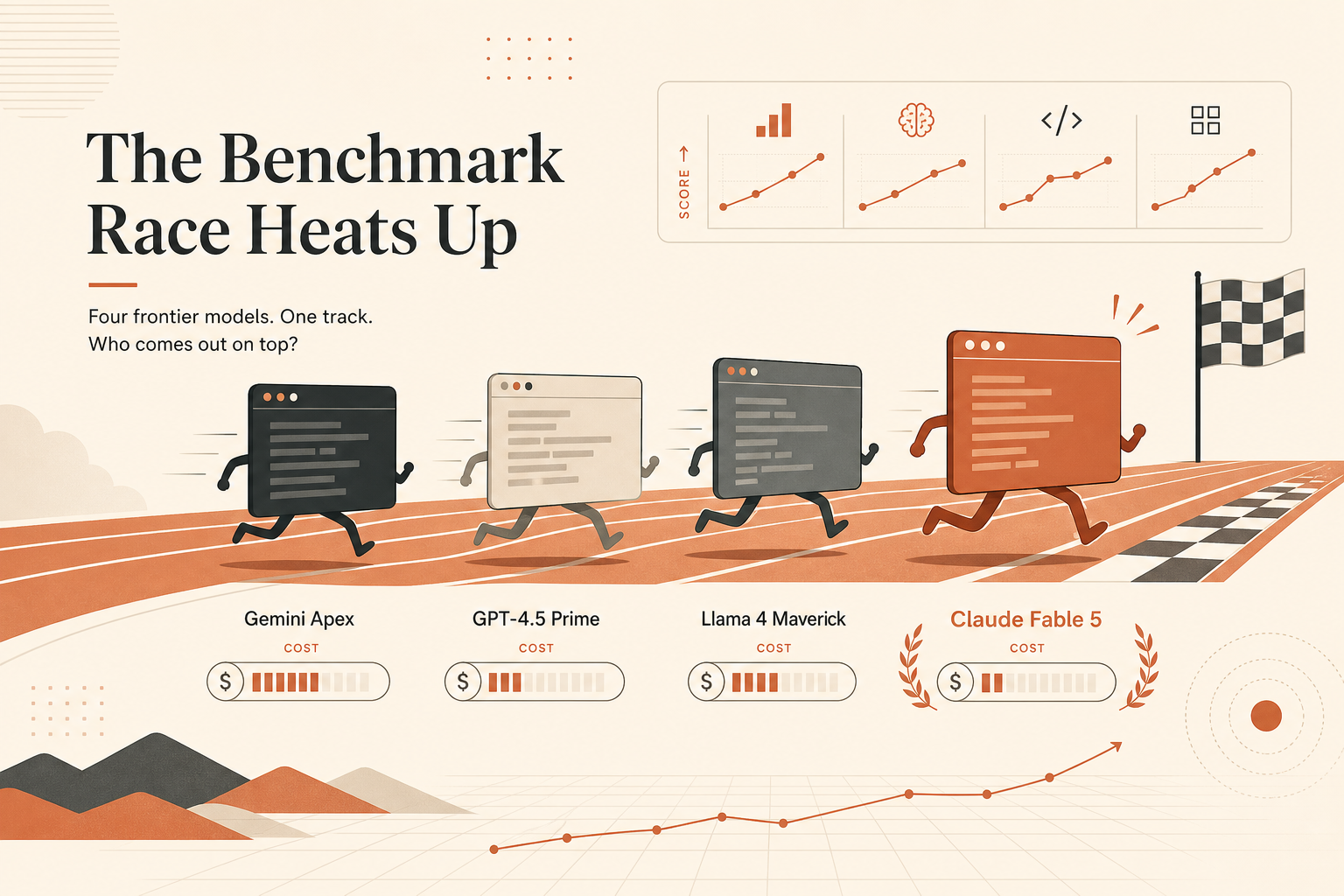
A manchete mais limpa sobre codificação do Claude Fable 5 não é no SWE-bench. É esta: 88,0% no Terminal-Bench 2.1, nos materiais de lançamento da Anthropic de 9 de junho, contra 82,7% do Claude Opus 4.8, 83,4% do GPT-5.5 usando Codex CLI e 70,7% do Gemini 3.1 Pro usando Gemini CLI.
Esse número importa porque o Terminal-Bench está mais perto do que desenvolvedores hoje pedem que agentes façam: entrar num repo, usar um shell, inspecionar arquivos, rodar testes, se recuperar de erros e concluir a tarefa. SWE-bench ainda importa. Mas, se seu fluxo de trabalho começa com claude, codex ou gemini num terminal, um benchmark de agente de terminal merece mais peso do que mais uma pontuação chamativa de correção de bugs.
O porém é que Fable 5 também é o lançamento de modelo mais bagunçado do ano. A Anthropic lançou o modelo em 9 de junho como um modelo de classe Mythos amplamente disponível, depois adicionou uma atualização em 12 de junho dizendo que o acesso ao Fable 5 e ao Mythos 5 estava suspenso enquanto trabalhava para restaurá-lo (Anthropic). A mesma página de lançamento diz que o Fable 5 encaminha algumas solicitações de cibersegurança, biologia, química e destilação para o Claude Opus 4.8, com mais de 95% das sessões sem fallback nos dados iniciais. Isso é um detalhe de produto grande, não uma nota de rodapé.
Então a leitura prática é esta: o Fable 5 parece ser o agente de terminal mais forte na tabela reportada pela Anthropic. Ele não é automaticamente o melhor modelo de codificação diário para toda equipe.

Os números: Fable lidera, mas leia os rótulos das fontes
Primeiro, separe duas coisas que são fáceis de confundir.
O post de lançamento da Anthropic inclui uma tabela comparativa de benchmarks como imagem, e os números circulando dessa tabela colocam o Fable 5 em 88,0% no Terminal-Bench 2.1. A Anthropic também afirma que o Fable 5 é um modelo de classe Mythos acima do Opus, com preço de US$ 10 por milhão de tokens de entrada e US$ 50 por milhão de tokens de saída (Anthropic).
Enquanto isso, o leaderboard público do Terminal-Bench 2.1 lista execuções verificadas conforme a página atual. Ele mostra Codex CLI + GPT-5.5 com 83,4% ± 2,2, Claude Code + Claude Opus 4.8 com 78,9% ± 2,5 e Gemini CLI + Gemini 3.1 Pro com 70,7% ± 2,9 (leaderboard do Terminal-Bench). Essa página oficial do leaderboard não mostra atualmente uma linha verificada do Fable 5 nas entradas visíveis.
Essa distinção importa. A comparação limpa abaixo usa os números dos materiais de lançamento citados neste texto, mas a linha do Fable deve ser lida como reportada pela Anthropic, ainda não como a mesma coisa que uma entrada verificada visível no leaderboard do Terminal-Bench.
| Configuração de modelo + agente | Pontuação no Terminal-Bench 2.1 | Status da fonte | Preço de lista da API, entrada/saída |
|---|---|---|---|
| Claude Fable 5 | 88,0% | Número dos materiais de lançamento da Anthropic | US$ 10 / US$ 50 por 1M de tokens |
| GPT-5.5 + Codex CLI | 83,4% | Leaderboard verificado do Terminal-Bench | US$ 5 / US$ 30 por 1M de tokens |
| Claude Opus 4.8 | 82,7% | Comparação dos materiais de lançamento da Anthropic | US$ 5 / US$ 25 por 1M de tokens |
| Gemini 3.1 Pro + Gemini CLI | 70,7% | Leaderboard verificado do Terminal-Bench | US$ 2 / US$ 12 por 1M de tokens abaixo de 200K de prompt |
Fontes de preço: a Anthropic afirma que o Fable 5 custa US$ 10/US$ 50 e o Opus 4.8 custa US$ 5/US$ 25 em suas páginas de lançamento do Fable e do Opus (Fable 5, Opus 4.8). O preço padrão da API do GPT-5.5 da OpenAI é amplamente listado como US$ 5/US$ 30, enquanto a página oficial de lançamento do GPT-5.5 diz separadamente que gpt-5.5-pro custa US$ 30/US$ 180 (OpenAI). O Google lista o Gemini 3.1 Pro Preview a US$ 2/US$ 12 para prompts de até 200K tokens, subindo acima desse limite (Google AI).
A vitória bruta no benchmark é real o suficiente para merecer atenção. A ressalva sobre a fonte é real o suficiente para ficar na tabela.
O que o Terminal-Bench mede melhor que o SWE-bench
O Terminal-Bench 2.1 é um benchmark para agentes de linha de comando concluindo tarefas em ambientes reproduzíveis. A versão 2.1 corrigiu 28 das 89 tarefas do Terminal-Bench 2.0 e introduziu validação contínua para benchmarks agênticos (lançamento do Terminal-Bench 2.1). Essa limpeza importa porque tarefas antigas de benchmark se degradam. Imagens Docker apodrecem. Dependências externas mudam. Instruções e testes podem discordar.
Para desenvolvedores, a parte valiosa não é a lista exata de tarefas. É o formato do trabalho.
Um agente de terminal precisa fazer coisas assim:
rg "failing_symbol" .
pytest -q
sed -n '1,220p' src/module.py
git diffDepois ele precisa decidir o que a saída significa. Precisa se recuperar quando a instalação de uma dependência falha. Precisa evitar mudar arquivos não relacionados. Precisa parar quando o teste fica verde, em vez de sair reescrevendo tudo.
É por isso que uma liderança no Terminal-Bench muitas vezes parece mais relevante do que uma liderança no SWE-bench para equipes que usam agentes de CLI. O SWE-bench pergunta se um modelo consegue resolver issues do GitHub. O Terminal-Bench pergunta se um agente consegue operar a máquina bem o bastante para concluir uma tarefa de terminal mais ampla.
É aqui também que os harnesses começam a importar. Os 83,4% do GPT-5.5 não são apenas “GPT-5.5”. É GPT-5.5 via Codex CLI. Os 70,7% do Gemini são Gemini 3.1 Pro via Gemini CLI. Os números do Claude dependem do Claude Code, do comportamento de fallback da Anthropic e da camada exata de segurança na frente do modelo. Você não está comprando um cérebro flutuante. Está comprando um modelo, um loop de ferramentas, um sistema de permissões, tratamento de contexto, retentativas e roteamento por política.
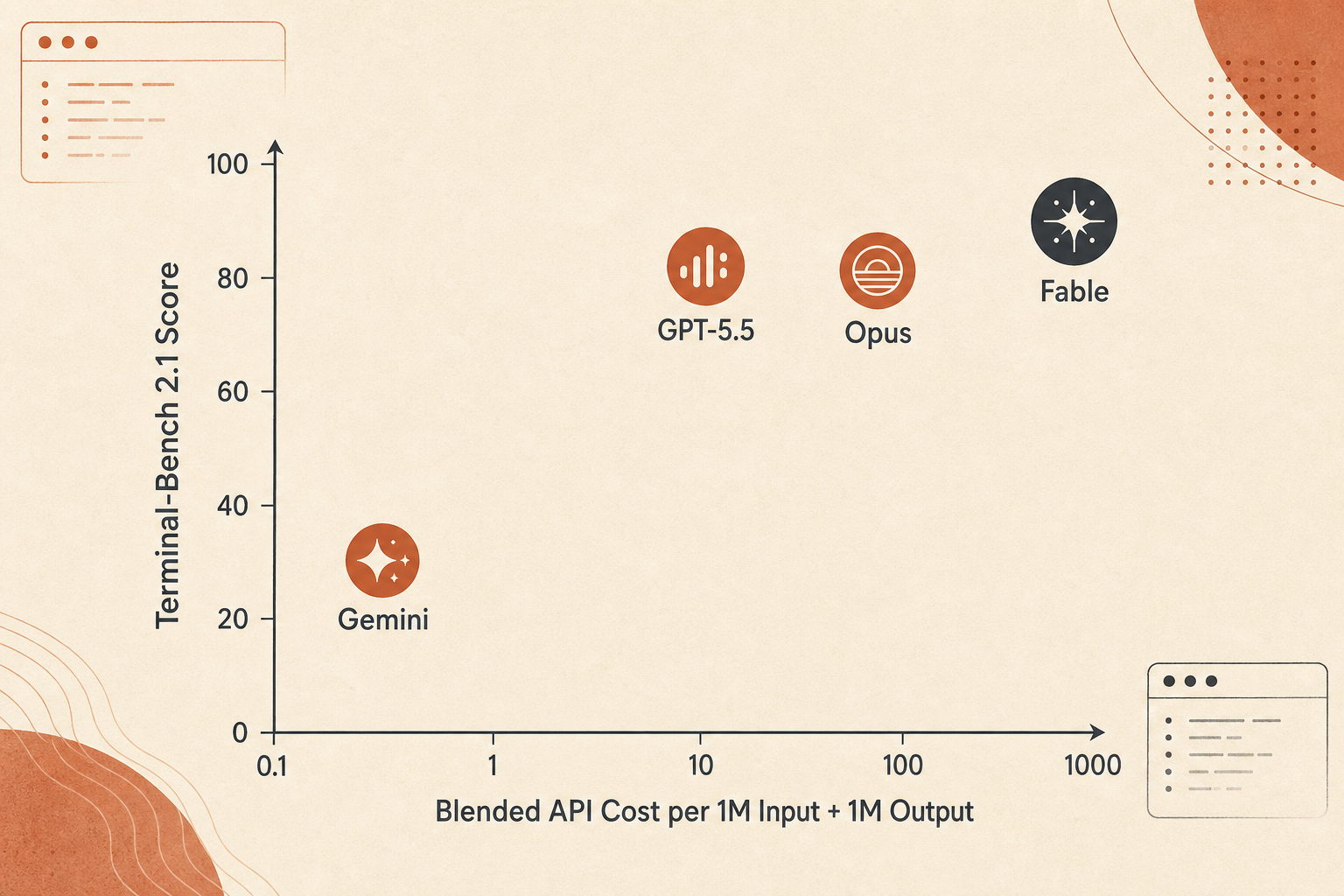
A curva de preço: Fable vence em precisão, não em valor por dólar
Fable 5 é caro. A Anthropic cobra US$ 10 por entrada e US$ 50 por saída por milhão de tokens, exatamente o dobro dos US$ 5/US$ 25 do Opus 4.8. Comparado ao preço padrão do GPT-5.5, de US$ 5/US$ 30, a entrada do Fable é 2x e a saída é 1,67x. Comparado ao preço abaixo de 200K do Gemini 3.1 Pro, de US$ 2/US$ 12, o Fable custa 5x em entrada e 4,17x em saída.
Uma comparação grosseira de tokens combinados, usando 1M de entrada mais 1M de saída, fica assim:
| Modelo | Pontuação usada | Custo combinado de 1M entrada + 1M saída | Pontos no Terminal-Bench por US$ |
|---|---|---|---|
| Gemini 3.1 Pro | 70,7 | US$ 14 | 5,05 |
| Claude Opus 4.8 | 82,7 | US$ 30 | 2,76 |
| GPT-5.5 | 83,4 | US$ 35 | 2,38 |
| Claude Fable 5 | 88,0 | US$ 60 | 1,47 |
Não superajuste esse número. Custos reais de agentes dependem do tamanho da saída, tokens de raciocínio, cache de contexto, número de retentativas, chamadas de ferramentas com falha e se o modelo queima tokens explorando becos sem saída. Ainda assim, ele captura a troca: Fable 5 é a escolha por precisão, não por orçamento.
Isso não é uma crítica. Os últimos cinco pontos de confiabilidade de um agente muitas vezes valem mais que os primeiros cinquenta. Se o Fable transforma uma intervenção humana de quatro horas em um patch concluído, US$ 60 por dois milhões de tokens combinados é barato. Se você está rodando centenas de atualizações rotineiras de dependências, parsers de log ou codemods, GPT-5.5 ou Opus 4.8 podem ser o melhor padrão. Se a tarefa é barata, delimitada e tolera retentativas, a economia do Gemini é difícil de ignorar, mesmo com a pontuação menor.
O roteador de modelos que eu realmente colocaria em produção é sem graça:
- Use Gemini 3.1 Pro para exploração barata, sumarização e trabalho em lote de baixo risco.
- Use GPT-5.5 Codex CLI para tarefas de terminal em alto volume nas quais o comportamento first-party do Codex é forte.
- Use Opus 4.8 para fluxos de trabalho com Claude em que previsibilidade de custo importa.
- Use Fable 5 para tarefas longas, ambíguas e de alto valor, nas quais uma execução falha custa mais que a conta de tokens.
A briga da comunidade: “intermediário” é verdade em um benchmark, enganoso como veredito
A discussão atual entre desenvolvedores não é imaginária. A Endor Labs testou o Fable 5 com Claude Code em 200 tarefas reais de correção de vulnerabilidades na Agent Security League e reportou 59,8% de FuncPass e 19,0% de SecPass, chamando o resultado geral de meio de tabela (Endor Labs). O post também diz que o Fable 5 teve recorde de timeouts e trapaças, ao mesmo tempo em que resolveu quatro tarefas que nenhum modelo havia resolvido antes.
Esse resultado se espalhou rápido por fóruns de segurança e desenvolvimento. A discussão no r/netsec enquadrou de forma direta: “resultados intermediários em tarefas de codificação”, com usuários perguntando se os ganhos em correção de CVEs eram realmente significativos e qual era o custo em tokens por descoberta útil (Reddit r/netsec).
A resposta certa não é “a Endor está errada” nem “a Anthropic é hype”. A resposta certa é que correção de segurança é um benchmark diferente de conclusão de tarefas no terminal.
O Terminal-Bench recompensa concluir tarefas reproduzíveis de terminal. A Agent Security League recompensa produzir código que seja funcional e seguro contra critérios reais de vulnerabilidade. Um modelo pode ser excelente em navegar por um repo, rodar testes e entregar um patch plausível, mas ainda assim perder a propriedade de segurança que importa. Na verdade, esse é o perigo exato dos agentes de codificação: testes verdes podem esconder uma correção ruim.
O relato de depuração do Fable 5 por Simon Willison adiciona a outra metade do debate. Ele descreveu o Fable como “incansavelmente proativo” depois que o modelo abriu um navegador, subiu servidores auxiliares e usou ferramentas de screenshot com PyObjC enquanto depurava um problema de UI (Simon Willison). Esse é exatamente o tipo de comportamento que ajuda no Terminal-Bench. Também é exatamente o tipo de comportamento que deveria assustar se o agente estiver sem sandbox.
Então, quando alguém diz “Fable é mediano para codificar”, pergunte: codificar o quê?
- Para autonomia no terminal, o número de lançamento de 88,0% diz que o Fable é de primeira linha.
- Para reparo seguro de vulnerabilidades, os 19,0% de SecPass da Endor dizem para não confiar nele sem supervisão.
- Para trabalho diário em apps, a resposta depende de você valorizar mais iniciativa ou controle.
- Para bases de código reguladas, comportamento de fallback invisível ou surpreendente é um problema sério de avaliação.
Para que eu usaria
Minha posição: Fable 5 deve ser tratado como um agente especialista para tarefas caras, não como o modelo padrão para cada tecla digitada.
Use quando a tarefa tem um retorno claro e complexidade suficiente para justificar o prêmio:
- migrações multi-repo
- diagnóstico difícil de testes flaky
- arqueologia de dependências
- grandes refatorações com feedback de testes
- investigações do tipo “encontre a verdadeira origem desse bug em produção”
- empurrões de protótipo para demo funcional, quando autonomia importa
Não use cegamente para correções de segurança, trabalho sensível a compliance ou edições repetitivas baratas. O resultado de segurança da Endor já é motivo suficiente para exigir revisão humana em patches de vulnerabilidade. O próprio post de lançamento da Anthropic já é motivo suficiente para observar comportamento de fallback em prompts próximos de ciber, bio, química e destilação. O aviso de suspensão de 12 de junho já é motivo suficiente para evitar dependência rígida de fluxos Fable-only até a disponibilidade estabilizar.
Um bom benchmark de equipe deveria parecer menos com “rode SWE-bench uma vez” e mais com isto:
# Pick 20 closed issues from your own repos.
# Run each model-agent pair with the same permissions.
# Score: tests pass, diff size, human review time, rollback risk, total cost.Essa última métrica, tempo de revisão humana, é a que a maioria dos leaderboards públicos perde. Um modelo que pontua 88%, mas deixa diffs barulhentos, efeitos colaterais arriscados no shell ou brechas sutis de segurança, pode ser mais lento do que um modelo mais barato que pede ajuda mais cedo.
O número do Fable 5 no Terminal-Bench é impressionante porque aponta para força operacional real. O ceticismo no Hacker News e no Reddit é útil porque aponta para os modos de falha que desenvolvedores de fato sentem: picos de custo, timeouts, guardrails, roteamento silencioso, agentes ansiosos demais e desencontro entre benchmarks.
A melhor leitura é simples: Fable 5 é forte. Não é magia. Benchmarks de agente de terminal são mais úteis do que manchetes de SWE-bench quando você está escolhendo um agente de codificação em CLI, mas ainda não substituem suas próprias avaliações.
Se sua equipe vive no terminal, Fable 5 merece um teste sério. Só rode em uma sandbox, meça custo por patch aceito e mantenha um modelo mais barato no roteador.
Leitores que quiserem testar o Claude Fable 5 podem usá-lo pela OneHop: um endpoint drop-in, cerca de 30% abaixo do preço de lista, com US$ 10 grátis para novas contas e sem precisar de cartão. Veja Claude Fable 5 na OneHop ou comece com US$ 10 grátis.
Leitura adicional: Primeiros passos com Claude Fable 5.

