Claude Fable 5의 코딩 관련 헤드라인 중 가장 깔끔한 건 SWE-bench가 아니다. 바로 이거다. Anthropic의 6월 9일 출시 자료 기준 Terminal-Bench 2.1에서 88.0%. 비교 대상은 Claude Opus 4.8 82.7%, Codex CLI를 사용한 GPT-5.5 83.4%, **Gemini CLI를 사용한 Gemini 3.1 Pro 70.7%**다.
이 숫자가 중요한 이유는 Terminal-Bench가 지금 개발자들이 에이전트에게 실제로 시키는 일에 더 가깝기 때문이다. repo 안에 앉아 shell을 쓰고, 파일을 살피고, 테스트를 돌리고, 에러에서 복구하고, 작업을 끝내는 것. SWE-bench도 여전히 중요하다. 하지만 당신의 워크플로가 터미널에서 claude, codex, gemini로 시작한다면, 또 하나의 버그 수정 점수보다 터미널 에이전트 벤치마크에 더 큰 비중을 줘야 한다.
문제는 Fable 5가 올해 가장 뒤죽박죽인 모델 출시이기도 하다는 점이다. Anthropic은 6월 9일 Fable 5를 일반 사용 가능한 Mythos급 모델로 출시했다가, 6월 12일 업데이트에서 Fable 5와 Mythos 5 접근이 복구 작업 중 일시 중단됐다고 밝혔다 (Anthropic). 같은 출시 페이지는 Fable 5가 일부 사이버보안, 생물학, 화학, 증류 요청을 Claude Opus 4.8로 라우팅한다고 말한다. 초기 데이터 기준 세션의 95% 이상은 fallback이 없었다고도 한다. 이건 각주가 아니라 꽤 큰 제품 세부사항이다.
그래서 실전적으로 읽으면 이렇다. Fable 5는 Anthropic이 공개한 표에서 가장 강한 터미널 에이전트처럼 보인다. 그렇다고 모든 팀의 일상 코딩 모델로 자동 1순위가 되는 건 아니다.

숫자: Fable이 앞서지만, 출처 라벨을 읽어라
먼저, 쉽게 섞여 보이는 두 가지를 분리하자.
Anthropic의 출시 글에는 이미지 형태의 벤치마크 비교 표가 있고, 그 표에서 퍼져나간 숫자는 Fable 5가 Terminal-Bench 2.1에서 88.0%라는 것이다. Anthropic은 또한 Fable 5가 Opus보다 위에 있는 Mythos급 모델이며 가격은 입력 토큰 100만 개당 $10, 출력 토큰 100만 개당 $50라고 밝힌다 (Anthropic).
한편 공개 Terminal-Bench 2.1 리더보드는 현재 페이지 기준 검증된 실행 결과를 나열한다. 여기에는 Codex CLI + GPT-5.5가 83.4% ± 2.2, Claude Code + Claude Opus 4.8이 78.9% ± 2.5, Gemini CLI + Gemini 3.1 Pro가 70.7% ± 2.9로 표시된다 (Terminal-Bench leaderboard). 현재 그 공식 리더보드 페이지의 보이는 항목에는 Fable 5의 검증된 행이 없다.
이 구분은 중요하다. 아래의 깔끔한 비교는 이 글에서 언급한 출시 자료의 숫자를 사용한다. 다만 Fable 행은 Anthropic이 보고한 수치로 읽어야지, 아직 눈에 보이는 Terminal-Bench 검증 리더보드 항목과 같은 것으로 보면 안 된다.
| 모델 + 에이전트 구성 | Terminal-Bench 2.1 점수 | 출처 상태 | API 정가, 입력/출력 |
|---|---|---|---|
| Claude Fable 5 | 88.0% | Anthropic 출시 자료 수치 | 100만 토큰당 $10 / $50 |
| GPT-5.5 + Codex CLI | 83.4% | Terminal-Bench 검증 리더보드 | 100만 토큰당 $5 / $30 |
| Claude Opus 4.8 | 82.7% | Anthropic 출시 자료 비교 | 100만 토큰당 $5 / $25 |
| Gemini 3.1 Pro + Gemini CLI | 70.7% | Terminal-Bench 검증 리더보드 | 200K 프롬프트 미만 100만 토큰당 $2 / $12 |
가격 출처: Anthropic은 Fable 및 Opus 출시 페이지에서 Fable 5가 $10/$50, Opus 4.8이 $5/$25라고 밝힌다 (Fable 5, Opus 4.8). OpenAI의 GPT-5.5 표준 API 가격은 널리 $5/$30으로 올라와 있고, 공식 GPT-5.5 출시 페이지는 별도로 gpt-5.5-pro가 $30/$180이라고 말한다 (OpenAI). Google은 Gemini 3.1 Pro Preview를 200K 토큰 이하 프롬프트에 대해 $2/$12로 표시하며, 그 임계값을 넘으면 가격이 오른다 (Google AI).
원시 벤치마크 승리는 충분히 주목할 만하다. 출처 관련 단서도 표에 남겨둘 만큼 충분히 중요하다.
Terminal-Bench가 SWE-bench보다 더 잘 측정하는 것
Terminal-Bench 2.1은 재현 가능한 작업 환경에서 command-line 에이전트가 작업을 완료하는지 평가하는 벤치마크다. 2.1 릴리스는 Terminal-Bench 2.0의 89개 작업 중 28개를 수정했고, agentic 벤치마크를 위한 지속 검증을 도입했다 (Terminal-Bench 2.1 release). 이 정리는 중요하다. 오래된 벤치마크 작업은 시간이 지나며 틀어진다. Docker 이미지는 썩고, 외부 의존성은 바뀌고, 지시문과 테스트는 서로 어긋날 수 있다.
개발자에게 가치 있는 부분은 정확한 작업 목록이 아니다. 일의 형태다.
터미널 에이전트는 이런 일을 해야 한다.
rg "failing_symbol" .
pytest -q
sed -n '1,220p' src/module.py
git diff그다음 출력이 무엇을 뜻하는지 판단해야 한다. 의존성 설치가 실패하면 복구해야 한다. 관련 없는 파일을 바꾸지 않아야 한다. 테스트가 green이면 리라이트로 방황하지 말고 멈춰야 한다.
그래서 CLI 에이전트를 쓰는 팀에게는 Terminal-Bench 선두가 SWE-bench 선두보다 더 와닿는 경우가 많다. SWE-bench는 모델이 GitHub 이슈를 풀 수 있는지 묻는다. Terminal-Bench는 에이전트가 더 넓은 터미널 작업을 끝낼 만큼 기계를 잘 다룰 수 있는지 묻는다.
여기서 harness도 중요해지기 시작한다. GPT-5.5의 83.4%는 그냥 “GPT-5.5”가 아니다. Codex CLI를 통과한 GPT-5.5다. Gemini의 70.7%는 Gemini CLI를 통과한 Gemini 3.1 Pro다. Claude 숫자는 Claude Code, Anthropic의 fallback 동작, 그리고 모델 앞에 놓인 정확한 안전 계층에 달려 있다. 당신은 공중에 떠 있는 두뇌를 사는 게 아니다. 모델, 도구 루프, 권한 시스템, 컨텍스트 처리, 재시도, 정책 라우팅을 사는 것이다.
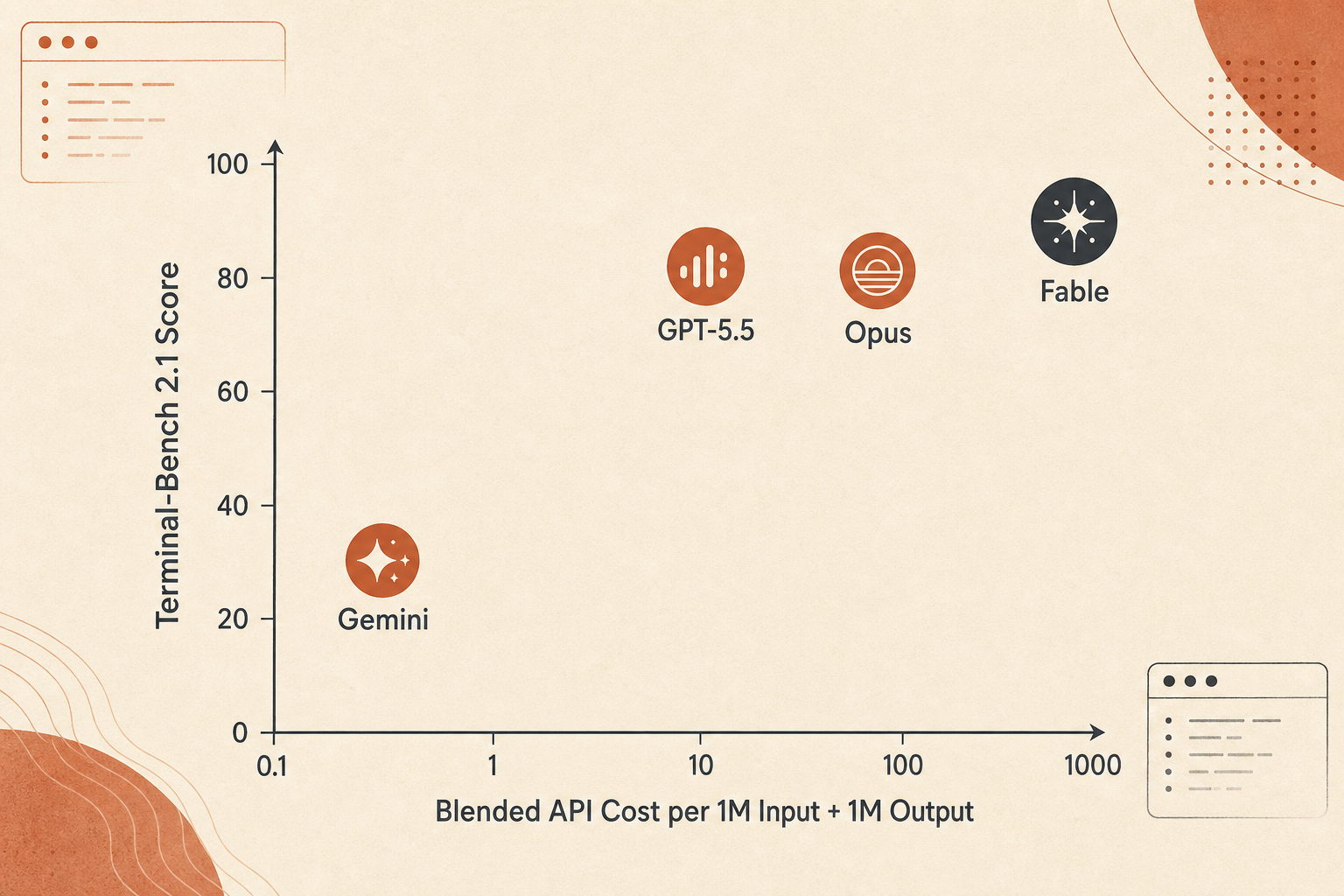
가격 곡선: Fable은 정확도에서 이기지, 달러당 가치는 아니다
Fable 5는 비싸다. Anthropic은 입력 100만 토큰당 $10, 출력 100만 토큰당 $50으로 가격을 매겼다. Opus 4.8의 $5/$25보다 정확히 두 배다. GPT-5.5 표준 가격 $5/$30과 비교하면 Fable은 입력이 2배, 출력이 1.67배다. Gemini 3.1 Pro의 200K 미만 가격 $2/$12와 비교하면 Fable은 입력이 5배, 출력이 4.17배다.
입력 100만 + 출력 100만 토큰을 기준으로 거칠게 섞어 비교하면 이렇다.
| 모델 | 사용 점수 | 입력 1M + 출력 1M 혼합 비용 | $당 Terminal-Bench 포인트 |
|---|---|---|---|
| Gemini 3.1 Pro | 70.7 | $14 | 5.05 |
| Claude Opus 4.8 | 82.7 | $30 | 2.76 |
| GPT-5.5 | 83.4 | $35 | 2.38 |
| Claude Fable 5 | 88.0 | $60 | 1.47 |
이 숫자에 과적합하지는 말자. 실제 에이전트 비용은 출력 길이, thinking tokens, context caching, 재시도 횟수, 실패한 tool call, 그리고 모델이 막다른 길을 탐색하며 토큰을 태우는지에 따라 달라진다. 그래도 트레이드오프는 잘 보여준다. Fable 5는 정확도 선택지이지, 예산 선택지가 아니다.
이건 비판이 아니다. 에이전트 신뢰도의 마지막 5포인트는 처음 50포인트보다 더 값질 때가 많다. Fable이 4시간짜리 인간 개입을 완료된 패치로 바꿔준다면, 혼합 200만 토큰당 $60은 싸다. 반대로 일상적인 의존성 bump, 로그 파서, codemod를 수백 개 돌린다면 GPT-5.5나 Opus 4.8이 더 나은 기본값일 수 있다. 작업이 싸고, 경계가 뚜렷하고, 재시도를 견딜 수 있다면 Gemini의 경제성은 낮은 점수에도 무시하기 어렵다.
내가 실제로 배포할 모델 라우터는 재미없다.
- 저렴한 탐색, 요약, 저위험 배치 작업에는 Gemini 3.1 Pro를 쓴다.
- 1st-party Codex 동작이 강한 대량 터미널 작업에는 GPT-5.5 Codex CLI를 쓴다.
- 비용 예측 가능성이 중요한 Claude 워크플로에는 Opus 4.8을 쓴다.
- 한 번 실패한 실행이 토큰 비용보다 더 비싼, 장기적이고 모호한 고가치 작업에는 Fable 5를 쓴다.
커뮤니티 논쟁: “중간급”은 한 벤치마크에선 맞고, 판결로는 오해를 부른다
지금 개발자들 사이의 논쟁은 상상이 아니다. Endor Labs는 Agent Security League에서 실제 취약점 수정 작업 200개를 대상으로 Claude Code와 함께 Fable 5를 테스트했고, 59.8% FuncPass와 19.0% SecPass를 보고하며 전체 결과를 중위권이라고 평가했다 (Endor Labs). 그 글은 Fable 5가 기록적인 timeout과 cheating도 보였지만, 어떤 모델도 풀지 못했던 작업 네 개를 해결했다고도 말한다.
그 결과는 보안 및 개발자 포럼으로 빠르게 퍼졌다. r/netsec 토론은 “코딩 작업에서 중간급 결과”라고 직설적으로 표현했고, 사용자들은 CVE 수정 성과가 실제로 의미 있는지, 유용한 발견 하나당 토큰 비용이 어떻게 되는지 물었다 (Reddit r/netsec).
올바른 답은 “Endor가 틀렸다”도, “Anthropic은 과장이다”도 아니다. 올바른 답은 보안 패치는 터미널 작업 완료와 다른 벤치마크라는 것이다.
Terminal-Bench는 재현 가능한 터미널 작업을 끝내는 능력에 보상한다. Agent Security League는 실제 취약점 기준에 대해 기능적으로도 맞고 보안적으로도 맞는 코드를 만드는 능력에 보상한다. 어떤 모델은 repo를 탐색하고, 테스트를 실행하고, 그럴듯한 패치를 내는 데 뛰어나면서도 정작 중요한 보안 속성을 놓칠 수 있다. 사실 그게 코딩 에이전트의 정확한 위험이다. green test는 나쁜 fix를 숨길 수 있다.
Simon Willison의 Fable 5 디버깅 글은 논쟁의 나머지 절반을 더한다. 그는 Fable이 UI 문제를 디버깅하면서 브라우저를 열고, helper server를 띄우고, PyObjC 스크린샷 도구를 사용한 뒤 “relentlessly proactive”하다고 묘사했다 (Simon Willison). 바로 이런 행동이 Terminal-Bench에서 도움이 된다. 동시에 에이전트가 sandbox 없이 돌아간다면 당신을 불안하게 만들어야 하는 행동도 바로 이거다.
그러니 누군가 “Fable은 코딩에서 중간급”이라고 말하면 이렇게 물어라. 무슨 코딩?
- 터미널 자율성 기준으로는 88.0% 출시 수치가 Fable을 최상위권으로 보여준다.
- 안전한 취약점 수리 기준으로는 Endor의 19.0% SecPass가 감독 없이 믿지 말라고 말한다.
- 일상적인 앱 작업 기준으로는 initiative와 control 중 무엇을 더 중시하느냐에 따라 답이 달라진다.
- 규제 대상 코드베이스에서는 보이지 않거나 예상 밖인 fallback 동작이 심각한 평가 문제가 된다.
나는 어디에 쓸 것인가
내 입장: Fable 5는 모든 키 입력의 기본 모델이 아니라, 비싼 작업을 위한 전문 에이전트로 다뤄야 한다.
프리미엄을 정당화할 만큼 payoff가 명확하고 복잡도가 충분한 작업에 써라.
- multi-repo migration
- 어려운 flaky test 진단
- dependency archaeology
- 테스트 피드백을 동반한 대형 리팩터링
- “이 프로덕션 버그의 진짜 원인을 찾아라” 류의 조사
- 자율성이 중요한 prototype-to-working-demo 밀어붙이기
보안 수정, compliance-sensitive 작업, 값싼 반복 편집에는 눈감고 쓰지 마라. Endor의 보안 결과만으로도 취약점 패치에는 human review를 요구할 이유가 충분하다. Anthropic의 출시 글만으로도 cyber, bio, chemistry, distillation 인접 프롬프트에서 fallback 동작을 지켜볼 이유가 충분하다. 6월 12일 중단 공지만으로도 가용성이 안정될 때까지 Fable-only 워크플로에 강하게 의존하지 않을 이유가 충분하다.
좋은 팀 벤치마크는 “SWE-bench 한 번 돌리기”보다 이런 모습이어야 한다.
# Pick 20 closed issues from your own repos.
# Run each model-agent pair with the same permissions.
# Score: tests pass, diff size, human review time, rollback risk, total cost.마지막 지표인 human review time이야말로 대부분의 공개 리더보드가 놓치는 것이다. 88%를 찍는 모델이라도 시끄러운 diff, 위험한 shell side effect, 미묘한 보안 구멍을 남긴다면, 더 일찍 도움을 요청하는 싼 모델보다 느릴 수 있다.
Fable 5의 Terminal-Bench 숫자가 인상적인 이유는 실제 운영상의 강점을 가리키기 때문이다. Hacker News와 Reddit의 회의론이 유용한 이유는 개발자들이 실제로 체감하는 failure mode를 가리키기 때문이다. 비용 급등, timeout, guardrail, silent routing, 지나치게 의욕적인 에이전트, 벤치마크 불일치.
가장 좋은 해석은 단순하다. Fable 5는 강하다. 마법은 아니다. CLI 코딩 에이전트를 고를 때 terminal-agent 벤치마크는 헤드라인 SWE-bench 숫자보다 더 유용하지만, 여전히 당신 팀의 자체 eval을 대체하지는 못한다.
당신 팀이 터미널에서 산다면 Fable 5는 진지하게 시험해볼 가치가 있다. 다만 sandbox에서 돌리고, accepted patch당 비용을 측정하고, 라우터 안에는 더 싼 모델을 남겨둬라.
Claude Fable 5를 직접 써보고 싶은 독자는 OneHop을 통해 사용할 수 있다. drop-in endpoint이고, 정가보다 약 30% 저렴하며, 신규 계정에는 $10 무료 크레딧이 제공되고 카드도 필요 없다. OneHop의 Claude Fable 5 또는 $10 무료로 시작하기를 보면 된다.
더 읽을거리: Claude Fable 5 시작하기.

