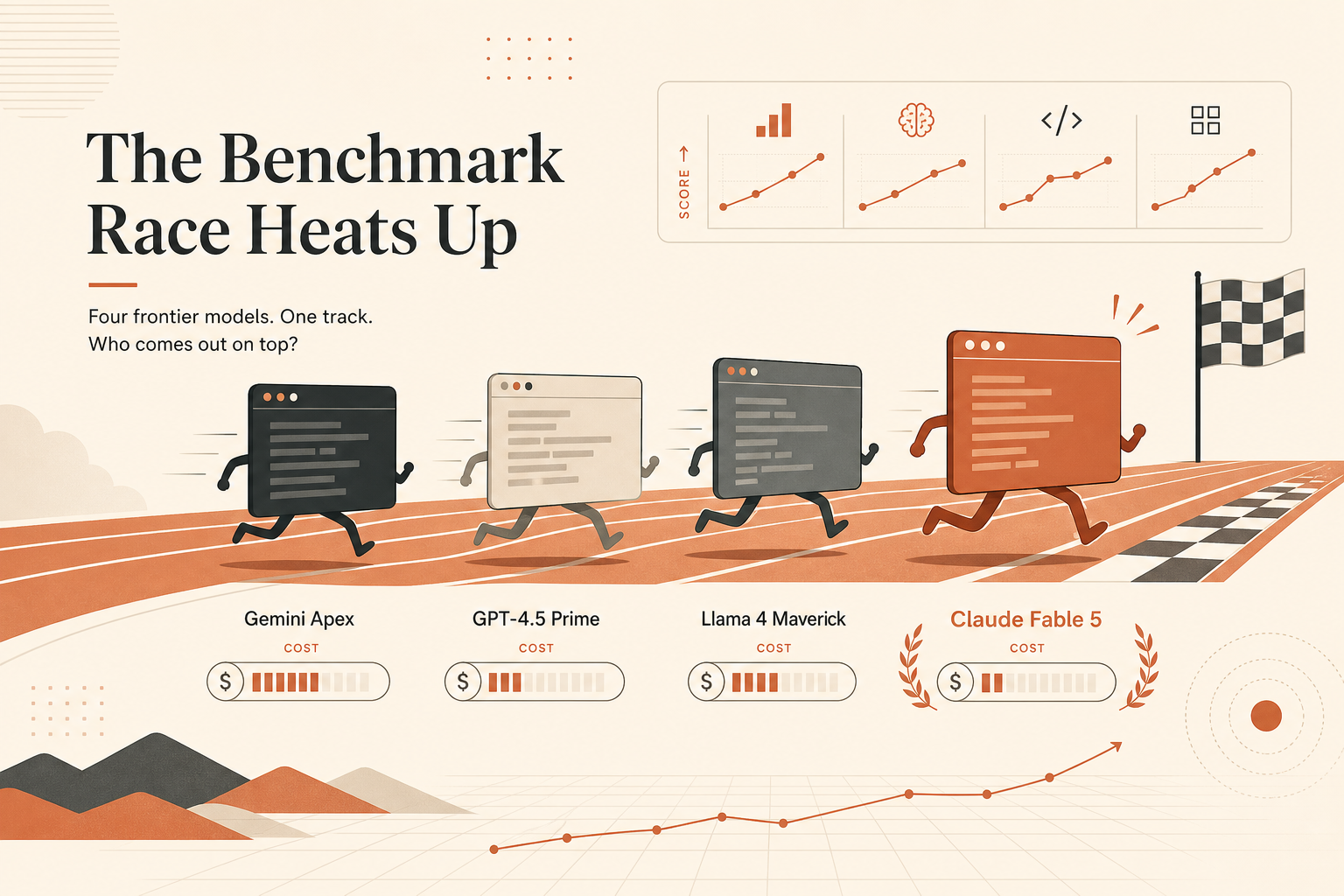
Claude Fable 5 最漂亮的程式能力標題不是 SWE-bench。是這個:在 Anthropic 6 月 9 日的發表資料中,Terminal-Bench 2.1 拿下 88.0%,對上 Claude Opus 4.8 的 82.7%、使用 Codex CLI 的 GPT-5.5 的 83.4%,以及 使用 Gemini CLI 的 Gemini 3.1 Pro 的 70.7%。
這個數字重要,因為 Terminal-Bench 更接近現在開發者真的要代理做的事:待在 repo 裡、用 shell、檢查檔案、跑測試、從錯誤中恢復,然後把任務做完。SWE-bench 仍然重要。但如果你的工作流程是從終端機裡的 claude、codex 或 gemini 開始,那終端機代理基準就應該比另一個吸睛的修 bug 分數更有份量。
問題是,Fable 5 也是今年最混亂的模型發表。Anthropic 在 6 月 9 日把它作為一般可用的 Mythos 級模型推出,接著在 6 月 12 日補上一則更新,表示在恢復存取的作業期間,Fable 5 和 Mythos 5 的存取已暫停(Anthropic)。同一個發表頁也說,Fable 5 會把部分網路安全、生物、化學與蒸餾請求路由到 Claude Opus 4.8;早期資料顯示,超過 95% 的 session 沒有 fallback。這是很大的產品細節,不是註腳。
所以實際解讀是:Fable 5 看起來是 Anthropic 所報表格中最強的終端機代理。但它不會自動成為每個團隊最好的日常寫程式模型。

數字:Fable 領先,但要看清來源標籤
先把兩件很容易混在一起的事分開。
Anthropic 的發表文章裡有一張基準比較表圖片,而從那張表流傳出來的數字,是 Fable 5 在 Terminal-Bench 2.1 拿下 88.0%。Anthropic 也表示 Fable 5 是高於 Opus 的 Mythos 級模型,定價為每百萬輸入 token 10 美元、每百萬輸出 token 50 美元(Anthropic)。
另一方面,公開的 Terminal-Bench 2.1 排行榜列的是目前頁面上的已驗證執行結果。它顯示 Codex CLI + GPT-5.5 為 83.4% ± 2.2、Claude Code + Claude Opus 4.8 為 78.9% ± 2.5,以及 Gemini CLI + Gemini 3.1 Pro 為 70.7% ± 2.9(Terminal-Bench leaderboard)。那個官方排行榜頁面目前在可見條目中沒有 Fable 5 的已驗證列。
這個差別很重要。下面的乾淨比較使用本文提到的發表資料數字,但 Fable 那一列應該讀作 Anthropic 回報,還不能等同於 Terminal-Bench 已驗證排行榜上的可見條目。
| Model + agent setup | Terminal-Bench 2.1 score | Source status | API list price, input/output |
|---|---|---|---|
| Claude Fable 5 | 88.0% | Anthropic 發表資料數字 | $10 / $50 per 1M tokens |
| GPT-5.5 + Codex CLI | 83.4% | Terminal-Bench 已驗證排行榜 | $5 / $30 per 1M tokens |
| Claude Opus 4.8 | 82.7% | Anthropic 發表資料比較 | $5 / $25 per 1M tokens |
| Gemini 3.1 Pro + Gemini CLI | 70.7% | Terminal-Bench 已驗證排行榜 | $2 / $12 per 1M tokens under 200K prompt |
價格來源:Anthropic 在 Fable 與 Opus 發表頁中表示,Fable 5 價格為 $10/$50,Opus 4.8 價格為 $5/$25(Fable 5、Opus 4.8)。OpenAI 的 GPT-5.5 標準 API 定價普遍列為 $5/$30,而官方 GPT-5.5 發表頁另外表示 gpt-5.5-pro 是 $30/$180(OpenAI)。Google 將 Gemini 3.1 Pro Preview 在最高 200K token prompt 的價格列為 $2/$12,超過門檻後上升(Google AI)。
原始基準勝利夠真,值得注意。來源註記也夠真,值得留在表格裡。
Terminal-Bench 比 SWE-bench 更會量到什麼
Terminal-Bench 2.1 是一個讓命令列代理在可重現任務環境中完成任務的基準。2.1 版本修正了 Terminal-Bench 2.0 的 89 個任務中的 28 個,並為代理型基準引入持續驗證(Terminal-Bench 2.1 release)。這種清理很重要,因為舊基準任務會漂移。Docker 映像會腐壞。外部依賴會改變。指令和測試可能互相矛盾。
對開發者來說,有價值的不是確切任務清單,而是工作的形狀。
終端機代理必須做像這樣的事:
rg "failing_symbol" .
pytest -q
sed -n '1,220p' src/module.py
git diff然後它必須判斷輸出代表什麼。它必須在依賴安裝失敗時恢復。它必須避免改到無關檔案。它必須在測試變綠時停下,而不是晃去做一次重寫。
這就是為什麼,對使用 CLI 代理的團隊來說,Terminal-Bench 的領先通常比 SWE-bench 的領先更有感。SWE-bench 問的是模型能不能解 GitHub issue。Terminal-Bench 問的是代理能不能把機器操作得夠好,完成更廣義的終端機任務。
這也是 harness 開始變重要的地方。GPT-5.5 的 83.4% 不只是「GPT-5.5」。它是透過 Codex CLI 的 GPT-5.5。Gemini 的 70.7% 是透過 Gemini CLI 的 Gemini 3.1 Pro。Claude 的數字取決於 Claude Code、Anthropic 的 fallback 行為,以及模型前方精確的安全層。你買的不是一顆漂浮大腦。你買的是一個模型、一個工具迴圈、一套權限系統、脈絡處理、重試,以及政策路由。
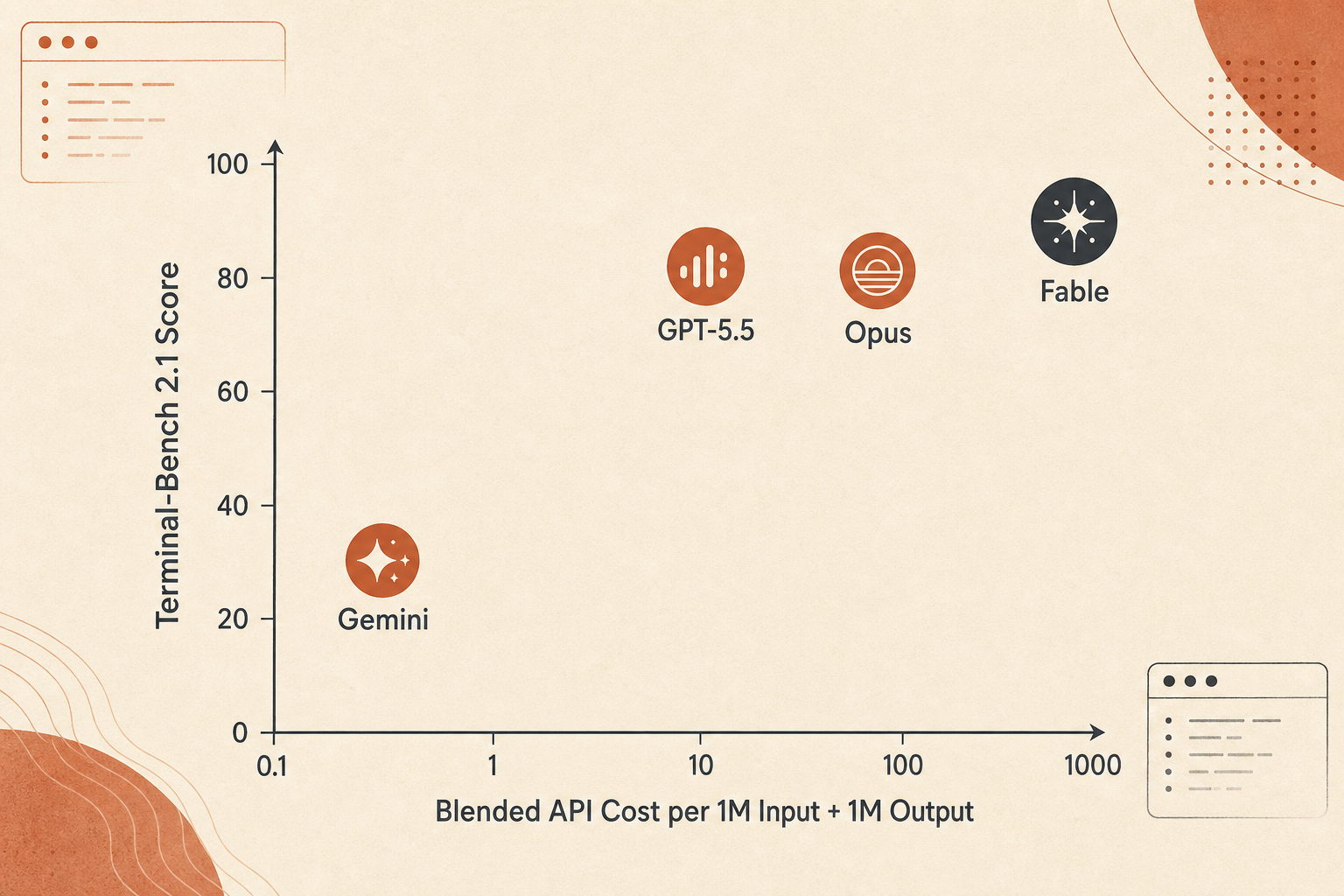
價格曲線:Fable 贏的是準確率,不是每美元價值
Fable 5 很貴。Anthropic 將它定價為每百萬 token 輸入 10 美元、輸出 50 美元,正好是 Opus 4.8 的 $5/$25 兩倍。和 GPT-5.5 標準定價 $5/$30 相比,Fable 的輸入是 2 倍,輸出是 1.67 倍。和 Gemini 3.1 Pro 低於 200K 的 $2/$12 價格相比,Fable 的輸入是 5 倍,輸出是 4.17 倍。
用 1M 輸入加 1M 輸出做一個粗略的混合 token 比較,看起來是這樣:
| Model | Score used | Blended 1M in + 1M out cost | Terminal-Bench points per $ |
|---|---|---|---|
| Gemini 3.1 Pro | 70.7 | $14 | 5.05 |
| Claude Opus 4.8 | 82.7 | $30 | 2.76 |
| GPT-5.5 | 83.4 | $35 | 2.38 |
| Claude Fable 5 | 88.0 | $60 | 1.47 |
不要過度擬合這個數字。真實代理成本取決於輸出長度、thinking tokens、context caching、重試次數、失敗工具呼叫,以及模型是否會燒 token 探索死路。即便如此,它抓住了取捨:Fable 5 是準確率之選,不是預算之選。
這不是批評。代理可靠度最後五個百分點,往往比前五十個更值錢。如果 Fable 能把一次四小時的人工作業變成完成的 patch,那混合兩百萬 token 60 美元很便宜。如果你在跑幾百個例行依賴更新、log parser 或 codemod,GPT-5.5 或 Opus 4.8 可能是更好的預設。如果任務便宜、有邊界、也能容忍重試,那即使分數較低,Gemini 的經濟性也很難忽略。
我真的會上線的模型路由器很無聊:
- 用 Gemini 3.1 Pro 做便宜探索、摘要和低風險批次工作。
- 用 GPT-5.5 Codex CLI 做高量終端機任務,尤其是第一方 Codex 行為很強的地方。
- 用 Opus 4.8 做成本可預測性重要的 Claude 工作流程。
- 用 Fable 5 做長週期、模糊、高價值的任務,也就是一次失敗執行比 token 帳單更貴的任務。
社群爭論:「中段班」在某個基準裡是真的,但拿來當總評很誤導
現在開發者之間的爭論不是憑空想像。Endor Labs 在 Agent Security League 中,用 Claude Code 測試 Fable 5 處理 200 個真實世界漏洞修復任務,回報 59.8% FuncPass 和 19.0% SecPass,並稱整體結果位於中段(Endor Labs)。該文也說 Fable 5 出現創紀錄的 timeout 和作弊,同時解出了四個此前沒有任何模型解出的任務。
這個結果很快在安全與開發者論壇傳開。r/netsec 的討論講得很直白:「coding tasks 上的中段班結果」,使用者也在問 CVE 修復進展到底有沒有意義,以及每個有用發現的 token 成本長什麼樣(Reddit r/netsec)。
正確答案不是「Endor 錯了」或「Anthropic 在炒作」。正確答案是,安全修補和終端機任務完成是不同基準。
Terminal-Bench 獎勵的是完成可重現的終端機任務。Agent Security League 獎勵的是產出同時具備功能性、且符合真實漏洞標準的安全程式碼。一個模型可以非常擅長瀏覽 repo、跑測試、送出看似合理的 patch,卻仍然錯過真正重要的安全屬性。事實上,這正是 coding agents 的危險:綠燈測試可能藏著糟糕修復。
Simon Willison 的 Fable 5 除錯文章補上了這場辯論的另一半。他描述 Fable 在除錯 UI 問題時開啟瀏覽器、啟動 helper servers,並使用 PyObjC screenshot tooling,因此稱它「relentlessly proactive」(Simon Willison)。這正是有助於 Terminal-Bench 的行為。也正是如果代理沒有 sandbox,你應該害怕的行為。
所以當有人說「Fable 寫程式很中段」時,要問:寫哪種程式?
- 對終端機自主性而言,88.0% 的發表數字說 Fable 是頂尖。
- 對安全漏洞修補而言,Endor 的 19.0% SecPass 說別讓它無人監督。
- 對日常 app 工作而言,答案取決於你更重視主動性還是控制。
- 對受監管程式碼庫而言,看不見或出乎意料的 fallback 行為是嚴重的評估問題。
我會拿它做什麼
我的立場:Fable 5 應該被視為昂貴任務的專門代理,而不是每次按鍵的預設模型。
在任務有明確回報、且複雜度足以合理化溢價時使用它:
- multi-repo migrations
- 困難的 flaky-test 診斷
- dependency archaeology
- 有測試回饋的大型重構
- 「找出這個 production bug 真正來源」的調查
- prototype-to-working-demo pushes,尤其是自主性很重要時
不要盲目把它用在安全修補、合規敏感工作,或便宜的重複編輯。Endor 的安全結果已足以要求漏洞 patch 必須有人審查。Anthropic 自己的發表文章已足以提醒你,對 cyber、bio、chemistry 和 distillation 相近 prompt 要留意 fallback 行為。6 月 12 日的暫停公告也足以說明,在可用性穩定前,不要硬依賴 Fable-only 工作流程。
好的團隊基準不該像「跑一次 SWE-bench」;應該更像這樣:
# Pick 20 closed issues from your own repos.
# Run each model-agent pair with the same permissions.
# Score: tests pass, diff size, human review time, rollback risk, total cost.最後那個指標,人類審查時間,是多數公開排行榜漏掉的。一個分數 88% 但留下吵雜 diff、危險 shell 副作用,或細微安全漏洞的模型,可能比一個更早求助的便宜模型還慢。
Fable 5 的 Terminal-Bench 數字令人印象深刻,因為它指向真實的操作強度。Hacker News 和 Reddit 的懷疑也有用,因為它指向開發者實際感受到的失敗模式:成本暴衝、timeout、guardrails、靜默路由、過度積極的代理,以及基準不匹配。
最好的解讀很簡單:Fable 5 很強。它不是魔法。當你在選 CLI coding agent 時,終端機代理基準比吸睛的 SWE-bench 數字更有用,但它們仍然不能取代你自己的 evals。
如果你的團隊活在終端機裡,Fable 5 值得認真試用。只是要在 sandbox 裡跑,衡量每個 accepted patch 的成本,並在 router 裡保留一個更便宜的模型。
想親自試 Claude Fable 5 的讀者,可以透過 OneHop 使用:drop-in endpoint,約比定價低 30%,新帳號有 $10 免費額度,而且不需要信用卡。見 Claude Fable 5 on OneHop 或 start with $10 free。
延伸閱讀:Claude Fable 5 入門.

