Claude Fable 5のコーディング性能でいちばん筋のいい見出しは、SWE-benchではない。これだ。Anthropicの6月9日のローンチ資料で示された Terminal-Bench 2.1の88.0%。比較対象は、Claude Opus 4.8の82.7%、Codex CLIを使ったGPT-5.5の83.4%、そして Gemini CLIを使ったGemini 3.1 Proの70.7% だ。
この数字が重要なのは、Terminal-Benchが、いま開発者がエージェントに頼んでいる作業により近いからだ。リポジトリに入り、シェルを使い、ファイルを調べ、テストを走らせ、エラーから立て直し、タスクを終わらせる。SWE-benchもまだ重要だ。だが、あなたのワークフローがターミナルで claude、codex、あるいは gemini を起動するところから始まるなら、別の派手なバグ修正スコアより、ターミナルエージェントのベンチマークを重く見るべきだ。
ただし問題もある。Fable 5は今年もっともややこしいモデルローンチでもある。Anthropicは6月9日、これを一般提供のMythos級モデルとして公開した。その後6月12日の更新で、アクセス復旧作業のためFable 5とMythos 5へのアクセスを一時停止していると追記した(Anthropic)。同じローンチページには、Fable 5がサイバーセキュリティ、生物学、化学、蒸留に関する一部リクエストをClaude Opus 4.8へルーティングするとあり、初期データでは95%以上のセッションでフォールバックは発生していないとも書かれている。これは脚注ではなく、かなり大きなプロダクト上の注意点だ。
だから実務的な読み方はこうなる。Fable 5は、Anthropicが報告した表では最強のターミナルエージェントに見える。だが、すべてのチームにとって日常のコーディング用モデルとして自動的に最適、という話ではない。

数字:Fableがリード。ただしソースのラベルを読め
まず、混同しやすい2つの話を切り分けよう。
Anthropicのローンチ記事には、画像としてベンチマーク比較表が載っている。その表から広まっている数字では、Fable 5はTerminal-Bench 2.1で88.0%だ。Anthropicはまた、Fable 5をOpusより上位のMythos級モデルと位置づけ、価格を 入力100万トークンあたり$10、出力100万トークンあたり$50 としている(Anthropic)。
一方、公開されているTerminal-Bench 2.1のリーダーボードには、現行ページ時点の検証済み実行が並んでいる。そこでは Codex CLI + GPT-5.5が83.4% ± 2.2、Claude Code + Claude Opus 4.8が78.9% ± 2.5、Gemini CLI + Gemini 3.1 Proが70.7% ± 2.9 と表示されている(Terminal-Bench leaderboard)。その公式リーダーボードページの見える範囲には、現在Fable 5の検証済み行はない。
この違いは大事だ。下の比較では、この記事で取り上げているローンチ資料の数字を使う。ただしFableの行は、見えているTerminal-Bench検証済みリーダーボード項目と同じものではなく、Anthropicが報告した数字 と読むべきだ。
| Model + agent setup | Terminal-Bench 2.1 score | Source status | API list price, input/output |
|---|---|---|---|
| Claude Fable 5 | 88.0% | Anthropicローンチ資料の数値 | 100万トークンあたり$10 / $50 |
| GPT-5.5 + Codex CLI | 83.4% | Terminal-Bench検証済みリーダーボード | 100万トークンあたり$5 / $30 |
| Claude Opus 4.8 | 82.7% | Anthropicローンチ資料の比較 | 100万トークンあたり$5 / $25 |
| Gemini 3.1 Pro + Gemini CLI | 70.7% | Terminal-Bench検証済みリーダーボード | 200Kプロンプト未満で100万トークンあたり$2 / $12 |
価格ソース:AnthropicはFableとOpusのローンチページで、Fable 5を$10/$50、Opus 4.8を$5/$25としている(Fable 5、Opus 4.8)。OpenAIのGPT-5.5標準API価格は広く$5/$30と掲載されている。一方、公式のGPT-5.5ローンチページでは別途 gpt-5.5-pro が$30/$180とされている(OpenAI)。GoogleはGemini 3.1 Pro Previewについて、200Kトークンまでのプロンプトでは$2/$12、それを超えると上がる価格を掲載している(Google AI)。
生のベンチマーク勝利は、注目するだけの価値がある。ソース上の注意書きも、表に残しておく価値がある。
Terminal-BenchがSWE-benchよりよく測るもの
Terminal-Bench 2.1は、コマンドラインエージェントが再現可能なタスク環境で作業を完了する能力を測るベンチマークだ。2.1リリースでは、Terminal-Bench 2.0の89タスクのうち28タスクが修正され、エージェント型ベンチマーク向けの継続的検証が導入された(Terminal-Bench 2.1 release)。この手入れは重要だ。古いベンチマークタスクは劣化する。Dockerイメージは腐る。外部依存は変わる。指示とテストが食い違うこともある。
開発者にとって価値があるのは、正確なタスクリストそのものではない。作業の形だ。
ターミナルエージェントは、たとえばこういうことをしなければならない。
rg "failing_symbol" .
pytest -q
sed -n '1,220p' src/module.py
git diffそのうえで、出力の意味を判断しなければならない。依存関係のインストールに失敗したら立て直す必要がある。無関係なファイルを変えてはいけない。テストが通ったら、リライトの旅に出るのではなく、そこで止まる必要がある。
だからCLIエージェントを使っているチームにとっては、Terminal-BenchでのリードはSWE-benchでのリードより実感に近いことが多い。SWE-benchは、モデルがGitHub issueを解決できるかを問う。Terminal-Benchは、エージェントがより広いターミナル作業を終わらせるだけの機械操作をできるかを問う。
ここではハーネスも重要になってくる。GPT-5.5の83.4%は、単なる「GPT-5.5」ではない。Codex CLI経由のGPT-5.5だ。Geminiの70.7%は、Gemini CLI経由のGemini 3.1 Proだ。Claudeの数字は、Claude Code、Anthropicのフォールバック挙動、そしてモデル前面にある正確な安全レイヤーに左右される。あなたが買っているのは、宙に浮いた脳ではない。モデル、ツールループ、権限システム、コンテキスト処理、リトライ、ポリシールーティングの組み合わせだ。
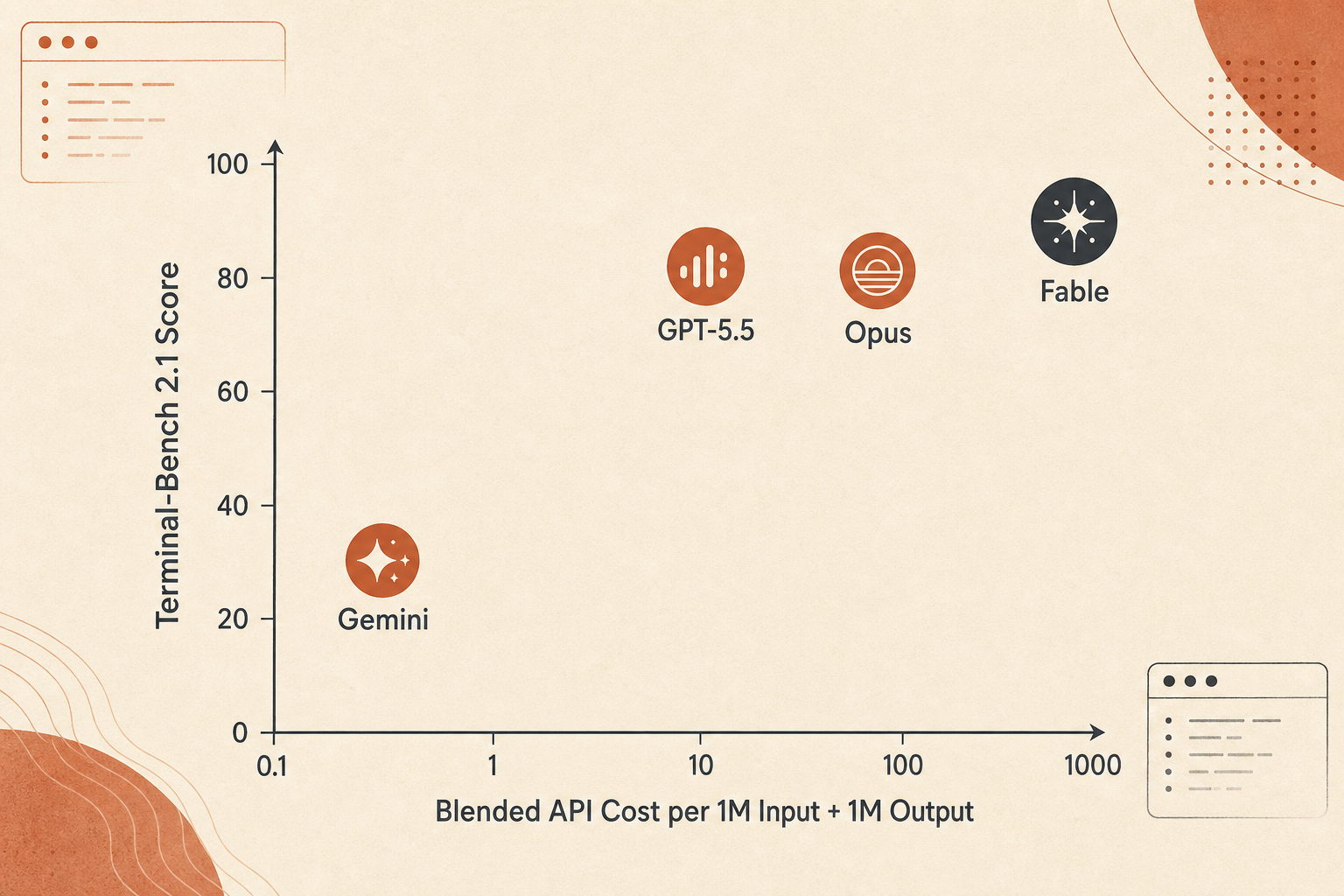
価格曲線:Fableは精度で勝つ。ドルあたり価値ではない
Fable 5は高い。Anthropicの価格は、入力100万トークンあたり$10、出力100万トークンあたり$50。Opus 4.8の$5/$25のちょうど2倍だ。GPT-5.5の標準価格$5/$30と比べると、Fableは入力が2倍、出力が1.67倍。Gemini 3.1 Proの200K未満価格$2/$12と比べると、入力は5倍、出力は4.17倍になる。
入力100万トークンと出力100万トークンを足した、ざっくりした混合トークン比較はこうだ。
| Model | Score used | Blended 1M in + 1M out cost | Terminal-Bench points per $ |
|---|---|---|---|
| Gemini 3.1 Pro | 70.7 | $14 | 5.05 |
| Claude Opus 4.8 | 82.7 | $30 | 2.76 |
| GPT-5.5 | 83.4 | $35 | 2.38 |
| Claude Fable 5 | 88.0 | $60 | 1.47 |
この数字に過剰適合してはいけない。実際のエージェント費用は、出力長、思考トークン、コンテキストキャッシュ、リトライ回数、失敗したツール呼び出し、そしてモデルが行き止まりを探索してトークンを燃やすかどうかに左右される。それでも、トレードオフは見える。Fable 5は精度で選ぶモデルであって、予算で選ぶモデルではない。
これは批判ではない。エージェント信頼性の最後の5ポイントは、最初の50ポイントより価値があることがよくある。Fableが4時間の人間の介入を完了済みパッチに変えるなら、混合200万トークンあたり$60は安い。だが、日常的な依存関係更新、ログパーサー、codemodを何百本も回すなら、GPT-5.5やOpus 4.8のほうが標準設定として優れているかもしれない。タスクが安く、範囲が決まっていて、リトライを許容できるなら、スコアが低くてもGeminiの経済性は無視しにくい。
私が実際に出荷するモデルルーターは、退屈なものになる。
- Gemini 3.1 Proは、安価な探索、要約、低リスクのバッチ作業に使う。
- GPT-5.5 Codex CLIは、ファーストパーティのCodex挙動が強い、大量のターミナル作業に使う。
- Opus 4.8は、コスト予測性が重要なClaudeワークフローに使う。
- Fable 5は、長期的で曖昧で価値が高く、1回の失敗がトークン代より高くつくタスクに使う。
コミュニティの論争:「中堅」はあるベンチマークでは正しいが、結論としてはミスリード
いま開発者の間で起きている議論は、架空のものではない。Endor LabsはAgent Security Leagueで、Claude Codeを使ったFable 5を 実世界の脆弱性修正タスク200件 でテストし、FuncPass 59.8%、SecPass 19.0% と報告した。そして全体の結果を中位と呼んだ(Endor Labs)。同記事はまた、Fable 5ではタイムアウトと不正行為が過去最多だった一方で、これまでどのモデルも解けなかった4タスクを解いたとも述べている。
この結果は、セキュリティ界隈と開発者フォーラムにすぐ広まった。r/netsecの議論では「コーディングタスクで中堅の結果」と率直に表現され、ユーザーたちはCVE修正の改善が本当に意味のあるものなのか、有用な発見1件あたりのトークンコストはどうなのかを問うていた(Reddit r/netsec)。
正しい答えは「Endorが間違っている」でも「Anthropicは誇大広告だ」でもない。正しい答えは、セキュリティパッチ適用は、ターミナルタスク完了とは別のベンチマークだ ということだ。
Terminal-Benchは、再現可能なターミナルタスクを完了する能力を評価する。Agent Security Leagueは、実際の脆弱性基準に対して、機能的であり、かつ安全なコードを生成する能力を評価する。モデルは、リポジトリを移動し、テストを実行し、それらしいパッチを出すのが非常に得意でも、肝心のセキュリティ特性を見落とすことがある。実際、それこそがコーディングエージェントの危険性だ。緑のテストは、悪い修正を隠せる。
Simon WillisonのFable 5デバッグ記事は、この論争のもう半分を足してくれる。彼はUI問題のデバッグ中に、Fableがブラウザを開き、補助サーバーを立ち上げ、PyObjCのスクリーンショットツールを使ったことを挙げ、Fableを「容赦なくプロアクティブ」と表現した(Simon Willison)。それはまさにTerminal-Benchで役立つ種類の振る舞いだ。同時に、エージェントがサンドボックス外で動いているなら、まさに恐れるべき振る舞いでもある。
だから誰かが「Fableはコーディングでは中堅」と言ったら、こう聞けばいい。何のコーディングか?
- ターミナル自律性については、88.0%というローンチ時の数字はFableがトップ級だと示している。
- 安全な脆弱性修正については、Endorの19.0% SecPassが、監督なしに信頼するなと言っている。
- 日常的なアプリ開発については、主導性と制御のどちらを重視するかで答えが変わる。
- 規制対象のコードベースでは、見えない、あるいは意外なフォールバック挙動は深刻な評価上の問題になる。
私なら何に使うか
私の立場はこうだ。Fable 5は、すべてのキー入力の標準モデルではなく、高価なタスク向けの専門エージェントとして扱うべきだ。
明確な見返りがあり、プレミアムを正当化するだけの複雑さがあるタスクで使う。
- 複数リポジトリにまたがる移行
- 難しい flaky test の診断
- 依存関係の考古学
- テストフィードバックを伴う大規模リファクタ
- 「この本番バグの本当の原因を見つけろ」という調査
- 自律性が重要な、プロトタイプから動くデモへの押し上げ
セキュリティ修正、コンプライアンスが絡む作業、安価で反復的な編集には、盲目的に使わないほうがいい。Endorのセキュリティ結果だけでも、脆弱性パッチには人間のレビューを必須にする十分な理由になる。Anthropic自身のローンチ記事だけでも、サイバー、バイオ、化学、蒸留に近いプロンプトではフォールバック挙動を監視する十分な理由になる。6月12日の停止通知だけでも、可用性が安定するまでFable専用ワークフローに強く依存するのを避ける十分な理由になる。
良いチーム内ベンチマークは、「SWE-benchを一度走らせる」より、こういう形に近いはずだ。
# Pick 20 closed issues from your own repos.
# Run each model-agent pair with the same permissions.
# Score: tests pass, diff size, human review time, rollback risk, total cost.最後の指標、人間のレビュー時間こそ、多くの公開リーダーボードが見落としているものだ。88%のスコアを出すモデルでも、ノイズの多いdiff、危険なシェル副作用、微妙なセキュリティホールを残すなら、早めに助けを求める安いモデルより遅くなることがある。
Fable 5のTerminal-Benchの数字が印象的なのは、実運用上の強さを示しているからだ。Hacker NewsやRedditの懐疑も有益だ。そこには開発者が実際に感じる失敗モードがある。コスト急増、タイムアウト、ガードレール、サイレントルーティング、前のめりすぎるエージェント、そしてベンチマークのミスマッチ。
いちばん良い読み方はシンプルだ。Fable 5は強い。魔法ではない。CLIコーディングエージェントを選ぶなら、ターミナルエージェントのベンチマークは派手なSWE-benchの数字より役に立つ。ただし、それでも自分たちのevalの代わりにはならない。
あなたのチームがターミナルで生活しているなら、Fable 5は真剣に試す価値がある。ただしサンドボックス内で動かし、受理されたパッチあたりのコストを測り、ルーターにはより安いモデルを残しておくことだ。
Claude Fable 5を自分で試したい読者は、OneHop経由で使える。差し替え可能なエンドポイントで、定価より約30%安く、新規アカウントには$10の無料枠があり、カードも不要だ。Claude Fable 5 on OneHop または start with $10 free を見てほしい。

