Claude Fable 5 не прокрался в таблицу лидеров. Он приземлился сразу на вершине.
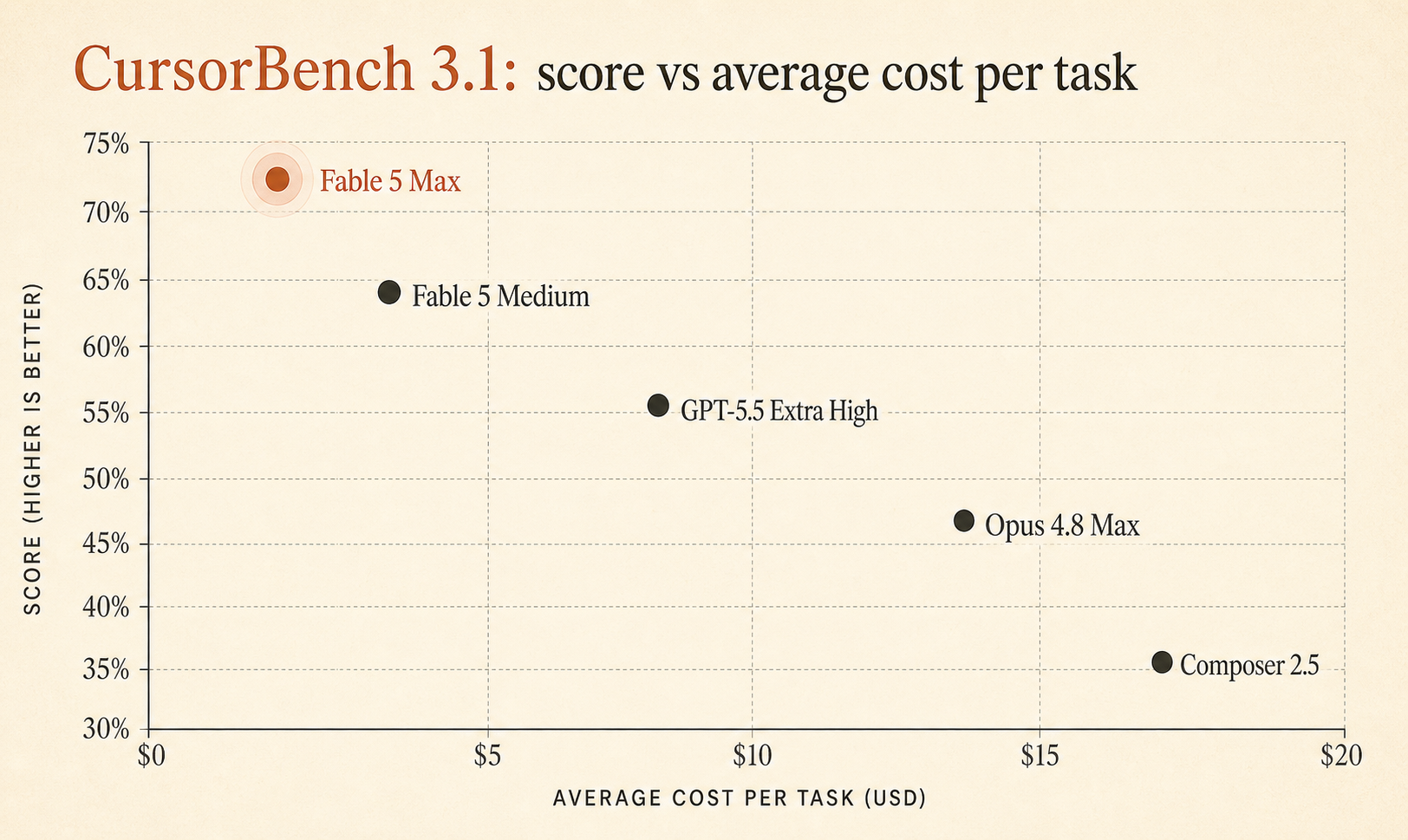
Живая страница CursorBench 3.1 от Cursor теперь показывает Fable 5 Max на уровне 72,9% при средней стоимости $18.02 за задачу, выше GPT-5.5 Extra High с 64,3% / $4.37 и Opus 4.8 Max с 63,8% / $7.59 (Cursor). Это большой разрыв в качестве на бенчмарке, построенном вокруг реальных сессий Cursor, а не игрушечных алгоритмических задачек.
И это дорого. Больно дорого, если вы гоняете агентов весь день.
Поэтому нынешний спор вокруг Claude Code и Cursor — это не «хорош ли Fable 5?». Таблица лидеров уже ответила. Более правильный вопрос: когда победа на 8–9 пунктов оправдывает счет в 2–4 раза выше?
Мой ответ: Fable 5 — это модель для эскалации, а не модель, которую надо бездумно оставлять включенной для каждой правки. Самый интересный результат не только в том, что Fable 5 Max побеждает. А в том, что Fable 5 Medium и Low могут оказаться куда более практичной историей.
Что на самом деле измеряет CursorBench 3.1
Cursor описывает CursorBench 3.1 как оценку «неоднозначных многофайловых задач из реальных сессий Cursor», где чем выше результат, тем лучше (Cursor). Эта формулировка важна. Большая часть раздражения разработчиков от кодинговых агентов возникает не из-за провалов в одном файле в стиле LeetCode. Она возникает из грязной реальности:
- понять структуру репозитория
- решить, какие файлы важны
- спланировать правку через границы модулей
- найти баги без чрезмерно подробных указаний
- ревьюить код, не выдумывая несуществующую проблему
- удерживать контекст достаточно долго, чтобы закончить
CursorBench 3.1 добавил задачи, сфокусированные на понимании кодовой базы, поиске багов, планировании и ревью кода, а также улучшил критерии оценки для части задач на редактирование (Cursor). В более подробном разборе бенчмарка Cursor пишет, что набор должен разделять frontier-модели там, где публичные бенчмарки все чаще насыщены, и что Cursor отслеживает онлайн-сигналы продукта вместе с офлайн-оценками (Cursor blog).
Это не делает его идеальным. Это все еще eval одного вендора, запущенный внутри агентной обвязки одного продукта, с одним распределением задач. Cursor также предупреждает, что небольшие различия в баллах могут быть статистически незначимыми (Cursor). Так что нет, разрыв в 0,6 пункта не стоит принимать как истину в последней инстанции.
Но Fable 5 Max выигрывает не на 0,6 пункта. Он опережает GPT-5.5 Extra High на 8,6 пункта и Opus 4.8 Max на 9,1 пункта. Это уже достаточно много, чтобы воспринимать результат серьезно.
Вот компактный срез таблицы лидеров, который важен для повседневного выбора кодингового агента:
| Модель / настройка | Результат CursorBench 3.1 | Средняя стоимость / задача | Токены / задача | Шаги / задача |
|---|---|---|---|---|
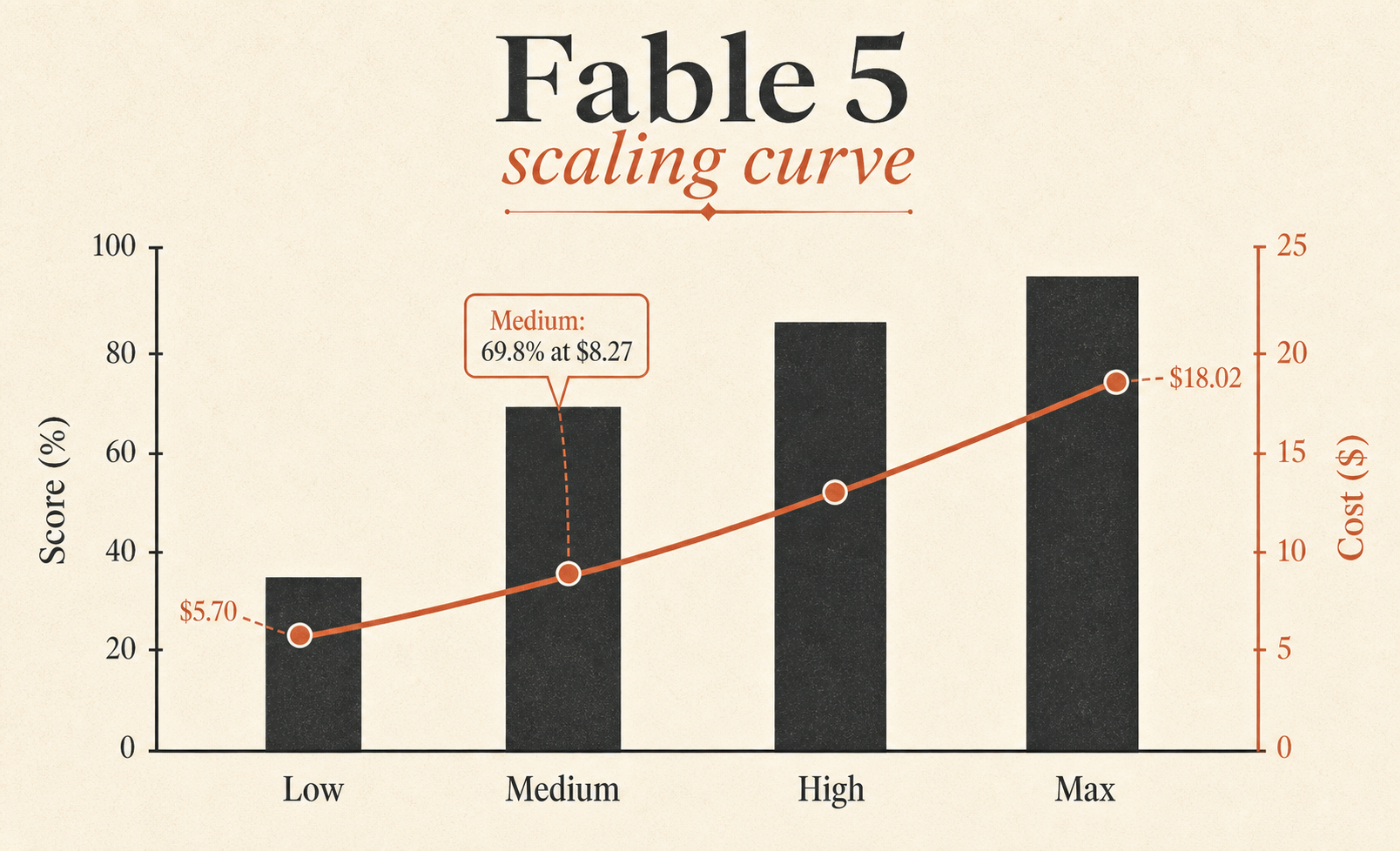
| Fable 5 Max | 72.9% | $18.02 | 63,842 | 76 |
| Fable 5 Extra High | 72.0% | $13.74 | 48,754 | 63 |
| Fable 5 High | 70.6% | $10.81 | 37,173 | 54 |
| Fable 5 Medium | 69.8% | $8.27 | 28,507 | 47 |
| Opus 4.7 Max | 64.8% | $11.02 | 62,989 | 96 |
| GPT-5.5 Extra High | 64.3% | $4.37 | 17,905 | 46 |
| Fable 5 Low | 64.2% | $5.70 | 18,882 | 36 |
| Opus 4.8 Max | 63.8% | $7.59 | 77,370 | 60 |
| Composer 2.5 | 63.2% | $0.55 | 15,152 | 37 |
Cursor говорит, что средняя стоимость задачи считается так: к токенам, использованным на каждой задаче CursorBench, применяется опубликованная цена каждой модели за миллион токенов — включая входные токены, чтение кэша, запись в кэш и выходные токены, — а затем берется среднее по задачам (Cursor). Это правильная рамка. Агенты стоят денег не по ощущениям. Они стоят денег по тому, сколько читают, переписывают, повторяют и объясняют.
Победитель — Fable 5. Победитель по ценности — нет.
Fable 5 Max побеждает по сырому результату. Тут не нужно ничего докручивать.
Но картина производительности на доллар жесткая:
| Модель / настройка | Результат | Стоимость | Пунктов результата за $1 |
|---|---|---|---|
| Fable 5 Max | 72.9% | $18.02 | 4.0 |
| Fable 5 Medium | 69.8% | $8.27 | 8.4 |
| GPT-5.5 Extra High | 64.3% | $4.37 | 14.7 |
| Opus 4.8 Max | 63.8% | $7.59 | 8.4 |
| Composer 2.5 | 63.2% | $0.55 | 114.9 |
Последняя строка — причина, почему спор в комьюнити такой горячий. Composer 2.5 далеко не рядом с Fable 5 Max по абсолютному качеству, но в этой таблице он близок к GPT-5.5 Extra High и Opus 4.8 Max, при этом стоит буквально копейки. Если вы запускаете сотни агентных задач в неделю, это важнее короны в leaderboard.
Маржинальная математика еще яснее:
Fable 5 Max vs GPT-5.5 Extra High:
+8.6 score points, +$13.65/task
≈ $1.59 per extra score pointПротив Opus 4.8 Max:
Fable 5 Max vs Opus 4.8 Max:
+9.1 score points, +$10.43/task
≈ $1.15 per extra score pointДля одной мерзкой миграции лишние $10–$14 — шум. Если модель сэкономит хотя бы одну проваленную попытку, она уже окупилась. Но для команды, которая запускает фоновых агентов на каждый pull request, dependency bump, падение lint и починку тестов, эта премия превращается в бюджетную политику.
Самая недооцененная строка — Fable 5 Medium. Он набирает 69,8%, всего на 3,1 пункта меньше Fable 5 Max, при цене $8.27 вместо $18.02. Иначе говоря, Medium сохраняет около 96% бенчмарк-результата Max примерно за 46% стоимости задачи Max. Если вам нужен Fable по умолчанию, смотреть надо именно на эту строку.
Спор в комьюнити на самом деле про сжигание токенов
Живые треды говорят без тонких намеков. В стартовом треде сабреддита Cursor один пользователь написал по первым впечатлениям, что Fable 5 показал очень подробное рассуждение и амбициозный план, но был еще и «очень медленным», с ожидаемыми проблемами подключения на фоне всплеска спроса (Reddit r/cursor). Это совпадает с таблицей: Fable 5 Max использует 63 842 токена на задачу и 76 шагов на задачу. Это не легкая рефлекторная модель.
В треде ClaudeAI о результате CursorBench возражения прилетели быстро: один комментатор назвал его «не настоящим бенчмарком», другой тут же спросил, нет ли теперь «никакой причины использовать opus, если fable medium дешевле», а в ответе указали на Composer 2.5 как на «очень дешевый и хороший» (Reddit r/ClaudeAI). Это правильный разрез: доверие к бенчмарку, вытеснение Opus и дешевые достаточно-хорошие альтернативы.
Тред ClaudeCode подошел еще ближе к операционной сути. Автор заметил, что Fable 5 Low умнее и дешевле, чем Opus 4.8 Max на CursorBench, а комментаторы сфокусировались на стоимости задачи и токенной эффективности. Один комментарий сформулировал прямо: для инди-разработчиков и фрилансеров важны стоимость задачи и относительный результат, потому что продуктивность скоро могут оценивать по потреблению токенов (Reddit r/ClaudeCode).
По таблице это сходится.
Fable 5 Low:
- 64.2%
- $5.70
- 18,882 токенов
Opus 4.8 Max:
- 63.8%
- $7.59
- 77,370 токенов
То есть на CursorBench 3.1 Fable 5 Low чуть опережает Opus 4.8 Max, стоит на $1.89 меньше за задачу и использует примерно на 76% меньше токенов. Это не мелкая сноска. Это продуктовое решение.
Если вы все еще используете Opus 4.8 Max как свою «серьезную Claude»-настройку внутри Cursor, бенчмарк говорит: надо немедленно протестировать Fable 5 Low и Medium. Не потому что каждый репозиторий совпадет с миксом задач Cursor. А потому что бремя доказательства сместилось.
Цены Anthropic объясняют шок от счета
Anthropic выпустила Claude Fable 5 и Claude Mythos 5 9 июня 2026 года, описав модели класса Mythos как уровень выше Opus. В запусковом посте Anthropic Fable 5 — это общий релиз, а Mythos 5 — та же базовая модель с частью safeguards, снятых для ограниченного trusted-access использования (Anthropic).
Цена API простая и высокая: $10 за миллион входных токенов и $50 за миллион выходных токенов как для Fable 5, так и для Mythos 5 (Anthropic). Anthropic также сказала, что Fable 5 доступен через Claude API как claude-fable-5, а доступ по подписочным планам включен только временно до 22 июня, если емкость не позволит продлить (Anthropic).
Такая цена меняет то, как стоит думать об агентных промптах.
С дешевыми моделями неряшливый контекст терпим. Вы вставляете лишнее, просите слишком широкое изменение, позволяете агенту бродить, и счет раздражает, но пережить можно. При стоимости уровня Fable 5 Max плохая архитектура harness становится видимой. Каждый лишний файл, повторный план, многословный результат инструмента и неудачная попытка патча накапливаются.
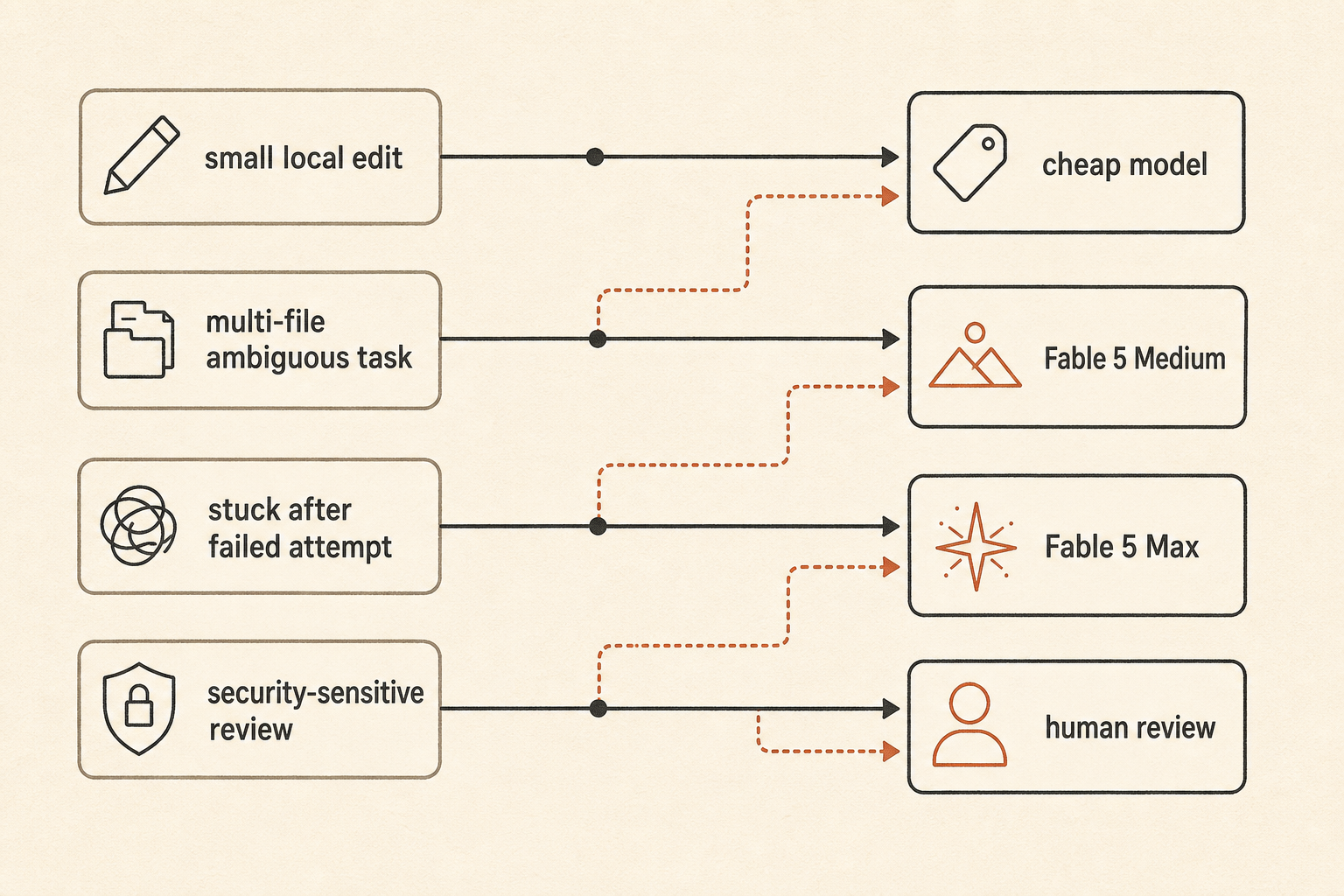
Практичная политика маршрутизации выглядит так:
default: fast/cheap model for local edits and small bugs
escalate: Fable 5 Medium for ambiguous multi-file work
reserve: Fable 5 Max for high-risk refactors, stuck tasks, and final review
fallback: human review when the agent starts exploring instead of editingЭто менее захватывающе, чем «используйте лучшую модель». Зато именно так команды не просыпаются от счета за токены, похожего на облачный инцидент.
У бенчмарка есть звездочка про доступность
Есть одна грязная деталь из текущих событий: неделя релиза Fable 5 не осталась тихой.
12 июня Anthropic опубликовала заявление, что правительство США выпустило директиву экспортного контроля о приостановке доступа к Fable 5 и Mythos 5 для иностранных граждан, включая сотрудников Anthropic с иностранным гражданством; Anthropic заявила, что единственный немедленный способ соблюсти требование — отключить модели для всех клиентов (Anthropic). Компания сказала, что другие модели Claude не затронуты.
Для интерпретации бенчмарка это не стирает результат CursorBench. Таблица лидеров все еще полезна как свидетельство возможностей модели в агентной обвязке Cursor. Но для закупок и проектирования workflow доступность — не сноска. Если команда стандартизируется на модели, которая может исчезнуть из-за емкости, политики или safety gating, вам нужен запасной путь.
Это еще одна причина не зашивать Fable 5 Max в каждую задачу. Лучшая инженерная настройка должна быть переносимой между моделями:
- промпты, которые не зависят от quirks одного провайдера
- достаточно маленькие границы задач, чтобы вторая модель могла повторить попытку
- evals на вашем собственном репозитории, а не только публичные leaderboard
- логи стоимости по задачам, а не только месячные счета
- точка эскалации к человеку для опасных diff
Бенчмарки говорят, с чего начать. Ваш репозиторий говорит, что отправлять в прод.
Мой вывод: используйте Fable 5 как старшего ревьюера, а не как autocomplete по умолчанию
Fable 5 Max заслуживает первого места в CursorBench 3.1. Результат 72,9% на неоднозначных многофайловых задачах Cursor — ровно тот сигнал, который должен волновать разработчиков. Он достаточно сильно обгоняет GPT-5.5 Extra High и Opus 4.8 Max, чтобы изменить привычки выбора модели.
Но неправильный вывод — «всегда используйте Max».
Правильный вывод уже: за Fable 5 стоит платить, когда узкое место — неоднозначность. Архитектурные миграции, баги на стыке файлов, падающие тестовые наборы с непонятной зоной ответственности, тонкие проходы ревью и ситуации «мне нужно, чтобы агент сначала сформировал план, а потом трогал код» — хорошие случаи. Рутинные CRUD-правки, очевидные фиксы тестов, чистка форматирования и рефакторинг одного файла — нет.
Если хотите практичный default из этой таблицы, начните с такого:
- Composer 2.5 для дешевой, достаточно-хорошей рутинной агентной работы.
- GPT-5.5 Extra High когда нужен сильный результат при куда меньшей цене, чем Fable Max.
- Fable 5 Medium как кандидат на серьезную ежедневную рабочую лошадку.
- Fable 5 Max для эскалации, а не фонового шума.
- Перетестируйте Opus 4.8 Max в своем workflow; CursorBench делает его трудно оправдать как default.
Заголовок Fable 5 — это 72,9%. Инженерный урок — маршрутизация.
Выиграют с этими моделями не те команды, которые всегда выбирают самую большую модель. Выиграют те, кто точно знает, когда самая большая модель оказывается дешевой.
Читатели, которые хотят сами попробовать Claude Fable 5, могут использовать его через OneHop: Claude Fable 5 on OneHop, drop-in endpoint примерно на 30% дешевле прайса. Новые аккаунты получают $10 бесплатно, карта не нужна.
Дополнительно: Getting started with Claude Fable 5.

