Claude Fable 5 不是偷偷摸摸爬上排行榜的。它是直接空降榜首。
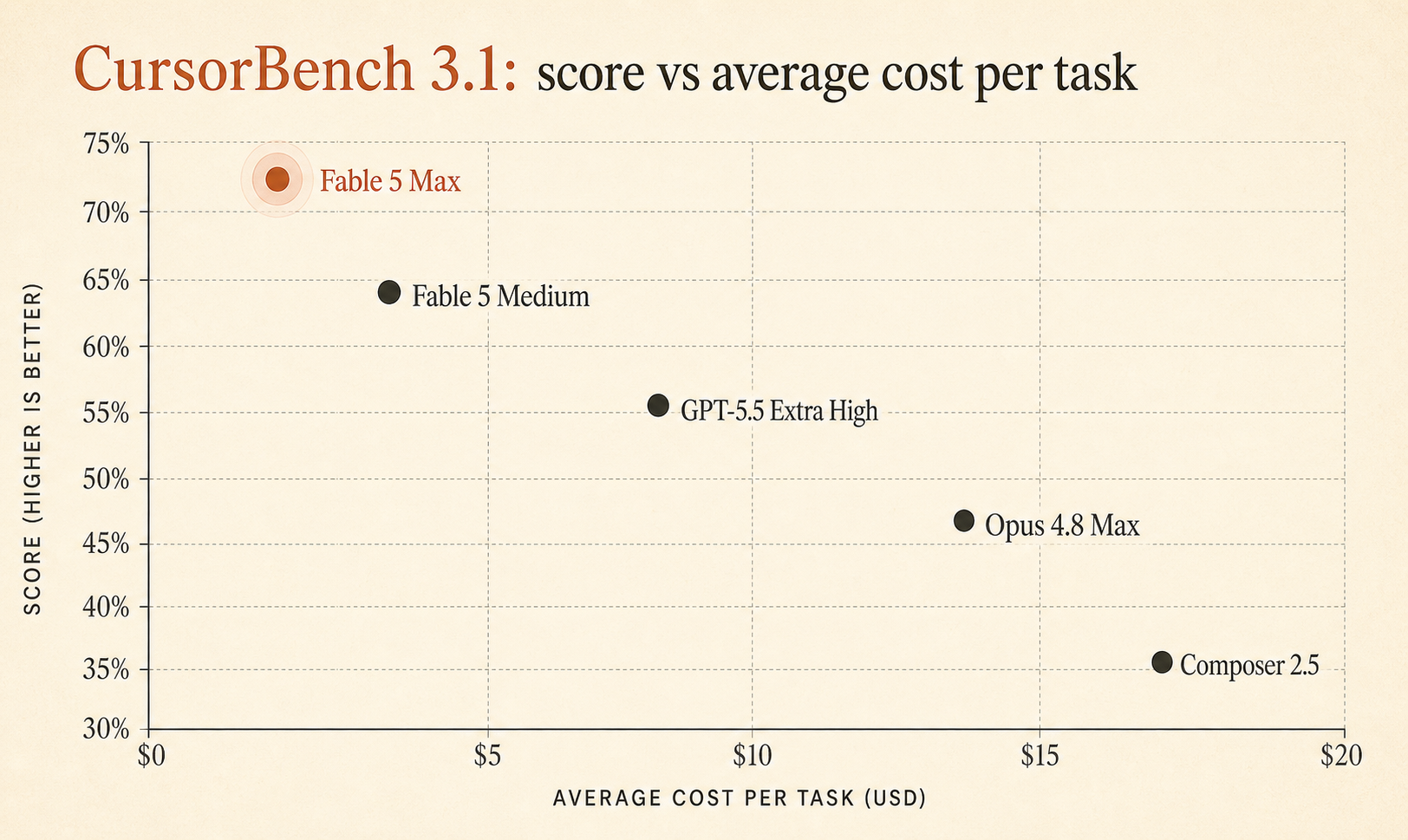
Cursor 的即時 CursorBench 3.1 頁面現在把 Fable 5 Max 列在 72.9%,每個任務平均成本 $18.02,領先 GPT-5.5 Extra High 的 64.3% / $4.37,以及 Opus 4.8 Max 的 63.8% / $7.59(Cursor)。這不是小差距,而且這個 benchmark 測的是實際 Cursor session,不是玩具級演算法題。
它也很貴。如果你整天跑 agents,會痛得很明顯。
所以現在 Claude Code 和 Cursor 的爭論,不該是「Fable 5 好不好?」排行榜已經回答了。更好的問題是:8 到 9 個百分點的勝差,什麼時候值得付 2 倍到 4 倍的帳單?
我的答案:Fable 5 是你升級處理時才拿出來的模型,不是每次改東西都盲目開著的預設。真正有意思的結果不只是 Fable 5 Max 贏了,而是 Fable 5 Medium 和 Low 可能才是更實用的故事。
CursorBench 3.1 實際上在測什麼
Cursor 將 CursorBench 3.1 描述為一個評估「來自真實 Cursor session、模糊、多檔案任務」的測試,分數越高越好(Cursor)。這句話很關鍵。開發者對 coding agents 的挫折,大多不是來自單檔案 LeetCode 式失敗,而是那些亂糟糟的東西:
- 理解 repo 結構
- 判斷哪些檔案重要
- 規劃跨邊界修改
- 在沒有被過度指示的情況下找 bug
- review 程式碼時不要幻覺出不存在的問題
- 讓上下文撐到任務完成
CursorBench 3.1 新增了聚焦於 codebase 理解、找 bug、規劃、code review 的問題,也改進了一些編輯任務的評分標準(Cursor)。Cursor 較長的 benchmark 文章說,這套測試是為了在公開 benchmark 越來越飽和時區分 frontier models,並且 Cursor 會把線上產品訊號和離線評分一起追蹤(Cursor blog)。
這不代表它完美。它仍然是一家供應商的 eval,在一個產品的 agent harness 裡跑,使用一種任務分布。Cursor 也提醒,小幅分數差異可能不具統計意義(Cursor)。所以,不,你不該把 0.6 分差距當成聖旨。
但 Fable 5 Max 不是贏 0.6 分。它領先 GPT-5.5 Extra High 8.6 分,領先 Opus 4.8 Max 9.1 分。這已經大到值得認真看待。
以下是對日常 coding-agent 選擇真正重要的精簡排行榜切片:
| 模型 / 設定 | CursorBench 3.1 分數 | 平均成本 / 任務 | Tokens / 任務 | Steps / 任務 |
|---|---|---|---|---|
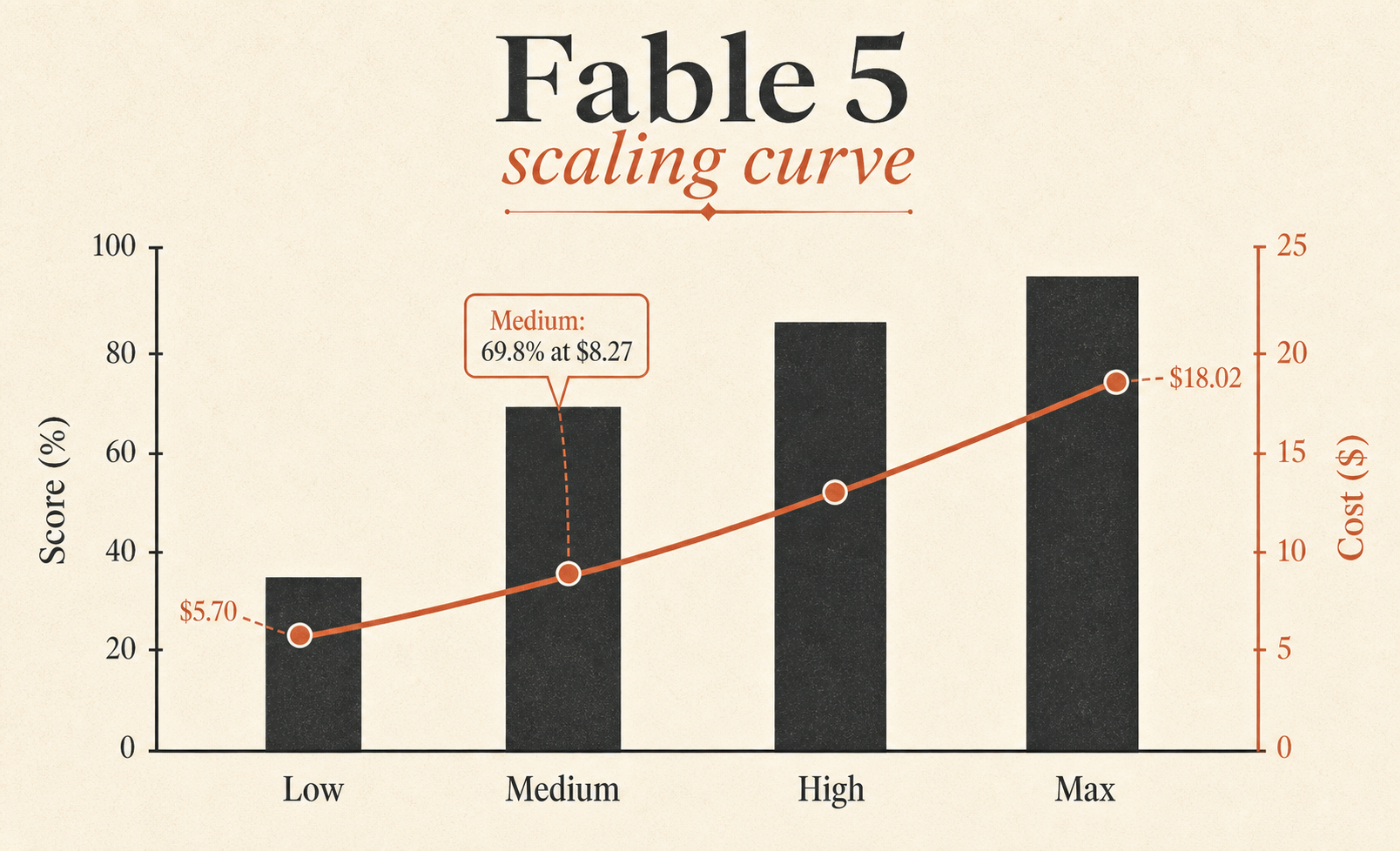
| Fable 5 Max | 72.9% | $18.02 | 63,842 | 76 |
| Fable 5 Extra High | 72.0% | $13.74 | 48,754 | 63 |
| Fable 5 High | 70.6% | $10.81 | 37,173 | 54 |
| Fable 5 Medium | 69.8% | $8.27 | 28,507 | 47 |
| Opus 4.7 Max | 64.8% | $11.02 | 62,989 | 96 |
| GPT-5.5 Extra High | 64.3% | $4.37 | 17,905 | 46 |
| Fable 5 Low | 64.2% | $5.70 | 18,882 | 36 |
| Opus 4.8 Max | 63.8% | $7.59 | 77,370 | 60 |
| Composer 2.5 | 63.2% | $0.55 | 15,152 | 37 |
Cursor 表示,每個任務的平均成本,是把各模型公布的每百萬 token 價格套用到每個 CursorBench 任務使用的 token 上,包含輸入、cache read、cache write、輸出 token,然後跨任務取平均(Cursor)。這個框架是對的。Agents 不是靠感覺定價,而是看它們讀了多少、重寫多少、重試多少、解釋多少。
贏家是 Fable 5。價值贏家不是。
Fable 5 Max 在原始分數上贏了。不需要任何話術。
但從每美元效能來看,畫面很殘酷:
| 模型 / 設定 | 分數 | 成本 | 每 $1 分數點 |
|---|---|---|---|
| Fable 5 Max | 72.9% | $18.02 | 4.0 |
| Fable 5 Medium | 69.8% | $8.27 | 8.4 |
| GPT-5.5 Extra High | 64.3% | $4.37 | 14.7 |
| Opus 4.8 Max | 63.8% | $7.59 | 8.4 |
| Composer 2.5 | 63.2% | $0.55 | 114.9 |
最後一列就是社群吵得這麼兇的原因。Composer 2.5 在絕對品質上不接近 Fable 5 Max,但在這份排行榜上,它和 GPT-5.5 Extra High、Opus 4.8 Max 很接近,成本卻幾乎只是零頭。如果你每週跑幾百個 agent 任務,這比榜首頭銜重要多了。
邊際算術更清楚:
Fable 5 Max vs GPT-5.5 Extra High:
+8.6 score points, +$13.65/task
≈ $1.59 per extra score point對上 Opus 4.8 Max:
Fable 5 Max vs Opus 4.8 Max:
+9.1 score points, +$10.43/task
≈ $1.15 per extra score point對一次棘手 migration 來說,多花 $10 到 $14 根本是雜訊。如果模型省掉一次失敗嘗試,它就回本了。可是對一個會在每個 pull request、dependency bump、lint failure、test repair 上跑背景 agents 的團隊來說,這個溢價會變成預算政策。
最被低估的一列是 Fable 5 Medium。它拿到 69.8%,只落後 Fable 5 Max 3.1 分,成本卻是 $8.27,不是 $18.02。換句話說,Medium 保留了大約 96% 的 Max benchmark 分數,但只要大約 46% 的 Max 任務成本。如果你想找一個 Fable 預設,那才是你該盯著看的列。
社群真正吵的是 Token 消耗
即時討論串一點也不含蓄。在 Cursor subreddit 的發布討論串裡,一位使用者的第一印象是 Fable 5 展現出非常細緻的推理和野心很大的計畫,但也「非常慢」,而且因需求暴增,連線小毛病也在預期內(Reddit r/cursor)。這和排行榜吻合:Fable 5 Max 每個任務使用 63,842 tokens,以及 76 steps。它不是輕量反射型模型。
在一個關於 CursorBench 結果的 ClaudeAI 討論串裡,反彈很快就來了:一位留言者稱它「不是合法 benchmark」,另一位馬上問如果 fable medium 更便宜,是不是「就沒有理由用 opus 了」,還有人回覆指出 Composer 2.5「非常便宜又好用」(Reddit r/ClaudeAI)。這正是合理的分歧:benchmark 信任度、Opus 被取代、以及便宜但夠好的替代方案。
一個 ClaudeCode 討論串更貼近營運問題。原貼注意到 Fable 5 Low 在 CursorBench 上比 Opus 4.8 Max 更聰明也更便宜,留言者則集中討論每個任務成本和 token 效率。有則留言說得很直白:對 indie developers 和 freelancers 來說,每個任務成本與相對分數才是重要 benchmark,因為生產力很快可能會用 token consumption 來衡量(Reddit r/ClaudeCode)。
這個說法對照表格是站得住腳的。
Fable 5 Low:
- 64.2%
- $5.70
- 18,882 tokens
Opus 4.8 Max:
- 63.8%
- $7.59
- 77,370 tokens
所以在 CursorBench 3.1 上,Fable 5 Low 稍微領先 Opus 4.8 Max,每個任務少花 $1.89,而且少用大約 76% tokens。這不是小小註腳,這是產品決策。
如果你在 Cursor 裡仍然把 Opus 4.8 Max 當成「認真 Claude」設定,這個 benchmark 等於告訴你:你應該立刻測 Fable 5 Low 和 Medium。不是因為每個 repo 都會符合 Cursor 的任務組合,而是因為舉證責任已經轉移了。
Anthropic 的定價解釋了為什麼大家被嚇到
Anthropic 在 2026 年 6 月 9 日推出 Claude Fable 5 和 Claude Mythos 5,並將 Mythos 級模型描述為高於 Opus 的一層。在 Anthropic 的發布文章中,Fable 5 是一般發布版本,而 Mythos 5 是同一個底層模型,但為受限可信存取用途移除部分 safeguards(Anthropic)。
API 價格簡單而且高:Fable 5 和 Mythos 5 都是 每百萬輸入 tokens $10、每百萬輸出 tokens $50(Anthropic)。Anthropic 也表示 Fable 5 可透過 Claude API 以 claude-fable-5 使用,而 subscription-plan 存取只暫時包含到 6 月 22 日,除非容量允許延長(Anthropic)。
這個價格會改變你思考 agent prompts 的方式。
用便宜模型時,凌亂的上下文還能忍。你貼太多、要求太廣、讓 agent 到處閒逛,帳單雖然煩人但還能承受。到了 Fable 5 Max 級成本,糟糕的 harness design 會直接現形。每個不必要的檔案、重複的 plan、冗長的 tool result、失敗的 patch attempt,都會疊上去。
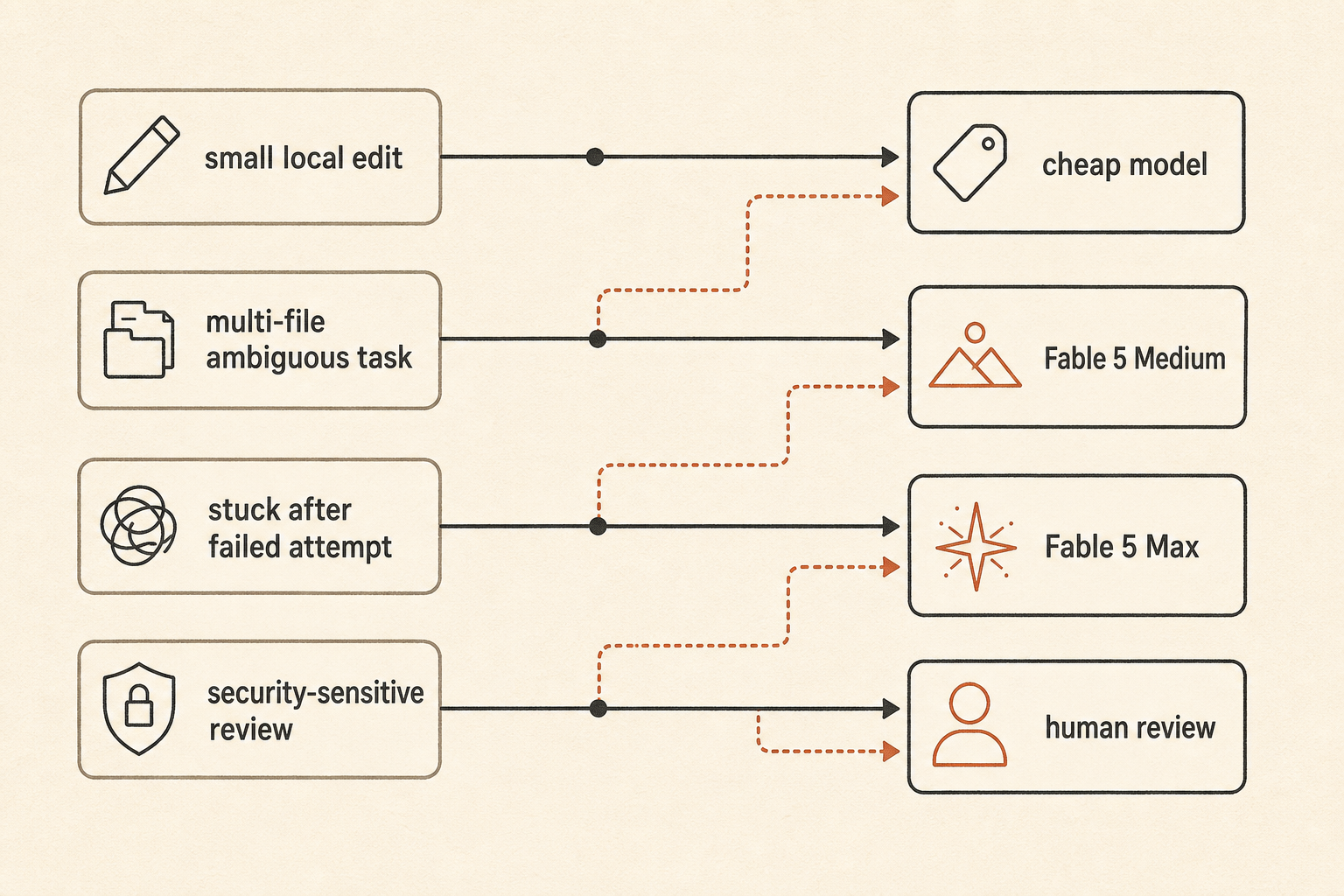
實用的 routing policy 大概長這樣:
default: fast/cheap model for local edits and small bugs
escalate: Fable 5 Medium for ambiguous multi-file work
reserve: Fable 5 Max for high-risk refactors, stuck tasks, and final review
fallback: human review when the agent starts exploring instead of editing這比「用最好的模型」沒那麼刺激。但這也是團隊避免醒來看到像雲端事故一樣 token 帳單的做法。
這個 Benchmark 有一個可用性星號
有一個麻煩的時事轉折:Fable 5 的發布週沒有一直風平浪靜。
6 月 12 日,Anthropic 發布聲明,表示美國政府發布出口管制指令,要求暫停外國國民存取 Fable 5 和 Mythos 5,包括外國國籍的 Anthropic 員工;Anthropic 表示,當下唯一能遵守的方法,是對所有客戶停用這些模型(Anthropic)。公司表示其他 Claude models 不受影響。
對 benchmark 解讀來說,這不會抹掉 CursorBench 結果。排行榜仍然是 Cursor agent harness 下模型能力的有用證據。但對採購和工作流程設計來說,可用性不是註腳。如果你的團隊標準化在一個可能因容量、政策或安全閘門而消失的模型上,你需要 fallback path。
這也是不要把 Fable 5 Max 接到每個任務上的另一個理由。最好的工程設定是 model-portable:
- 不依賴單一 provider quirks 的 prompts
- 任務邊界夠小,讓第二個模型可以重試
- 在你自己的 repo 上做 evals,而不是只看公開排行榜
- 按任務記錄成本,不只是看月結發票
- 對危險 diff 設置 human escalation point
Benchmarks 告訴你從哪裡開始。你的 repo 告訴你該 ship 什麼。
我的看法:把 Fable 5 當資深 Reviewer 用,不要當預設 Autocomplete
Fable 5 Max 配得上 CursorBench 3.1 的榜首。在模糊、多檔案 Cursor 任務上拿到 72.9%,正是開發者該在意的訊號。它大幅打敗 GPT-5.5 Extra High 和 Opus 4.8 Max,足以改變模型選擇習慣。
但錯誤教訓是「永遠用 Max」。
正確教訓更窄:當模糊性是瓶頸時,Fable 5 值得付錢。Architecture migrations、跨檔案 bugs、ownership 不清的 failing test suites、細緻 review pass,以及「我需要 agent 在碰 code 前先形成 plan」這類任務都很適合。例行 CRUD edits、明顯 test fixes、格式清理、一檔案 refactors 則不適合。
如果你想從這份排行榜找實用預設,從這裡開始:
- Composer 2.5 用於便宜、夠好的例行 agent work。
- GPT-5.5 Extra High 用於想要強分數但成本遠低於 Fable Max 的時候。
- Fable 5 Medium 作為嚴肅 daily-driver 候選。
- Fable 5 Max 用於 escalation,不是背景噪音。
- Retest Opus 4.8 Max 在你的 workflow 裡;CursorBench 讓它很難被合理化為預設。
Fable 5 的標題是 72.9%。工程教訓是 routing。
真正用這些模型勝出的團隊,不會是永遠選最大模型的團隊。而是那些清楚知道什麼時候最大模型反而便宜的團隊。
想親自試 Claude Fable 5 的讀者,可以透過 OneHop 使用:Claude Fable 5 on OneHop,這是一個 drop-in endpoint,價格大約比牌價低 30%。新帳號有 $10 free,不需要信用卡。
延伸閱讀:Claude Fable 5 入門.

