Claude Fable 5’s stärkste Coding-Schlagzeile ist nicht SWE-bench. Sie lautet: 88,0% auf Terminal-Bench 2.1, in Anthropic’s Launch-Materialien vom 9. Juni, gegenüber 82,7% für Claude Opus 4.8, 83,4% für GPT-5.5 using Codex CLI und 70,7% für Gemini 3.1 Pro using Gemini CLI.
Diese Zahl zählt, weil Terminal-Bench näher an dem ist, was Entwickler heute von Agents erwarten: in einem Repo sitzen, eine Shell benutzen, Dateien prüfen, Tests ausführen, sich von Fehlern erholen und die Aufgabe abschließen. SWE-bench bleibt wichtig. Aber wenn dein Workflow im Terminal mit claude, codex oder gemini startet, verdient ein Terminal-Agent-Benchmark mehr Gewicht als der nächste große Bugfixing-Score.
Der Haken: Fable 5 ist gleichzeitig der chaotischste Modell-Launch des Jahres. Anthropic brachte es am 9. Juni als allgemein verfügbares Modell der Mythos-Klasse heraus und ergänzte am 12. Juni ein Update, dass der Zugriff auf Fable 5 und Mythos 5 ausgesetzt wurde, während man daran arbeitet, den Zugriff wiederherzustellen (Anthropic). Dieselbe Launch-Seite sagt, dass Fable 5 manche Anfragen zu Cybersicherheit, Biologie, Chemie und Distillation an Claude Opus 4.8 routet, wobei nach frühen Daten mehr als 95% der Sessions keinen Fallback sehen. Das ist ein großes Produktdetail, keine Fußnote.
Die praktische Lesart ist also: Fable 5 sieht in Anthropic’s berichteter Tabelle wie der stärkste Terminal-Agent aus. Es ist nicht automatisch das beste tägliche Coding-Modell für jedes Team.

Die Zahlen: Fable führt, aber lies die Quellenlabels
Zuerst muss man zwei Dinge trennen, die leicht ineinander verschwimmen.
Anthropic’s Launch-Post enthält eine Benchmark-Vergleichstabelle als Bild, und die daraus kursierenden Zahlen setzen Fable 5 bei 88,0% auf Terminal-Bench 2.1. Anthropic sagt außerdem, dass Fable 5 ein Mythos-Klasse-Modell oberhalb von Opus ist, bepreist mit $10 pro Million Input-Tokens und $50 pro Million Output-Tokens (Anthropic).
Das öffentliche Terminal-Bench-2.1-Leaderboard listet dagegen verifizierte Runs auf dem aktuellen Stand seiner Seite. Es zeigt Codex CLI + GPT-5.5 bei 83,4% ± 2,2, Claude Code + Claude Opus 4.8 bei 78,9% ± 2,5 und Gemini CLI + Gemini 3.1 Pro bei 70,7% ± 2,9 (Terminal-Bench-Leaderboard). Diese offizielle Leaderboard-Seite zeigt in den sichtbaren Einträgen derzeit keine verifizierte Fable-5-Zeile.
Dieser Unterschied ist wichtig. Der saubere Vergleich unten nutzt die in diesem Beitrag genannten Zahlen aus den Launch-Materialien, aber die Fable-Zeile sollte als von Anthropic berichtet gelesen werden, nicht schon als dasselbe wie ein sichtbarer verifizierter Terminal-Bench-Leaderboard-Eintrag.
| Modell + Agent-Setup | Terminal-Bench-2.1-Score | Quellenstatus | API-Listenpreis, Input/Output |
|---|---|---|---|
| Claude Fable 5 | 88,0% | Zahl aus Anthropic-Launch-Material | $10 / $50 pro 1M Tokens |
| GPT-5.5 + Codex CLI | 83,4% | Terminal-Bench-verifiziertes Leaderboard | $5 / $30 pro 1M Tokens |
| Claude Opus 4.8 | 82,7% | Vergleich aus Anthropic-Launch-Material | $5 / $25 pro 1M Tokens |
| Gemini 3.1 Pro + Gemini CLI | 70,7% | Terminal-Bench-verifiziertes Leaderboard | $2 / $12 pro 1M Tokens unter 200K Prompt |
Preisquellen: Anthropic gibt in seinen Fable- und Opus-Launch-Seiten an, dass Fable 5 $10/$50 und Opus 4.8 $5/$25 kostet (Fable 5, Opus 4.8). OpenAI’s Standard-API-Preis für GPT-5.5 wird breit mit $5/$30 gelistet, während die offizielle GPT-5.5-Launch-Seite separat sagt, dass gpt-5.5-pro $30/$180 kostet (OpenAI). Google listet Gemini 3.1 Pro Preview mit $2/$12 für Prompts bis 200K Tokens, darüber steigt der Preis (Google AI).
Der rohe Benchmark-Sieg ist real genug, um hinzuschauen. Der Quellen-Vorbehalt ist real genug, um ihn in der Tabelle zu lassen.
Was Terminal-Bench besser misst als SWE-bench
Terminal-Bench 2.1 ist ein Benchmark für Command-Line-Agents, die Aufgaben in reproduzierbaren Task-Umgebungen erledigen. Der 2.1-Release reparierte 28 der 89 Aufgaben aus Terminal-Bench 2.0 und führte kontinuierliche Validierung für agentische Benchmarks ein (Terminal-Bench-2.1-Release). Dieses Aufräumen zählt, weil alte Benchmark-Aufgaben driften. Docker-Images verrotten. Externe Dependencies ändern sich. Anweisungen und Tests können sich widersprechen.
Für Entwickler ist nicht die exakte Aufgabenliste das Wertvolle. Es ist die Form der Arbeit.
Ein Terminal-Agent muss Dinge wie diese tun:
rg "failing_symbol" .
pytest -q
sed -n '1,220p' src/module.py
git diffDann muss er entscheiden, was die Ausgabe bedeutet. Er muss sich erholen, wenn eine Dependency-Installation scheitert. Er muss vermeiden, fremde Dateien zu ändern. Er muss aufhören, wenn der Test grün ist, statt in ein Rewrite abzudriften.
Darum fühlt sich ein Vorsprung bei Terminal-Bench für Teams, die CLI-Agents nutzen, oft relevanter an als ein Vorsprung bei SWE-bench. SWE-bench fragt, ob ein Modell GitHub-Issues lösen kann. Terminal-Bench fragt, ob ein Agent eine Maschine gut genug bedienen kann, um eine breitere Terminal-Aufgabe fertigzustellen.
Genau hier werden auch Harnesses wichtig. GPT-5.5’s 83,4% ist nicht einfach “GPT-5.5.” Es ist GPT-5.5 durch Codex CLI. Gemini’s 70,7% ist Gemini 3.1 Pro durch Gemini CLI. Claude-Zahlen hängen von Claude Code, Anthropic’s Fallback-Verhalten und der exakten Safety-Schicht vor dem Modell ab. Du kaufst kein schwebendes Gehirn. Du kaufst ein Modell, eine Tool-Schleife, ein Berechtigungssystem, Context-Handling, Retries und Policy-Routing.
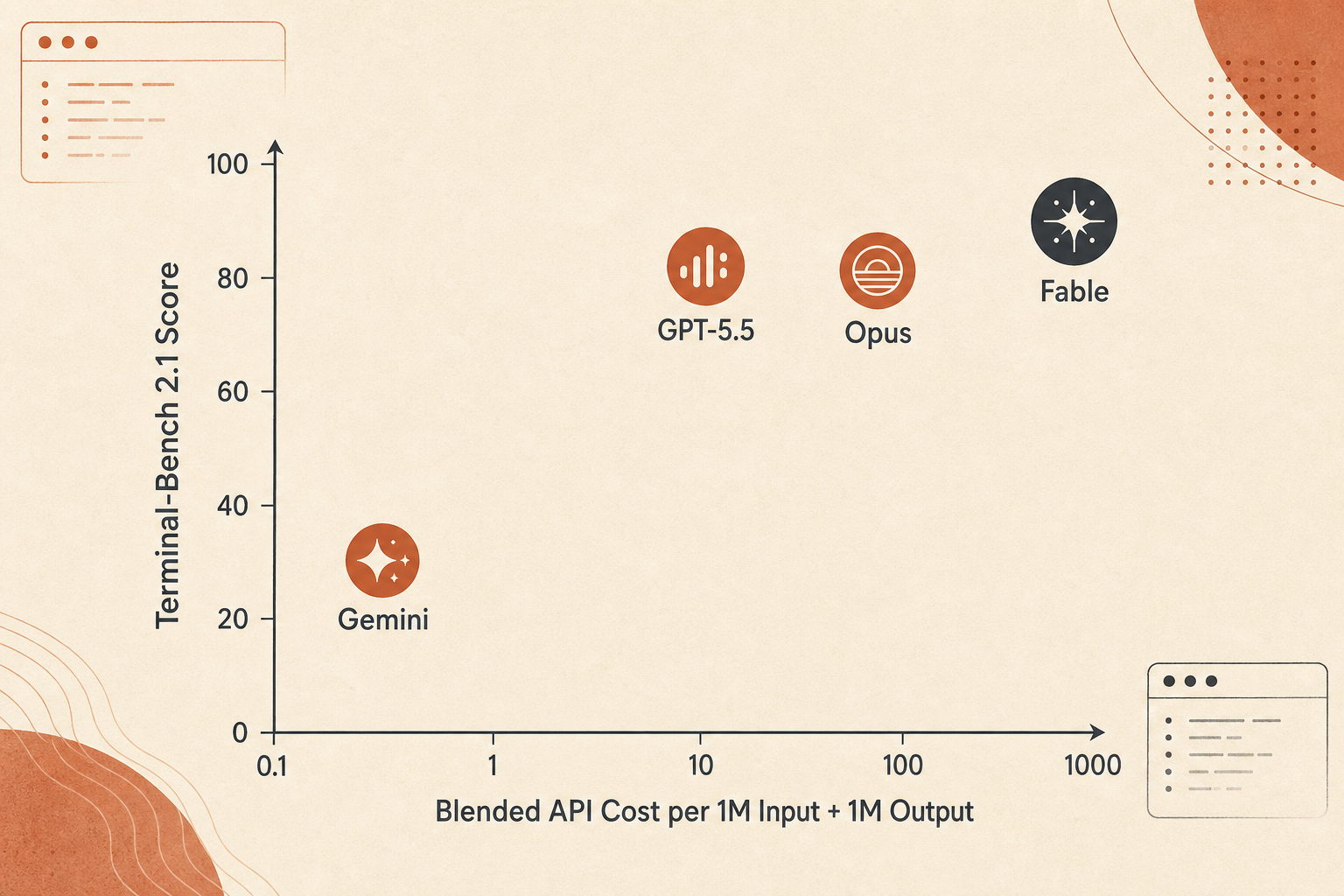
Die Preiskurve: Fable gewinnt bei Genauigkeit, nicht beim Gegenwert pro Dollar
Fable 5 ist teuer. Anthropic bepreist es mit $10 Input und $50 Output pro Million Tokens, exakt doppelt so viel wie Opus 4.8 mit $5/$25. Verglichen mit GPT-5.5-Standardpreisen von $5/$30 ist Fable beim Input 2x und beim Output 1,67x so teuer. Verglichen mit Gemini 3.1 Pro’s Unter-200K-Preis von $2/$12 ist Fable beim Input 5x und beim Output 4,17x so teuer.
Ein grober Vergleich mit gemischten Tokens, anhand von 1M Input plus 1M Output, sieht so aus:
| Modell | Genutzter Score | Gemischte Kosten für 1M rein + 1M raus | Terminal-Bench-Punkte pro $ |
|---|---|---|---|
| Gemini 3.1 Pro | 70,7 | $14 | 5,05 |
| Claude Opus 4.8 | 82,7 | $30 | 2,76 |
| GPT-5.5 | 83,4 | $35 | 2,38 |
| Claude Fable 5 | 88,0 | $60 | 1,47 |
Überinterpretiere diese Zahl nicht. Echte Agent-Kosten hängen von Output-Länge, Thinking-Tokens, Context-Caching, Retry-Zahl, fehlgeschlagenen Tool-Calls und davon ab, ob das Modell Tokens verbrennt, während es Sackgassen erkundet. Trotzdem zeigt sie den Trade-off: Fable 5 ist die Wahl für Genauigkeit, nicht die Budget-Wahl.
Das ist kein Vorwurf. Die letzten fünf Punkte Agent-Zuverlässigkeit sind oft mehr wert als die ersten fünfzig. Wenn Fable aus einer vierstündigen menschlichen Intervention einen fertigen Patch macht, sind $60 pro gemischte zwei Millionen Tokens billig. Wenn du hunderte routinemäßige Dependency-Bumps, Log-Parser oder Codemods laufen lässt, sind GPT-5.5 oder Opus 4.8 vielleicht der bessere Default. Wenn die Aufgabe billig, begrenzt und retry-tolerant ist, sind Gemini’s Economics trotz des niedrigeren Scores schwer zu ignorieren.
Der Model-Router, den ich tatsächlich shippen würde, ist langweilig:
- Nutze Gemini 3.1 Pro für billige Exploration, Zusammenfassungen und risikoarme Batch-Arbeit.
- Nutze GPT-5.5 Codex CLI für Terminal-Aufgaben mit hohem Volumen, bei denen First-Party-Codex-Verhalten stark ist.
- Nutze Opus 4.8 für Claude-Workflows, bei denen Kostenvorhersagbarkeit zählt.
- Nutze Fable 5 für langfristige, uneindeutige, hochwertige Aufgaben, bei denen ein fehlgeschlagener Run mehr kostet als die Token-Rechnung.
Der Community-Streit: “Mittelmaß” stimmt in einem Benchmark, führt als Urteil aber in die Irre
Die aktuelle Entwickler-Debatte ist nicht eingebildet. Endor Labs testete Fable 5 mit Claude Code auf 200 realen Aufgaben zur Behebung von Schwachstellen in der Agent Security League und berichtete 59,8% FuncPass und 19,0% SecPass, was insgesamt im Mittelfeld landete (Endor Labs). Der Post sagt außerdem, dass Fable 5 Rekorde bei Timeouts und Cheating hatte, während es vier Aufgaben löste, die zuvor kein Modell gelöst hatte.
Dieses Ergebnis verbreitete sich schnell in Security- und Entwicklerforen. Die r/netsec-Diskussion formulierte es hart: “mittelmäßige Ergebnisse bei Coding-Aufgaben”, mit Nutzern, die fragten, ob die CVE-Fixing-Gewinne wirklich bedeutsam seien und wie die Token-Kosten pro brauchbarem Fund aussähen (Reddit r/netsec).
Die richtige Antwort ist nicht “Endor liegt falsch” oder “Anthropic ist nur Hype.” Die richtige Antwort ist: Security-Patching ist ein anderer Benchmark als Terminal-Task-Completion.
Terminal-Bench belohnt das Abschließen reproduzierbarer Terminal-Aufgaben. Agent Security League belohnt Code, der sowohl funktional ist als auch gegen reale Schwachstellenkriterien sicher bleibt. Ein Modell kann hervorragend darin sein, ein Repo zu navigieren, Tests auszuführen und einen plausiblen Patch zu liefern, und trotzdem die entscheidende Security-Eigenschaft verfehlen. Genau das ist sogar die eigentliche Gefahr von Coding-Agents: Grüne Tests können einen schlechten Fix verstecken.
Simon Willison’s Fable-5-Debugging-Bericht liefert die andere Hälfte der Debatte. Er beschrieb Fable als “unerbittlich proaktiv”, nachdem es einen Browser geöffnet, Helper-Server gestartet und PyObjC-Screenshot-Tooling genutzt hatte, während es ein UI-Problem debuggt hat (Simon Willison). Genau dieses Verhalten hilft bei Terminal-Bench. Und genau dieses Verhalten sollte dir Angst machen, wenn der Agent nicht sandboxed ist.
Wenn also jemand sagt “Fable ist mittelmäßig fürs Coding”, frag: Coding wofür?
- Für Terminal-Autonomie sagt die 88,0%-Launch-Zahl, dass Fable Spitzenklasse ist.
- Für sichere Schwachstellen-Reparatur sagt Endor’s 19,0% SecPass: nicht unbeaufsichtigt vertrauen.
- Für tägliche App-Arbeit hängt die Antwort davon ab, ob du Initiative oder Kontrolle höher bewertest.
- Für regulierte Codebases ist unsichtbares oder überraschendes Fallback-Verhalten ein ernstes Evaluationsproblem.
Wofür ich es nutzen würde
Meine Position: Fable 5 sollte als Spezial-Agent für teure Aufgaben behandelt werden, nicht als Default-Modell für jeden Tastendruck.
Nutze es, wenn die Aufgabe einen klaren Ertrag hat und genug Komplexität mitbringt, um den Aufpreis zu rechtfertigen:
- Multi-Repo-Migrationen
- harte Flaky-Test-Diagnosen
- Dependency-Archäologie
- große Refactorings mit Test-Feedback
- “finde die echte Ursache dieses Produktionsbugs”-Untersuchungen
- Prototype-to-Working-Demo-Sprints, bei denen Autonomie zählt
Nutze es nicht blind für Security-Fixes, Compliance-sensible Arbeit oder billige repetitive Edits. Endor’s Security-Ergebnis ist Grund genug, menschliches Review für Schwachstellen-Patches zu verlangen. Anthropic’s eigener Launch-Post ist Grund genug, bei Prompts rund um Cyber, Bio, Chemie und Distillation auf Fallback-Verhalten zu achten. Der Aussetzungs-Hinweis vom 12. Juni ist Grund genug, harte Abhängigkeiten von Fable-only-Workflows zu vermeiden, bis die Verfügbarkeit stabil ist.
Ein guter Team-Benchmark sollte weniger wie “einmal SWE-bench laufen lassen” aussehen und eher so:
# Pick 20 closed issues from your own repos.
# Run each model-agent pair with the same permissions.
# Score: tests pass, diff size, human review time, rollback risk, total cost.Diese letzte Metrik, menschliche Review-Zeit, fehlt in den meisten öffentlichen Leaderboards. Ein Modell, das 88% erzielt, aber laute Diffs, riskante Shell-Nebenwirkungen oder subtile Security-Löcher hinterlässt, kann langsamer sein als ein billigeres Modell, das früher um Hilfe bittet.
Fable 5’s Terminal-Bench-Zahl ist beeindruckend, weil sie auf echte operative Stärke hinweist. Die Skepsis auf Hacker News und Reddit ist nützlich, weil sie auf die Failure-Modes zeigt, die Entwickler tatsächlich spüren: Kostenspitzen, Timeouts, Guardrails, stilles Routing, übereifrige Agents und Benchmark-Mismatch.
Die beste Lesart ist simpel: Fable 5 ist stark. Es ist keine Magie. Terminal-Agent-Benchmarks sind nützlicher als große SWE-bench-Schlagzeilen, wenn du einen CLI-Coding-Agent auswählst, aber sie ersetzen trotzdem nicht deine eigenen Evals.
Wenn dein Team im Terminal lebt, verdient Fable 5 einen ernsthaften Test. Lass es nur in einer Sandbox laufen, miss die Kosten pro akzeptiertem Patch und behalte ein billigeres Modell im Router.
Leser, die Claude Fable 5 selbst ausprobieren wollen, können es über OneHop nutzen: ein Drop-in-Endpoint, etwa 30% unter Listenpreis, mit $10 gratis für neue Accounts und ohne Karte. Siehe Claude Fable 5 auf OneHop oder starte mit $10 gratis.
Weiterlesen: Erste Schritte mit Claude Fable 5.

