Claude Fable 5 liderlik tablosuna sessizce sızmadı. Doğrudan tepeye indi.
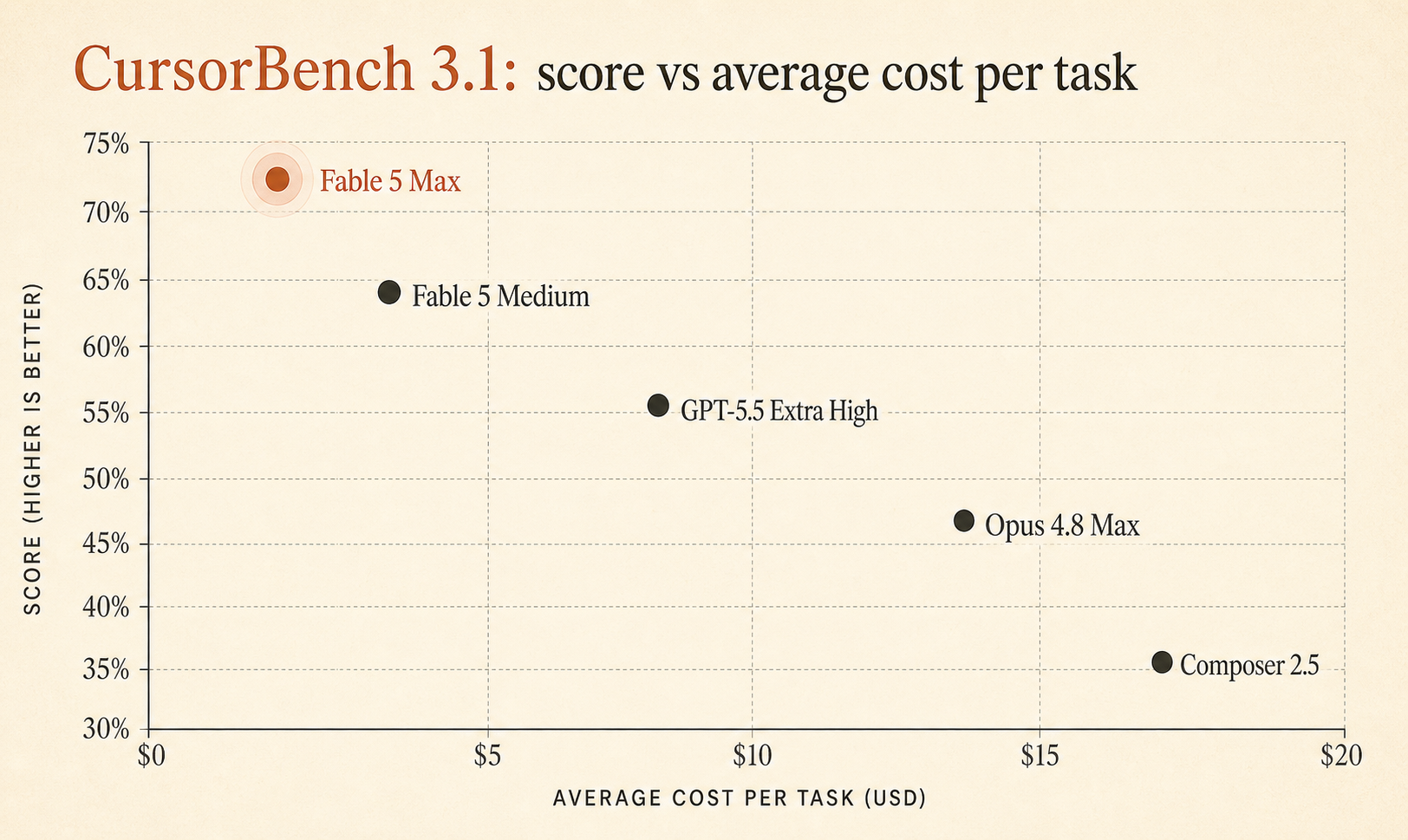
Cursor’ın canlı CursorBench 3.1 sayfası artık Fable 5 Max’i %72,9 ve görev başına ortalama $18.02 maliyetle gösteriyor; %64,3 / $4.37 ile GPT-5.5 Extra High ve %63,8 / $7.59 ile Opus 4.8 Max’in önünde (Cursor). Oyuncak algoritma bulmacaları değil, gerçek Cursor oturumları üzerine kurulmuş bir benchmark için bu ciddi bir kalite farkı.
Aynı zamanda pahalı. Ajanları gün boyu çalıştırıyorsanız can yakacak kadar pahalı.
Bu yüzden şu anki Claude Code ve Cursor tartışması “Fable 5 iyi mi?” değil. Liderlik tablosu bunun cevabını veriyor. Daha iyi soru şu: 8-9 puanlık bir üstünlük, faturanın 2 ila 4 katına çıkmasını ne zaman haklı çıkarır?
Benim cevabım: Fable 5, gerektiğinde yükselteceğiniz model; her düzenleme için körlemesine açık bırakacağınız model değil. İlginç sonuç sadece Fable 5 Max’in kazanması değil. Asıl mesele, Fable 5 Medium ve Low’un daha pratik hikâye olabilmesi.
CursorBench 3.1 Aslında Neyi Ölçüyor
Cursor, CursorBench 3.1’i “gerçek Cursor oturumlarından alınmış belirsiz, çok dosyalı görevlerin” değerlendirmesi olarak tanımlıyor; daha yüksek skor daha iyi demek (Cursor). Bu ifade önemli. Geliştiricilerin kodlama ajanlarıyla yaşadığı hayal kırıklıklarının çoğu, tek dosyalık LeetCode tarzı başarısızlıklardan gelmiyor. Dağınık işlerden geliyor:
- repo düzenini anlamak
- hangi dosyaların önemli olduğuna karar vermek
- sınırları aşan bir düzenlemeyi planlamak
- aşırı yönlendirme olmadan bug bulmak
- sahte bir sorun uydurmadan kod incelemek
- işi bitirecek kadar bağlamı canlı tutmak
CursorBench 3.1, kod tabanı anlama, bug bulma, planlama ve kod inceleme odaklı problemler ekledi; bazı düzenleme görevleri için değerlendirme ölçütlerini de iyileştirdi (Cursor). Cursor’ın daha uzun benchmark yazısı, bu setin halka açık benchmark’ların giderek doyuma ulaştığı yerde frontier modelleri ayırmayı amaçladığını ve Cursor’ın çevrimdışı notların yanında çevrimiçi ürün sinyallerini de izlediğini söylüyor (Cursor blog).
Bu onu kusursuz yapmaz. Hâlâ tek bir sağlayıcının değerlendirmesi; tek bir ürünün ajan koşumunda, tek bir görev dağılımıyla çalışıyor. Cursor ayrıca küçük skor farklarının istatistiksel olarak anlamlı olmayabileceği konusunda uyarıyor (Cursor). Yani evet, 0,6 puanlık farkı kutsal metin gibi okumamalısınız.
Ama Fable 5 Max 0,6 puanla kazanmıyor. GPT-5.5 Extra High’ın 8,6 puan, Opus 4.8 Max’in 9,1 puan önünde. Bu, ciddiye alınacak kadar büyük.
Günlük kodlama ajanı seçimleri için asıl önemli olan kompakt liderlik tablosu şöyle:
| Model / ayar | CursorBench 3.1 skoru | Ort. maliyet / görev | Token / görev | Adım / görev |
|---|---|---|---|---|
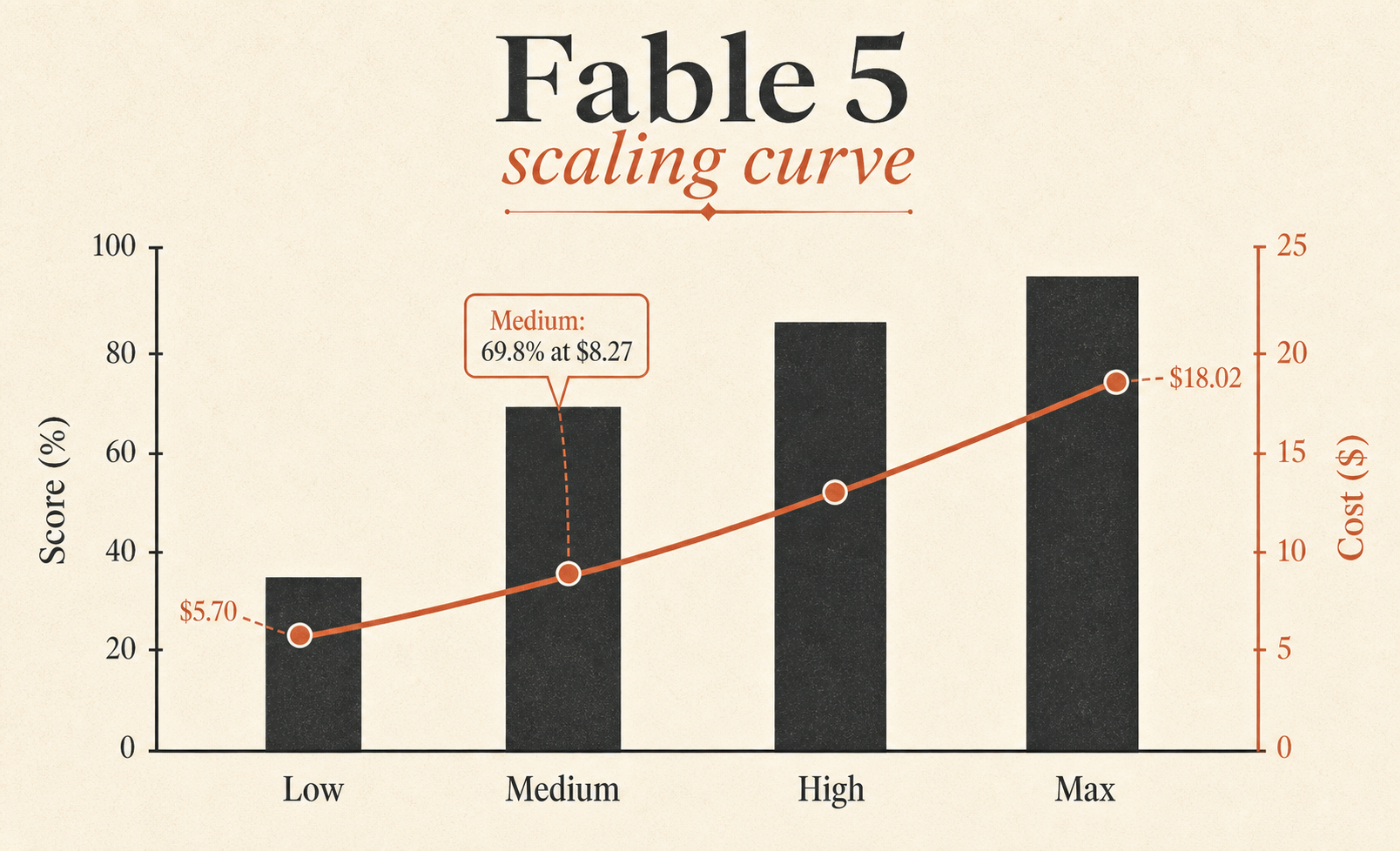
| Fable 5 Max | 72.9% | $18.02 | 63,842 | 76 |
| Fable 5 Extra High | 72.0% | $13.74 | 48,754 | 63 |
| Fable 5 High | 70.6% | $10.81 | 37,173 | 54 |
| Fable 5 Medium | 69.8% | $8.27 | 28,507 | 47 |
| Opus 4.7 Max | 64.8% | $11.02 | 62,989 | 96 |
| GPT-5.5 Extra High | 64.3% | $4.37 | 17,905 | 46 |
| Fable 5 Low | 64.2% | $5.70 | 18,882 | 36 |
| Opus 4.8 Max | 63.8% | $7.59 | 77,370 | 60 |
| Composer 2.5 | 63.2% | $0.55 | 15,152 | 37 |
Cursor, görev başına ortalama maliyetin her modelin yayımlanmış milyon-token başına fiyatı uygulanarak hesaplandığını söylüyor; buna input, cache read, cache write ve output token’ları dahil, her CursorBench görevinde kullanılan token’lara uygulanıyor ve sonra görevler üzerinden ortalaması alınıyor (Cursor). Doğru çerçeve bu. Ajanlar hislerle fiyatlanmaz. Ne kadar okuduklarına, yeniden yazdıklarına, tekrar denediklerine ve açıkladıklarına göre fiyatlanır.
Kazanan Fable 5. Değer Kazananı Değil.
Ham skorda Fable 5 Max kazanıyor. Bunu eğip bükmeye gerek yok.
Ama dolar başına performans görüntüsü acımasız:
| Model / ayar | Skor | Maliyet | $1 başına skor puanı |
|---|---|---|---|
| Fable 5 Max | 72.9% | $18.02 | 4.0 |
| Fable 5 Medium | 69.8% | $8.27 | 8.4 |
| GPT-5.5 Extra High | 64.3% | $4.37 | 14.7 |
| Opus 4.8 Max | 63.8% | $7.59 | 8.4 |
| Composer 2.5 | 63.2% | $0.55 | 114.9 |
Son satır, topluluk tartışmasının neden hararetli olduğunu açıklıyor. Composer 2.5 mutlak kalite açısından Fable 5 Max’e yakın değil; ama bu liderlik tablosunda GPT-5.5 Extra High ve Opus 4.8 Max’e yakın dururken kıyasla bozuk para seviyesinde maliyet çıkarıyor. Haftada yüzlerce ajan görevi çalıştırıyorsanız, bu bir liderlik tacından daha önemli.
Marjinal hesap daha net:
Fable 5 Max vs GPT-5.5 Extra High:
+8.6 score points, +$13.65/task
≈ $1.59 per extra score pointOpus 4.8 Max’e karşı:
Fable 5 Max vs Opus 4.8 Max:
+9.1 score points, +$10.43/task
≈ $1.15 per extra score pointTek bir çetrefilli migration için fazladan $10-$14 gürültüdür. Model tek bir başarısız denemeyi önlerse parasını çıkarmıştır. Ama her pull request, dependency bump, lint hatası ve test onarımı için arka planda ajan çalıştıran bir ekipte bu prim artık bütçe politikası olur.
En az değer verilen satır Fable 5 Medium. %69,8 alıyor; Fable 5 Max’in sadece 3,1 puan gerisinde ve $18.02 yerine $8.27. Başka deyişle Medium, Max’in benchmark skorunun yaklaşık %96’sını, Max’in görev maliyetinin yaklaşık %46’sıyla koruyor. Varsayılan bir Fable istiyorsanız, uzun uzun bakmanız gereken satır bu.
Topluluk Tartışması Aslında Token Yakma Hızıyla İlgili
Canlı başlıklar pek ince davranmıyor. Cursor subreddit’indeki lansman başlığında bir kullanıcının ilk izlenimleri, Fable 5’in çok ayrıntılı muhakeme ve iddialı bir plan gösterdiği, ama aynı zamanda “çok yavaş” olduğu yönündeydi; talep patladıkça bağlantı tuhaflıkları da bekleniyordu (Reddit r/cursor). Bu liderlik tablosuyla uyumlu: Fable 5 Max, görev başına 63.842 token ve görev başına 76 adım kullanıyor. Hafif bir refleks modeli değil.
CursorBench sonucu hakkındaki bir ClaudeAI başlığında itirazlar hemen geldi: bir yorumcu bunu “meşru bir benchmark değil” diye niteledi; bir başkası hemen “fable medium daha ucuzsa opus kullanmak için neden kalıyor mu” diye sordu; bir yanıt da Composer 2.5’in “çok ucuz ve iyi” olduğuna işaret etti (Reddit r/ClaudeAI). Doğru ayrım bu: benchmark’a güven, Opus’un yerinden edilmesi ve ucuz-yeterince-iyi alternatifler.
Bir ClaudeCode başlığı operasyonel meseleye daha da yaklaştı. Orijinal gönderi, Fable 5 Low’un CursorBench’te Opus 4.8 Max’ten daha akıllı ve daha ucuz göründüğünü fark etti; yorumlar da görev başına maliyet ve token verimliliğine odaklandı. Bir yorum bunu açıkça söyledi: bağımsız geliştiriciler ve freelancer’lar için önemli benchmark’lar görev başına maliyet ve göreli skordur, çünkü üretkenlik yakında token tüketimiyle değerlendirilebilir (Reddit r/ClaudeCode).
Bu iddia tabloyla örtüşüyor.
Fable 5 Low:
- 64.2%
- $5.70
- 18,882 tokens
Opus 4.8 Max:
- 63.8%
- $7.59
- 77,370 tokens
Yani CursorBench 3.1’de Fable 5 Low, Opus 4.8 Max’in biraz önünde, görev başına $1.89 daha ucuz ve yaklaşık %76 daha az token kullanıyor. Bu küçük bir dipnot değil. Bu bir ürün kararı.
Cursor içinde hâlâ “ciddi Claude” ayarınız olarak Opus 4.8 Max kullanıyorsanız, benchmark Fable 5 Low ve Medium’u hemen test etmeniz gerektiğini söylüyor. Her repo Cursor’ın görev karışımıyla birebir uyuşacağı için değil. İspat yükü yer değiştirdiği için.
Anthropic’in Fiyatlandırması Etiket Şokunu Açıklıyor
Anthropic, Claude Fable 5 ve Claude Mythos 5’i 9 Haziran 2026’da duyurdu; Mythos sınıfı modelleri Opus’un üzerinde bir katman olarak tanımladı. Anthropic’in lansman yazısında Fable 5 genel sürüm, Mythos 5 ise kısıtlı güvenilir erişim kullanımı için bazı güvenlik önlemleri kaldırılmış aynı temel model olarak anlatılıyor (Anthropic).
API fiyatı basit ve yüksek: hem Fable 5 hem Mythos 5 için milyon input token başına $10 ve milyon output token başına $50 (Anthropic). Anthropic ayrıca Fable 5’in Claude API üzerinden claude-fable-5 olarak kullanılabildiğini ve abonelik planı erişiminin kapasite uzatmaya izin vermezse yalnızca 22 Haziran’a kadar geçici olarak dahil edildiğini söyledi (Anthropic).
Bu fiyatlandırma, ajan prompt’larını düşünme biçiminizi değiştirir.
Ucuz modellerde özensiz bağlam tolere edilebilir. Çok fazla şey yapıştırırsınız, çok geniş bir değişiklik istersiniz, ajanın dolaşmasına izin verirsiniz; fatura sinir bozucu olur ama hayatta kalınır. Fable 5 Max sınıfı maliyetlerde kötü koşum tasarımı görünür hâle gelir. Gereksiz her dosya, tekrarlanan her plan, laf kalabalığı yapan her araç sonucu ve başarısız her patch denemesi üst üste biner.
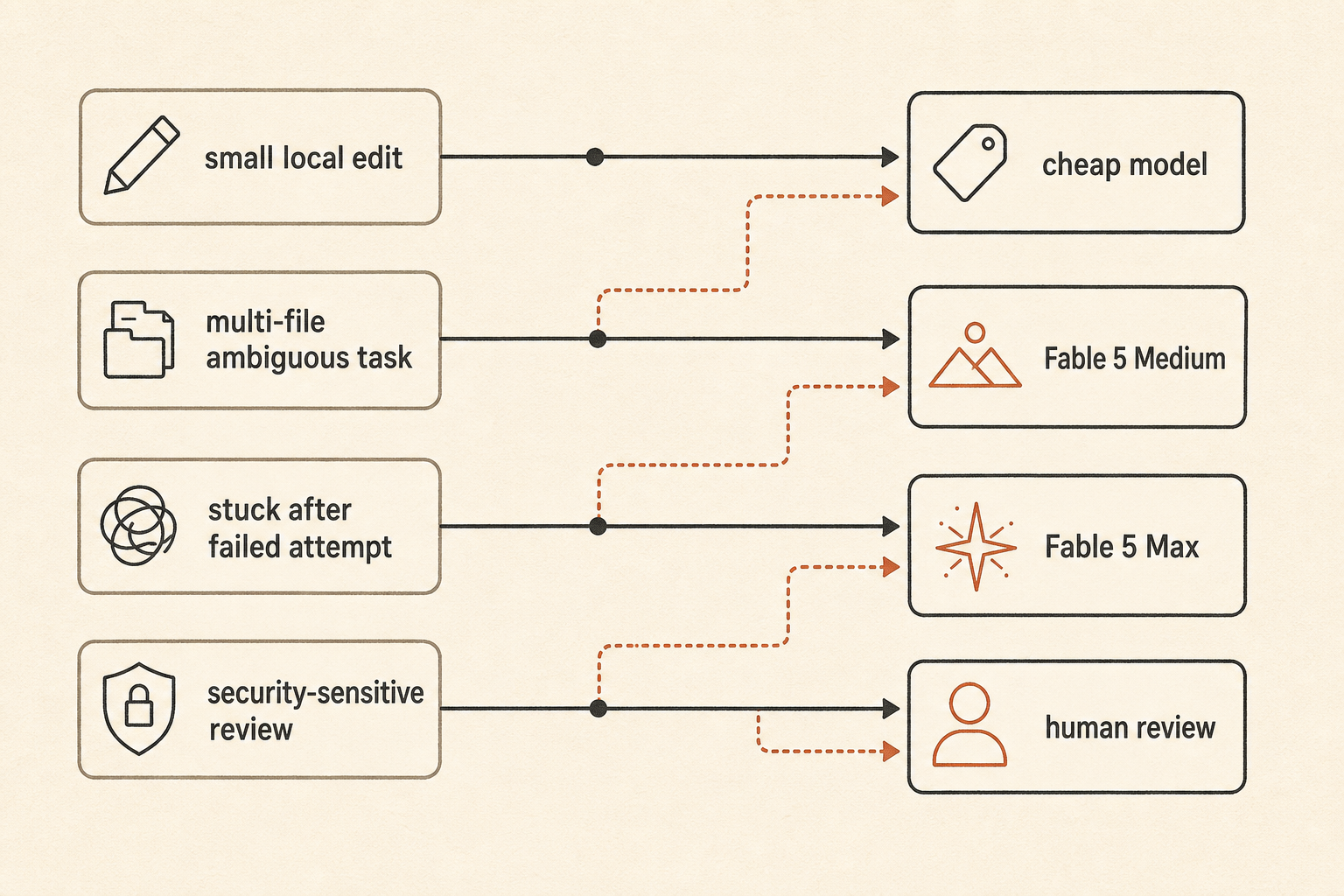
Pratik bir yönlendirme politikası şöyle görünür:
default: fast/cheap model for local edits and small bugs
escalate: Fable 5 Medium for ambiguous multi-file work
reserve: Fable 5 Max for high-risk refactors, stuck tasks, and final review
fallback: human review when the agent starts exploring instead of editingBu, “en iyi modeli kullan” kadar heyecanlı değil. Ama ekiplerin bir bulut vakasına benzeyen token faturasıyla uyanmamasını sağlayan şey de bu.
Benchmark’ın Bir Erişilebilirlik Yıldızı Var
Güncel olaylara dair dağınık bir ayrıntı var: Fable 5’in çıkış haftası sessiz kalmadı.
12 Haziran’da Anthropic, ABD hükümetinin yabancı uyrukluların Fable 5 ve Mythos 5’e erişimini askıya almak için bir ihracat kontrol direktifi yayımladığını; buna yabancı uyruklu Anthropic çalışanlarının da dahil olduğunu belirten bir açıklama yayımladı. Anthropic, buna uymanın o anki tek yolunun modelleri tüm müşteriler için devre dışı bırakmak olduğunu söyledi (Anthropic). Şirket, diğer Claude modellerinin etkilenmediğini belirtti.
Benchmark yorumu açısından bu, CursorBench sonucunu silmiyor. Liderlik tablosu hâlâ Cursor’ın ajan koşumu altında model kabiliyeti hakkında yararlı bir kanıt. Ama satın alma ve iş akışı tasarımı için erişilebilirlik dipnot değildir. Ekibiniz kapasite, politika veya güvenlik kapıları nedeniyle ortadan kaybolabilecek bir modeli standartlaştırırsa, bir fallback yoluna ihtiyacınız var.
Fable 5 Max’i her göreve bağlamamanız için bir neden daha bu. En iyi mühendislik düzeni model taşınabilir olandır:
- tek bir sağlayıcının tuhaflıklarına bağlı olmayan prompt’lar
- ikinci bir modelin tekrar deneyebileceği kadar küçük görev sınırları
- yalnızca halka açık liderlik tabloları değil, kendi reponuzda eval’lar
- yalnızca aylık faturalar değil, görev başına maliyet kayıtları
- tehlikeli diff’ler için insana yükseltme noktası
Benchmark’lar nereden başlayacağınızı söyler. Ne göndereceğinizi reponuz söyler.
Benim Görüşüm: Fable 5’i Varsayılan Autocomplete Gibi Değil, Kıdemli Reviewer Gibi Kullanın
Fable 5 Max, CursorBench 3.1’de tepeyi hak ediyor. Belirsiz, çok dosyalı Cursor görevlerinde %72,9 skor, geliştiricilerin önemsemesi gereken sinyalin tam türü. GPT-5.5 Extra High ve Opus 4.8 Max’i, model seçme alışkanlıklarını değiştirmeye yetecek kadar geride bırakıyor.
Ama çıkarılacak yanlış ders “her zaman Max kullan” olur.
Doğru ders daha dar: Fable 5, belirsizlik darboğaz olduğunda parasını hak eder. Mimari migration’lar, dosyalar arası bug’lar, sahipliği belirsiz kırık test setleri, ince kod inceleme geçişleri ve “ajana koda dokunmadan önce plan kurdurmam gerekiyor” işleri iyi uyum sağlar. Rutin CRUD düzenlemeleri, bariz test düzeltmeleri, format temizliği ve tek dosyalık refactor’lar sağlamaz.
Bu liderlik tablosundan pratik varsayılanı istiyorsanız, şununla başlayın:
- Composer 2.5 ucuz, yeterince iyi rutin ajan işleri için.
- GPT-5.5 Extra High Fable Max’ten çok daha düşük maliyetle güçlü skor istediğinizde.
- Fable 5 Medium ciddi günlük kullanım adayı olarak.
- Fable 5 Max arka plan gürültüsü değil, yükseltme seçeneği olarak.
- Opus 4.8 Max’i yeniden test edin; CursorBench onu varsayılan olarak savunmayı zorlaştırıyor.
Fable 5’in manşeti %72,9. Mühendislik dersi yönlendirme.
Bu modellerle kazanan ekipler her zaman en büyük modeli seçenler olmayacak. En büyük modelin tam olarak ne zaman ucuz olduğunu bilenler olacak.
Claude Fable 5’i kendileri denemek isteyen okurlar OneHop üzerinden kullanabilir: OneHop’ta Claude Fable 5, liste fiyatının yaklaşık %30 altında fiyatlanan drop-in endpoint. Yeni hesaplar $10 ücretsiz alır, kart gerekmez.
Ek okuma: Claude Fable 5’e başlangıç.

