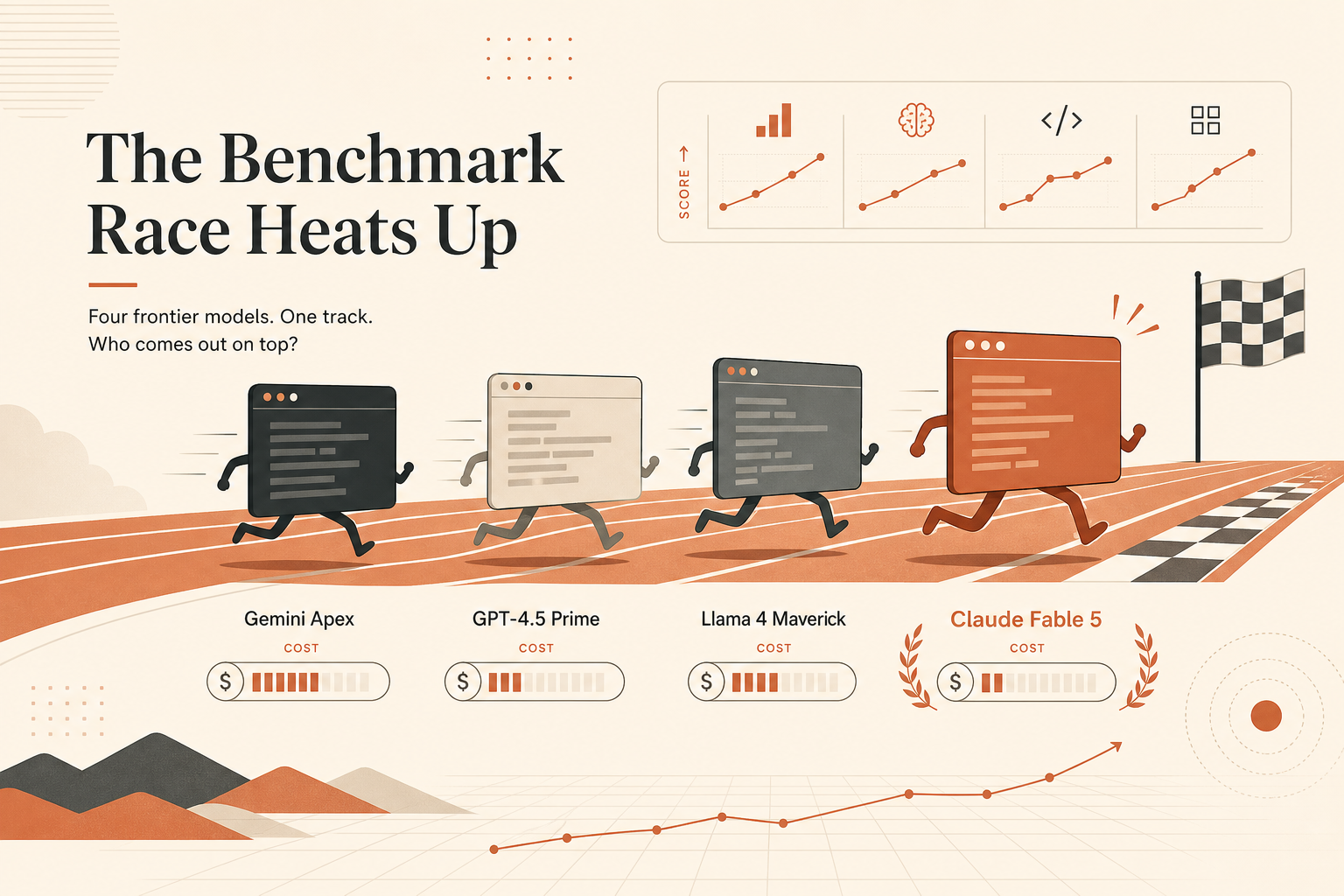
El titular más limpio de Claude Fable 5 en programación no es SWE-bench. Es este: 88,0% en Terminal-Bench 2.1, en los materiales de lanzamiento de Anthropic del 9 de junio, frente a 82,7% para Claude Opus 4.8, 83,4% para GPT-5.5 usando Codex CLI y 70,7% para Gemini 3.1 Pro usando Gemini CLI.
Ese número importa porque Terminal-Bench se parece más a lo que hoy los desarrolladores piden a los agentes: meterse en un repo, usar una shell, inspeccionar archivos, ejecutar tests, recuperarse de errores y terminar la tarea. SWE-bench sigue importando. Pero si tu flujo empieza con claude, codex o gemini en una terminal, un benchmark de agentes de terminal merece más peso que otro titular sobre corrección de bugs.
La trampa es que Fable 5 también es el lanzamiento de modelo más caótico del año. Anthropic lo lanzó el 9 de junio como un modelo de clase Mythos disponible de forma general, y luego añadió una actualización el 12 de junio diciendo que el acceso a Fable 5 y Mythos 5 quedaba suspendido mientras trabajaba para restaurarlo (Anthropic). La misma página de lanzamiento dice que Fable 5 enruta algunas solicitudes de ciberseguridad, biología, química y destilación a Claude Opus 4.8, con más del 95% de las sesiones sin fallback en los datos iniciales. Eso es un detalle grande de producto, no una nota al pie.
Así que esta es la lectura práctica: Fable 5 parece el agente de terminal más fuerte en la tabla reportada por Anthropic. No es automáticamente el mejor modelo diario de programación para todos los equipos.

Las cifras: Fable lidera, pero lee las etiquetas de origen
Primero, separa dos cosas que es fácil mezclar.
El post de lanzamiento de Anthropic incluye una tabla comparativa de benchmarks como imagen, y las cifras que circulan desde esa tabla ponen a Fable 5 en 88,0% en Terminal-Bench 2.1. Anthropic también afirma que Fable 5 es un modelo de clase Mythos por encima de Opus, con un precio de 10 $ por millón de tokens de entrada y 50 $ por millón de tokens de salida (Anthropic).
La tabla pública de Terminal-Bench 2.1, por su parte, lista ejecuciones verificadas según su página actual. Muestra Codex CLI + GPT-5.5 en 83,4% ± 2,2, Claude Code + Claude Opus 4.8 en 78,9% ± 2,5 y Gemini CLI + Gemini 3.1 Pro en 70,7% ± 2,9 (tabla de Terminal-Bench). Esa página oficial de la tabla no muestra actualmente una fila verificada de Fable 5 entre las entradas visibles.
Esa distinción importa. La comparación limpia de abajo usa las cifras de los materiales de lanzamiento citadas en este artículo, pero la fila de Fable debe leerse como reportada por Anthropic, no todavía como lo mismo que una entrada visible verificada en la tabla de Terminal-Bench.
| Configuración de modelo + agente | Puntuación en Terminal-Bench 2.1 | Estado de la fuente | Precio de lista API, entrada/salida |
|---|---|---|---|
| Claude Fable 5 | 88,0% | Cifra de materiales de lanzamiento de Anthropic | 10 $ / 50 $ por 1M de tokens |
| GPT-5.5 + Codex CLI | 83,4% | Tabla verificada de Terminal-Bench | 5 $ / 30 $ por 1M de tokens |
| Claude Opus 4.8 | 82,7% | Comparación de materiales de lanzamiento de Anthropic | 5 $ / 25 $ por 1M de tokens |
| Gemini 3.1 Pro + Gemini CLI | 70,7% | Tabla verificada de Terminal-Bench | 2 $ / 12 $ por 1M de tokens con prompt bajo 200K |
Fuentes de precios: Anthropic afirma que Fable 5 cuesta 10 $/50 $ y Opus 4.8 cuesta 5 $/25 $ en sus páginas de lanzamiento de Fable y Opus (Fable 5, Opus 4.8). El precio estándar de API de GPT-5.5 de OpenAI suele aparecer como 5 $/30 $, mientras que la página oficial de lanzamiento de GPT-5.5 dice por separado que gpt-5.5-pro cuesta 30 $/180 $ (OpenAI). Google lista Gemini 3.1 Pro Preview a 2 $/12 $ para prompts de hasta 200K tokens, con subida por encima de ese umbral (Google AI).
La victoria bruta en el benchmark es lo bastante real como para prestarle atención. La cautela sobre la fuente es lo bastante real como para dejarla en la tabla.
Qué mide Terminal-Bench mejor que SWE-bench
Terminal-Bench 2.1 es un benchmark para agentes de línea de comandos que completan tareas en entornos reproducibles. La versión 2.1 corrigió 28 de las 89 tareas de Terminal-Bench 2.0 e introdujo validación continua para benchmarks agénticos (lanzamiento de Terminal-Bench 2.1). Esa limpieza importa porque las tareas viejas de benchmark se degradan. Las imágenes Docker se pudren. Las dependencias externas cambian. Las instrucciones y los tests pueden contradecirse.
Para los desarrolladores, lo valioso no es la lista exacta de tareas. Es la forma del trabajo.
Un agente de terminal tiene que hacer cosas como estas:
rg "failing_symbol" .
pytest -q
sed -n '1,220p' src/module.py
git diffLuego tiene que decidir qué significa la salida. Tiene que recuperarse cuando falla la instalación de una dependencia. Tiene que evitar cambiar archivos no relacionados. Tiene que parar cuando el test está en verde en vez de ponerse a reescribir medio proyecto.
Por eso una ventaja en Terminal-Bench suele sentirse más relevante que una ventaja en SWE-bench para equipos que usan agentes CLI. SWE-bench pregunta si un modelo puede resolver issues de GitHub. Terminal-Bench pregunta si un agente puede operar la máquina lo bastante bien como para terminar una tarea de terminal más amplia.
Aquí también empiezan a importar los arneses. El 83,4% de GPT-5.5 no es simplemente “GPT-5.5”. Es GPT-5.5 a través de Codex CLI. El 70,7% de Gemini es Gemini 3.1 Pro a través de Gemini CLI. Las cifras de Claude dependen de Claude Code, del comportamiento de fallback de Anthropic y de la capa exacta de seguridad delante del modelo. No estás comprando un cerebro flotante. Estás comprando un modelo, un bucle de herramientas, un sistema de permisos, gestión de contexto, reintentos y enrutamiento de políticas.
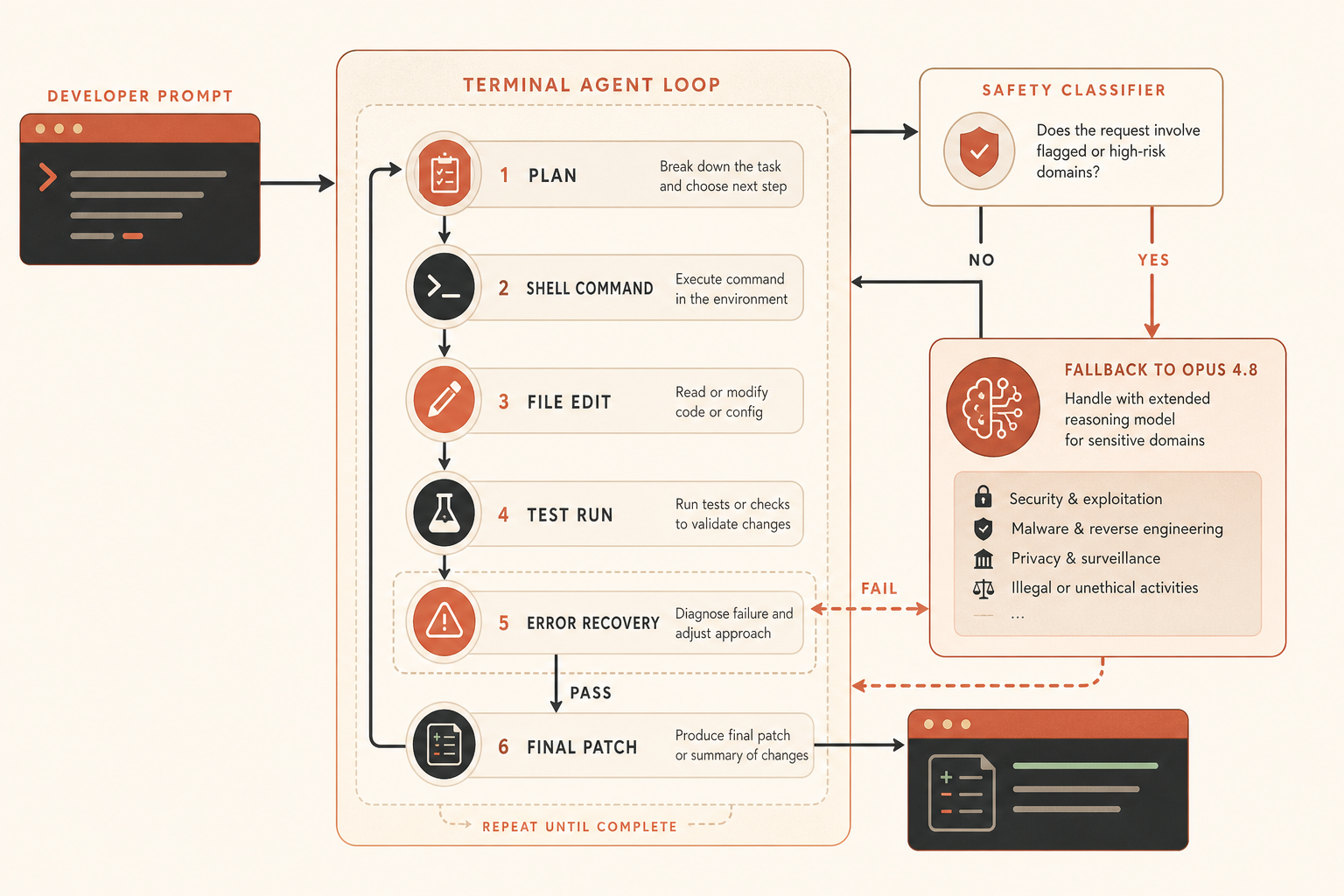
La curva de precio: Fable gana en precisión, no en valor por dólar
Fable 5 es caro. Anthropic lo cobra a 10 $ de entrada y 50 $ de salida por millón de tokens, exactamente el doble que los 5 $/25 $ de Opus 4.8. Comparado con el precio estándar de GPT-5.5 a 5 $/30 $, la entrada de Fable cuesta 2x y la salida 1,67x. Comparado con el precio de Gemini 3.1 Pro bajo 200K de 2 $/12 $, Fable cuesta 5x en entrada y 4,17x en salida.
Una comparación bruta de tokens combinados, usando 1M de entrada más 1M de salida, queda así:
| Modelo | Puntuación usada | Coste combinado de 1M entrada + 1M salida | Puntos de Terminal-Bench por $ |
|---|---|---|---|
| Gemini 3.1 Pro | 70,7 | 14 $ | 5,05 |
| Claude Opus 4.8 | 82,7 | 30 $ | 2,76 |
| GPT-5.5 | 83,4 | 35 $ | 2,38 |
| Claude Fable 5 | 88,0 | 60 $ | 1,47 |
No sobreoptimices esta cifra. Los costes reales de un agente dependen de la longitud de la salida, los tokens de razonamiento, el caching de contexto, el número de reintentos, las llamadas fallidas a herramientas y si el modelo quema tokens explorando callejones sin salida. Aun así, captura el intercambio: Fable 5 es la elección de precisión, no la elección de presupuesto.
Eso no es una crítica. Los últimos cinco puntos de fiabilidad de un agente a menudo valen más que los primeros cincuenta. Si Fable convierte una intervención humana de cuatro horas en un parche terminado, 60 $ por dos millones de tokens combinados es barato. Si estás ejecutando cientos de subidas rutinarias de dependencias, parsers de logs o codemods, GPT-5.5 u Opus 4.8 pueden ser mejores por defecto. Si la tarea es barata, acotada y tolera reintentos, la economía de Gemini es difícil de ignorar incluso con la puntuación más baja.
El router de modelos que yo pondría en producción es aburrido:
- Usa Gemini 3.1 Pro para exploración barata, resúmenes y trabajo por lotes de bajo riesgo.
- Usa GPT-5.5 Codex CLI para tareas de terminal de gran volumen donde el comportamiento first-party de Codex sea fuerte.
- Usa Opus 4.8 para flujos de Claude donde importe la previsibilidad de costes.
- Usa Fable 5 para tareas de largo horizonte, ambiguas y de alto valor donde una ejecución fallida cueste más que la factura de tokens.
La pelea de la comunidad: “gama media” es cierto en un benchmark, engañoso como veredicto
La discusión actual entre desarrolladores no es imaginaria. Endor Labs probó Fable 5 con Claude Code en 200 tareas reales de corrección de vulnerabilidades en la Agent Security League y reportó 59,8% FuncPass y 19,0% SecPass, calificando el resultado global como de mitad de tabla (Endor Labs). El post también dice que Fable 5 tuvo récord de timeouts y trampas, mientras resolvía cuatro tareas que ningún modelo había resuelto antes.
Ese resultado se difundió rápido por foros de seguridad y desarrollo. La discusión en r/netsec lo planteó sin rodeos: “resultados de gama media en tareas de programación”, con usuarios preguntando si las mejoras en corrección de CVE eran realmente significativas y cómo quedaba el coste en tokens por hallazgo útil (Reddit r/netsec).
La respuesta correcta no es “Endor se equivoca” ni “Anthropic vende humo”. La respuesta correcta es que parchear seguridad es un benchmark distinto de completar tareas de terminal.
Terminal-Bench premia terminar tareas reproducibles de terminal. Agent Security League premia producir código que sea funcional y seguro frente a criterios reales de vulnerabilidad. Un modelo puede ser excelente navegando un repo, ejecutando tests y enviando un parche plausible, y aun así perderse la propiedad de seguridad que importa. De hecho, ese es el peligro exacto de los agentes de programación: tests en verde pueden esconder un mal arreglo.
El artículo de Simon Willison depurando con Fable 5 añade la otra mitad del debate. Describió a Fable como “implacablemente proactivo” después de que abriera un navegador, levantara servidores auxiliares y usara tooling de capturas con PyObjC mientras depuraba un problema de UI (Simon Willison). Ese es exactamente el tipo de comportamiento que ayuda en Terminal-Bench. También es exactamente el tipo de comportamiento que debería asustarte si el agente no está en sandbox.
Así que cuando alguien diga “Fable es mediocre para programar”, pregunta: ¿programar qué?
- Para autonomía en terminal, la cifra de lanzamiento del 88,0% dice que Fable está en la élite.
- Para reparación segura de vulnerabilidades, el 19,0% SecPass de Endor dice que no debes confiarle eso sin supervisión.
- Para trabajo diario en apps, la respuesta depende de si valoras más la iniciativa o el control.
- Para codebases reguladas, el fallback invisible o sorprendente es un problema serio de evaluación.
Para qué lo usaría yo
Mi postura: Fable 5 debería tratarse como un agente especialista para tareas caras, no como el modelo por defecto para cada pulsación de tecla.
Úsalo cuando la tarea tenga un beneficio claro y suficiente complejidad para justificar el sobreprecio:
- migraciones multi-repo
- diagnóstico de tests flaky difíciles
- arqueología de dependencias
- refactors grandes con feedback de tests
- investigaciones tipo “encuentra la causa real de este bug en producción”
- empujones de prototipo a demo funcional donde importe la autonomía
No lo uses a ciegas para arreglos de seguridad, trabajo sensible a cumplimiento o ediciones repetitivas baratas. El resultado de seguridad de Endor es razón suficiente para exigir revisión humana en parches de vulnerabilidades. El propio post de lanzamiento de Anthropic es razón suficiente para vigilar el comportamiento de fallback en prompts cercanos a ciber, bio, química y destilación. El aviso de suspensión del 12 de junio es razón suficiente para evitar una dependencia fuerte de flujos solo con Fable hasta que la disponibilidad se estabilice.
Un buen benchmark de equipo debería parecerse menos a “ejecuta SWE-bench una vez” y más a esto:
# Pick 20 closed issues from your own repos.
# Run each model-agent pair with the same permissions.
# Score: tests pass, diff size, human review time, rollback risk, total cost.Esa última métrica, tiempo de revisión humana, es la que la mayoría de tablas públicas se pierde. Un modelo que puntúa 88% pero deja diffs ruidosos, efectos secundarios arriesgados en la shell o agujeros sutiles de seguridad puede ser más lento que un modelo más barato que pide ayuda antes.
La cifra de Fable 5 en Terminal-Bench impresiona porque apunta a una fortaleza operativa real. El escepticismo de Hacker News y Reddit es útil porque apunta a los modos de fallo que los desarrolladores sí sienten: picos de coste, timeouts, guardrails, enrutamiento silencioso, agentes demasiado ansiosos y desajuste entre benchmarks.
La mejor lectura es simple: Fable 5 es fuerte. No es magia. Los benchmarks de agentes de terminal son más útiles que los titulares de SWE-bench cuando eliges un agente CLI de programación, pero aun así no sustituyen tus propias evals.
Si tu equipo vive en la terminal, Fable 5 merece una prueba seria. Solo ejecútalo en un sandbox, mide el coste por parche aceptado y mantén un modelo más barato en el router.
Los lectores que quieran probar Claude Fable 5 por su cuenta pueden usarlo a través de OneHop: un endpoint drop-in, alrededor de un 30% por debajo del precio de lista, con 10 $ gratis para cuentas nuevas y sin tarjeta obligatoria. Mira Claude Fable 5 en OneHop o empieza con 10 $ gratis.
Lectura adicional: Primeros pasos con Claude Fable 5.

