Claude Fable 5 ne s’est pas glissé discrètement dans le classement. Il a atterri tout en haut.
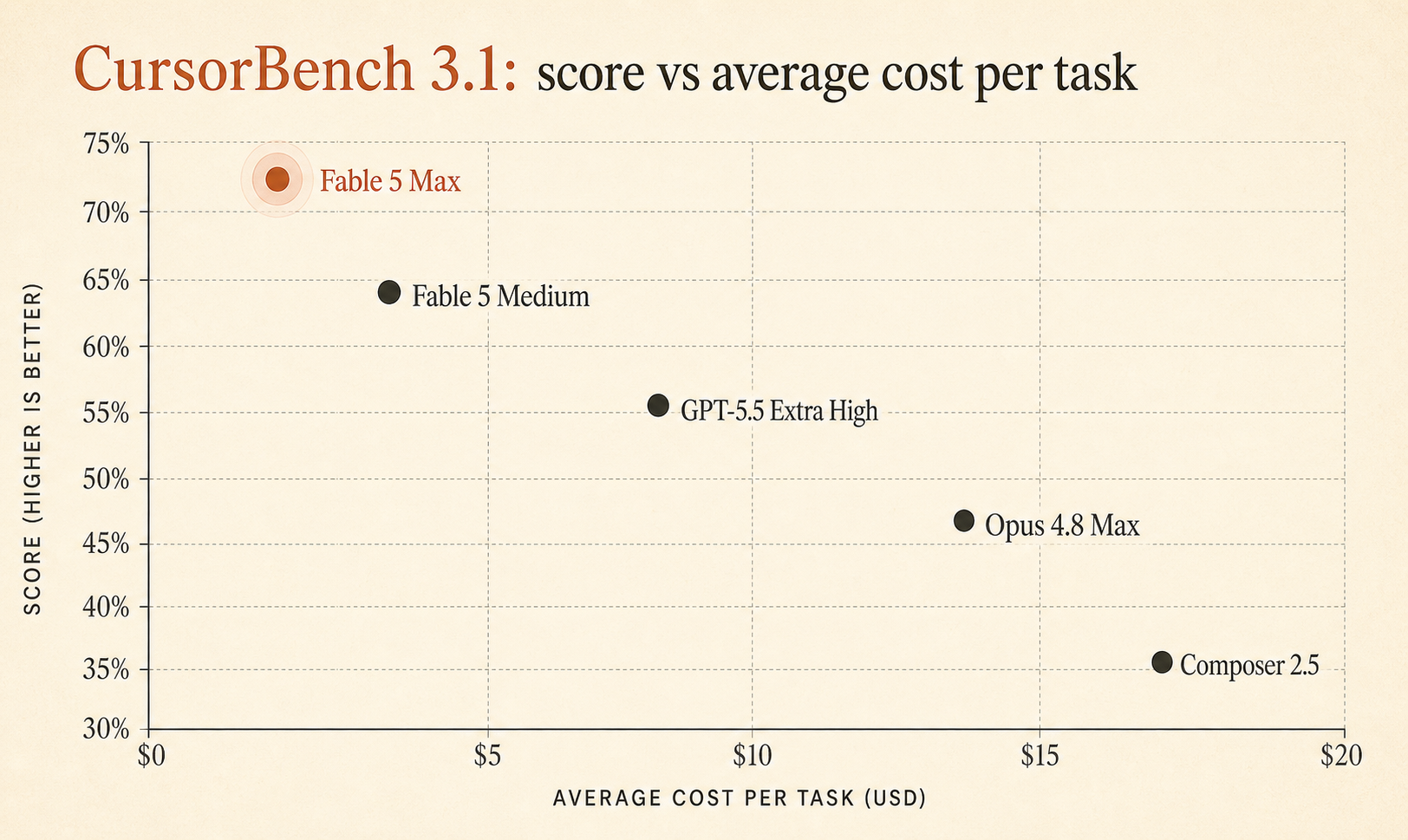
La page live CursorBench 3.1 de Cursor place désormais Fable 5 Max à 72,9 % avec un coût moyen de 18,02 $ par tâche, devant GPT-5.5 Extra High à 64,3 % / 4,37 $ et Opus 4.8 Max à 63,8 % / 7,59 $ (Cursor). C’est un gros écart de qualité sur un benchmark construit autour de vraies sessions Cursor, pas de petits puzzles d’algorithmes jouets.
C’est aussi cher. Douloureusement cher si vous faites tourner des agents toute la journée.
C’est pour ça que le débat actuel autour de Claude Code et Cursor n’est pas « Fable 5 est-il bon ? ». Le classement répond déjà à ça. La vraie question est : quand est-ce qu’une avance de 8 à 9 points justifie une facture 2 à 4 fois plus élevée ?
Ma réponse : Fable 5 est le modèle vers lequel on escalade, pas celui qu’on laisse tourner aveuglément pour chaque modification. Le résultat intéressant n’est pas seulement que Fable 5 Max gagne. C’est que Fable 5 Medium et Low pourraient bien être l’histoire la plus utile en pratique.
Ce que CursorBench 3.1 mesure vraiment
Cursor décrit CursorBench 3.1 comme une évaluation de « tâches ambiguës, multifichiers, issues de vraies sessions Cursor », où un score plus élevé est meilleur (Cursor). Cette phrase compte. La plupart des frustrations des développeurs avec les agents de code ne viennent pas d’échecs façon LeetCode sur un seul fichier. Elles viennent du bazar réel :
- comprendre la structure d’un repo
- décider quels fichiers comptent
- planifier une modification qui traverse plusieurs frontières
- trouver des bugs sans être sur-guidé
- relire du code sans halluciner un faux problème
- garder assez de contexte pour aller au bout
CursorBench 3.1 a ajouté des problèmes centrés sur la compréhension de codebase, la recherche de bugs, la planification et la revue de code, et a amélioré les critères de notation pour certaines tâches de modification (Cursor). Le billet plus long de Cursor sur le benchmark explique que la suite vise à départager les modèles de pointe à un moment où les benchmarks publics sont de plus en plus saturés, et que Cursor suit des signaux produit en ligne en plus des notes hors ligne (Cursor blog).
Ça ne le rend pas parfait. Cela reste l’évaluation d’un seul fournisseur, exécutée dans le harnais d’agent d’un seul produit, avec une seule distribution de tâches. Cursor prévient aussi que de petits écarts de score peuvent ne pas être statistiquement significatifs (Cursor). Donc non, il ne faut pas traiter un écart de 0,6 point comme parole d’évangile.
Mais Fable 5 Max ne gagne pas de 0,6 point. Il devance GPT-5.5 Extra High de 8,6 points et Opus 4.8 Max de 9,1 points. C’est assez large pour être pris au sérieux.
Voici l’extrait compact du classement qui compte pour les choix quotidiens d’agents de code :
| Modèle / réglage | Score CursorBench 3.1 | Coût moyen / tâche | Tokens / tâche | Étapes / tâche |
|---|---|---|---|---|
| Fable 5 Max | 72,9 % | 18,02 $ | 63 842 | 76 |
| Fable 5 Extra High | 72,0 % | 13,74 $ | 48 754 | 63 |
| Fable 5 High | 70,6 % | 10,81 $ | 37 173 | 54 |
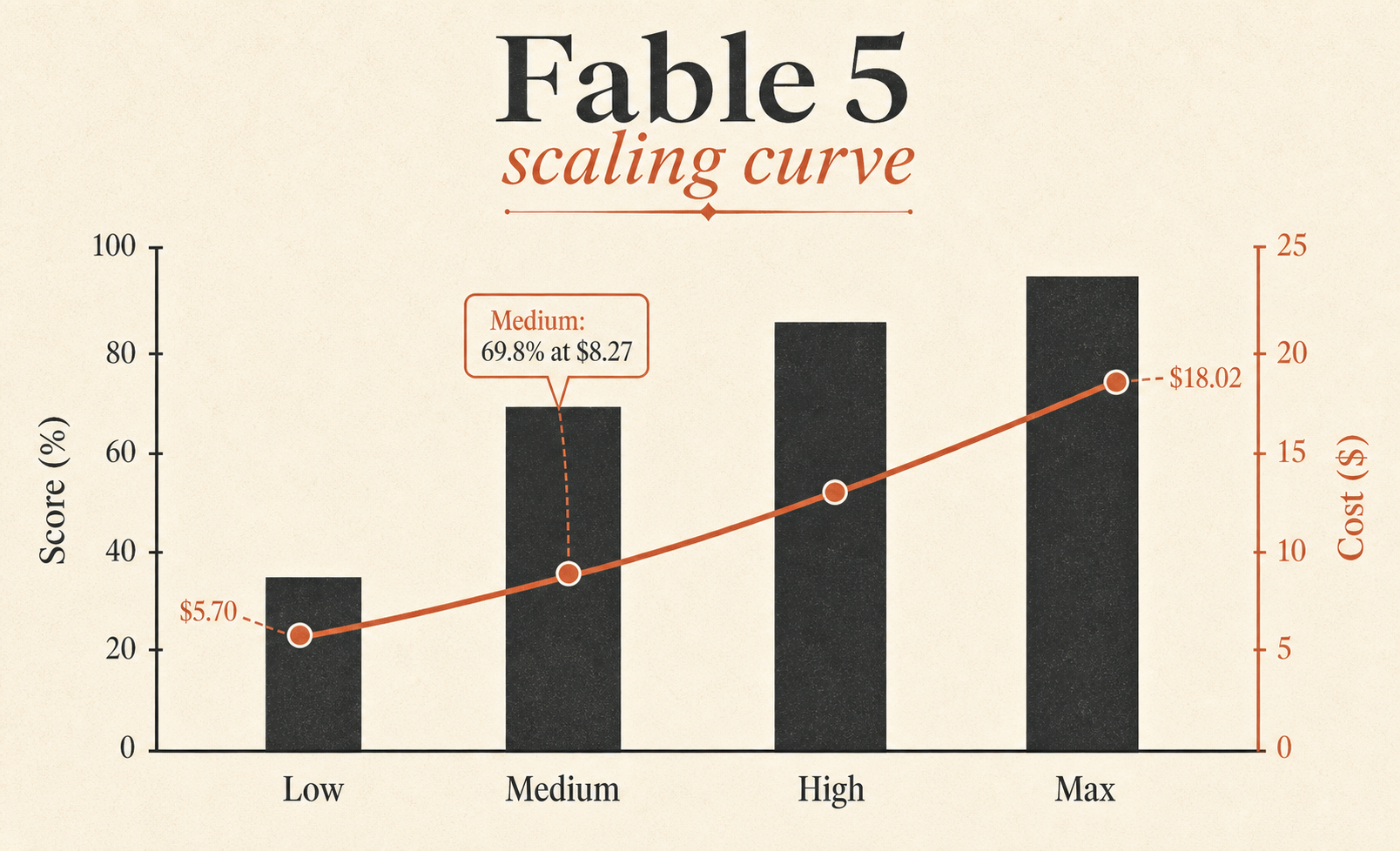
| Fable 5 Medium | 69,8 % | 8,27 $ | 28 507 | 47 |
| Opus 4.7 Max | 64,8 % | 11,02 $ | 62 989 | 96 |
| GPT-5.5 Extra High | 64,3 % | 4,37 $ | 17 905 | 46 |
| Fable 5 Low | 64,2 % | 5,70 $ | 18 882 | 36 |
| Opus 4.8 Max | 63,8 % | 7,59 $ | 77 370 | 60 |
| Composer 2.5 | 63,2 % | 0,55 $ | 15 152 | 37 |
Cursor indique que le coût moyen par tâche est calculé en appliquant les tarifs publiés par million de tokens de chaque modèle, incluant les tokens d’entrée, de lecture du cache, d’écriture du cache et de sortie, aux tokens utilisés sur chaque tâche CursorBench, puis en faisant la moyenne sur les tâches (Cursor). C’est le bon cadrage. Les agents ne se tarifent pas au feeling. Ils se tarifent selon ce qu’ils lisent, réécrivent, retentent et expliquent.
Le gagnant, c’est Fable 5. Le gagnant côté valeur, non.
Fable 5 Max gagne au score brut. Pas besoin de tourner autour.
Mais la lecture performance par dollar est brutale :
| Modèle / réglage | Score | Coût | Points de score par 1 $ |
|---|---|---|---|
| Fable 5 Max | 72,9 % | 18,02 $ | 4,0 |
| Fable 5 Medium | 69,8 % | 8,27 $ | 8,4 |
| GPT-5.5 Extra High | 64,3 % | 4,37 $ | 14,7 |
| Opus 4.8 Max | 63,8 % | 7,59 $ | 8,4 |
| Composer 2.5 | 63,2 % | 0,55 $ | 114,9 |
Cette dernière ligne explique pourquoi le débat dans la communauté est aussi tendu. Composer 2.5 n’est pas proche de Fable 5 Max en qualité absolue, mais il est proche de GPT-5.5 Extra High et d’Opus 4.8 Max sur ce classement, tout en coûtant des centimes en comparaison. Si vous lancez des centaines de tâches d’agent par semaine, ça compte plus qu’une couronne de classement.
Le calcul marginal est plus clair :
Fable 5 Max vs GPT-5.5 Extra High:
+8.6 score points, +$13.65/task
≈ $1.59 per extra score pointFace à Opus 4.8 Max :
Fable 5 Max vs Opus 4.8 Max:
+9.1 score points, +$10.43/task
≈ $1.15 per extra score pointPour une migration bien tordue, 10 à 14 $ de plus, c’est du bruit. Si le modèle évite une seule tentative ratée, il est rentabilisé. Pour une équipe qui lance des agents en arrière-plan sur chaque pull request, mise à jour de dépendance, échec de lint et réparation de test, cette prime devient une politique budgétaire.
La ligne la plus sous-estimée est Fable 5 Medium. Il obtient 69,8 %, seulement 3,1 points derrière Fable 5 Max, à 8,27 $ au lieu de 18,02 $. Autrement dit, Medium conserve environ 96 % du score benchmark de Max pour environ 46 % du coût par tâche de Max. Si vous voulez un Fable par défaut, c’est cette ligne qu’il faut fixer.
Le vrai débat de la communauté porte sur la consommation de tokens
Les discussions live ne font pas dans la subtilité. Dans un fil de lancement du subreddit Cursor, les premières impressions d’un utilisateur étaient que Fable 5 montrait un raisonnement très détaillé et un plan ambitieux, mais qu’il était aussi « très lent », avec des bizarreries de connexion attendues vu le pic de demande (Reddit r/cursor). Ça colle au classement : Fable 5 Max utilise 63 842 tokens par tâche et 76 étapes par tâche. Ce n’est pas un modèle réflexe léger.
Dans un fil ClaudeAI sur le résultat CursorBench, les critiques sont arrivées vite : un commentaire l’a qualifié de « benchmark non légitime », tandis qu’un autre a immédiatement demandé s’il n’y avait « plus aucune raison d’utiliser opus si fable medium est moins cher », et une réponse pointait Composer 2.5 comme « très bon et très peu cher » (Reddit r/ClaudeAI). C’est exactement la bonne fracture : confiance dans le benchmark, remplacement d’Opus, et alternatives pas chères mais suffisantes.
Un fil ClaudeCode s’est encore plus rapproché du vrai sujet opérationnel. Le post d’origine remarquait que Fable 5 Low est plus intelligent et moins cher qu’Opus 4.8 Max sur CursorBench, et les commentaires se sont concentrés sur le coût par tâche et l’efficacité en tokens. Un commentaire le disait franchement : pour les développeurs indépendants et freelances, le coût par tâche et le score relatif sont les benchmarks importants, parce que la productivité pourrait bientôt être jugée à la consommation de tokens (Reddit r/ClaudeCode).
Cette affirmation tient face au tableau.
Fable 5 Low :
- 64,2 %
- 5,70 $
- 18 882 tokens
Opus 4.8 Max :
- 63,8 %
- 7,59 $
- 77 370 tokens
Donc sur CursorBench 3.1, Fable 5 Low est légèrement devant Opus 4.8 Max, coûte 1,89 $ de moins par tâche, et utilise environ 76 % de tokens en moins. Ce n’est pas une minuscule note de bas de page. C’est une décision produit.
Si vous utilisez encore Opus 4.8 Max comme votre réglage « Claude sérieux » dans Cursor, le benchmark dit que vous devriez tester Fable 5 Low et Medium immédiatement. Pas parce que chaque repo correspondra à la distribution de tâches de Cursor. Parce que la charge de la preuve a changé de camp.
Les tarifs d’Anthropic expliquent le choc
Anthropic a lancé Claude Fable 5 et Claude Mythos 5 le 9 juin 2026, en décrivant les modèles de classe Mythos comme un niveau au-dessus d’Opus. Dans le billet de lancement d’Anthropic, Fable 5 est la version générale, tandis que Mythos 5 est le même modèle sous-jacent avec certaines protections levées pour un usage restreint en accès de confiance (Anthropic).
Le prix de l’API est simple et élevé : 10 $ par million de tokens d’entrée et 50 $ par million de tokens de sortie pour Fable 5 comme pour Mythos 5 (Anthropic). Anthropic a aussi indiqué que Fable 5 était disponible via l’API Claude sous claude-fable-5, et que l’accès via les abonnements n’était inclus que temporairement jusqu’au 22 juin, sauf prolongation permise par la capacité (Anthropic).
Ce prix change la façon dont il faut penser les prompts d’agent.
Avec des modèles bon marché, un contexte brouillon reste tolérable. Vous collez trop de choses, demandez une modification trop large, laissez l’agent se balader, et la facture est agaçante mais survivable. Avec des coûts de classe Fable 5 Max, une mauvaise conception de harnais devient visible. Chaque fichier inutile, plan répété, résultat d’outil verbeux et tentative de patch ratée s’additionne.
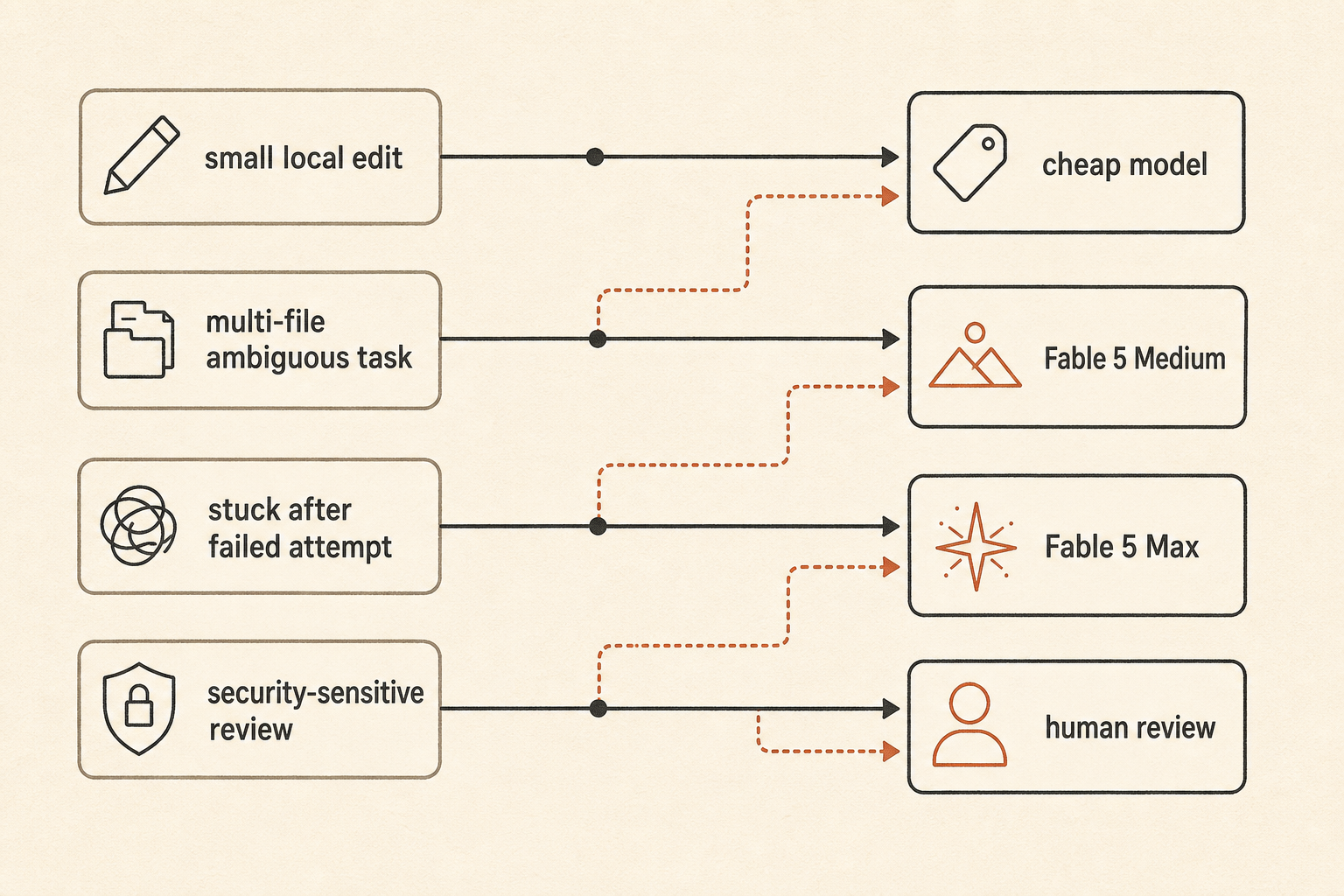
Une politique de routage pratique ressemble à ça :
default: fast/cheap model for local edits and small bugs
escalate: Fable 5 Medium for ambiguous multi-file work
reserve: Fable 5 Max for high-risk refactors, stuck tasks, and final review
fallback: human review when the agent starts exploring instead of editingC’est moins excitant que « utilisez le meilleur modèle ». C’est aussi comme ça que les équipes évitent de se réveiller avec une facture de tokens qui ressemble à un incident cloud.
Le benchmark a un astérisque côté disponibilité
Il y a une complication d’actualité : la semaine de sortie de Fable 5 n’est pas restée calme.
Le 12 juin, Anthropic a publié une déclaration indiquant que le gouvernement américain avait émis une directive de contrôle des exportations demandant la suspension de l’accès à Fable 5 et Mythos 5 pour les ressortissants étrangers, y compris les employés Anthropic ressortissants étrangers ; Anthropic a déclaré que le seul moyen immédiat de se conformer était de désactiver les modèles pour tous les clients (Anthropic). L’entreprise a précisé que les autres modèles Claude n’étaient pas affectés.
Pour l’interprétation du benchmark, cela n’efface pas le résultat CursorBench. Le classement reste une preuve utile de la capacité du modèle dans le harnais d’agent de Cursor. Mais pour l’achat et la conception des workflows, la disponibilité n’est pas une note de bas de page. Si votre équipe se standardise sur un modèle qui peut disparaître pour des raisons de capacité, de politique ou de filtrage de sécurité, il vous faut une voie de secours.
C’est une raison de plus de ne pas brancher Fable 5 Max sur chaque tâche. Le meilleur setup d’ingénierie est portable entre modèles :
- des prompts qui ne dépendent pas des manies d’un fournisseur
- des frontières de tâche assez petites pour qu’un second modèle puisse réessayer
- des évaluations sur votre propre repo, pas seulement sur des classements publics
- des logs de coût par tâche, pas seulement des factures mensuelles
- un point d’escalade humain pour les diffs dangereux
Les benchmarks vous disent par où commencer. Votre repo vous dit quoi livrer.
Mon avis : utilisez Fable 5 comme un reviewer senior, pas comme une autocomplétion par défaut
Fable 5 Max mérite la première place sur CursorBench 3.1. Un score de 72,9 % sur des tâches Cursor ambiguës et multifichiers est exactement le genre de signal auquel les développeurs devraient prêter attention. Il bat GPT-5.5 Extra High et Opus 4.8 Max avec assez d’avance pour modifier les habitudes de sélection de modèle.
Mais la mauvaise leçon serait : « utilisez toujours Max ».
La bonne leçon est plus ciblée : Fable 5 vaut son prix quand l’ambiguïté est le goulot d’étranglement. Les migrations d’architecture, les bugs transverses, les suites de tests en échec sans propriétaire clair, les passes de revue subtiles, et les cas où « j’ai besoin que l’agent forme un plan avant de toucher au code » sont de bons candidats. Les modifications CRUD routinières, les corrections de tests évidentes, le nettoyage de formatage et les refactors sur un seul fichier ne le sont pas.
Si vous voulez le défaut pratique à retenir de ce classement, commencez par ça :
- Composer 2.5 pour le travail d’agent routinier, bon marché et suffisamment bon.
- GPT-5.5 Extra High quand vous voulez un score solide à un coût bien inférieur à Fable Max.
- Fable 5 Medium comme candidat sérieux au rôle de daily-driver.
- Fable 5 Max pour l’escalade, pas pour le bruit de fond.
- Retestez Opus 4.8 Max dans votre workflow ; CursorBench le rend difficile à justifier comme choix par défaut.
Le titre Fable 5, c’est 72,9 %. La leçon d’ingénierie, c’est le routage.
Les équipes qui gagneront avec ces modèles ne seront pas celles qui choisissent toujours le plus gros modèle. Ce seront celles qui savent exactement quand le plus gros modèle est bon marché.
Les lecteurs qui veulent essayer Claude Fable 5 eux-mêmes peuvent l’utiliser via OneHop : Claude Fable 5 sur OneHop, un endpoint drop-in facturé environ 30 % sous le prix catalogue. Les nouveaux comptes reçoivent 10 $ gratuits, sans carte requise.
À lire aussi : Bien démarrer avec Claude Fable 5.

