Claude Fable 5 hat sich nicht heimlich aufs Leaderboard geschlichen. Es ist direkt oben gelandet.
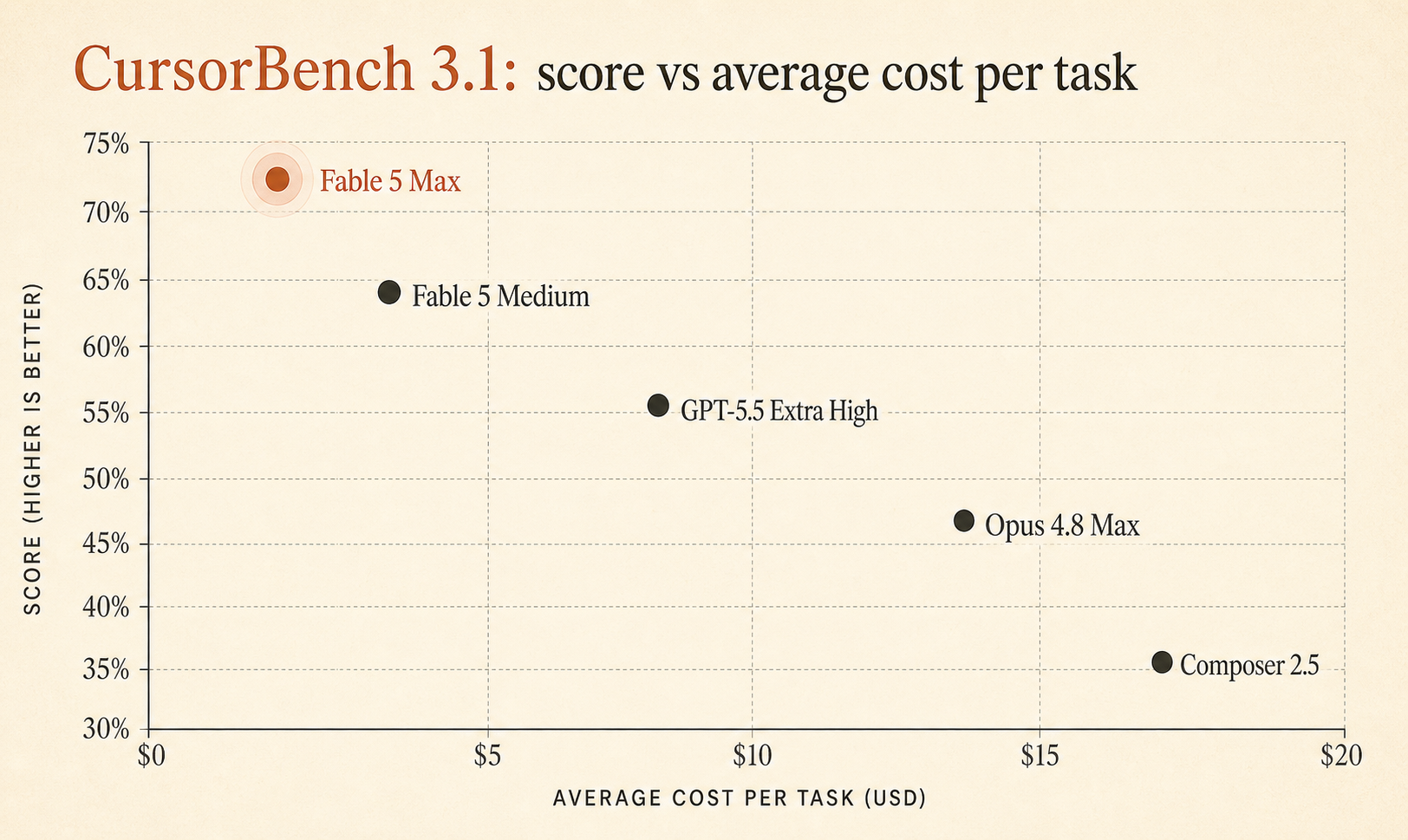
Cursors Live-Seite zu CursorBench 3.1 führt Fable 5 Max jetzt mit 72,9 % und $18.02 durchschnittlichen Kosten pro Aufgabe, vor GPT-5.5 Extra High mit 64,3 % / $4.37 und Opus 4.8 Max mit 63,8 % / $7.59 (Cursor). Das ist ein großer Qualitätsabstand auf einem Benchmark, der auf echten Cursor-Sessions basiert, nicht auf Spielzeug-Algorithmusrätseln.
Es ist außerdem teuer. Schmerzhaft teuer, wenn man den ganzen Tag Agenten laufen lässt.
Darum lautet die aktuelle Claude Code- und Cursor-Debatte nicht: „Ist Fable 5 gut?“ Das beantwortet das Leaderboard. Die bessere Frage ist: Wann rechtfertigt ein Vorsprung von 8 bis 9 Punkten eine 2- bis 4-mal so hohe Rechnung?
Meine Antwort: Fable 5 ist das Modell, zu dem man eskaliert, nicht das Modell, das man blind für jede Änderung eingeschaltet lässt. Das Interessante ist nicht nur, dass Fable 5 Max gewinnt. Sondern dass Fable 5 Medium und Low vielleicht die praktischere Geschichte sind.
Was CursorBench 3.1 tatsächlich misst
Cursor beschreibt CursorBench 3.1 als Evaluation von „mehrdeutigen Multi-File-Aufgaben aus echten Cursor-Sessions“, bei der ein höherer Score besser ist (Cursor). Diese Formulierung ist wichtig. Die meiste Frustration von Entwicklern mit Coding-Agenten entsteht nicht durch Single-File-Fehlschläge im LeetCode-Stil. Sie entsteht durch das unordentliche Zeug:
- ein Repo-Layout verstehen
- entscheiden, welche Dateien relevant sind
- eine Änderung über Dateigrenzen hinweg planen
- Bugs finden, ohne zu stark angeleitet zu werden
- Code reviewen, ohne ein falsches Problem zu halluzinieren
- Kontext lange genug halten, um fertig zu werden
CursorBench 3.1 hat Aufgaben mit Fokus auf Codebase-Verständnis, Bugfinding, Planung und Code-Review hinzugefügt und die Bewertungskriterien für einige Editieraufgaben verbessert (Cursor). Cursors ausführlicherer Benchmark-Beitrag sagt, die Suite solle Frontier-Modelle voneinander trennen, während öffentliche Benchmarks zunehmend gesättigt sind, und Cursor erfasse Online-Produktsignale zusätzlich zu Offline-Bewertungen (Cursor blog).
Das macht ihn nicht perfekt. Es ist immer noch die Eval eines einzelnen Anbieters, ausgeführt in der Agent-Harness eines einzelnen Produkts, mit einer bestimmten Aufgabenverteilung. Cursor warnt außerdem, dass kleine Score-Unterschiede statistisch nicht unbedingt bedeutsam sind (Cursor). Nein, man sollte einen Abstand von 0,6 Punkten also nicht als Evangelium behandeln.
Aber Fable 5 Max gewinnt nicht mit 0,6 Punkten Vorsprung. Es liegt 8,6 Punkte vor GPT-5.5 Extra High und 9,1 Punkte vor Opus 4.8 Max. Das ist groß genug, um es ernst zu nehmen.
Hier ist der kompakte Leaderboard-Ausschnitt, der für alltägliche Coding-Agent-Entscheidungen zählt:
| Modell / Einstellung | CursorBench 3.1 Score | Durchschnittliche Kosten / Aufgabe | Token / Aufgabe | Schritte / Aufgabe |
|---|---|---|---|---|
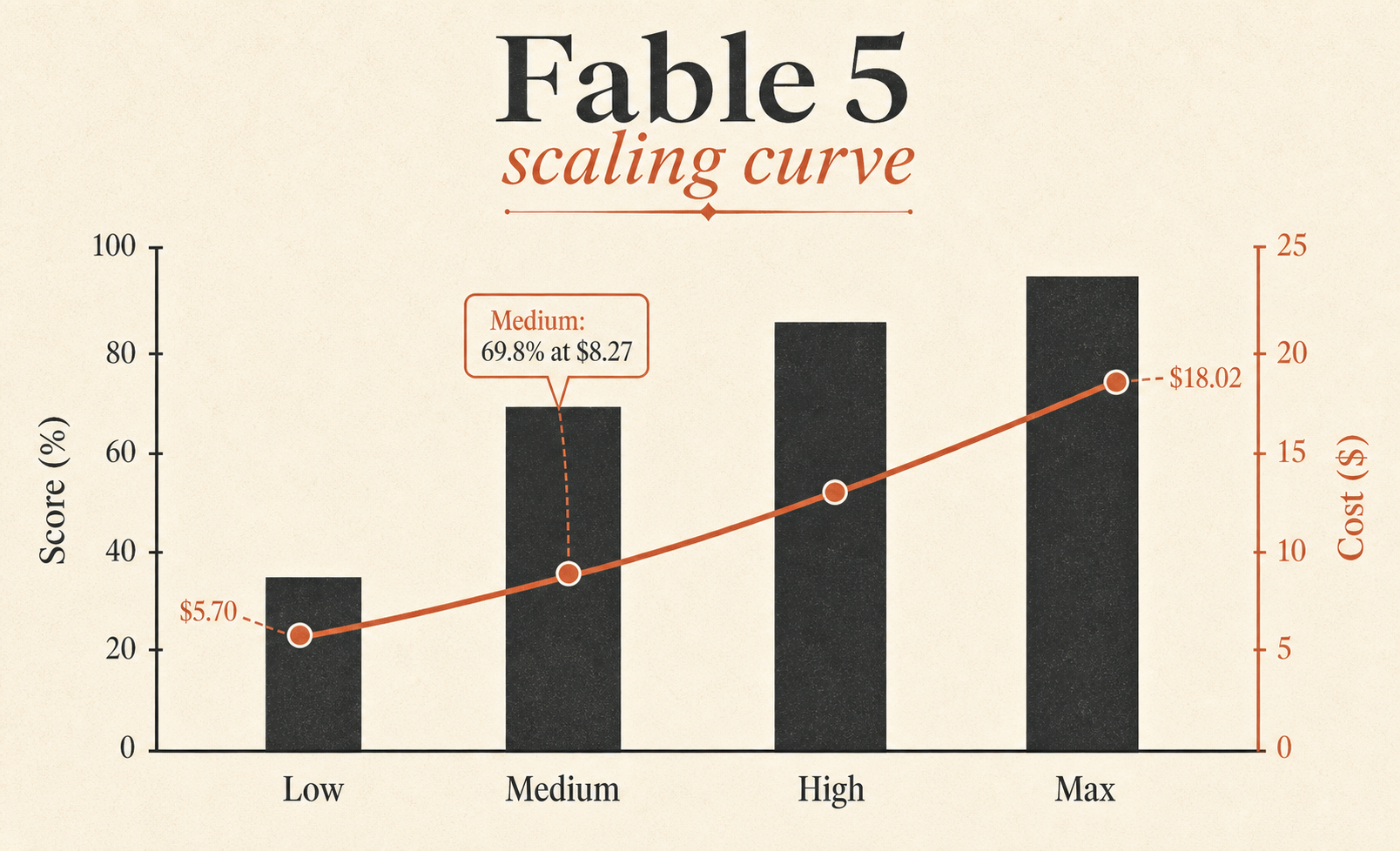
| Fable 5 Max | 72,9 % | $18.02 | 63.842 | 76 |
| Fable 5 Extra High | 72,0 % | $13.74 | 48.754 | 63 |
| Fable 5 High | 70,6 % | $10.81 | 37.173 | 54 |
| Fable 5 Medium | 69,8 % | $8.27 | 28.507 | 47 |
| Opus 4.7 Max | 64,8 % | $11.02 | 62.989 | 96 |
| GPT-5.5 Extra High | 64,3 % | $4.37 | 17.905 | 46 |
| Fable 5 Low | 64,2 % | $5.70 | 18.882 | 36 |
| Opus 4.8 Max | 63,8 % | $7.59 | 77.370 | 60 |
| Composer 2.5 | 63,2 % | $0.55 | 15.152 | 37 |
Cursor sagt, die durchschnittlichen Kosten pro Aufgabe würden berechnet, indem die veröffentlichten Preise pro Million Token jedes Modells — einschließlich Input-, Cache-Read-, Cache-Write- und Output-Token — auf die in jeder CursorBench-Aufgabe verwendeten Token angewendet und anschließend über alle Aufgaben gemittelt werden (Cursor). Das ist der richtige Rahmen. Agenten werden nicht nach Gefühl bepreist. Sie kosten danach, wie viel sie lesen, neu schreiben, erneut versuchen und erklären.
Der Gewinner ist Fable 5. Der Value-Gewinner nicht.
Fable 5 Max gewinnt beim reinen Score. Da muss man nichts schönreden.
Aber die Performance-pro-Dollar-Sicht ist brutal:
| Modell / Einstellung | Score | Kosten | Score-Punkte pro $1 |
|---|---|---|---|
| Fable 5 Max | 72,9 % | $18.02 | 4,0 |
| Fable 5 Medium | 69,8 % | $8.27 | 8,4 |
| GPT-5.5 Extra High | 64,3 % | $4.37 | 14,7 |
| Opus 4.8 Max | 63,8 % | $7.59 | 8,4 |
| Composer 2.5 | 63,2 % | $0.55 | 114,9 |
Die letzte Zeile erklärt, warum die Community-Debatte so hitzig ist. Composer 2.5 kommt absolut gesehen nicht an Fable 5 Max heran, liegt auf diesem Leaderboard aber nah bei GPT-5.5 Extra High und Opus 4.8 Max, während es im Vergleich nur Centbeträge kostet. Wenn man Hunderte Agent-Aufgaben pro Woche ausführt, zählt das mehr als eine Leaderboard-Krone.
Die Grenzkosten-Rechnung ist klarer:
Fable 5 Max vs GPT-5.5 Extra High:
+8.6 score points, +$13.65/task
≈ $1.59 per extra score pointGegen Opus 4.8 Max:
Fable 5 Max vs Opus 4.8 Max:
+9.1 score points, +$10.43/task
≈ $1.15 per extra score pointFür eine fiese Migration sind $10 bis $14 extra Rauschen. Wenn das Modell einen einzigen Fehlversuch spart, hat es sich bezahlt gemacht. Für ein Team, das Hintergrund-Agenten auf jedem Pull Request, Dependency-Bump, Lint-Fehler und Test-Fix laufen lässt, wird dieser Aufpreis zur Budgetpolitik.
Die am meisten unterschätzte Zeile ist Fable 5 Medium. Es erreicht 69,8 %, nur 3,1 Punkte hinter Fable 5 Max, bei $8.27 statt $18.02. Anders gesagt: Medium behält etwa 96 % von Max’ Benchmark-Score bei etwa 46 % von Max’ Aufgabenkosten. Wenn man ein Fable-Default will, ist das die Zeile, auf die man starren sollte.
In der Community-Debatte geht es eigentlich um Token-Verbrauch
Die Live-Threads sind nicht subtil. In einem Launch-Thread im Cursor-Subreddit lauteten die ersten Eindrücke eines Nutzers, Fable 5 zeige sehr detailliertes Reasoning und einen ambitionierten Plan, sei aber auch „sehr langsam“, mit Konnektivitätsmacken, die bei anziehender Nachfrage zu erwarten seien (Reddit r/cursor). Das passt zum Leaderboard: Fable 5 Max nutzt 63.842 Token pro Aufgabe und 76 Schritte pro Aufgabe. Es ist kein leichtgewichtiges Reflex-Modell.
In einem ClaudeAI-Thread zum CursorBench-Ergebnis kam der Widerspruch schnell: Ein Kommentator nannte es „keinen legitimen Benchmark“, während ein anderer sofort fragte, ob es dann „keinen Grund mehr gebe, opus zu nutzen, wenn fable medium günstiger ist“, und eine Antwort auf Composer 2.5 als „sehr günstig und gut“ verwies (Reddit r/ClaudeAI). Das ist die richtige Aufteilung: Benchmark-Vertrauen, Opus-Verdrängung und günstige, gut-genug Alternativen.
Ein ClaudeCode-Thread kam dem operativen Problem noch näher. Der ursprüngliche Post bemerkte, dass Fable 5 Low auf CursorBench smarter und günstiger als Opus 4.8 Max ist, und die Kommentatoren konzentrierten sich auf Kosten pro Aufgabe und Token-Effizienz. Ein Kommentar brachte es schlicht auf den Punkt: Für Indie-Entwickler und Freelancer seien Kosten pro Aufgabe und relativer Score die wichtigen Benchmarks, weil Produktivität bald am Token-Verbrauch gemessen werden könnte (Reddit r/ClaudeCode).
Diese Behauptung hält der Tabelle stand.
Fable 5 Low:
- 64,2 %
- $5.70
- 18.882 Token
Opus 4.8 Max:
- 63,8 %
- $7.59
- 77.370 Token
Auf CursorBench 3.1 liegt Fable 5 Low also knapp vor Opus 4.8 Max, kostet $1.89 weniger pro Aufgabe und nutzt etwa 76 % weniger Token. Das ist keine winzige Fußnote. Das ist eine Produktentscheidung.
Wenn du Opus 4.8 Max in Cursor noch als deine „ernsthafte Claude“-Einstellung nutzt, sagt der Benchmark: Teste Fable 5 Low und Medium sofort. Nicht, weil jedes Repo Cursors Aufgabenmix entsprechen wird. Sondern weil die Beweislast sich verschoben hat.
Anthropic’s Preise erklären den Schock
Anthropic brachte Claude Fable 5 und Claude Mythos 5 am 9. Juni 2026 heraus und beschrieb Mythos-Klasse-Modelle als eine Stufe über Opus. In Anthropics Launch-Post ist Fable 5 der allgemeine Release, während Mythos 5 dasselbe zugrunde liegende Modell ist, bei dem einige Schutzmechanismen für eingeschränkten Trusted-Access-Einsatz aufgehoben wurden (Anthropic).
Der API-Preis ist einfach und hoch: $10 pro Million Input-Token und $50 pro Million Output-Token für Fable 5 und Mythos 5 (Anthropic). Anthropic sagte außerdem, Fable 5 sei über die Claude API als claude-fable-5 verfügbar, und der Zugriff über Abonnementpläne sei nur vorübergehend bis zum 22. Juni enthalten, sofern die Kapazität keine Verlängerung erlaube (Anthropic).
Diese Preisgestaltung verändert, wie man über Agent-Prompts nachdenken sollte.
Bei günstigen Modellen ist schlampiger Kontext tolerierbar. Man fügt zu viel ein, bittet um eine zu breite Änderung, lässt den Agenten herumirren, und die Rechnung ist nervig, aber überlebbar. Bei Kosten der Fable 5 Max-Klasse wird schlechtes Harness-Design sichtbar. Jede unnötige Datei, jeder wiederholte Plan, jedes ausschweifende Tool-Ergebnis und jeder gescheiterte Patch-Versuch summiert sich.
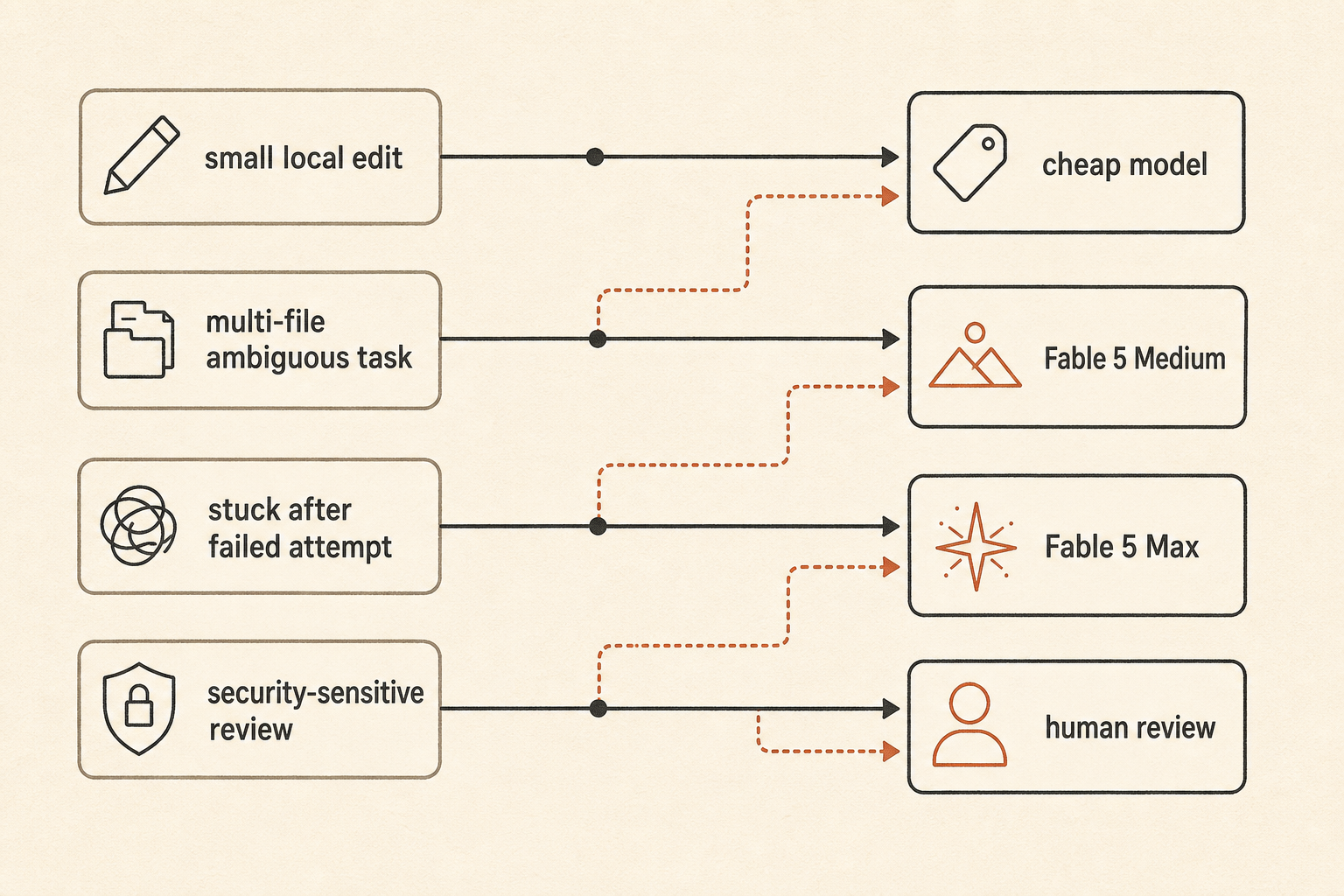
Eine praktische Routing-Policy sieht so aus:
default: fast/cheap model for local edits and small bugs
escalate: Fable 5 Medium for ambiguous multi-file work
reserve: Fable 5 Max for high-risk refactors, stuck tasks, and final review
fallback: human review when the agent starts exploring instead of editingDas ist weniger aufregend als „nimm das beste Modell“. Es ist aber auch der Weg, wie Teams vermeiden, morgens mit einer Token-Rechnung aufzuwachen, die wie ein Cloud-Incident aussieht.
Der Benchmark hat ein Verfügbarkeits-Sternchen
Es gibt eine unschöne aktuelle Wendung: Die Release-Woche von Fable 5 blieb nicht ruhig.
Am 12. Juni veröffentlichte Anthropic eine Stellungnahme, wonach die US-Regierung eine Exportkontroll-Anweisung erlassen habe, um den Zugriff auf Fable 5 und Mythos 5 für ausländische Staatsangehörige auszusetzen, einschließlich ausländischer Anthropic-Mitarbeiter; Anthropic sagte, der einzige unmittelbare Weg zur Einhaltung sei gewesen, die Modelle für alle Kunden zu deaktivieren (Anthropic). Das Unternehmen sagte, andere Claude-Modelle seien nicht betroffen.
Für die Interpretation des Benchmarks löscht das das CursorBench-Ergebnis nicht aus. Das Leaderboard bleibt ein nützlicher Hinweis auf die Modellfähigkeit innerhalb von Cursors Agent-Harness. Aber für Beschaffung und Workflow-Design ist Verfügbarkeit keine Fußnote. Wenn dein Team sich auf ein Modell standardisiert, das wegen Kapazität, Regulierung oder Safety-Gating verschwinden kann, brauchst du einen Fallback-Pfad.
Das ist ein weiterer Grund, Fable 5 Max nicht in jede Aufgabe fest zu verdrahten. Das beste Engineering-Setup ist modell-portabel:
- Prompts, die nicht von den Eigenheiten eines einzelnen Providers abhängen
- Aufgabengrenzen klein genug, damit ein zweites Modell erneut versuchen kann
- Evals auf dem eigenen Repo, nicht nur öffentliche Leaderboards
- Kostenlogs pro Aufgabe, nicht nur Monatsrechnungen
- ein menschlicher Eskalationspunkt für gefährliche Diffs
Benchmarks sagen dir, wo du anfangen sollst. Dein Repo sagt dir, was du shippen sollst.
Meine Einschätzung: Nutze Fable 5 wie einen Senior Reviewer, nicht wie Default-Autocomplete
Fable 5 Max verdient den Spitzenplatz auf CursorBench 3.1. Ein Score von 72,9 % auf mehrdeutigen Multi-File-Cursor-Aufgaben ist genau die Art Signal, die Entwickler interessieren sollte. Es schlägt GPT-5.5 Extra High und Opus 4.8 Max deutlich genug, dass das Ergebnis Modellwahl-Gewohnheiten verändern sollte.
Aber die falsche Lektion lautet: „Immer Max nutzen.“
Die richtige Lektion ist enger: Fable 5 lohnt sich, wenn Mehrdeutigkeit der Engpass ist. Architektur-Migrationen, dateiübergreifende Bugs, fehlschlagende Testsuiten mit unklarer Zuständigkeit, subtile Review-Durchgänge und „ich brauche, dass der Agent einen Plan bildet, bevor er Code anfasst“ passen gut. Routinemäßige CRUD-Änderungen, offensichtliche Test-Fixes, Formatting-Aufräumen und One-File-Refactorings nicht.
Wenn du aus diesem Leaderboard den praktischen Default ableiten willst, fang hier an:
- Composer 2.5 für günstige, gut-genug Routinearbeit mit Agenten.
- GPT-5.5 Extra High wenn du einen starken Score zu viel niedrigeren Kosten als Fable Max willst.
- Fable 5 Medium als Kandidat für den ernsthaften Daily Driver.
- Fable 5 Max für Eskalation, nicht als Hintergrundrauschen.
- Opus 4.8 Max erneut testen in deinem Workflow; CursorBench macht es schwer, es als Default zu rechtfertigen.
Die Fable 5-Schlagzeile ist 72,9 %. Die Engineering-Lektion ist Routing.
Die Teams, die mit diesen Modellen gewinnen, werden nicht die sein, die immer das größte Modell wählen. Es werden die sein, die genau wissen, wann das größte Modell billig ist.
Leser, die Claude Fable 5 selbst ausprobieren möchten, können es über OneHop nutzen: Claude Fable 5 on OneHop, ein Drop-in-Endpoint mit Preisen rund 30 % unter Listenpreis. Neue Accounts erhalten $10 free, keine Karte erforderlich.
Weiterlesen: Getting started with Claude Fable 5.

