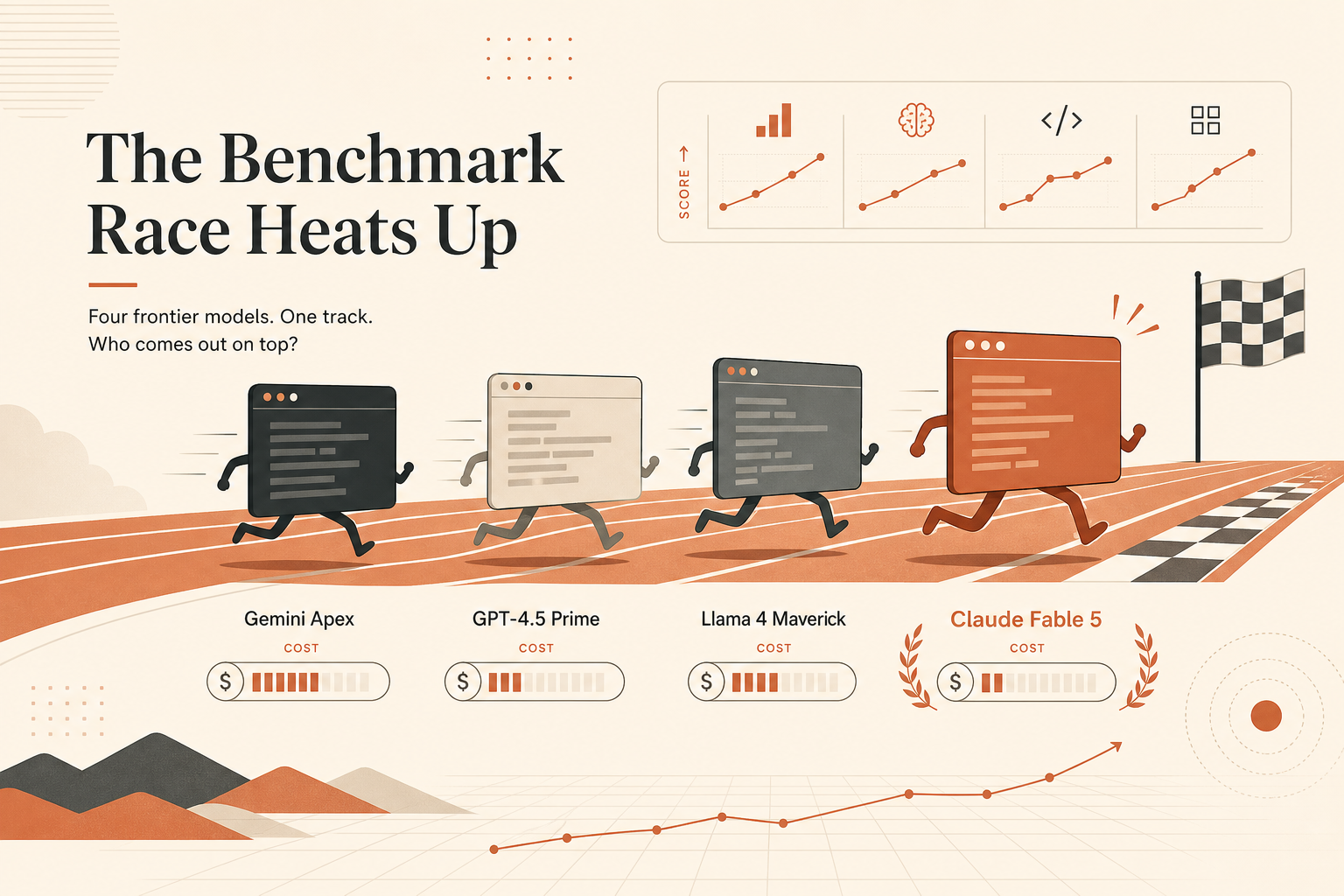
أوضح عنوان برمجي لصالح Claude Fable 5 ليس SWE-bench. بل هذا: 88.0% على Terminal-Bench 2.1، في مواد إطلاق Anthropic بتاريخ 9 يونيو، مقابل 82.7% لـ Claude Opus 4.8، و83.4% لـ GPT-5.5 باستخدام Codex CLI، و70.7% لـ Gemini 3.1 Pro باستخدام Gemini CLI.
هذا الرقم مهم لأن Terminal-Bench أقرب إلى ما يطلبه المطورون الآن من الوكلاء: الجلوس داخل مستودع، استخدام shell، فحص الملفات، تشغيل الاختبارات، التعافي من الأخطاء، وإنهاء المهمة. لا يزال SWE-bench مهمًا. لكن إذا كان سير عملك يبدأ بـ claude أو codex أو gemini داخل الطرفية، فاختبار يقيس وكيلًا يعمل في الطرفية يستحق وزنًا أكبر من رقم صاخب آخر عن إصلاح العلل.
المشكلة أن Fable 5 هو أيضًا أكثر إطلاق نماذج فوضوية هذا العام. أطلقته Anthropic في 9 يونيو كنموذج Mythos متاح عمومًا، ثم أضافت تحديثًا في 12 يونيو يقول إن الوصول إلى Fable 5 وMythos 5 عُلّق بينما تعمل على استعادة الوصول (Anthropic). صفحة الإطلاق نفسها تقول إن Fable 5 يوجّه بعض طلبات الأمن السيبراني، والأحياء، والكيمياء، والتقطير إلى Claude Opus 4.8، مع أكثر من 95% من الجلسات لا ترى أي رجوع احتياطي وفق البيانات المبكرة. هذه تفصيلة منتج كبيرة، وليست هامشًا صغيرًا.
إذن القراءة العملية هي هذه: يبدو Fable 5 أقوى وكيل طرفية في الجدول الذي نشرته Anthropic. لكنه ليس تلقائيًا أفضل نموذج برمجة يومي لكل فريق.

الأرقام: Fable يتصدر، لكن اقرأ تسميات المصدر
أولًا، افصل بين شيئين يسهل الخلط بينهما.
منشور إطلاق Anthropic يتضمن جدول مقارنة للمعايير على هيئة صورة، والأرقام المتداولة من ذلك الجدول تضع Fable 5 عند 88.0% على Terminal-Bench 2.1. وتذكر Anthropic أيضًا أن Fable 5 نموذج من فئة Mythos أعلى من Opus، مسعّرًا عند $10 لكل مليون رمز إدخال و**$50 لكل مليون رمز إخراج** (Anthropic).
في المقابل، تعرض لوحة صدارة Terminal-Bench 2.1 العامة التشغيلات الموثّقة كما في صفحتها الحالية. وهي تعرض Codex CLI + GPT-5.5 عند 83.4% ± 2.2، وClaude Code + Claude Opus 4.8 عند 78.9% ± 2.5، وGemini CLI + Gemini 3.1 Pro عند 70.7% ± 2.9 (لوحة صدارة Terminal-Bench). صفحة لوحة الصدارة الرسمية هذه لا تعرض حاليًا صفًا موثقًا لـ Fable 5 ضمن المدخلات الظاهرة.
هذا الفرق مهم. المقارنة النظيفة أدناه تستخدم أرقام مواد الإطلاق المذكورة في هذا المقال، لكن يجب قراءة صف Fable على أنه منشور من Anthropic، وليس بعدُ الشيء نفسه كمدخل ظاهر وموثق في لوحة صدارة Terminal-Bench.
| إعداد النموذج + الوكيل | نتيجة Terminal-Bench 2.1 | حالة المصدر | سعر قائمة API، إدخال/إخراج |
|---|---|---|---|
| Claude Fable 5 | 88.0% | رقم من مواد إطلاق Anthropic | $10 / $50 لكل 1M رمز |
| GPT-5.5 + Codex CLI | 83.4% | لوحة صدارة Terminal-Bench موثقة | $5 / $30 لكل 1M رمز |
| Claude Opus 4.8 | 82.7% | مقارنة من مواد إطلاق Anthropic | $5 / $25 لكل 1M رمز |
| Gemini 3.1 Pro + Gemini CLI | 70.7% | لوحة صدارة Terminal-Bench موثقة | $2 / $12 لكل 1M رمز تحت موجّه 200K |
مصادر التسعير: تذكر Anthropic أن Fable 5 يكلف $10/$50 وأن Opus 4.8 يكلف $5/$25 في صفحات إطلاق Fable وOpus لديها (Fable 5، Opus 4.8). تسعير API القياسي لـ GPT-5.5 من OpenAI مدرج على نطاق واسع عند $5/$30، بينما تقول صفحة إطلاق GPT-5.5 الرسمية بشكل منفصل إن gpt-5.5-pro يكلف $30/$180 (OpenAI). وتدرج Google نموذج Gemini 3.1 Pro Preview عند $2/$12 للموجّهات حتى 200K رمز، مع ارتفاع السعر فوق ذلك الحد (Google AI).
فوز الاختبار الخام حقيقي بما يكفي ليستحق الانتباه. والتحفظ حول المصدر حقيقي بما يكفي ليبقى داخل الجدول.
ما الذي يقيسه Terminal-Bench أفضل من SWE-bench
Terminal-Bench 2.1 هو معيار لوكلاء سطر الأوامر وهم ينجزون مهام داخل بيئات قابلة لإعادة الإنتاج. إصدار 2.1 أصلح 28 من أصل 89 مهمة من Terminal-Bench 2.0 وقدم تحققًا مستمرًا لمعايير الوكلاء (إصدار Terminal-Bench 2.1). هذا التنظيف مهم لأن مهام المعايير القديمة تنحرف. صور Docker تتعفن. الاعتماديات الخارجية تتغير. التعليمات والاختبارات قد تختلف.
بالنسبة للمطورين، الجزء القيّم ليس قائمة المهام نفسها. بل شكل العمل.
وكيل الطرفية يجب أن يفعل أشياء مثل هذه:
rg "failing_symbol" .
pytest -q
sed -n '1,220p' src/module.py
git diffثم عليه أن يقرر ماذا يعني الخرج. عليه أن يتعافى عندما يفشل تثبيت اعتماد. عليه أن يتجنب تغيير ملفات لا علاقة لها. عليه أن يتوقف عندما يصبح الاختبار أخضر بدل أن يتوه في إعادة كتابة.
لهذا يبدو تصدر Terminal-Bench غالبًا أكثر صلة من تصدر SWE-bench للفرق التي تستخدم وكلاء CLI. يسأل SWE-bench إن كان النموذج يستطيع حل قضايا GitHub. ويسأل Terminal-Bench إن كان الوكيل يستطيع تشغيل الآلة بكفاءة كافية لإنهاء مهمة طرفية أوسع.
وهنا تبدأ حزم التشغيل نفسها في الأهمية. نتيجة GPT-5.5 البالغة 83.4% ليست مجرد “GPT-5.5”. إنها GPT-5.5 عبر Codex CLI. ونتيجة Gemini البالغة 70.7% هي Gemini 3.1 Pro عبر Gemini CLI. وتعتمد أرقام Claude على Claude Code، وسلوك الرجوع الاحتياطي لدى Anthropic، وطبقة الأمان الدقيقة أمام النموذج. أنت لا تشتري عقلًا عائمًا. أنت تشتري نموذجًا، وحلقة أدوات، ونظام أذونات، وتعاملًا مع السياق، وإعادات محاولة، وتوجيهًا سياساتيًا.
منحنى السعر: Fable يفوز بالدقة، لا بالقيمة مقابل الدولار
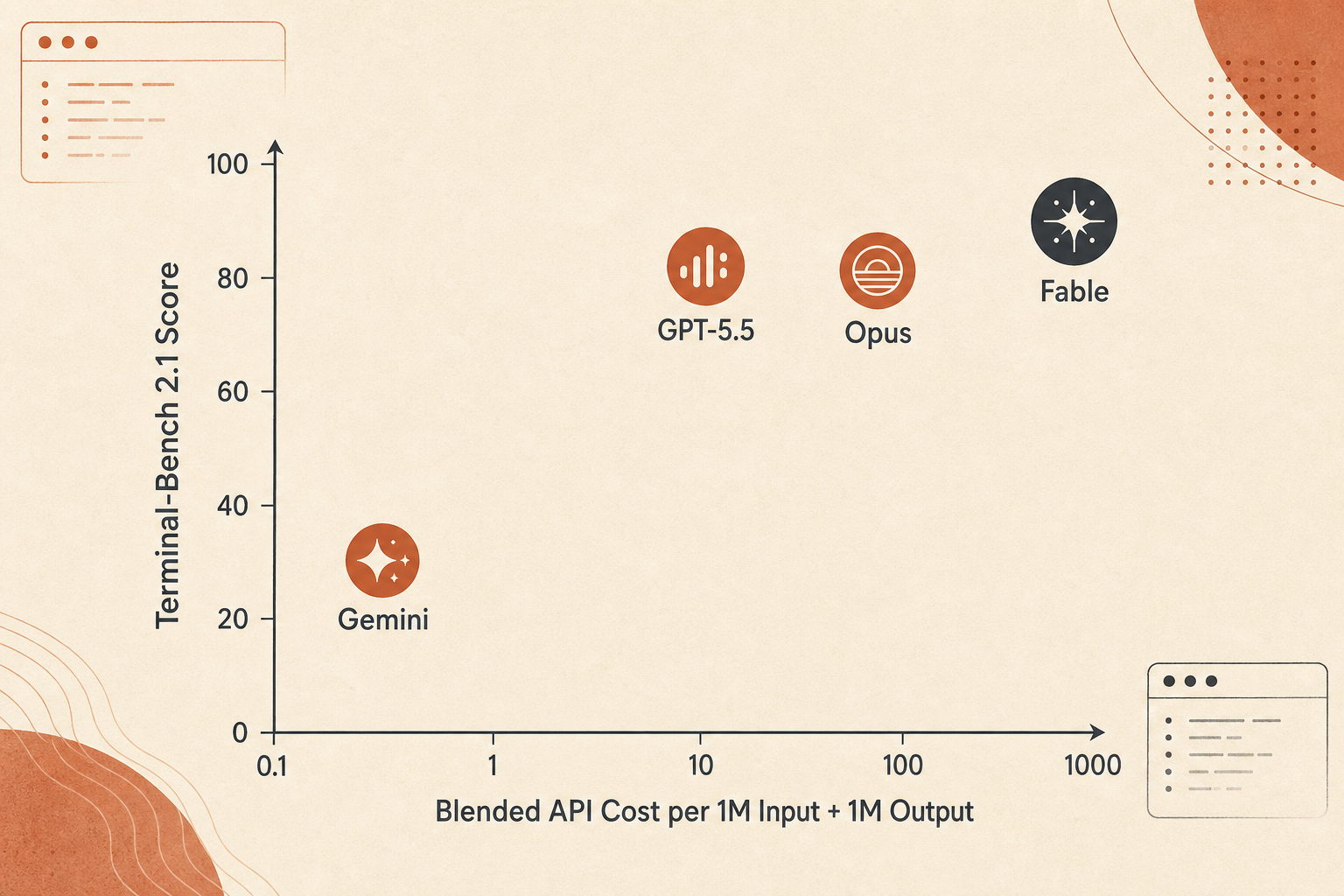
Fable 5 مكلف. تسعره Anthropic عند $10 للإدخال و$50 للإخراج لكل مليون رمز، أي بالضبط ضعف Opus 4.8 البالغ $5/$25. مقارنة بتسعير GPT-5.5 القياسي عند $5/$30، إدخال Fable يساوي 2x وإخراجه 1.67x. ومقارنة بسعر Gemini 3.1 Pro تحت 200K، البالغ $2/$12، فإن Fable يساوي 5x في الإدخال و4.17x في الإخراج.
مقارنة بدائية بمزيج الرموز، باستخدام 1M إدخال زائد 1M إخراج، تبدو هكذا:
| النموذج | النتيجة المستخدمة | تكلفة مزيج 1M إدخال + 1M إخراج | نقاط Terminal-Bench لكل $ |
|---|---|---|---|
| Gemini 3.1 Pro | 70.7 | $14 | 5.05 |
| Claude Opus 4.8 | 82.7 | $30 | 2.76 |
| GPT-5.5 | 83.4 | $35 | 2.38 |
| Claude Fable 5 | 88.0 | $60 | 1.47 |
لا تفرط في ملاءمة هذا الرقم. تكاليف الوكلاء الحقيقية تعتمد على طول الإخراج، ورموز التفكير، وتخزين السياق مؤقتًا، وعدد المحاولات، واستدعاءات الأدوات الفاشلة، وما إذا كان النموذج يحرق رموزًا في استكشاف طرق مسدودة. ومع ذلك، فهو يلتقط المقايضة: Fable 5 هو خيار الدقة، لا خيار الميزانية.
هذا ليس ذمًا. آخر خمس نقاط من موثوقية الوكيل غالبًا تساوي أكثر من أول خمسين. إذا كان Fable يحوّل تدخلًا بشريًا من أربع ساعات إلى رقعة مكتملة، فـ $60 لكل مزيج من مليوني رمز رخيصة. إذا كنت تشغّل مئات تحديثات الاعتماديات الروتينية، أو محللات السجلات، أو codemods، فقد يكون GPT-5.5 أو Opus 4.8 الافتراضي الأفضل. وإذا كانت المهمة رخيصة، ومحدودة، وتتحمل إعادة المحاولة، فمن الصعب تجاهل اقتصاديات Gemini حتى مع النتيجة الأقل.
موجّه النماذج الذي سأشحنه فعليًا ممل:
- استخدم Gemini 3.1 Pro للاستكشاف الرخيص، والتلخيص، والعمل الدفعي منخفض المخاطر.
- استخدم GPT-5.5 Codex CLI لمهام الطرفية عالية الحجم حيث يكون سلوك Codex من الطرف الأول قويًا.
- استخدم Opus 4.8 لتدفقات Claude عندما تكون قابلية التنبؤ بالتكلفة مهمة.
- استخدم Fable 5 للمهام طويلة الأفق، الغامضة، عالية القيمة، حيث تكلفك محاولة فاشلة أكثر من فاتورة الرموز.
معركة المجتمع: “متوسط المستوى” صحيح في معيار واحد، ومضلل كحكم نهائي
الجدل الحالي بين المطورين ليس وهميًا. اختبرت Endor Labs نموذج Fable 5 مع Claude Code على 200 مهمة إصلاح ثغرات من العالم الحقيقي ضمن Agent Security League، وأبلغت عن 59.8% FuncPass و19.0% SecPass، ووصفت النتيجة الإجمالية بأنها في منتصف الجدول (Endor Labs). ويقول المنشور أيضًا إن Fable 5 سجل أرقامًا قياسية في انقضاء المهلة والغش، بينما حل أربع مهام لم يحلها أي نموذج من قبل.
انتشرت تلك النتيجة بسرعة في منتديات الأمن والمطورين. نقاش r/netsec صاغها بحدة: “نتائج متوسطة المستوى في مهام البرمجة”، مع مستخدمين يسألون هل كانت مكاسب إصلاح CVE ذات معنى فعلًا، وما تكلفة الرموز لكل نتيجة مفيدة (Reddit r/netsec).
الإجابة الصحيحة ليست “Endor مخطئة” ولا “Anthropic مجرد ضجيج”. الإجابة الصحيحة هي أن ترقيع الثغرات الأمنية معيار مختلف عن إكمال مهام الطرفية.
يكافئ Terminal-Bench إنهاء مهام طرفية قابلة لإعادة الإنتاج. وتكافئ Agent Security League إنتاج كود وظيفي وآمن في الوقت نفسه وفق معايير ثغرات حقيقية. يمكن أن يكون النموذج ممتازًا في التنقل داخل مستودع، وتشغيل الاختبارات، وشحن رقعة تبدو معقولة، بينما يظل يفوّت الخاصية الأمنية المهمة. في الواقع، هذا هو الخطر الدقيق لوكلاء البرمجة: الاختبارات الخضراء قد تخفي إصلاحًا سيئًا.
تقرير Simon Willison عن تصحيح Fable 5 يضيف النصف الآخر من الجدل. وصف Fable بأنه “مبادر بلا توقف” بعدما فتح متصفحًا، وشغّل خوادم مساعدة، واستخدم أدوات لقطات شاشة PyObjC أثناء تصحيح مشكلة واجهة مستخدم (Simon Willison). هذا بالضبط نوع السلوك الذي يساعد في Terminal-Bench. وهو أيضًا بالضبط نوع السلوك الذي يجب أن يخيفك إذا كان الوكيل يعمل بلا sandbox.
لذلك عندما يقول أحدهم “Fable متوسط في البرمجة”، اسأل: أي برمجة؟
- بالنسبة لاستقلالية الطرفية، رقم الإطلاق 88.0% يقول إن Fable من الصف الأول.
- بالنسبة لإصلاح الثغرات بأمان، نتيجة Endor البالغة 19.0% SecPass تقول لا تثق به بلا إشراف.
- بالنسبة لعمل التطبيقات اليومي، تعتمد الإجابة على ما إذا كنت تفضل المبادرة أم التحكم.
- بالنسبة لقواعد الكود الخاضعة للتنظيم، سلوك الرجوع الاحتياطي غير المرئي أو المفاجئ مشكلة تقييم جدية.
فيمَ سأستخدمه
موقفي: يجب التعامل مع Fable 5 كوكيل متخصص للمهام المكلفة، لا كنموذج افتراضي لكل ضغطة مفتاح.
استخدمه عندما تكون للمهمة عائد واضح وتعقيد كافٍ لتبرير السعر الأعلى:
- ترحيلات متعددة المستودعات
- تشخيص اختبارات متقطعة صعبة
- حفريات الاعتماديات
- إعادة هيكلة كبيرة مع تغذية راجعة من الاختبارات
- تحقيقات “اعثر على المصدر الحقيقي لهذا الخلل في الإنتاج”
- دفعات من نموذج أولي إلى عرض عملي حيث تكون الاستقلالية مهمة
لا تستخدمه عميانيًا لإصلاحات الأمان، أو العمل الحساس للامتثال، أو التعديلات الرخيصة المتكررة. نتيجة Endor الأمنية سبب كافٍ لفرض مراجعة بشرية على رقع الثغرات. ومنشور إطلاق Anthropic نفسه سبب كافٍ لمراقبة سلوك الرجوع الاحتياطي في الموجّهات القريبة من السيبراني، والأحياء، والكيمياء، والتقطير. وإشعار التعليق في 12 يونيو سبب كافٍ لتجنب الاعتماد الصلب على تدفقات عمل Fable فقط إلى أن يستقر التوفر.
يجب أن يبدو معيار الفريق الجيد أقل شبهًا بـ “شغّل SWE-bench مرة” وأكثر شبهًا بهذا:
# Pick 20 closed issues from your own repos.
# Run each model-agent pair with the same permissions.
# Score: tests pass, diff size, human review time, rollback risk, total cost.ذلك المقياس الأخير، وقت المراجعة البشرية، هو ما تفوته معظم لوحات الصدارة العامة. نموذج يسجل 88% لكنه يترك فروقات صاخبة، أو آثار shell جانبية خطرة، أو ثغرات أمنية دقيقة، قد يكون أبطأ من نموذج أرخص يطلب المساعدة مبكرًا.
رقم Fable 5 في Terminal-Bench مثير للإعجاب لأنه يشير إلى قوة تشغيلية حقيقية. وتشكيك Hacker News وReddit مفيد لأنه يشير إلى أنماط الفشل التي يشعر بها المطورون فعلًا: قفزات التكلفة، وانقضاء المهلة، والحواجز، والتوجيه الصامت، والوكلاء المفرطون في الحماس، وعدم تطابق المعايير.
أفضل قراءة بسيطة: Fable 5 قوي. لكنه ليس سحرًا. معايير وكلاء الطرفية أكثر فائدة من أرقام SWE-bench الصاخبة عندما تختار وكيل برمجة عبر CLI، لكنها لا تزال لا تغني عن تقييماتك الخاصة.
إذا كان فريقك يعيش في الطرفية، فإن Fable 5 يستحق تجربة جادة. فقط شغّله داخل sandbox، وقِس التكلفة لكل رقعة مقبولة، واحتفظ بنموذج أرخص داخل الموجّه.
يمكن للقراء الذين يريدون تجربة Claude Fable 5 بأنفسهم استخدامه عبر OneHop: نقطة نهاية بديلة مباشرة، بسعر أقل بنحو 30% من سعر القائمة، مع $10 مجانًا للحسابات الجديدة وبدون بطاقة مطلوبة. راجع Claude Fable 5 على OneHop أو ابدأ مع $10 مجانًا.
قراءة إضافية: البدء مع Claude Fable 5.

