Claude Fable 5 no se coló en la tabla de clasificación. Aterrizó directamente en la cima.
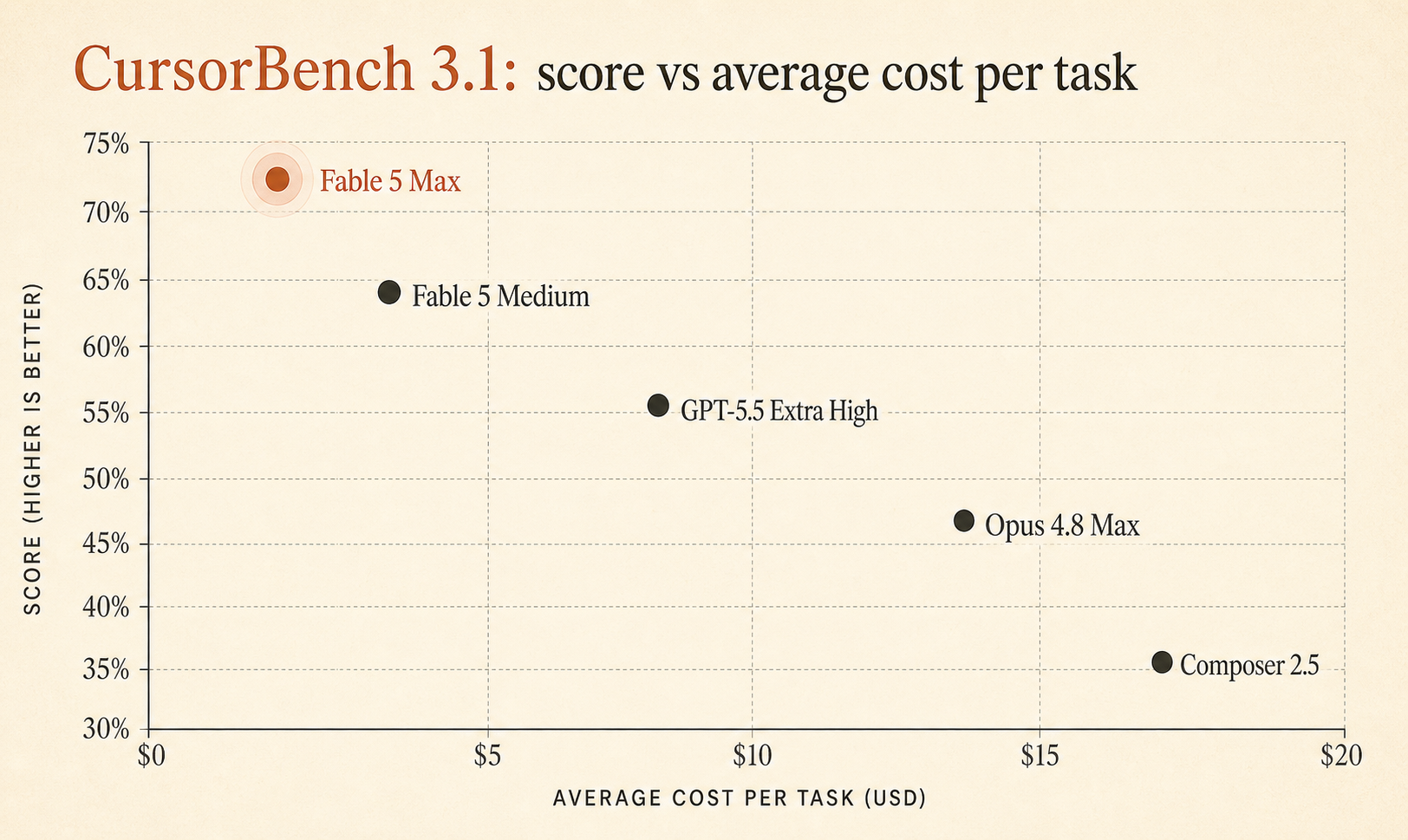
La página en vivo de CursorBench 3.1 de Cursor ahora sitúa a Fable 5 Max en 72,9% con un coste medio de $18.02 por tarea, por delante de GPT-5.5 Extra High con 64,3% / $4.37 y Opus 4.8 Max con 63,8% / $7.59 (Cursor). Es una brecha de calidad grande en un benchmark construido alrededor de sesiones reales de Cursor, no de juguetitos algorítmicos.
También es caro. Dolorosamente caro si tienes agentes corriendo todo el día.
Por eso el debate actual sobre Claude Code y Cursor no es “¿Fable 5 es bueno?”. La tabla ya responde eso. La mejor pregunta es: ¿cuándo una ventaja de 8 a 9 puntos justifica una factura de 2x a 4x?
Mi respuesta: Fable 5 es el modelo al que escalas, no el que dejas encendido a ciegas para cada edición. Lo interesante no es solo que Fable 5 Max gane. Es que Fable 5 Medium y Low quizá sean la historia más práctica.
Qué mide realmente CursorBench 3.1
Cursor describe CursorBench 3.1 como una evaluación de “tareas ambiguas y multiarchivo de sesiones reales de Cursor”, donde una puntuación más alta es mejor (Cursor). Esa frase importa. La mayor parte de la frustración de los desarrolladores con los agentes de programación no viene de fallos tipo LeetCode en un solo archivo. Viene del barro:
- entender la estructura de un repo
- decidir qué archivos importan
- planificar una edición que cruza límites
- encontrar bugs sin que te lleven demasiado de la mano
- revisar código sin alucinar un problema falso
- mantener vivo el contexto el tiempo suficiente para terminar
CursorBench 3.1 añadió problemas centrados en comprensión de codebases, búsqueda de bugs, planificación y revisión de código, y mejoró los criterios de evaluación para algunas tareas de edición (Cursor). El análisis más largo de Cursor sobre el benchmark dice que la suite está pensada para separar modelos frontier en un momento en que los benchmarks públicos están cada vez más saturados, y que Cursor sigue señales de producto online junto con notas offline (Cursor blog).
Eso no lo hace perfecto. Sigue siendo la evaluación de un proveedor, ejecutada dentro del arnés de agente de un producto, con una distribución concreta de tareas. Cursor también advierte que diferencias pequeñas de puntuación quizá no sean estadísticamente significativas (Cursor). Así que no, no deberías tratar una brecha de 0,6 puntos como palabra sagrada.
Pero Fable 5 Max no gana por 0,6 puntos. Está por delante de GPT-5.5 Extra High por 8,6 puntos y de Opus 4.8 Max por 9,1 puntos. Eso es lo bastante grande como para tomárselo en serio.
Aquí está el recorte compacto de la tabla que importa para elegir agentes de programación en el día a día:
| Modelo / ajuste | Puntuación en CursorBench 3.1 | Coste medio / tarea | Tokens / tarea | Pasos / tarea |
|---|---|---|---|---|
| Fable 5 Max | 72.9% | $18.02 | 63,842 | 76 |
| Fable 5 Extra High | 72.0% | $13.74 | 48,754 | 63 |
| Fable 5 High | 70.6% | $10.81 | 37,173 | 54 |
| Fable 5 Medium | 69.8% | $8.27 | 28,507 | 47 |
| Opus 4.7 Max | 64.8% | $11.02 | 62,989 | 96 |
| GPT-5.5 Extra High | 64.3% | $4.37 | 17,905 | 46 |
| Fable 5 Low | 64.2% | $5.70 | 18,882 | 36 |
| Opus 4.8 Max | 63.8% | $7.59 | 77,370 | 60 |
| Composer 2.5 | 63.2% | $0.55 | 15,152 | 37 |
Cursor dice que el coste medio por tarea se calcula aplicando el precio publicado por millón de tokens de cada modelo, incluyendo tokens de entrada, lectura de caché, escritura de caché y salida, a los tokens usados en cada tarea de CursorBench, y luego promediando entre tareas (Cursor). Ese es el encuadre correcto. Los agentes no se tarifican por sensaciones. Se tarifican por cuánto leen, reescriben, reintentan y explican.
El ganador es Fable 5. El ganador en valor no.
Fable 5 Max gana en puntuación bruta. No hace falta maquillarlo.
Pero la lectura de rendimiento por dólar es brutal:
| Modelo / ajuste | Puntuación | Coste | Puntos de puntuación por $1 |
|---|---|---|---|
| Fable 5 Max | 72.9% | $18.02 | 4.0 |
| Fable 5 Medium | 69.8% | $8.27 | 8.4 |
| GPT-5.5 Extra High | 64.3% | $4.37 | 14.7 |
| Opus 4.8 Max | 63.8% | $7.59 | 8.4 |
| Composer 2.5 | 63.2% | $0.55 | 114.9 |
Esa última fila explica por qué la discusión en la comunidad está tan encendida. Composer 2.5 no está cerca de Fable 5 Max en calidad absoluta, pero sí está cerca de GPT-5.5 Extra High y Opus 4.8 Max en esta tabla, costando calderilla en comparación. Si ejecutas cientos de tareas de agente por semana, eso importa más que una corona en el leaderboard.
La cuenta marginal es más clara:
Fable 5 Max vs GPT-5.5 Extra High:
+8.6 score points, +$13.65/task
≈ $1.59 per extra score pointFrente a Opus 4.8 Max:
Fable 5 Max vs Opus 4.8 Max:
+9.1 score points, +$10.43/task
≈ $1.15 per extra score pointPara una migración retorcida, $10 a $14 extra es ruido. Si el modelo evita un intento fallido, ya se pagó solo. Para un equipo que ejecuta agentes en segundo plano en cada pull request, actualización de dependencias, fallo de lint y reparación de tests, esa prima se convierte en política presupuestaria.
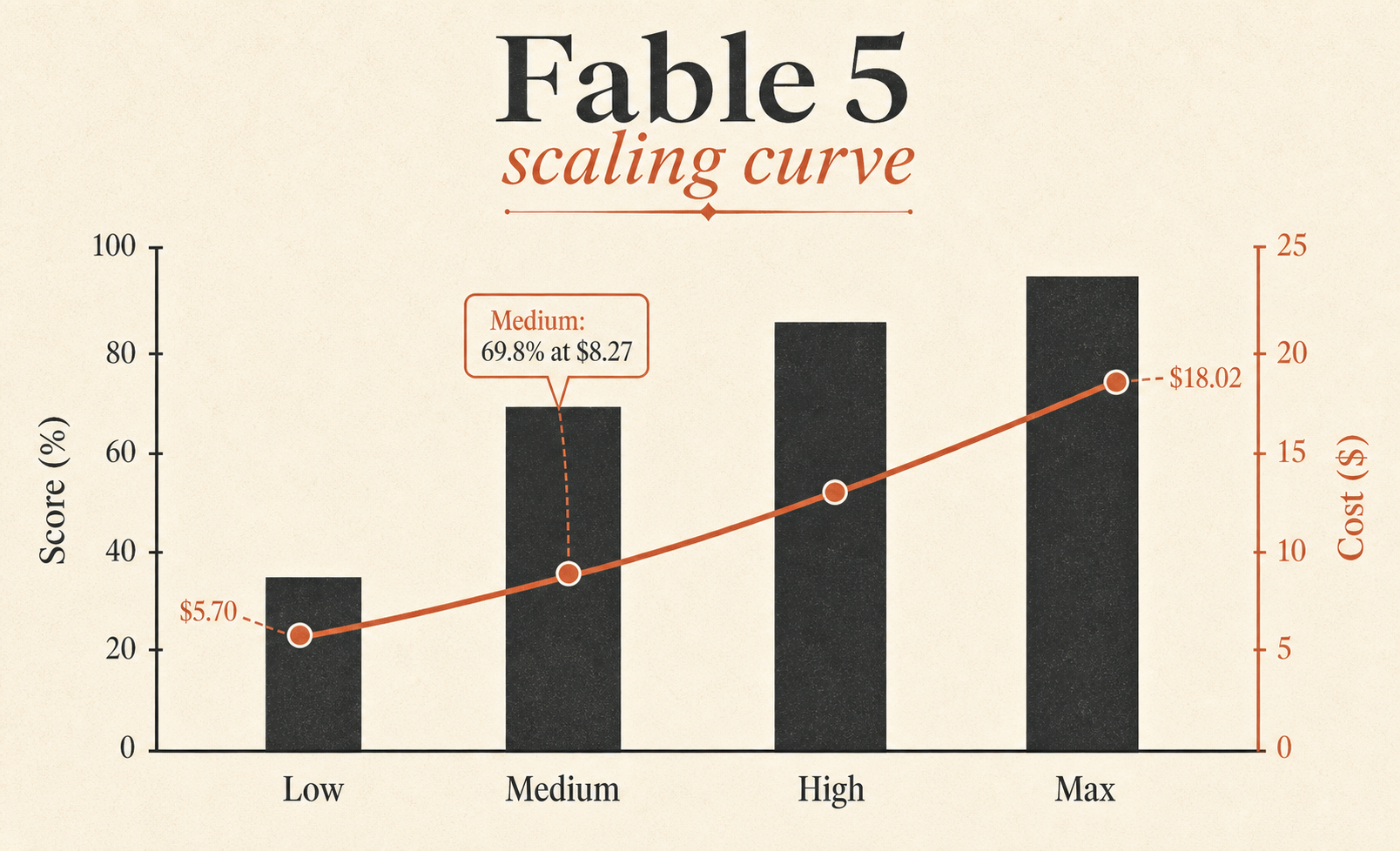
La fila más infravalorada es Fable 5 Medium. Saca 69,8%, solo 3,1 puntos por detrás de Fable 5 Max, a $8.27 en lugar de $18.02. Dicho de otra forma, Medium conserva alrededor del 96% de la puntuación de Max en el benchmark por aproximadamente el 46% del coste por tarea de Max. Si quieres un Fable por defecto, esa es la fila que hay que mirar fijamente.
El debate de la comunidad va realmente sobre quemar tokens
Los hilos en vivo no son sutiles. En un hilo de lanzamiento del subreddit de Cursor, las primeras impresiones de un usuario fueron que Fable 5 mostraba un razonamiento muy detallado y un plan ambicioso, pero que también era “muy lento”, con rarezas de conectividad esperables mientras subía la demanda (Reddit r/cursor). Encaja con la tabla: Fable 5 Max usa 63.842 tokens por tarea y 76 pasos por tarea. No es un modelo reflejo y ligero.
En un hilo de ClaudeAI sobre el resultado de CursorBench, la reacción crítica llegó rápido: un comentarista lo llamó “un benchmark no legítimo”, mientras otro preguntó inmediatamente si entonces “no había razón para usar opus si fable medium es más barato”, y una respuesta apuntó a que Composer 2.5 era “muy barato y bueno” (Reddit r/ClaudeAI). Esa es la división correcta: confianza en el benchmark, desplazamiento de Opus y alternativas baratas suficientemente buenas.
Un hilo de ClaudeCode se acercó aún más al problema operativo. El post original señalaba que Fable 5 Low es más inteligente y más barato que Opus 4.8 Max en CursorBench, y los comentaristas se centraron en el coste por tarea y la eficiencia de tokens. Un comentario lo dijo sin rodeos: para desarrolladores independientes y freelancers, el coste por tarea y la puntuación relativa son los benchmarks importantes, porque pronto quizá se mida la productividad por consumo de tokens (Reddit r/ClaudeCode).
Esa afirmación cuadra con la tabla.
Fable 5 Low:
- 64.2%
- $5.70
- 18,882 tokens
Opus 4.8 Max:
- 63.8%
- $7.59
- 77,370 tokens
Así que en CursorBench 3.1, Fable 5 Low queda ligeramente por encima de Opus 4.8 Max, cuesta $1.89 menos por tarea y usa alrededor de 76% menos tokens. No es una nota al pie diminuta. Es una decisión de producto.
Si todavía usas Opus 4.8 Max como tu ajuste de “Claude serio” dentro de Cursor, el benchmark dice que deberías probar Fable 5 Low y Medium inmediatamente. No porque todos los repos vayan a coincidir con la mezcla de tareas de Cursor. Sino porque la carga de la prueba ha cambiado de sitio.
El precio de Anthropic explica el susto
Anthropic lanzó Claude Fable 5 y Claude Mythos 5 el 9 de junio de 2026, describiendo los modelos de clase Mythos como un nivel por encima de Opus. En el post de lanzamiento de Anthropic, Fable 5 es la versión general, mientras que Mythos 5 es el mismo modelo subyacente con algunas salvaguardas levantadas para uso restringido con acceso de confianza (Anthropic).
El precio de la API es simple y alto: $10 por millón de tokens de entrada y $50 por millón de tokens de salida tanto para Fable 5 como para Mythos 5 (Anthropic). Anthropic también dijo que Fable 5 estaba disponible a través de la Claude API como claude-fable-5, y que el acceso mediante planes de suscripción solo estaba incluido temporalmente hasta el 22 de junio salvo que la capacidad permitiera una extensión (Anthropic).
Ese precio cambia cómo deberías pensar los prompts para agentes.
Con modelos baratos, el contexto descuidado se tolera. Pegas demasiado, pides un cambio demasiado amplio, dejas que el agente deambule, y la factura molesta pero se sobrevive. Con costes de clase Fable 5 Max, el mal diseño del arnés se vuelve visible. Cada archivo innecesario, plan repetido, resultado de herramienta verboso e intento fallido de parche se acumula.
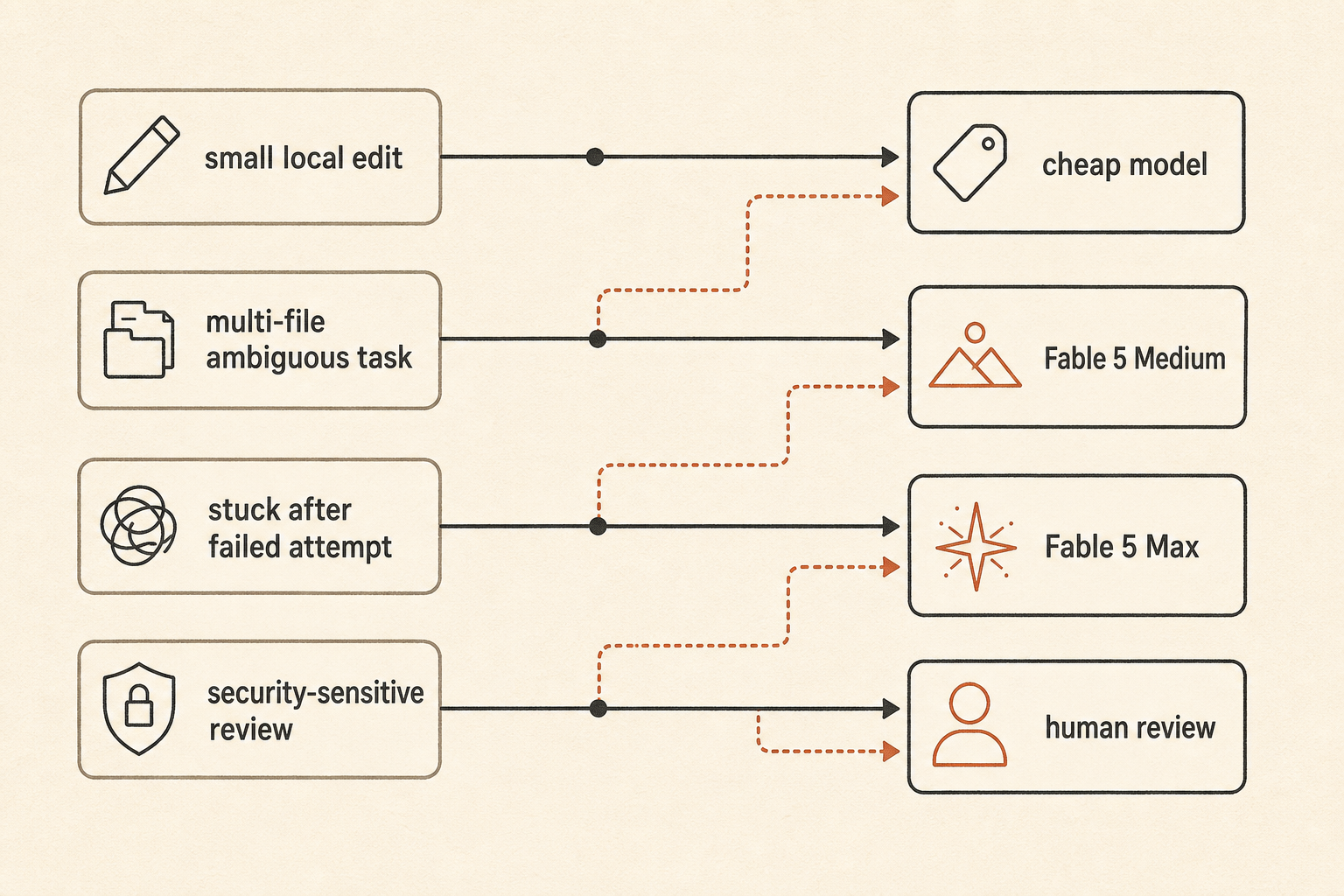
Una política práctica de enrutamiento se ve así:
default: fast/cheap model for local edits and small bugs
escalate: Fable 5 Medium for ambiguous multi-file work
reserve: Fable 5 Max for high-risk refactors, stuck tasks, and final review
fallback: human review when the agent starts exploring instead of editingEs menos emocionante que “usa el mejor modelo”. También es la forma en que los equipos evitan despertarse con una factura de tokens que parece un incidente de cloud.
El benchmark tiene un asterisco de disponibilidad
Hay una arruga de actualidad algo incómoda: la semana de lanzamiento de Fable 5 no se quedó tranquila.
El 12 de junio, Anthropic publicó un comunicado diciendo que el gobierno de EE. UU. había emitido una directiva de control de exportaciones para suspender el acceso a Fable 5 y Mythos 5 por parte de ciudadanos extranjeros, incluidos empleados extranjeros de Anthropic; Anthropic dijo que la única forma inmediata de cumplir era desactivar los modelos para todos los clientes (Anthropic). La empresa dijo que los demás modelos Claude no se veían afectados.
Para interpretar el benchmark, esto no borra el resultado de CursorBench. La tabla sigue siendo evidencia útil sobre la capacidad del modelo bajo el arnés de agente de Cursor. Pero para compras y diseño de flujos de trabajo, la disponibilidad no es una nota al pie. Si tu equipo se estandariza en un modelo que puede desaparecer por capacidad, política o puertas de seguridad, necesitas una ruta de respaldo.
Esa es otra razón para no cablear Fable 5 Max en cada tarea. La mejor configuración de ingeniería es portable entre modelos:
- prompts que no dependan de las rarezas de un proveedor
- límites de tarea lo bastante pequeños como para que un segundo modelo pueda reintentar
- evaluaciones en tu propio repo, no solo leaderboards públicos
- logs de coste por tarea, no solo facturas mensuales
- un punto de escalado humano para diffs peligrosos
Los benchmarks te dicen por dónde empezar. Tu repo te dice qué enviar.
Mi lectura: usa Fable 5 como un reviewer senior, no como autocomplete por defecto
Fable 5 Max merece el primer puesto en CursorBench 3.1. Una puntuación de 72,9% en tareas ambiguas y multiarchivo de Cursor es exactamente el tipo de señal que debería importar a los desarrolladores. Gana a GPT-5.5 Extra High y Opus 4.8 Max por margen suficiente como para cambiar hábitos de selección de modelo.
Pero la lección equivocada es “usa siempre Max”.
La lección correcta es más estrecha: merece la pena pagar por Fable 5 cuando la ambigüedad es el cuello de botella. Migraciones de arquitectura, bugs entre archivos, suites de tests fallando sin dueño claro, pasadas de revisión sutiles y “necesito que el agente forme un plan antes de tocar código” son buenos casos. Ediciones CRUD rutinarias, arreglos de tests obvios, limpieza de formato y refactors de un archivo no lo son.
Si quieres el default práctico a partir de esta tabla, empieza por esto:
- Composer 2.5 para trabajo rutinario de agente barato y suficientemente bueno.
- GPT-5.5 Extra High cuando quieres una puntuación fuerte a mucho menor coste que Fable Max.
- Fable 5 Medium como candidato serio a caballo de batalla diario.
- Fable 5 Max para escalar, no como ruido de fondo.
- Vuelve a probar Opus 4.8 Max en tu flujo; CursorBench hace difícil justificarlo como default.
El titular de Fable 5 es 72,9%. La lección de ingeniería es el enrutamiento.
Los equipos que ganen con estos modelos no serán los que siempre elijan el modelo más grande. Serán los que sepan exactamente cuándo el modelo más grande sale barato.
Los lectores que quieran probar Claude Fable 5 pueden usarlo a través de OneHop: Claude Fable 5 en OneHop, un endpoint drop-in con un precio alrededor de un 30% por debajo de la tarifa oficial. Las cuentas nuevas reciben $10 gratis, sin tarjeta.
Lectura adicional: Primeros pasos con Claude Fable 5.

