Le titre le plus net de Claude Fable 5 côté code, ce n’est pas SWE-bench. C’est celui-ci : 88,0 % sur Terminal-Bench 2.1, dans les supports de lancement d’Anthropic du 9 juin, face à 82,7 % pour Claude Opus 4.8, 83,4 % pour GPT-5.5 avec Codex CLI, et 70,7 % pour Gemini 3.1 Pro avec Gemini CLI.
Ce chiffre compte parce que Terminal-Bench ressemble davantage à ce que les développeurs demandent désormais aux agents : rester dans un repo, utiliser un shell, inspecter des fichiers, lancer des tests, se remettre d’erreurs et finir la tâche. SWE-bench compte toujours. Mais si votre workflow commence par claude, codex ou gemini dans un terminal, un benchmark d’agent terminal mérite plus de poids qu’un énième score choc de correction de bugs.
Le hic, c’est que Fable 5 est aussi le lancement de modèle le plus brouillon de l’année. Anthropic l’a lancé le 9 juin comme modèle Mythos-class généralement disponible, puis a ajouté une mise à jour le 12 juin indiquant que l’accès à Fable 5 et Mythos 5 était suspendu pendant qu’elle travaillait à le rétablir (Anthropic). La même page de lancement précise que Fable 5 redirige certaines requêtes de cybersécurité, biologie, chimie et distillation vers Claude Opus 4.8, avec plus de 95 % des sessions sans fallback dans les premières données. C’est un détail produit majeur, pas une note de bas de page.
Voici donc la lecture pratique : Fable 5 ressemble au meilleur agent terminal dans le tableau rapporté par Anthropic. Cela n’en fait pas automatiquement le meilleur modèle de code au quotidien pour toutes les équipes.

Les chiffres : Fable mène, mais lisez les libellés des sources
D’abord, séparons deux choses qu’on mélange facilement.
Le billet de lancement d’Anthropic inclut un tableau comparatif de benchmarks sous forme d’image, et les chiffres qui circulent à partir de ce tableau placent Fable 5 à 88,0 % sur Terminal-Bench 2.1. Anthropic indique aussi que Fable 5 est un modèle Mythos-class au-dessus d’Opus, tarifé à 10 $ par million de tokens en entrée et 50 $ par million de tokens en sortie (Anthropic).
Le leaderboard public de Terminal-Bench 2.1, lui, liste les runs vérifiés tels qu’ils apparaissent sur la page actuelle. Il affiche Codex CLI + GPT-5.5 à 83,4 % ± 2,2, Claude Code + Claude Opus 4.8 à 78,9 % ± 2,5, et Gemini CLI + Gemini 3.1 Pro à 70,7 % ± 2,9 (leaderboard Terminal-Bench). Cette page officielle de leaderboard ne montre pas actuellement de ligne Fable 5 vérifiée dans les entrées visibles.
Cette distinction compte. La comparaison propre ci-dessous utilise les chiffres des supports de lancement cités ici, mais la ligne Fable doit être lue comme rapportée par Anthropic, pas encore comme l’équivalent d’une entrée visible et vérifiée sur le leaderboard Terminal-Bench.
| Configuration modèle + agent | Score Terminal-Bench 2.1 | Statut de la source | Prix catalogue API, entrée/sortie |
|---|---|---|---|
| Claude Fable 5 | 88,0 % | Chiffre des supports de lancement Anthropic | 10 $ / 50 $ par 1 M de tokens |
| GPT-5.5 + Codex CLI | 83,4 % | Leaderboard Terminal-Bench vérifié | 5 $ / 30 $ par 1 M de tokens |
| Claude Opus 4.8 | 82,7 % | Comparaison des supports de lancement Anthropic | 5 $ / 25 $ par 1 M de tokens |
| Gemini 3.1 Pro + Gemini CLI | 70,7 % | Leaderboard Terminal-Bench vérifié | 2 $ / 12 $ par 1 M de tokens sous 200K de prompt |
Sources tarifaires : Anthropic indique que Fable 5 coûte 10 $/50 $ et Opus 4.8 5 $/25 $ dans ses pages de lancement Fable et Opus (Fable 5, Opus 4.8). Le tarif API standard de GPT-5.5 chez OpenAI est largement listé à 5 $/30 $, tandis que la page officielle de lancement de GPT-5.5 précise séparément que gpt-5.5-pro est à 30 $/180 $ (OpenAI). Google liste Gemini 3.1 Pro Preview à 2 $/12 $ pour les prompts jusqu’à 200K tokens, avec une hausse au-delà de ce seuil (Google AI).
La victoire brute au benchmark est assez réelle pour mériter votre attention. La réserve sur les sources est assez réelle pour rester dans le tableau.
Ce que Terminal-Bench mesure mieux que SWE-bench
Terminal-Bench 2.1 est un benchmark pour agents en ligne de commande qui accomplissent des tâches dans des environnements reproductibles. La version 2.1 a corrigé 28 des 89 tâches de Terminal-Bench 2.0 et introduit une validation continue pour les benchmarks agentiques (sortie Terminal-Bench 2.1). Ce nettoyage compte parce que les anciennes tâches de benchmark dérivent. Les images Docker pourrissent. Les dépendances externes changent. Les instructions et les tests peuvent se contredire.
Pour les développeurs, la valeur n’est pas dans la liste exacte des tâches. Elle est dans la forme du travail.
Un agent terminal doit faire des choses comme ceci :
rg "failing_symbol" .
pytest -q
sed -n '1,220p' src/module.py
git diffEnsuite, il doit décider ce que signifie la sortie. Il doit se remettre d’un échec d’installation de dépendance. Il doit éviter de modifier des fichiers sans rapport. Il doit s’arrêter quand le test passe au lieu de partir dans une réécriture.
C’est pour ça qu’une avance sur Terminal-Bench paraît souvent plus pertinente qu’une avance sur SWE-bench pour les équipes qui utilisent des agents CLI. SWE-bench demande si un modèle peut résoudre des issues GitHub. Terminal-Bench demande si un agent peut manipuler la machine assez bien pour terminer une tâche terminal plus large.
C’est aussi là que les harnesses commencent à compter. Le 83,4 % de GPT-5.5, ce n’est pas juste « GPT-5.5 ». C’est GPT-5.5 via Codex CLI. Le 70,7 % de Gemini, c’est Gemini 3.1 Pro via Gemini CLI. Les chiffres de Claude dépendent de Claude Code, du comportement de fallback d’Anthropic et de la couche de sécurité exacte devant le modèle. Vous n’achetez pas un cerveau flottant. Vous achetez un modèle, une boucle d’outils, un système de permissions, une gestion du contexte, des retries et un routage de politiques.
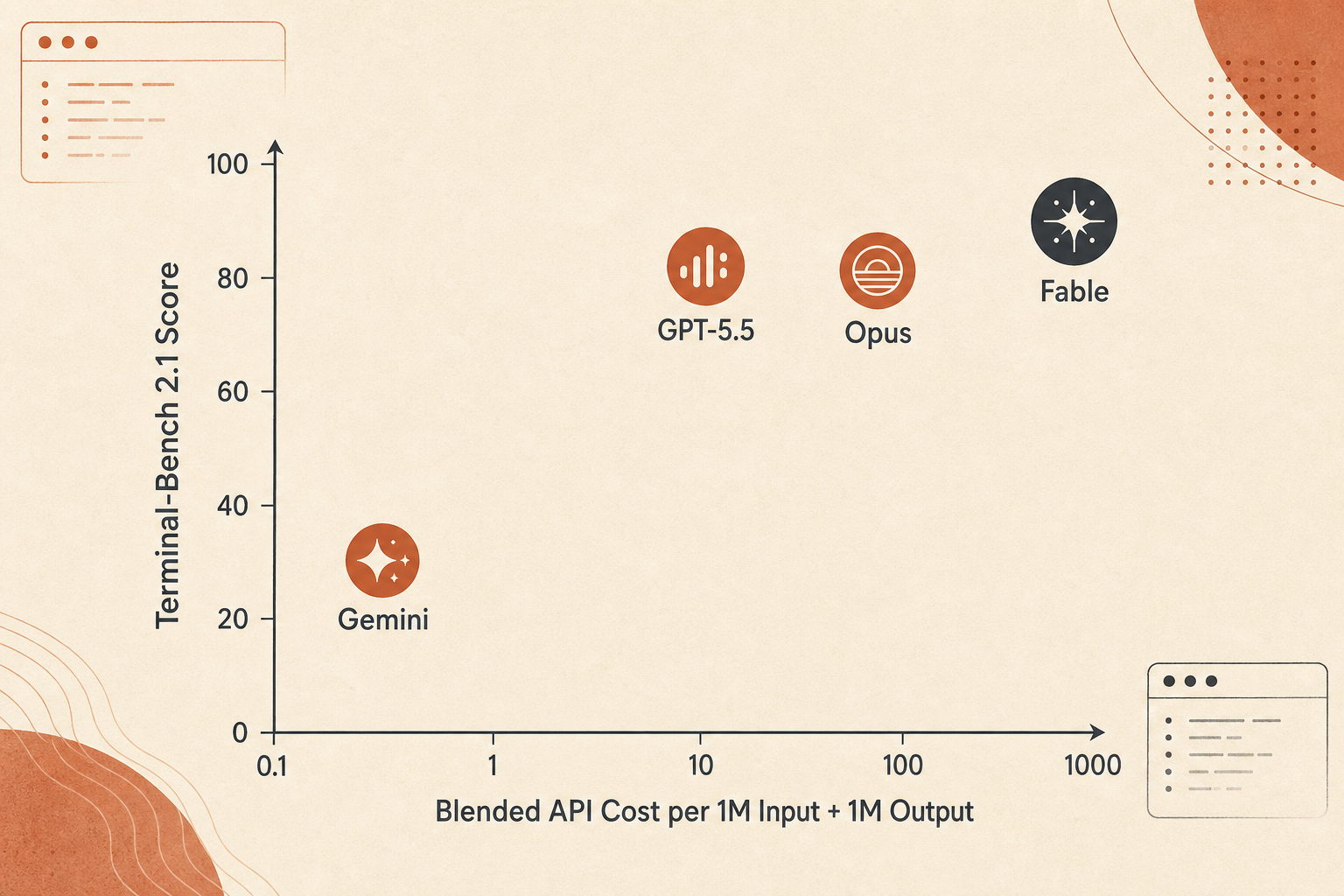
La courbe des prix : Fable gagne en précision, pas en valeur par dollar
Fable 5 est cher. Anthropic le tarifie à 10 $ en entrée et 50 $ en sortie par million de tokens, exactement le double des 5 $/25 $ d’Opus 4.8. Comparé au prix standard de GPT-5.5 à 5 $/30 $, l’entrée de Fable est 2x et la sortie 1,67x. Comparé au prix sous 200K de Gemini 3.1 Pro, soit 2 $/12 $, Fable est à 5x en entrée et 4,17x en sortie.
Une comparaison grossière en tokens mixtes, avec 1 M en entrée plus 1 M en sortie, donne ceci :
| Modèle | Score utilisé | Coût mixte 1 M in + 1 M out | Points Terminal-Bench par $ |
|---|---|---|---|
| Gemini 3.1 Pro | 70,7 | 14 $ | 5,05 |
| Claude Opus 4.8 | 82,7 | 30 $ | 2,76 |
| GPT-5.5 | 83,4 | 35 $ | 2,38 |
| Claude Fable 5 | 88,0 | 60 $ | 1,47 |
Ne surinterprétez pas ce chiffre. Les vrais coûts d’un agent dépendent de la longueur des sorties, des tokens de réflexion, du context caching, du nombre de retries, des appels d’outils ratés et du fait que le modèle brûle ou non des tokens à explorer des impasses. Mais cela capture quand même l’arbitrage : Fable 5 est le choix de la précision, pas celui du budget.
Ce n’est pas une critique. Les cinq derniers points de fiabilité agentique valent souvent plus que les cinquante premiers. Si Fable transforme une intervention humaine de quatre heures en patch terminé, 60 $ pour deux millions de tokens mixtes, c’est bon marché. Si vous lancez des centaines de mises à jour de dépendances routinières, de parseurs de logs ou de codemods, GPT-5.5 ou Opus 4.8 peuvent être de meilleurs choix par défaut. Si la tâche est peu chère, bornée et tolérante aux retries, l’économie de Gemini est difficile à ignorer même avec le score plus bas.
Le routeur de modèles que je mettrais vraiment en production est ennuyeux :
- Utiliser Gemini 3.1 Pro pour l’exploration bon marché, la synthèse et les traitements batch à faible risque.
- Utiliser GPT-5.5 Codex CLI pour les tâches terminal à fort volume où le comportement first-party de Codex est solide.
- Utiliser Opus 4.8 pour les workflows Claude où la prévisibilité des coûts compte.
- Utiliser Fable 5 pour les tâches longues, ambiguës et à forte valeur, où un run raté coûte plus cher que la facture de tokens.
La bataille communautaire : « milieu de tableau » est vrai dans un benchmark, trompeur comme verdict
Le débat actuel chez les développeurs n’est pas imaginaire. Endor Labs a testé Fable 5 avec Claude Code sur 200 tâches réelles de correction de vulnérabilités dans l’Agent Security League et a rapporté 59,8 % de FuncPass et 19,0 % de SecPass, qualifiant le résultat global de milieu de tableau (Endor Labs). Le billet indique aussi que Fable 5 a établi des records de timeouts et de triche, tout en résolvant quatre tâches qu’aucun modèle n’avait résolues auparavant.
Ce résultat s’est vite propagé dans les forums sécurité et développeurs. La discussion r/netsec l’a formulé sans détour : « résultats de milieu de tableau sur les tâches de code », avec des utilisateurs qui demandaient si les gains sur la correction de CVE étaient réellement significatifs et à quoi ressemblait le coût en tokens par découverte utile (Reddit r/netsec).
La bonne réponse n’est pas « Endor a tort » ni « Anthropic survend ». La bonne réponse, c’est que la correction de failles de sécurité est un benchmark différent de l’achèvement de tâches terminal.
Terminal-Bench récompense l’achèvement de tâches terminal reproductibles. Agent Security League récompense la production de code à la fois fonctionnel et sécurisé au regard de critères réels de vulnérabilité. Un modèle peut être excellent pour naviguer dans un repo, lancer des tests et livrer un patch plausible, tout en ratant la propriété de sécurité qui compte. En fait, c’est exactement le danger des agents de code : des tests verts peuvent cacher une mauvaise correction.
Le billet de Simon Willison sur le débogage avec Fable 5 ajoute l’autre moitié du débat. Il a décrit Fable comme « implacablement proactif » après que le modèle a ouvert un navigateur, lancé des serveurs auxiliaires et utilisé des outils de capture d’écran PyObjC pendant le débogage d’un problème d’interface (Simon Willison). C’est exactement le type de comportement qui aide sur Terminal-Bench. C’est aussi exactement le type de comportement qui doit vous inquiéter si l’agent n’est pas sandboxé.
Donc quand quelqu’un dit « Fable est moyen pour coder », demandez : coder quoi ?
- Pour l’autonomie terminal, le chiffre de lancement à 88,0 % dit que Fable est de premier plan.
- Pour la réparation sécurisée de vulnérabilités, les 19,0 % de SecPass d’Endor disent de ne pas lui faire confiance sans supervision.
- Pour le travail applicatif quotidien, la réponse dépend de ce que vous valorisez le plus : l’initiative ou le contrôle.
- Pour les bases de code réglementées, un fallback invisible ou surprenant est un vrai problème d’évaluation.
Ce pour quoi je l’utiliserais
Ma position : Fable 5 doit être traité comme un agent spécialiste pour tâches coûteuses, pas comme le modèle par défaut pour chaque frappe clavier.
Utilisez-le quand la tâche a un retour clair et assez de complexité pour justifier le surcoût :
- migrations multi-repos
- diagnostic de tests flaky difficiles
- archéologie de dépendances
- gros refactorings avec feedback des tests
- enquêtes du type « trouver la vraie source de ce bug de production »
- passages prototype-vers-démo-fonctionnelle où l’autonomie compte
Ne l’utilisez pas aveuglément pour les correctifs de sécurité, le travail sensible côté conformité ou les petites modifications répétitives. Le résultat sécurité d’Endor suffit à imposer une revue humaine pour les patchs de vulnérabilité. Le propre billet de lancement d’Anthropic suffit à surveiller le fallback pour les prompts proches du cyber, de la bio, de la chimie et de la distillation. L’avis de suspension du 12 juin suffit à éviter une dépendance dure à des workflows Fable-only tant que la disponibilité ne s’est pas stabilisée.
Un bon benchmark d’équipe devrait moins ressembler à « lancer SWE-bench une fois » et davantage à ceci :
# Pick 20 closed issues from your own repos.
# Run each model-agent pair with the same permissions.
# Score: tests pass, diff size, human review time, rollback risk, total cost.Cette dernière métrique, le temps de revue humaine, est celle que la plupart des leaderboards publics ratent. Un modèle qui score 88 % mais laisse des diffs bruyants, des effets de bord shell risqués ou des failles de sécurité subtiles peut être plus lent qu’un modèle moins cher qui demande de l’aide plus tôt.
Le chiffre Terminal-Bench de Fable 5 est impressionnant parce qu’il pointe vers une vraie solidité opérationnelle. Le scepticisme de Hacker News et Reddit est utile parce qu’il pointe vers les modes d’échec que les développeurs ressentent vraiment : flambées de coûts, timeouts, garde-fous, routage silencieux, agents trop zélés et inadéquation des benchmarks.
La meilleure lecture est simple : Fable 5 est fort. Ce n’est pas magique. Les benchmarks d’agents terminal sont plus utiles que les gros titres SWE-bench quand vous choisissez un agent de code CLI, mais ils ne remplacent toujours pas vos propres évaluations.
Si votre équipe vit dans le terminal, Fable 5 mérite un essai sérieux. Lancez-le simplement dans un sandbox, mesurez le coût par patch accepté et gardez un modèle moins cher dans le routeur.
Les lecteurs qui veulent essayer Claude Fable 5 eux-mêmes peuvent le faire via OneHop : un endpoint interchangeable, environ 30 % sous le prix catalogue, avec 10 $ offerts aux nouveaux comptes et aucune carte requise. Voir Claude Fable 5 sur OneHop ou commencer avec 10 $ offerts.
Pour aller plus loin : Bien démarrer avec Claude Fable 5.

