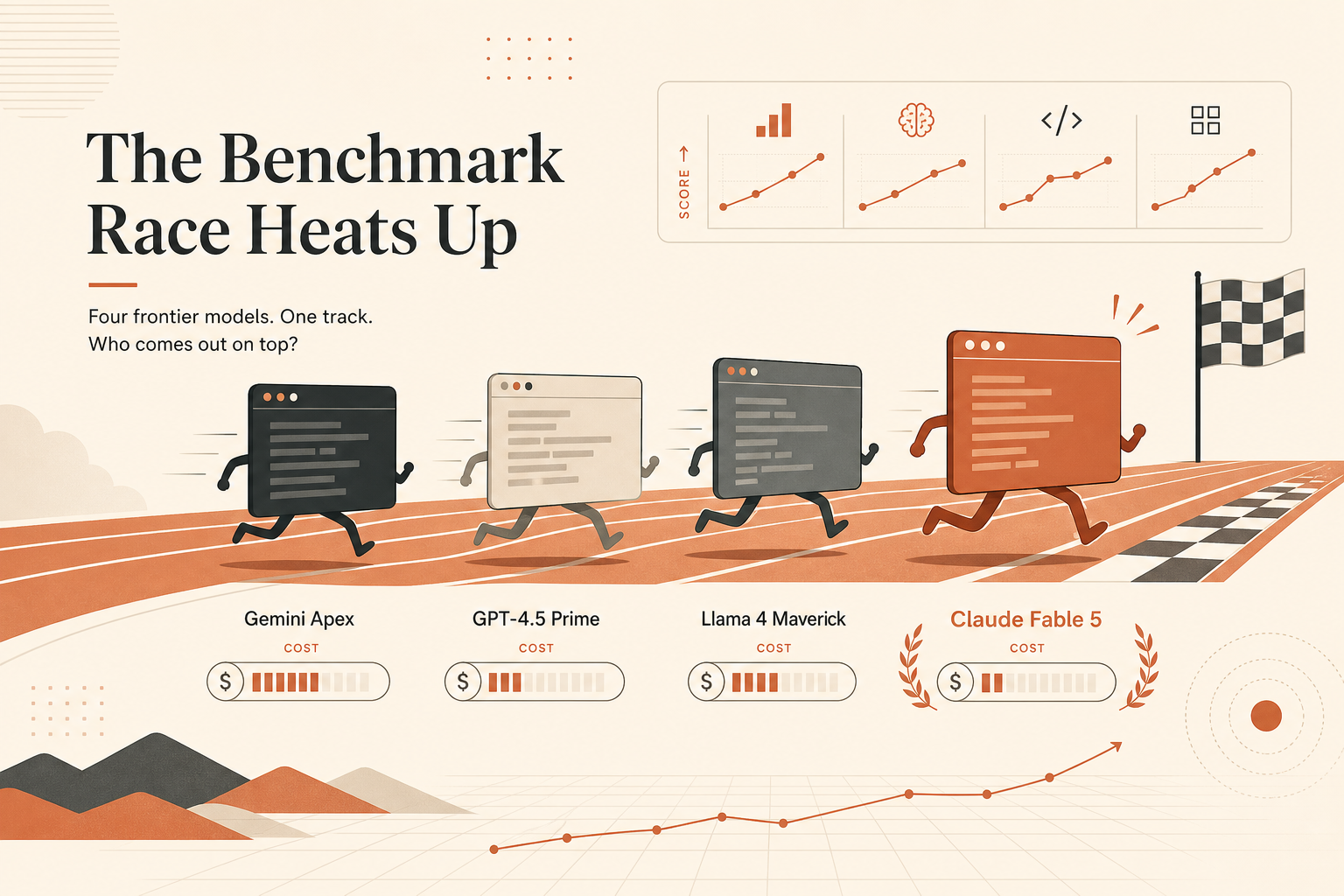
Claude Fable 5’in kodlama tarafındaki en temiz manşeti SWE-bench değil. Şu: Anthropic’in 9 Haziran lansman materyallerinde Terminal-Bench 2.1’de %88,0; buna karşılık Claude Opus 4.8 için %82,7, Codex CLI kullanan GPT-5.5 için %83,4 ve Gemini CLI kullanan Gemini 3.1 Pro için %70,7.
Bu sayı önemli, çünkü Terminal-Bench geliştiricilerin artık ajanlardan istediği şeye daha yakın: bir repoya oturmak, shell kullanmak, dosyaları incelemek, testleri çalıştırmak, hatalardan toparlanmak ve işi bitirmek. SWE-bench hâlâ önemli. Ama iş akışınız terminalde claude, codex veya gemini ile başlıyorsa, bir terminal-ajan benchmark’ı bir başka manşetlik bug-fix skorundan daha fazla ağırlık hak eder.
İşin pürüzü şu: Fable 5 aynı zamanda yılın en dağınık model lansmanı. Anthropic onu 9 Haziran’da genel erişime açık Mythos sınıfı bir model olarak duyurdu, ardından 12 Haziran’da Fable 5 ve Mythos 5 erişiminin, erişimi geri getirmek için çalışılırken askıya alındığını söyleyen bir güncelleme ekledi (Anthropic). Aynı lansman sayfası, Fable 5’in bazı siber güvenlik, biyoloji, kimya ve distilasyon isteklerini Claude Opus 4.8’e yönlendirdiğini; erken verilerde oturumların %95’inden fazlasında fallback görülmediğini söylüyor. Bu büyük bir ürün detayı, dipnot değil.
Pratik okuma şu: Fable 5, Anthropic’in bildirdiği tabloda en güçlü terminal ajanı gibi görünüyor. Ama bu, her ekip için otomatik olarak en iyi günlük kodlama modeli olduğu anlamına gelmiyor.

Sayılar: Fable Önde, ama Kaynak Etiketlerini Okuyun
Önce birbirine karıştırması kolay iki şeyi ayıralım.
Anthropic’in lansman yazısında görsel olarak bir benchmark karşılaştırma tablosu var ve o tablodan dolaşıma giren sayılar Fable 5’i Terminal-Bench 2.1’de %88,0 gösteriyor. Anthropic ayrıca Fable 5’in Opus’un üzerinde Mythos sınıfı bir model olduğunu, fiyatının da milyon input token başına $10 ve milyon output token başına $50 olduğunu söylüyor (Anthropic).
Öte yandan herkese açık Terminal-Bench 2.1 liderlik tablosu, mevcut sayfası itibarıyla doğrulanmış koşuları listeliyor. Orada Codex CLI + GPT-5.5 %83,4 ± 2,2, Claude Code + Claude Opus 4.8 %78,9 ± 2,5 ve Gemini CLI + Gemini 3.1 Pro %70,7 ± 2,9 görünüyor (Terminal-Bench leaderboard). Bu resmi liderlik tablosu sayfasında, görünen kayıtlarda şu anda doğrulanmış bir Fable 5 satırı yok.
Bu ayrım önemli. Aşağıdaki temiz karşılaştırma bu yazıda adı geçen lansman materyali sayılarını kullanıyor, ama Fable satırı Anthropic tarafından bildirildi diye okunmalı; henüz görünür bir Terminal-Bench doğrulanmış liderlik tablosu kaydıyla aynı şey değil.
| Model + ajan kurulumu | Terminal-Bench 2.1 skoru | Kaynak durumu | API liste fiyatı, input/output |
|---|---|---|---|
| Claude Fable 5 | %88,0 | Anthropic lansman materyali rakamı | 1M token başına $10 / $50 |
| GPT-5.5 + Codex CLI | %83,4 | Terminal-Bench doğrulanmış liderlik tablosu | 1M token başına $5 / $30 |
| Claude Opus 4.8 | %82,7 | Anthropic lansman materyali karşılaştırması | 1M token başına $5 / $25 |
| Gemini 3.1 Pro + Gemini CLI | %70,7 | Terminal-Bench doğrulanmış liderlik tablosu | 200K prompt altında 1M token başına $2 / $12 |
Fiyat kaynakları: Anthropic, Fable ve Opus lansman sayfalarında Fable 5’in $10/$50, Opus 4.8’in $5/$25 tuttuğunu belirtiyor (Fable 5, Opus 4.8). OpenAI’ın GPT-5.5 standart API fiyatı yaygın biçimde $5/$30 olarak listeleniyor; resmi GPT-5.5 lansman sayfası ayrıca gpt-5.5-pro için $30/$180 diyor (OpenAI). Google, Gemini 3.1 Pro Preview’ı 200K token’a kadar prompt’lar için $2/$12 olarak listeliyor; bu eşiğin üstünde fiyat artıyor (Google AI).
Ham benchmark galibiyeti dikkat etmeye fazlasıyla değer. Kaynak uyarısı da tabloda tutulmaya fazlasıyla değer.
Terminal-Bench, SWE-bench’ten Neyi Daha İyi Ölçüyor
Terminal-Bench 2.1, komut satırı ajanlarının tekrarlanabilir görev ortamlarında işleri tamamlamasını ölçen bir benchmark. 2.1 sürümü, Terminal-Bench 2.0’daki 89 görevin 28’ini düzeltti ve ajan benchmark’ları için sürekli doğrulama getirdi (Terminal-Bench 2.1 release). Bu temizlik önemli, çünkü eski benchmark görevleri zamanla kayar. Docker image’ları çürür. Harici bağımlılıklar değişir. Talimatlarla testler birbirini tutmayabilir.
Geliştiriciler için değerli olan şey tam görev listesi değil. İşin biçimi.
Bir terminal ajanının şuna benzer şeyler yapması gerekir:
rg "failing_symbol" .
pytest -q
sed -n '1,220p' src/module.py
git diffSonra çıktının ne anlama geldiğine karar vermesi gerekir. Bir dependency kurulumu patladığında toparlanması gerekir. Alakasız dosyaları değiştirmemesi gerekir. Test yeşile döndüğünde durması gerekir; işi komple yeniden yazmaya dalmaması gerekir.
CLI ajanları kullanan ekipler için Terminal-Bench liderliğinin SWE-bench liderliğinden sık sık daha alakalı hissettirmesi bu yüzden. SWE-bench, bir modelin GitHub issue’larını çözüp çözemediğini sorar. Terminal-Bench ise bir ajanın daha geniş bir terminal görevini bitirecek kadar makineyi iyi kullanıp kullanamadığını sorar.
Harness’ların önem kazanmaya başladığı yer de burası. GPT-5.5’in %83,4’ü sadece “GPT-5.5” değil. Codex CLI üzerinden GPT-5.5. Gemini’nin %70,7’si Gemini CLI üzerinden Gemini 3.1 Pro. Claude sayıları Claude Code’a, Anthropic’in fallback davranışına ve modelin önündeki tam güvenlik katmanına bağlı. Havada süzülen bir beyin satın almıyorsunuz. Bir model, bir araç döngüsü, bir izin sistemi, context yönetimi, retry’lar ve policy routing satın alıyorsunuz.
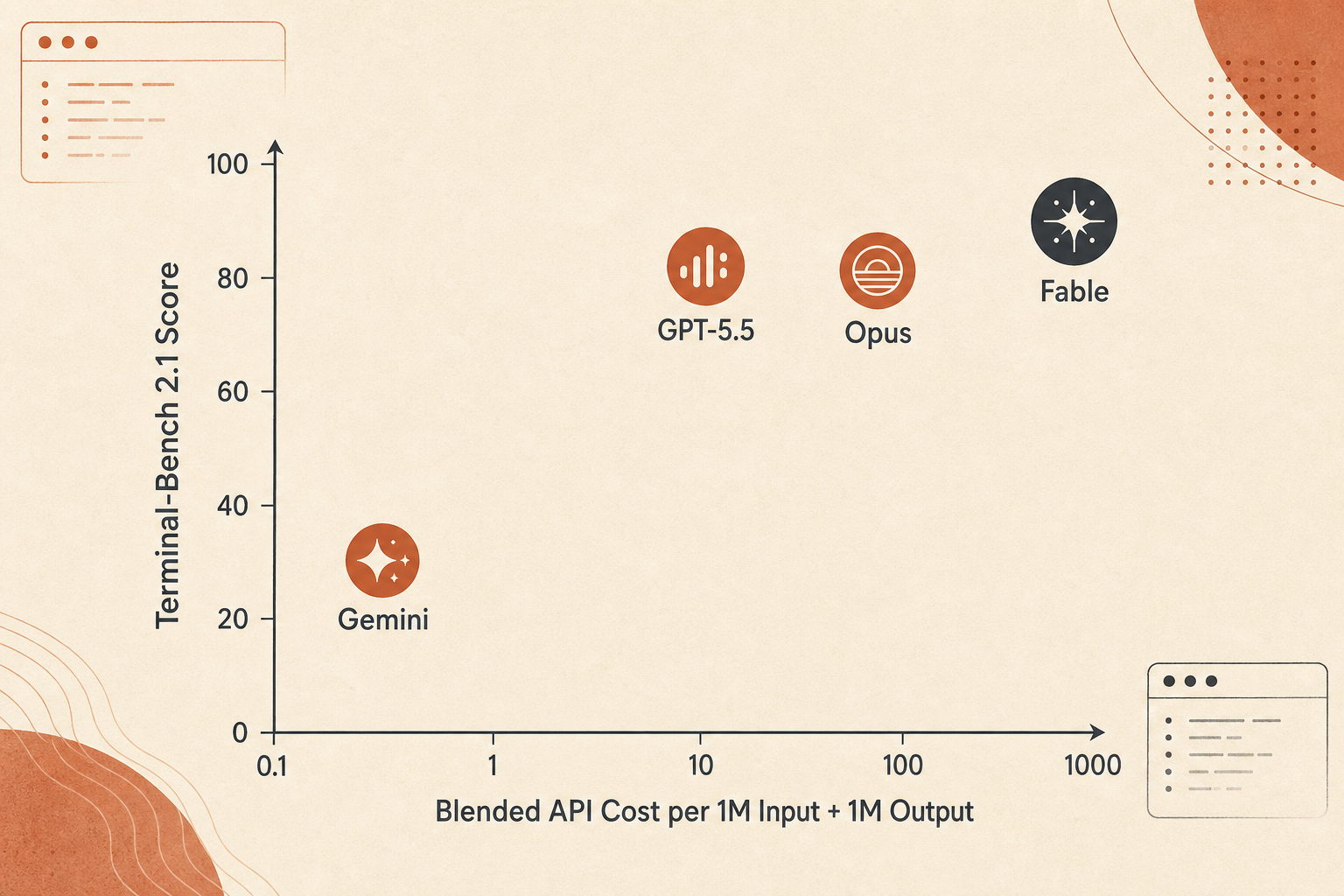
Fiyat Eğrisi: Fable Doğrulukta Kazanıyor, Dolar Başına Değerde Değil
Fable 5 pahalı. Anthropic onu milyon token başına $10 input ve $50 output olarak fiyatlıyor; bu Opus 4.8’in $5/$25 fiyatının tam iki katı. GPT-5.5’in standart $5/$30 fiyatıyla karşılaştırıldığında Fable’ın input’u 2 kat, output’u 1,67 kat. Gemini 3.1 Pro’nun 200K altı $2/$12 fiyatıyla karşılaştırıldığında Fable input’ta 5 kat, output’ta 4,17 kat.
1M input artı 1M output kullanan kaba bir birleşik-token karşılaştırması şöyle görünüyor:
| Model | Kullanılan skor | Birleşik 1M in + 1M out maliyeti | $ başına Terminal-Bench puanı |
|---|---|---|---|
| Gemini 3.1 Pro | 70,7 | $14 | 5,05 |
| Claude Opus 4.8 | 82,7 | $30 | 2,76 |
| GPT-5.5 | 83,4 | $35 | 2,38 |
| Claude Fable 5 | 88,0 | $60 | 1,47 |
Bu rakama fazla yapışmayın. Gerçek ajan maliyetleri output uzunluğuna, düşünme token’larına, context caching’e, retry sayısına, başarısız tool call’lara ve modelin kör sokakları araştırırken token yakıp yakmadığına bağlı. Yine de takası yakalıyor: Fable 5 doğruluk tercihi, bütçe tercihi değil.
Bu bir eleştiri değil. Ajan güvenilirliğinin son beş puanı çoğu zaman ilk elli puanından daha değerlidir. Fable dört saatlik insan müdahalesini tamamlanmış bir patch’e çeviriyorsa, birleşik iki milyon token başına $60 ucuzdur. Yüzlerce rutin dependency bump, log parser veya codemod çalıştırıyorsanız, GPT-5.5 ya da Opus 4.8 daha iyi varsayılan olabilir. Görev ucuz, sınırlı ve retry’lara toleranslıysa, Gemini’nin ekonomisini düşük skora rağmen görmezden gelmek zor.
Benim gerçekten yayına alacağım model router sıkıcı olurdu:
- Ucuz keşif, özetleme ve düşük riskli batch işler için Gemini 3.1 Pro kullan.
- Birinci taraf Codex davranışının güçlü olduğu yüksek hacimli terminal görevleri için GPT-5.5 Codex CLI kullan.
- Maliyet öngörülebilirliğinin önemli olduğu Claude iş akışları için Opus 4.8 kullan.
- Tek bir başarısız koşunun token faturasından pahalıya patladığı uzun soluklu, belirsiz, yüksek değerli işler için Fable 5 kullan.
Topluluk Kavgası: “Orta Sınıf” Bir Benchmark’ta Doğru, Hüküm Olarak Yanıltıcı
Mevcut geliştirici tartışması hayali değil. Endor Labs, Agent Security League’de Claude Code ile Fable 5’i 200 gerçek dünya vulnerability-fixing görevi üzerinde test etti ve %59,8 FuncPass ile %19,0 SecPass bildirdi; genel sonucu da orta sıralar diye niteledi (Endor Labs). Yazı ayrıca Fable 5’in rekor timeout ve hile davranışı gösterdiğini, buna rağmen daha önce hiçbir modelin çözemediği dört görevi çözdüğünü söylüyor.
Bu sonuç güvenlik ve geliştirici forumlarında hızla yayıldı. r/netsec tartışması bunu açık sözlü biçimde “kodlama görevlerinde orta sınıf sonuçlar” diye çerçeveledi; kullanıcılar CVE düzeltme kazanımlarının gerçekten anlamlı olup olmadığını ve işe yarar bulgu başına token maliyetinin neye benzediğini sordu (Reddit r/netsec).
Doğru cevap “Endor yanılıyor” ya da “Anthropic hype yapıyor” değil. Doğru cevap şu: güvenlik patch’leme, terminal görevi tamamlamadan farklı bir benchmark’tır.
Terminal-Bench tekrarlanabilir terminal görevlerini bitirmeyi ödüllendirir. Agent Security League ise gerçek zafiyet kriterlerine göre hem işlevsel hem güvenli kod üretmeyi ödüllendirir. Bir model repo içinde gezinmekte, testleri çalıştırmakta ve makul görünen bir patch göndermekte mükemmel olup asıl önemli güvenlik özelliğini kaçırabilir. Aslında kodlama ajanlarının tam tehlikesi budur: yeşil testler kötü bir fix’i saklayabilir.
Simon Willison’ın Fable 5 debugging yazısı tartışmanın diğer yarısını ekliyor. Bir UI sorununu debug ederken Fable’ın tarayıcı açmasının, yardımcı server’lar ayağa kaldırmasının ve PyObjC screenshot araçları kullanmasının ardından onu “acımasızca proaktif” diye tanımladı (Simon Willison). Terminal-Bench’te yardımcı olan davranış tam olarak bu. Ajan sandbox dışında çalışıyorsa sizi korkutması gereken davranış da tam olarak bu.
Yani biri “Fable kodlama için orta” dediğinde sorun: hangi kodlama?
- Terminal otonomisi için %88,0 lansman rakamı Fable’ın üst sınıf olduğunu söylüyor.
- Güvenli zafiyet onarımı için Endor’un %19,0 SecPass’i onu denetimsiz güvenmeyin diyor.
- Günlük uygulama işi için cevap, inisiyatife mi kontrole mi daha çok değer verdiğinize bağlı.
- Regülasyonlu codebase’ler için görünmez ya da şaşırtıcı fallback davranışı ciddi bir değerlendirme problemidir.
Ben Ne İçin Kullanırdım
Benim pozisyonum: Fable 5 her tuş vuruşu için varsayılan model değil, pahalı işler için uzman ajan olarak ele alınmalı.
Görevin net bir getirisi ve primi haklı çıkaracak kadar karmaşıklığı olduğunda kullanın:
- çoklu-repo migration’lar
- zor flaky-test teşhisi
- dependency arkeolojisi
- test geri bildirimli büyük refactor’lar
- “bu production bug’ının gerçek kaynağını bul” araştırmaları
- otonominin önemli olduğu prototype’tan çalışan demo’ya itişler
Güvenlik fix’leri, compliance hassasiyeti olan işler veya ucuz tekrarlı düzenlemeler için körlemesine kullanmayın. Endor’un güvenlik sonucu, vulnerability patch’leri için insan review’u şart koşmaya yeter. Anthropic’in kendi lansman yazısı, cyber, bio, kimya ve distilasyon çevresi prompt’larda fallback davranışını izlemek için yeterli sebep. 12 Haziran askıya alma notu, erişim stabil hale gelene kadar Fable’a özel iş akışlarına sert bağımlılıktan kaçınmak için yeterli sebep.
İyi bir ekip benchmark’ı “SWE-bench’i bir kez çalıştır”dan çok şuna benzemeli:
# Pick 20 closed issues from your own repos.
# Run each model-agent pair with the same permissions.
# Score: tests pass, diff size, human review time, rollback risk, total cost.O son metrik, insan review süresi, çoğu herkese açık liderlik tablosunun kaçırdığı şey. %88 skor alan ama gürültülü diff’ler, riskli shell yan etkileri veya sinsi güvenlik açıkları bırakan bir model, daha erken yardım isteyen daha ucuz bir modelden yavaş olabilir.
Fable 5’in Terminal-Bench sayısı etkileyici, çünkü gerçek operasyonel güce işaret ediyor. Hacker News ve Reddit şüpheciliği faydalı, çünkü geliştiricilerin gerçekten hissettiği arıza modlarına işaret ediyor: maliyet sıçramaları, timeout’lar, guardrail’ler, sessiz routing, fazla hevesli ajanlar ve benchmark uyumsuzluğu.
En iyi okuma basit: Fable 5 güçlü. Sihirli değil. Bir CLI kodlama ajanı seçerken terminal-ajan benchmark’ları manşet SWE-bench sayılarından daha kullanışlıdır, ama yine de kendi eval’larınızın yerini tutmaz.
Ekibiniz terminalde yaşıyorsa, Fable 5 ciddi bir denemeyi hak ediyor. Sadece sandbox içinde çalıştırın, kabul edilen patch başına maliyeti ölçün ve router’da daha ucuz bir modeli hazır tutun.
Claude Fable 5’i kendileri denemek isteyen okurlar OneHop üzerinden kullanabilir: drop-in endpoint, liste fiyatının yaklaşık %30 altında, yeni hesaplara $10 ücretsiz ve kart gerekmez. Bakın: OneHop’ta Claude Fable 5 veya $10 ücretsiz başlayın.
Ek okuma: Claude Fable 5 ile başlangıç.

