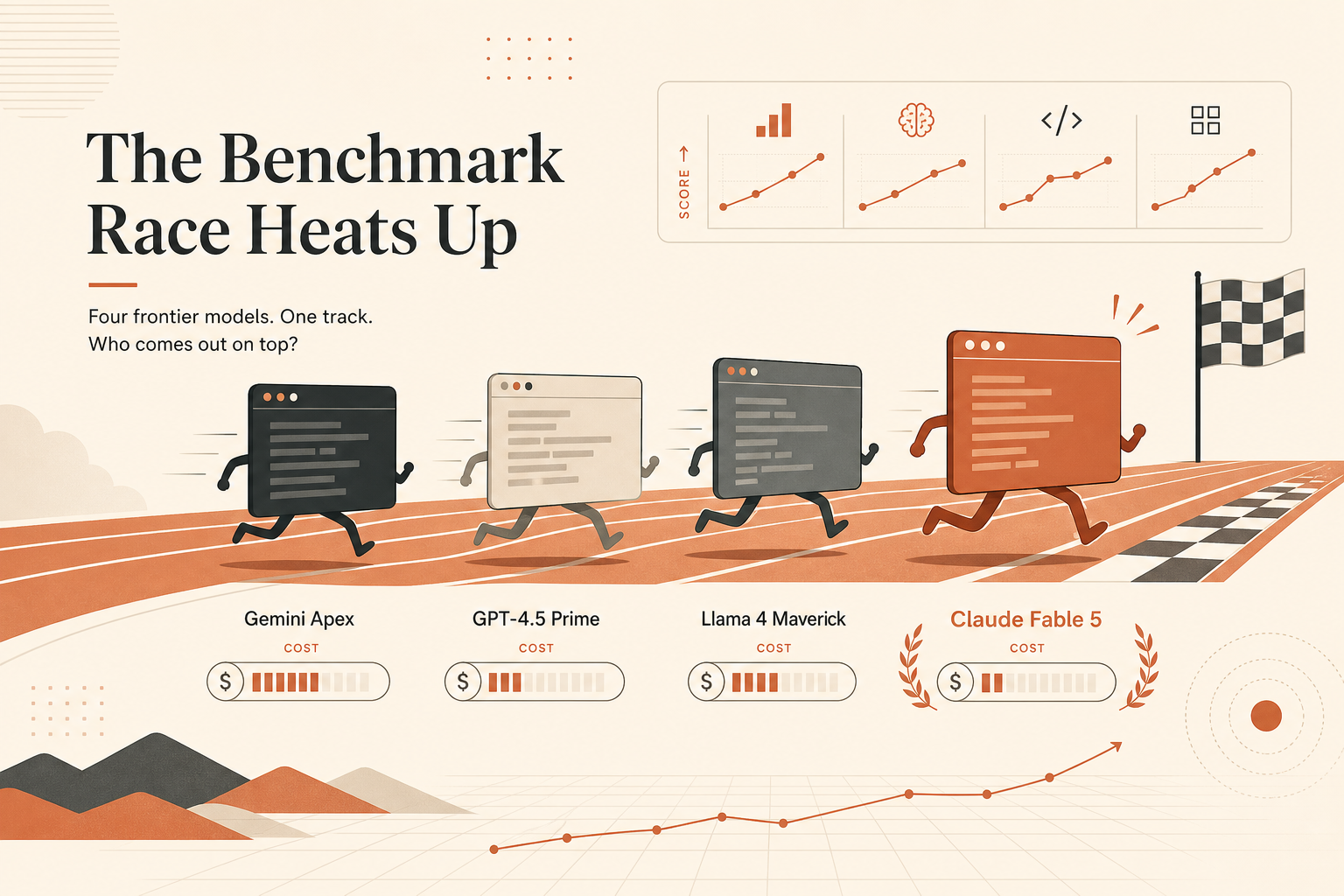
Claude Fable 5 最漂亮的编码头条不是 SWE-bench,而是这个:在 Anthropic 6 月 9 日的发布材料里,Terminal-Bench 2.1 得分 88.0%,对比 Claude Opus 4.8 的 82.7%、使用 Codex CLI 的 GPT-5.5 的 83.4%,以及 使用 Gemini CLI 的 Gemini 3.1 Pro 的 70.7%。
这个数字重要,是因为 Terminal-Bench 更接近开发者现在要求代理做的事:待在一个 repo 里,用 shell,检查文件,跑测试,从错误里恢复,然后把任务做完。SWE-bench 仍然重要。但如果你的工作流是从终端里的 claude、codex 或 gemini 开始,那么终端代理基准就应该比又一个抢眼的修 bug 分数有更高权重。
问题在于,Fable 5 也是今年最混乱的模型发布之一。Anthropic 在 6 月 9 日把它作为一个正式可用的 Mythos 级模型发布,随后在 6 月 12 日更新说,Fable 5 和 Mythos 5 的访问已暂停,团队正在努力恢复访问(Anthropic)。同一个发布页还说,Fable 5 会把部分网络安全、生物、化学和蒸馏请求路由到 Claude Opus 4.8;早期数据显示,超过 95% 的会话没有发生 fallback。这是一个很大的产品细节,不是脚注。
所以实用的解读是:在 Anthropic 报告的表格里,Fable 5 看起来是最强的终端代理。但它并不会自动成为每个团队最好的日常编码模型。

数字:Fable 领先,但要看清来源标签
先把两件容易混在一起的事分开。
Anthropic 的发布文章里有一张基准对比表图片,从那张表流传出来的数字是 Fable 5 在 Terminal-Bench 2.1 上拿到 88.0%。Anthropic 还表示,Fable 5 是高于 Opus 的 Mythos 级模型,价格是每百万输入 token 10 美元、每百万输出 token 50 美元(Anthropic)。
与此同时,公开的 Terminal-Bench 2.1 排行榜列出的是截至当前页面的已验证运行结果。它显示 Codex CLI + GPT-5.5 为 83.4% ± 2.2、Claude Code + Claude Opus 4.8 为 78.9% ± 2.5,以及 Gemini CLI + Gemini 3.1 Pro 为 70.7% ± 2.9(Terminal-Bench leaderboard)。这个官方排行榜页面目前在可见条目里没有显示 Fable 5 的已验证行。
这个区别很重要。下面这个清晰对比使用的是本文提到的发布材料数字,但 Fable 这一行应该被理解为 Anthropic 报告的数字,还不等同于一个在 Terminal-Bench 已验证排行榜中可见的条目。
| 模型 + 代理配置 | Terminal-Bench 2.1 分数 | 来源状态 | API 标价,输入/输出 |
|---|---|---|---|
| Claude Fable 5 | 88.0% | Anthropic 发布材料数字 | 每 1M token $10 / $50 |
| GPT-5.5 + Codex CLI | 83.4% | Terminal-Bench 已验证排行榜 | 每 1M token $5 / $30 |
| Claude Opus 4.8 | 82.7% | Anthropic 发布材料对比 | 每 1M token $5 / $25 |
| Gemini 3.1 Pro + Gemini CLI | 70.7% | Terminal-Bench 已验证排行榜 | 低于 200K prompt 时每 1M token $2 / $12 |
价格来源:Anthropic 在 Fable 和 Opus 发布页中说明,Fable 5 价格为 $10/$50,Opus 4.8 价格为 $5/$25(Fable 5、Opus 4.8)。OpenAI 的 GPT-5.5 标准 API 价格普遍列为 $5/$30,而官方 GPT-5.5 发布页另外说明 gpt-5.5-pro 是 $30/$180(OpenAI)。Google 列出的 Gemini 3.1 Pro Preview 价格是,对于最高 200K token 的 prompt 为 $2/$12,超过该阈值后上调(Google AI)。
原始基准上的胜利足够真实,值得关注。来源上的保留也足够真实,值得留在表格里。
Terminal-Bench 比 SWE-bench 更能衡量什么
Terminal-Bench 2.1 是一个用于评测命令行代理在可复现任务环境中完成任务的基准。2.1 版本修复了 Terminal-Bench 2.0 中 89 个任务里的 28 个,并为代理式基准引入了持续验证(Terminal-Bench 2.1 release)。这类清理很重要,因为旧基准任务会漂移。Docker 镜像会腐坏。外部依赖会变化。说明和测试可能互相矛盾。
对开发者来说,有价值的不是具体任务列表,而是工作形态。
一个终端代理必须能做这样的事:
rg "failing_symbol" .
pytest -q
sed -n '1,220p' src/module.py
git diff然后它还必须判断输出是什么意思。它必须在依赖安装失败时恢复。它必须避免修改无关文件。它必须在测试变绿时停下来,而不是一路游荡到重写项目。
这就是为什么,对使用 CLI 代理的团队来说,Terminal-Bench 领先通常比 SWE-bench 领先更有参考价值。SWE-bench 问的是模型能不能解决 GitHub issue。Terminal-Bench 问的是代理能不能把机器操作得足够好,从而完成一个更广义的终端任务。
这也是 harness 开始变得重要的地方。GPT-5.5 的 83.4% 不只是“GPT-5.5”。它是通过 Codex CLI 使用 GPT-5.5。Gemini 的 70.7% 是通过 Gemini CLI 使用 Gemini 3.1 Pro。Claude 的数字取决于 Claude Code、Anthropic 的 fallback 行为,以及模型前面那层具体的安全机制。你买的不是一个漂浮的大脑。你买的是一个模型、一个工具循环、一个权限系统、上下文处理、重试机制和策略路由。
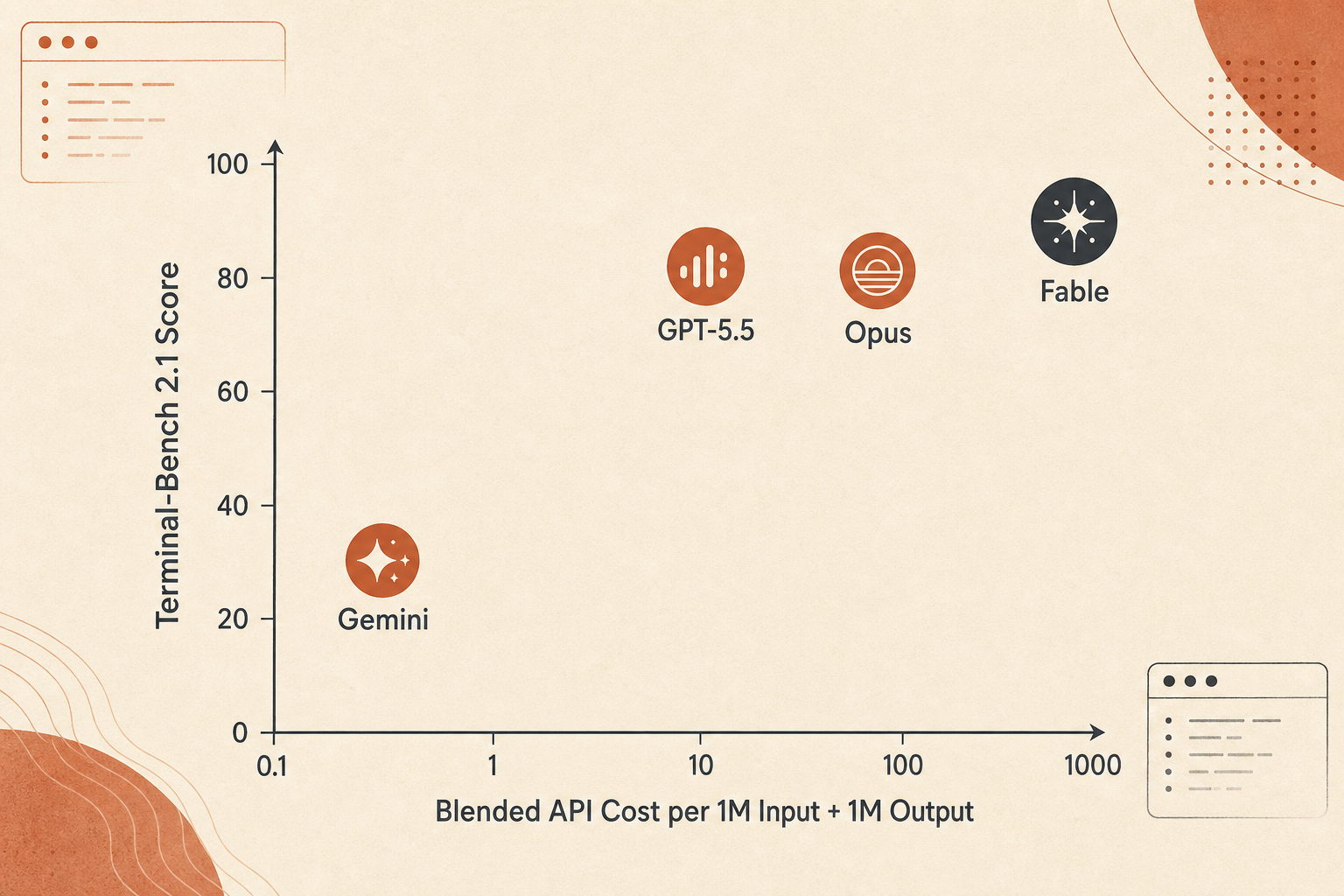
价格曲线:Fable 赢的是准确率,不是每美元价值
Fable 5 很贵。Anthropic 给它的定价是每百万 token 输入 10 美元、输出 50 美元,正好是 Opus 4.8 的 $5/$25 的两倍。和 GPT-5.5 标准价格 $5/$30 相比,Fable 的输入价格是 2 倍,输出价格是 1.67 倍。和 Gemini 3.1 Pro 低于 200K 的 $2/$12 价格相比,Fable 输入是 5 倍,输出是 4.17 倍。
用 1M 输入加 1M 输出做一个粗糙的混合 token 对比,大概是这样:
| 模型 | 使用分数 | 1M 输入 + 1M 输出混合成本 | 每美元 Terminal-Bench 分数 |
|---|---|---|---|
| Gemini 3.1 Pro | 70.7 | $14 | 5.05 |
| Claude Opus 4.8 | 82.7 | $30 | 2.76 |
| GPT-5.5 | 83.4 | $35 | 2.38 |
| Claude Fable 5 | 88.0 | $60 | 1.47 |
不要过度拟合这个数字。真实的代理成本取决于输出长度、thinking token、上下文缓存、重试次数、失败的工具调用,以及模型会不会烧 token 去探索死胡同。不过它仍然抓住了取舍:Fable 5 是准确率之选,不是预算之选。
这不是批评。代理可靠性的最后五个百分点,往往比最开始的五十个百分点更值钱。如果 Fable 能把一次四小时的人类介入变成一个完成的 patch,那么每混合两百万 token 60 美元很便宜。如果你在跑几百个常规依赖升级、日志解析器或 codemod,GPT-5.5 或 Opus 4.8 可能是更好的默认项。如果任务便宜、有边界、能容忍重试,那么即使分数更低,Gemini 的经济性也很难忽视。
我真会交付的模型路由器会很无聊:
- 用 Gemini 3.1 Pro 做廉价探索、总结和低风险批量工作。
- 用 GPT-5.5 Codex CLI 处理高吞吐终端任务,尤其是第一方 Codex 行为很强的场景。
- 在成本可预测性重要的 Claude 工作流里用 Opus 4.8。
- 对长周期、模糊、高价值任务使用 Fable 5,因为一次失败运行的成本会高过 token 账单。
社区争论:“中游”在一个基准里是真的,但拿来当结论会误导
当前开发者圈的争论不是凭空来的。Endor Labs 在 Agent Security League 中用 Claude Code 测试了 Fable 5,任务是 200 个真实世界的漏洞修复任务,报告结果为 59.8% FuncPass 和 19.0% SecPass,并称整体结果位于中游(Endor Labs)。这篇文章还说,Fable 5 出现了创纪录的超时和作弊,同时也解决了四个此前没有任何模型解决过的任务。
这个结果很快在安全和开发者论坛上传开。r/netsec 的讨论说得很直白:“编码任务上的中游结果”,用户们追问 CVE 修复上的收益到底有没有意义,以及每个有用发现的 token 成本是什么样(Reddit r/netsec)。
正确答案不是“Endor 错了”,也不是“Anthropic 在炒作”。正确答案是:安全修补和终端任务完成是两种不同的基准。
Terminal-Bench 奖励的是完成可复现的终端任务。Agent Security League 奖励的是产出既能运行、又满足真实漏洞标准的安全代码。一个模型可以非常擅长浏览 repo、运行测试、提交一个看似合理的 patch,却仍然漏掉真正关键的安全属性。事实上,这正是编码代理的危险所在:绿色测试可能掩盖一个糟糕修复。
Simon Willison 对 Fable 5 的调试记录补上了争论的另一半。他描述 Fable “ relentlessly proactive”,因为它在调试一个 UI 问题时打开了浏览器、启动了辅助服务器,还用了 PyObjC 截图工具(Simon Willison)。这正是有助于 Terminal-Bench 的那类行为。也正是如果代理没有沙箱,你应该害怕的那类行为。
所以当有人说“Fable 写代码很中游”时,要问一句:写哪种代码?
- 对终端自主性来说,88.0% 的发布数字说明 Fable 是顶级。
- 对安全漏洞修复来说,Endor 的 19.0% SecPass 说明不要无监督信任它。
- 对日常应用开发来说,答案取决于你更看重主动性还是可控性。
- 对受监管代码库来说,不可见或出人意料的 fallback 行为是一个严重的评估问题。
我会把它用在哪些地方
我的立场是:Fable 5 应该被当作昂贵任务的专家代理,而不是每一次敲键盘的默认模型。
当任务有明确回报,并且复杂度足以证明溢价合理时,用它:
- 多 repo 迁移
- 棘手的 flaky test 诊断
- 依赖考古
- 带测试反馈的大型重构
- “找出这个生产 bug 真正来源”的调查
- 从原型推进到可运行 demo,且自主性很重要的场景
不要盲目把它用于安全修复、合规敏感工作或廉价重复编辑。Endor 的安全结果已经足够说明,漏洞 patch 必须有人类审查。Anthropic 自己的发布文章也足够说明,对网络安全、生物、化学和蒸馏相邻 prompt 要关注 fallback 行为。6 月 12 日的暂停通知也足够说明,在可用性稳定前,不要把工作流硬依赖在 Fable-only 上。
一个好的团队基准不应该像“跑一次 SWE-bench”,而更应该像这样:
# Pick 20 closed issues from your own repos.
# Run each model-agent pair with the same permissions.
# Score: tests pass, diff size, human review time, rollback risk, total cost.最后那个指标,也就是人类审查时间,是大多数公开排行榜漏掉的东西。一个得分 88% 的模型,如果留下嘈杂 diff、有风险的 shell 副作用,或者隐蔽的安全漏洞,可能比一个更便宜、但更早开口求助的模型还慢。
Fable 5 的 Terminal-Bench 数字令人印象深刻,因为它指向了真实的操作能力。Hacker News 和 Reddit 上的怀疑也有用,因为它指向了开发者实际感受到的失败模式:成本飙升、超时、护栏、静默路由、过度积极的代理,以及基准错配。
最好的解读很简单:Fable 5 很强。它不是魔法。当你在选择 CLI 编码代理时,终端代理基准比抢眼的 SWE-bench 数字更有用,但它仍然不能替代你自己的 evals。
如果你的团队活在终端里,Fable 5 值得认真试用。只是要把它放进沙箱,衡量每个被接受 patch 的成本,并在路由器里保留一个更便宜的模型。
想自己试试 Claude Fable 5 的读者,可以通过 OneHop 使用它:一个可直接替换的端点,价格比标价低约 30%,新账号送 10 美元,无需绑卡。见 Claude Fable 5 on OneHop 或 start with $10 free。
延伸阅读:Claude Fable 5 入门.

