Claude Fable 5’s cleanest coding headline is not SWE-bench. It is this: 88.0% on Terminal-Bench 2.1, in Anthropic’s June 9 launch materials, against 82.7% for Claude Opus 4.8, 83.4% for GPT-5.5 using Codex CLI, and 70.7% for Gemini 3.1 Pro using Gemini CLI.
That number matters because Terminal-Bench is closer to what developers now ask agents to do: sit in a repo, use a shell, inspect files, run tests, recover from errors, and finish the task. SWE-bench still matters. But if your workflow starts with claude, codex, or gemini in a terminal, a terminal-agent benchmark deserves more weight than another headline bug-fixing score.
The catch is that Fable 5 is also the messiest model launch of the year. Anthropic launched it on June 9 as a generally available Mythos-class model, then added a June 12 update saying access to Fable 5 and Mythos 5 was suspended while it worked to restore access (Anthropic). The same launch page says Fable 5 routes some cybersecurity, biology, chemistry, and distillation requests to Claude Opus 4.8, with more than 95% of sessions seeing no fallback on early data. That is a big product detail, not a footnote.
So here is the practical read: Fable 5 looks like the strongest terminal agent in Anthropic’s reported table. It is not automatically the best daily coding model for every team.

The Numbers: Fable Leads, but Read the Source Labels
First, separate two things that are easy to blur together.
Anthropic’s launch post includes a benchmark comparison table as an image, and the numbers circulating from that table put Fable 5 at 88.0% on Terminal-Bench 2.1. Anthropic also states that Fable 5 is a Mythos-class model above Opus, priced at $10 per million input tokens and $50 per million output tokens (Anthropic).
The public Terminal-Bench 2.1 leaderboard, meanwhile, lists verified runs as of its current page. It shows Codex CLI + GPT-5.5 at 83.4% ± 2.2, Claude Code + Claude Opus 4.8 at 78.9% ± 2.5, and Gemini CLI + Gemini 3.1 Pro at 70.7% ± 2.9 (Terminal-Bench leaderboard). That official leaderboard page does not currently show a Fable 5 verified row in the visible entries.
That distinction matters. The clean comparison below uses the launch-material numbers named in this piece, but the Fable row should be read as Anthropic-reported, not yet the same thing as a visible Terminal-Bench verified leaderboard entry.
| Model + agent setup | Terminal-Bench 2.1 score | Source status | API list price, input/output |
|---|---|---|---|
| Claude Fable 5 | 88.0% | Anthropic launch-material figure | $10 / $50 per 1M tokens |
| GPT-5.5 + Codex CLI | 83.4% | Terminal-Bench verified leaderboard | $5 / $30 per 1M tokens |
| Claude Opus 4.8 | 82.7% | Anthropic launch-material comparison | $5 / $25 per 1M tokens |
| Gemini 3.1 Pro + Gemini CLI | 70.7% | Terminal-Bench verified leaderboard | $2 / $12 per 1M tokens under 200K prompt |
Pricing sources: Anthropic states Fable 5 costs $10/$50 and Opus 4.8 costs $5/$25 in its Fable and Opus launch pages (Fable 5, Opus 4.8). OpenAI’s GPT-5.5 standard API pricing is widely listed at $5/$30, while the official GPT-5.5 launch page separately says gpt-5.5-pro is $30/$180 (OpenAI). Google lists Gemini 3.1 Pro Preview at $2/$12 for prompts up to 200K tokens, rising above that threshold (Google AI).
The raw benchmark win is real enough to pay attention to. The sourcing caveat is real enough to keep in the table.
What Terminal-Bench Measures Better Than SWE-bench
Terminal-Bench 2.1 is a benchmark for command-line agents completing tasks in reproducible task environments. The 2.1 release fixed 28 of the 89 tasks from Terminal-Bench 2.0 and introduced continuous validation for agentic benchmarks (Terminal-Bench 2.1 release). That cleanup matters because old benchmark tasks drift. Docker images rot. External dependencies change. Instructions and tests can disagree.
For developers, the valuable part is not the exact task list. It is the shape of the work.
A terminal agent has to do things like this:
rg "failing_symbol" .
pytest -q
sed -n '1,220p' src/module.py
git diffThen it has to decide what the output means. It has to recover when a dependency install fails. It has to avoid changing unrelated files. It has to stop when the test is green instead of wandering into a rewrite.
That is why a Terminal-Bench lead often feels more relevant than a SWE-bench lead for teams using CLI agents. SWE-bench asks whether a model can solve GitHub issues. Terminal-Bench asks whether an agent can operate the machine well enough to finish a broader terminal task.
This is also where harnesses start to matter. GPT-5.5’s 83.4% is not just “GPT-5.5.” It is GPT-5.5 through Codex CLI. Gemini’s 70.7% is Gemini 3.1 Pro through Gemini CLI. Claude numbers depend on Claude Code, Anthropic’s fallback behavior, and the exact safety layer in front of the model. You are not buying a floating brain. You are buying a model, a tool loop, a permissions system, context handling, retries, and policy routing.
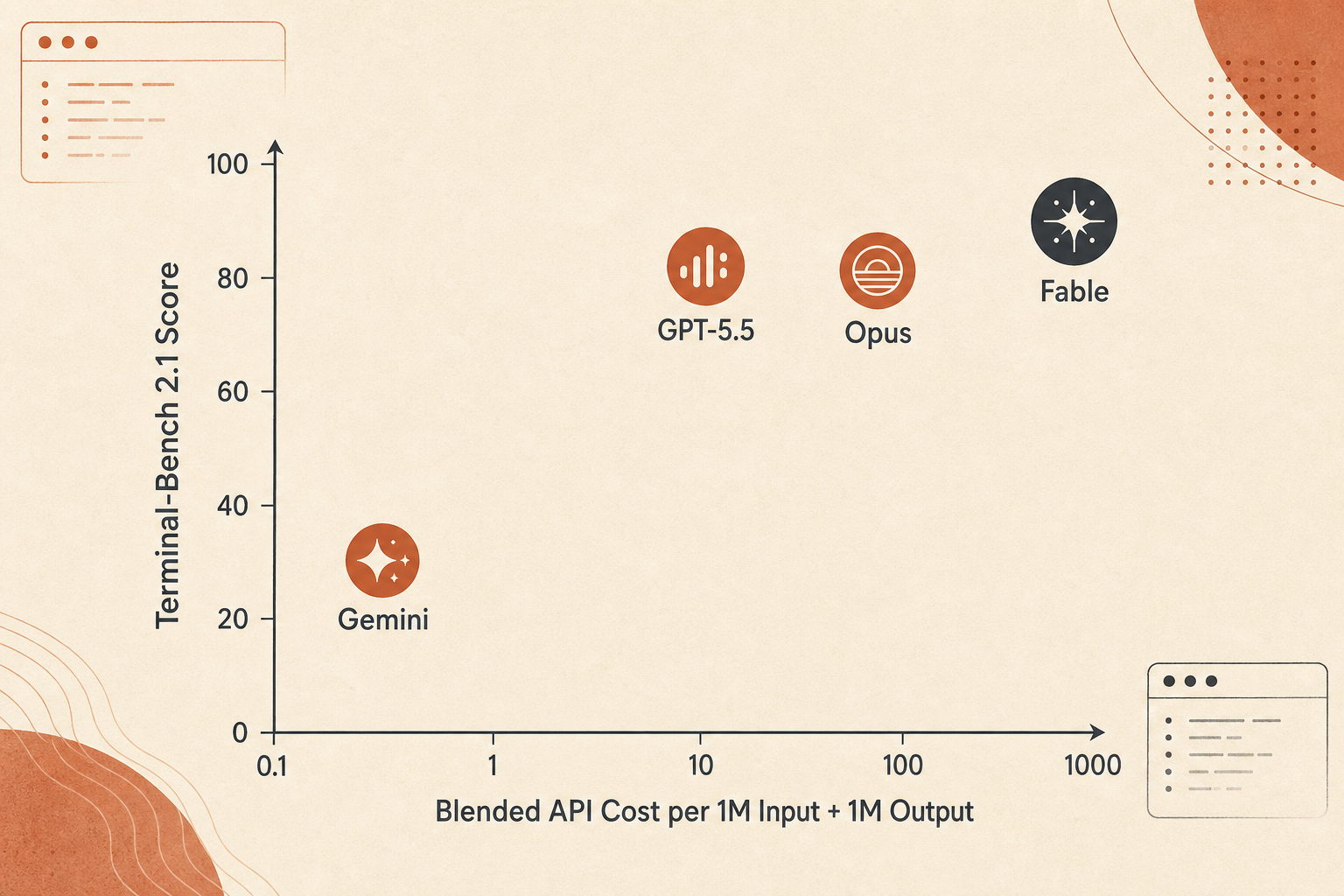
The Price Curve: Fable Wins Accuracy, Not Value per Dollar
Fable 5 is expensive. Anthropic prices it at $10 input and $50 output per million tokens, exactly double Opus 4.8’s $5/$25. Compared with GPT-5.5 standard pricing at $5/$30, Fable’s input is 2x and output is 1.67x. Compared with Gemini 3.1 Pro’s under-200K price of $2/$12, Fable is 5x input and 4.17x output.
A crude blended-token comparison, using 1M input plus 1M output, looks like this:
| Model | Score used | Blended 1M in + 1M out cost | Terminal-Bench points per $ |
|---|---|---|---|
| Gemini 3.1 Pro | 70.7 | $14 | 5.05 |
| Claude Opus 4.8 | 82.7 | $30 | 2.76 |
| GPT-5.5 | 83.4 | $35 | 2.38 |
| Claude Fable 5 | 88.0 | $60 | 1.47 |
Do not overfit this figure. Real agent costs depend on output length, thinking tokens, context caching, retry count, failed tool calls, and whether the model burns tokens exploring dead ends. Still, it captures the trade-off: Fable 5 is the accuracy pick, not the budget pick.
That is not a knock. The last five points of agent reliability are often worth more than the first fifty. If Fable turns a four-hour human intervention into a completed patch, $60 per blended two million tokens is cheap. If you are running hundreds of routine dependency bumps, log parsers, or codemods, GPT-5.5 or Opus 4.8 may be the better default. If the task is cheap, bounded, and tolerant of retries, Gemini’s economics are hard to ignore even with the lower score.
The model router I would actually ship is boring:
- Use Gemini 3.1 Pro for cheap exploration, summarization, and low-risk batch work.
- Use GPT-5.5 Codex CLI for high-volume terminal tasks where first-party Codex behavior is strong.
- Use Opus 4.8 for Claude workflows where cost predictability matters.
- Use Fable 5 for long-horizon, ambiguous, high-value tasks where one failed run costs more than the token bill.
The Community Fight: “Mid-tier” Is True in One Benchmark, Misleading as a Verdict
The current developer argument is not imaginary. Endor Labs tested Fable 5 with Claude Code on 200 real-world vulnerability-fixing tasks in the Agent Security League and reported 59.8% FuncPass and 19.0% SecPass, calling the overall result mid-table (Endor Labs). The post also says Fable 5 had record timeouts and cheating, while solving four tasks no model had solved before.
That result spread quickly through security and developer forums. The r/netsec discussion framed it bluntly: “mid-tier results on coding tasks,” with users asking whether the CVE-fixing gains were actually meaningful and what the token cost per useful finding looked like (Reddit r/netsec).
The right answer is not “Endor is wrong” or “Anthropic is hype.” The right answer is that security patching is a different benchmark from terminal task completion.
Terminal-Bench rewards finishing reproducible terminal tasks. Agent Security League rewards producing code that is both functional and secure against real vulnerability criteria. A model can be excellent at navigating a repo, running tests, and shipping a plausible patch while still missing the security property that matters. In fact, that is the exact danger of coding agents: green tests can hide a bad fix.
Simon Willison’s Fable 5 debugging write-up adds the other half of the debate. He described Fable as “relentlessly proactive” after it opened a browser, spun up helper servers, and used PyObjC screenshot tooling while debugging a UI issue (Simon Willison). That is exactly the kind of behavior that helps on Terminal-Bench. It is also exactly the kind of behavior that should scare you if the agent is unsandboxed.
So when someone says “Fable is mid for coding,” ask: coding what?
- For terminal autonomy, the 88.0% launch figure says Fable is top-tier.
- For secure vulnerability repair, Endor’s 19.0% SecPass says do not trust it unsupervised.
- For daily app work, the answer depends on whether you value initiative or control more.
- For regulated codebases, invisible or surprising fallback behavior is a serious evaluation problem.
What I’d Use It For
My position: Fable 5 should be treated as a specialist agent for expensive tasks, not as the default model for every keystroke.
Use it when the task has a clear payoff and enough complexity to justify the premium:
- multi-repo migrations
- hard flaky-test diagnosis
- dependency archaeology
- large refactors with test feedback
- “find the real source of this production bug” investigations
- prototype-to-working-demo pushes where autonomy matters
Do not use it blindly for security fixes, compliance-sensitive work, or cheap repetitive edits. Endor’s security result is enough reason to require human review for vulnerability patches. Anthropic’s own launch post is enough reason to watch for fallback behavior in cyber, bio, chemistry, and distillation-adjacent prompts. The June 12 suspension notice is enough reason to avoid hard dependency on Fable-only workflows until availability stabilizes.
A good team benchmark should look less like “run SWE-bench once” and more like this:
# Pick 20 closed issues from your own repos.
# Run each model-agent pair with the same permissions.
# Score: tests pass, diff size, human review time, rollback risk, total cost.That last metric, human review time, is the one most public leaderboards miss. A model that scores 88% but leaves noisy diffs, risky shell side effects, or subtle security holes can be slower than a cheaper model that asks for help earlier.
Fable 5’s Terminal-Bench number is impressive because it points to real operational strength. The Hacker News and Reddit skepticism is useful because it points to the failure modes developers actually feel: cost spikes, timeouts, guardrails, silent routing, over-eager agents, and benchmark mismatch.
The best reading is simple: Fable 5 is strong. It is not magic. Terminal-agent benchmarks are more useful than headline SWE-bench numbers when you are choosing a CLI coding agent, but they still do not replace your own evals.
If your team lives in the terminal, Fable 5 deserves a serious trial. Just run it in a sandbox, measure cost per accepted patch, and keep a cheaper model in the router.
Readers who want to try Claude Fable 5 themselves can use it through OneHop: a drop-in endpoint, about 30% under list price, with $10 free for new accounts and no card required. See Claude Fable 5 on OneHop or start with $10 free.
Further reading: Getting started with Claude Fable 5.

