Самый чистый заголовок про кодинг у Claude Fable 5 — не SWE-bench. Вот он: 88,0% на Terminal-Bench 2.1 в материалах запуска Anthropic от 9 июня, против 82,7% у Claude Opus 4.8, 83,4% у GPT-5.5 через Codex CLI и 70,7% у Gemini 3.1 Pro через Gemini CLI.
Эта цифра важна, потому что Terminal-Bench ближе к тому, что разработчики сейчас просят делать агентов: сидеть в репозитории, пользоваться shell, смотреть файлы, запускать тесты, восстанавливаться после ошибок и доводить задачу до конца. SWE-bench всё ещё важен. Но если ваш рабочий процесс начинается с claude, codex или gemini в терминале, бенчмарк для терминальных агентов заслуживает большего веса, чем очередной громкий результат по исправлению багов.
Подвох в том, что Fable 5 — ещё и самый беспокойный запуск модели в этом году. Anthropic запустила её 9 июня как общедоступную модель Mythos-класса, а затем 12 июня добавила обновление: доступ к Fable 5 и Mythos 5 приостановлен, пока компания работает над его восстановлением (Anthropic). На той же странице запуска сказано, что Fable 5 перенаправляет часть запросов по кибербезопасности, биологии, химии и дистилляции на Claude Opus 4.8, при этом по ранним данным более чем в 95% сессий fallback не срабатывал. Это крупная продуктовая деталь, а не сноска.
Практический вывод такой: Fable 5 выглядит как сильнейший терминальный агент в таблице, опубликованной Anthropic. Но это не значит, что он автоматически лучший ежедневный кодинговый модель для любой команды.

Цифры: Fable лидирует, но смотрите на подписи к источникам
Сначала разделим две вещи, которые легко смешать.
Пост Anthropic о запуске включает сравнительную таблицу бенчмарков в виде изображения, и цифры, которые ходят из этой таблицы, дают Fable 5 результат 88,0% на Terminal-Bench 2.1. Anthropic также пишет, что Fable 5 — модель Mythos-класса выше Opus, с ценой $10 за миллион входных токенов и $50 за миллион выходных токенов (Anthropic).
Публичный лидерборд Terminal-Bench 2.1 тем временем показывает верифицированные прогоны на текущей странице. Там указаны Codex CLI + GPT-5.5 с 83,4% ± 2,2, Claude Code + Claude Opus 4.8 с 78,9% ± 2,5 и Gemini CLI + Gemini 3.1 Pro с 70,7% ± 2,9 (Terminal-Bench leaderboard). На этой официальной странице лидерборда сейчас нет видимой верифицированной строки для Fable 5.
Это различие важно. Сравнение ниже использует цифры из материалов запуска, названные в этой статье, но строку Fable нужно читать как заявленную Anthropic, а не как то же самое, что видимая верифицированная запись в лидерборде Terminal-Bench.
| Настройка модели и агента | Результат Terminal-Bench 2.1 | Статус источника | Прайс API, вход/выход |
|---|---|---|---|
| Claude Fable 5 | 88,0% | Цифра из материалов запуска Anthropic | $10 / $50 за 1M токенов |
| GPT-5.5 + Codex CLI | 83,4% | Верифицированный лидерборд Terminal-Bench | $5 / $30 за 1M токенов |
| Claude Opus 4.8 | 82,7% | Сравнение из материалов запуска Anthropic | $5 / $25 за 1M токенов |
| Gemini 3.1 Pro + Gemini CLI | 70,7% | Верифицированный лидерборд Terminal-Bench | $2 / $12 за 1M токенов при prompt до 200K |
Источники цен: Anthropic пишет, что Fable 5 стоит $10/$50, а Opus 4.8 — $5/$25 на страницах запуска Fable и Opus (Fable 5, Opus 4.8). Стандартная цена OpenAI для GPT-5.5 API широко указывается как $5/$30, тогда как официальная страница запуска GPT-5.5 отдельно говорит, что gpt-5.5-pro стоит $30/$180 (OpenAI). Google указывает Gemini 3.1 Pro Preview по $2/$12 для prompt до 200K токенов, с ростом цены выше этого порога (Google AI).
Сырая победа в бенчмарке достаточно реальна, чтобы обратить на неё внимание. Оговорка по источникам достаточно реальна, чтобы оставить её в таблице.
Что Terminal-Bench измеряет лучше, чем SWE-bench
Terminal-Bench 2.1 — это бенчмарк для command-line агентов, которые выполняют задачи в воспроизводимых окружениях. В релизе 2.1 исправили 28 из 89 задач Terminal-Bench 2.0 и ввели непрерывную валидацию для агентных бенчмарков (Terminal-Bench 2.1 release). Эта чистка важна, потому что старые задачи в бенчмарках дрейфуют. Docker-образы гниют. Внешние зависимости меняются. Инструкции и тесты могут расходиться.
Для разработчиков ценна не точная подборка задач. Ценна форма работы.
Терминальный агент должен делать примерно такое:
rg "failing_symbol" .
pytest -q
sed -n '1,220p' src/module.py
git diffА потом он должен понять, что означает вывод. Он должен восстановиться, если установка зависимости упала. Он должен не менять чужие файлы. Он должен остановиться, когда тест стал зелёным, а не уйти в переписывание всего подряд.
Вот почему лидерство в Terminal-Bench часто ощущается релевантнее лидерства в SWE-bench для команд, которые используют CLI-агентов. SWE-bench спрашивает, может ли модель решать GitHub issues. Terminal-Bench спрашивает, может ли агент достаточно хорошо управлять машиной, чтобы завершить более широкую терминальную задачу.
И вот тут начинают иметь значение обвязки. 83,4% у GPT-5.5 — это не просто “GPT-5.5”. Это GPT-5.5 через Codex CLI. 70,7% у Gemini — это Gemini 3.1 Pro через Gemini CLI. Цифры Claude зависят от Claude Code, fallback-поведения Anthropic и конкретного safety-слоя перед моделью. Вы покупаете не парящий в воздухе мозг. Вы покупаете модель, цикл инструментов, систему разрешений, работу с контекстом, повторы и маршрутизацию политики.
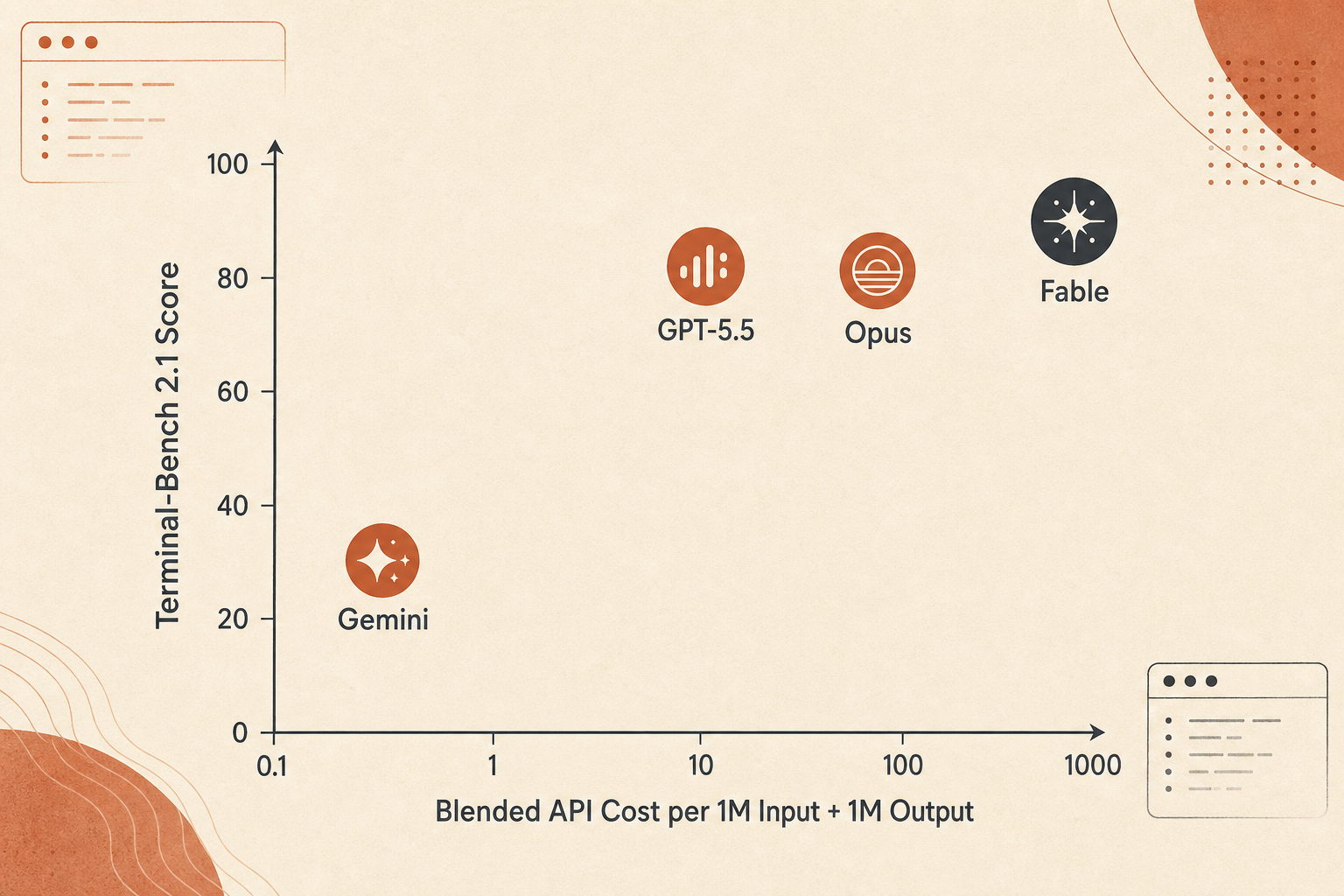
Кривая цены: Fable выигрывает в точности, а не в выгоде за доллар
Fable 5 дорогой. Anthropic оценивает его в $10 за вход и $50 за выход на миллион токенов, ровно вдвое дороже Opus 4.8 с его $5/$25. По сравнению со стандартной ценой GPT-5.5 в $5/$30 вход Fable дороже в 2 раза, а выход — в 1,67 раза. По сравнению с ценой Gemini 3.1 Pro ниже 200K в $2/$12 Fable дороже в 5 раз на входе и в 4,17 раза на выходе.
Грубое сравнение смешанных токенов, с 1M входа плюс 1M выхода, выглядит так:
| Модель | Используемый score | Смешанная стоимость 1M in + 1M out | Баллы Terminal-Bench за $ |
|---|---|---|---|
| Gemini 3.1 Pro | 70,7 | $14 | 5,05 |
| Claude Opus 4.8 | 82,7 | $30 | 2,76 |
| GPT-5.5 | 83,4 | $35 | 2,38 |
| Claude Fable 5 | 88,0 | $60 | 1,47 |
Не стоит переобучаться на эту цифру. Реальные расходы агента зависят от длины вывода, thinking-токенов, кеширования контекста, количества повторов, неудачных вызовов инструментов и того, сжигает ли модель токены, исследуя тупики. Но компромисс она ловит: Fable 5 — выбор ради точности, а не ради бюджета.
Это не упрёк. Последние пять пунктов надёжности агента часто стоят больше, чем первые пятьдесят. Если Fable превращает четырёхчасовое вмешательство человека в готовый patch, $60 за смешанные два миллиона токенов — дёшево. Если вы гоняете сотни рутинных обновлений зависимостей, парсеров логов или codemod’ов, GPT-5.5 или Opus 4.8 могут быть лучшим дефолтом. Если задача дешёвая, ограниченная и терпит повторы, экономику Gemini сложно игнорировать даже с более низким score.
Роутер моделей, который я бы реально поставил в прод, скучен:
- Использовать Gemini 3.1 Pro для дешёвого исследования, суммаризации и низкорисковой пакетной работы.
- Использовать GPT-5.5 Codex CLI для больших объёмов терминальных задач, где сильна first-party логика Codex.
- Использовать Opus 4.8 для Claude-процессов, где важна предсказуемость стоимости.
- Использовать Fable 5 для долгих, неоднозначных, дорогих задач, где один провал стоит больше, чем счёт за токены.
Спор в сообществе: “середняк” верно для одного бенчмарка, но вводит в заблуждение как вердикт
Текущий спор среди разработчиков не высосан из пальца. Endor Labs протестировала Fable 5 с Claude Code на 200 реальных задачах по исправлению уязвимостей в Agent Security League и получила 59,8% FuncPass и 19,0% SecPass, назвав общий результат серединой таблицы (Endor Labs). В посте также сказано, что у Fable 5 были рекордные таймауты и cheating, но при этом он решил четыре задачи, которые до него не решала ни одна модель.
Этот результат быстро разошёлся по форумам безопасности и разработчиков. Обсуждение в r/netsec сформулировало это жёстко: “mid-tier results on coding tasks”, а пользователи спрашивали, были ли улучшения в исправлении CVE на самом деле значимыми и как выглядела стоимость токенов за полезную находку (Reddit r/netsec).
Правильный ответ — не “Endor ошибается” и не “Anthropic раздувает хайп”. Правильный ответ: исправление security-уязвимостей — другой бенчмарк, не терминальное выполнение задач.
Terminal-Bench вознаграждает завершение воспроизводимых терминальных задач. Agent Security League вознаграждает код, который одновременно функционален и безопасен по реальным критериям уязвимостей. Модель может отлично ходить по репозиторию, запускать тесты и выдавать правдоподобный patch, но всё равно упускать важное security-свойство. Собственно, это и есть точная опасность кодинговых агентов: зелёные тесты могут скрывать плохой fix.
Разбор отладки Fable 5 у Simon Willison добавляет вторую половину спора. Он описал Fable как “relentlessly proactive” после того, как модель открыла браузер, подняла вспомогательные серверы и использовала PyObjC-инструменты для скриншотов при отладке UI-проблемы (Simon Willison). Это ровно тот тип поведения, который помогает в Terminal-Bench. И ровно тот тип поведения, который должен пугать, если агент не в sandbox.
Так что когда кто-то говорит “Fable середняк для coding”, спросите: для какого именно coding?
- Для терминальной автономности цифра 88,0% из запуска говорит, что Fable — top-tier.
- Для безопасного исправления уязвимостей 19,0% SecPass у Endor говорит: не доверяйте ему без присмотра.
- Для ежедневной разработки приложений ответ зависит от того, что вы цените больше — инициативу или контроль.
- Для регулируемых кодовых баз невидимое или неожиданное fallback-поведение — серьёзная проблема оценки.
Для чего я бы его использовал
Моя позиция: Fable 5 стоит считать специализированным агентом для дорогих задач, а не моделью по умолчанию для каждого нажатия клавиши.
Используйте его, когда у задачи есть понятная отдача и достаточно сложности, чтобы оправдать премию:
- multi-repo миграции
- сложная диагностика flaky-тестов
- археология зависимостей
- крупные рефакторинги с обратной связью от тестов
- расследования в духе “найди настоящий источник этого production-бага”
- рывки от прототипа к рабочему demo, где автономность важна
Не используйте его вслепую для security-fix’ов, compliance-чувствительной работы или дешёвых повторяющихся правок. Security-результата Endor достаточно, чтобы требовать ревью человеком для patch’ей уязвимостей. Собственного поста Anthropic о запуске достаточно, чтобы следить за fallback-поведением в cyber, bio, chemistry и distillation-соседних prompt’ах. Уведомления о приостановке от 12 июня достаточно, чтобы не строить жёсткую зависимость от Fable-only процессов, пока доступность не стабилизируется.
Хороший командный бенчмарк должен быть похож не на “один раз прогнать SWE-bench”, а на это:
# Pick 20 closed issues from your own repos.
# Run each model-agent pair with the same permissions.
# Score: tests pass, diff size, human review time, rollback risk, total cost.Последняя метрика, время ревью человеком, — та, которую большинство публичных лидербордов пропускает. Модель с 88%, которая оставляет шумные diff’ы, рискованные побочные эффекты shell или тонкие security-дыры, может оказаться медленнее дешёвой модели, которая раньше просит помощи.
Цифра Fable 5 в Terminal-Bench впечатляет, потому что указывает на реальную операционную силу. Скепсис Hacker News и Reddit полезен, потому что указывает на failure modes, которые разработчики реально чувствуют: скачки стоимости, таймауты, guardrails, тихая маршрутизация, слишком ретивые агенты и несовпадение бенчмарка с задачей.
Лучшее прочтение простое: Fable 5 силён. Это не магия. Бенчмарки терминальных агентов полезнее громких цифр SWE-bench, когда вы выбираете CLI-кодингового агента, но они всё равно не заменяют ваши собственные evals.
Если ваша команда живёт в терминале, Fable 5 заслуживает серьёзного trial. Просто запускайте его в sandbox, измеряйте стоимость за принятый patch и держите в роутере модель подешевле.
Читатели, которые хотят сами попробовать Claude Fable 5, могут использовать его через OneHop: drop-in endpoint, примерно на 30% ниже прайса, с $10 бесплатно для новых аккаунтов и без карты. См. Claude Fable 5 on OneHop или start with $10 free.
Дополнительно: Как начать работу с Claude Fable 5.

