Claude Fable 5 不是悄悄摸上榜单的。它是一上来就站到了最顶端。
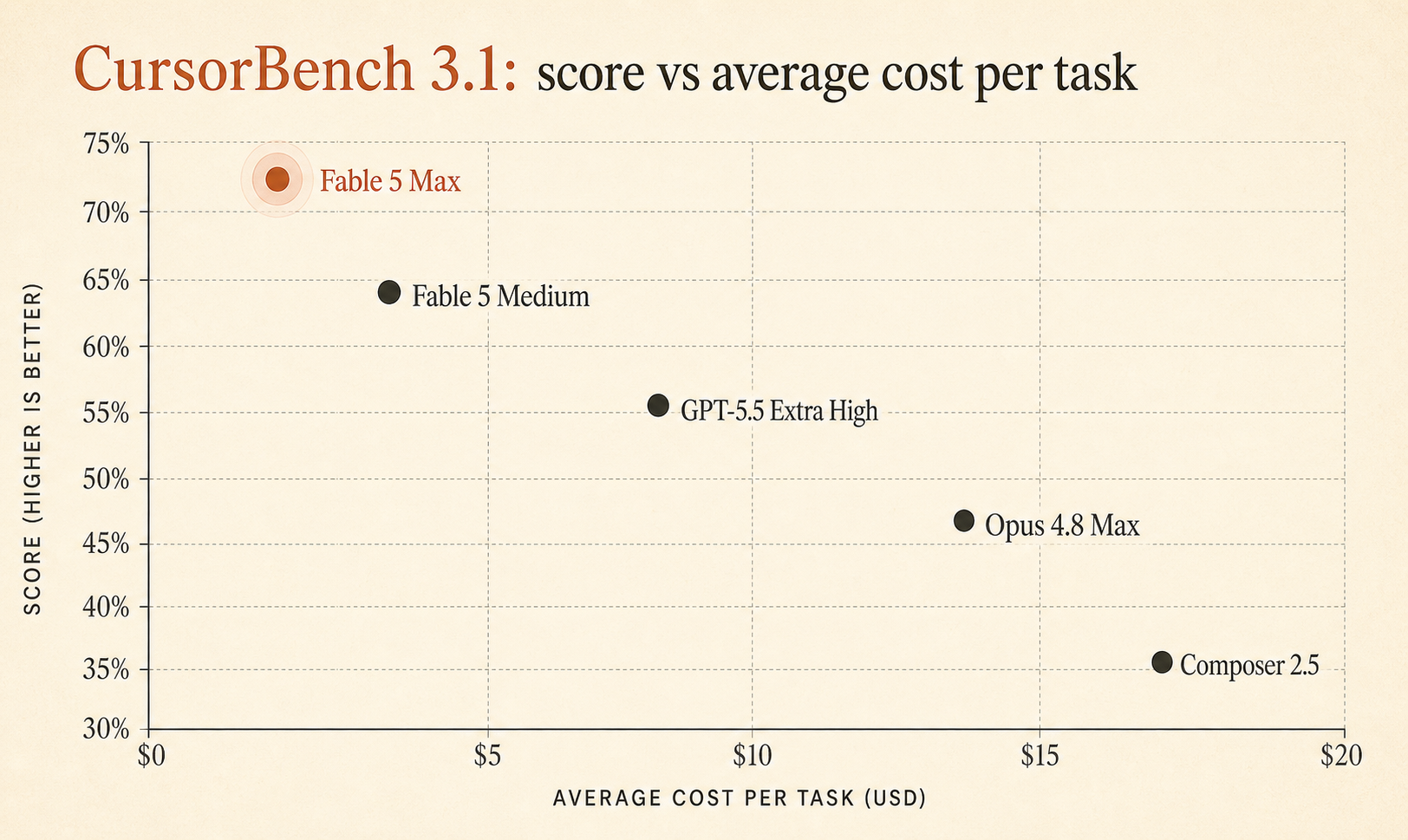
Cursor 的实时 CursorBench 3.1 页面现在显示,Fable 5 Max 达到 72.9%,每个任务平均成本 $18.02,领先于 GPT-5.5 Extra High 的 64.3% / $4.37 和 Opus 4.8 Max 的 63.8% / $7.59(Cursor)。这是一个很大的质量差距,而且这个基准测的是围绕真实 Cursor 会话构建的任务,不是玩具式算法题。
它也很贵。如果你整天跑代理,那就是疼得很明显的贵。
所以现在 Claude Code 和 Cursor 的争论,不是“Fable 5 好不好?”榜单已经回答了。更好的问题是:8 到 9 个百分点的领先,什么时候值得多付 2 到 4 倍账单?
我的答案是:Fable 5 是你用来升级处理的模型,不是你盲目让它接管每一次编辑的模型。真正有意思的结果,不只是 Fable 5 Max 赢了。而是 Fable 5 Medium 和 Low 可能才是更实用的故事。
CursorBench 3.1 到底在测什么
Cursor 将 CursorBench 3.1 描述为对“来自真实 Cursor 会话的模糊、多文件任务”的评测,分数越高越好(Cursor)。这句话很关键。开发者对编码代理的多数挫败感,并不是来自单文件 LeetCode 风格的失败。它来自那些乱糟糟的东西:
- 理解仓库结构
- 判断哪些文件重要
- 规划跨边界编辑
- 在没有被过度指挥的情况下找 bug
- 代码审查时不幻觉出一个不存在的问题
- 维持足够长的上下文,直到把事情做完
CursorBench 3.1 增加了聚焦于代码库理解、找 bug、规划和代码审查的问题,并改进了一些编辑任务的评分标准(Cursor)。Cursor 更长的基准说明文章称,这套测试是为了在公开基准越来越饱和的情况下区分前沿模型,同时 Cursor 也会把线上产品信号和离线评分一起跟踪(Cursor blog)。
这并不意味着它完美。它仍然是一家厂商的评测,运行在一个产品的代理框架里,任务分布也只有一种。Cursor 还提醒,小幅分数差异可能没有统计意义(Cursor)。所以不,你不该把 0.6 分的差距当成真理。
但 Fable 5 Max 不是赢了 0.6 分。它领先 GPT-5.5 Extra High 8.6 分,领先 Opus 4.8 Max 9.1 分。这已经大到值得认真对待。
下面是对日常编码代理选择真正重要的精简榜单:
| Model / setting | CursorBench 3.1 score | Avg cost / task | Tokens / task | Steps / task |
|---|---|---|---|---|
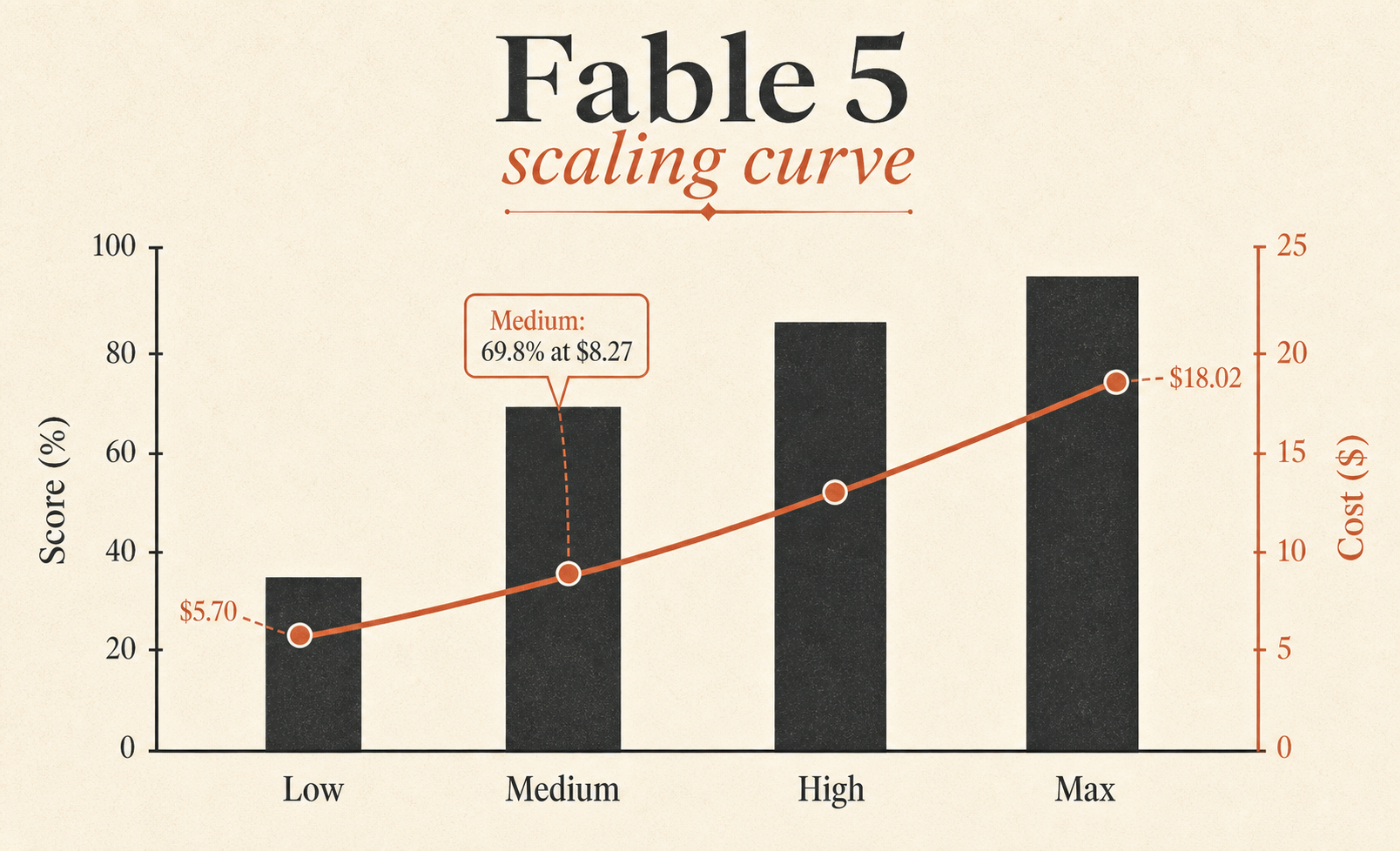
| Fable 5 Max | 72.9% | $18.02 | 63,842 | 76 |
| Fable 5 Extra High | 72.0% | $13.74 | 48,754 | 63 |
| Fable 5 High | 70.6% | $10.81 | 37,173 | 54 |
| Fable 5 Medium | 69.8% | $8.27 | 28,507 | 47 |
| Opus 4.7 Max | 64.8% | $11.02 | 62,989 | 96 |
| GPT-5.5 Extra High | 64.3% | $4.37 | 17,905 | 46 |
| Fable 5 Low | 64.2% | $5.70 | 18,882 | 36 |
| Opus 4.8 Max | 63.8% | $7.59 | 77,370 | 60 |
| Composer 2.5 | 63.2% | $0.55 | 15,152 | 37 |
Cursor 表示,每个任务的平均成本,是将各模型公开的每百万 token 定价,包括输入、缓存读取、缓存写入和输出 token,应用到每个 CursorBench 任务所使用的 token 上,然后对所有任务取平均(Cursor)。这个框架是对的。代理不是按感觉计费的。它们按读取、改写、重试和解释的量计费。
赢的是 Fable 5。性价比赢家不是。
Fable 5 Max 在原始分数上获胜。不需要任何包装。
但按每美元性能来看,画面很残酷:
| Model / setting | Score | Cost | Score points per $1 |
|---|---|---|---|
| Fable 5 Max | 72.9% | $18.02 | 4.0 |
| Fable 5 Medium | 69.8% | $8.27 | 8.4 |
| GPT-5.5 Extra High | 64.3% | $4.37 | 14.7 |
| Opus 4.8 Max | 63.8% | $7.59 | 8.4 |
| Composer 2.5 | 63.2% | $0.55 | 114.9 |
最后一行就是社区争论这么激烈的原因。Composer 2.5 在绝对质量上离 Fable 5 Max 并不近,但它在这个榜单上接近 GPT-5.5 Extra High 和 Opus 4.8 Max,而成本相比之下几乎是零钱。如果你每周跑几百个代理任务,这比榜首头衔重要得多。
边际账更清楚:
Fable 5 Max vs GPT-5.5 Extra High:
+8.6 score points, +$13.65/task
≈ $1.59 per extra score point对比 Opus 4.8 Max:
Fable 5 Max vs Opus 4.8 Max:
+9.1 score points, +$10.43/task
≈ $1.15 per extra score point对于一次棘手的迁移,多花 $10 到 $14 只是噪音。如果模型少让你失败一次,它就已经回本了。可如果一个团队在每个 pull request、依赖升级、lint 失败和测试修复上都跑后台代理,这个溢价就会变成预算政策。
最被低估的一行是 Fable 5 Medium。它得分 69.8%,只比 Fable 5 Max 低 3.1 分,成本却是 $8.27,而不是 $18.02。换句话说,Medium 用大约 46% 的 Max 任务成本,保住了约 96% 的 Max 基准分数。如果你想找一个 Fable 默认模型,就该盯着这一行看。
社区争论真正围绕的是 token 消耗
实时讨论串一点也不含蓄。在 Cursor subreddit 的发布讨论中,一位用户的第一印象是,Fable 5 展现了非常细致的推理和雄心勃勃的计划,但也“非常慢”,并且随着需求激增,连接方面的小问题也在预期之内(Reddit r/cursor)。这和榜单吻合:Fable 5 Max 每个任务使用 63,842 tokens 和 76 steps。它不是一个轻量反射型模型。
在关于 CursorBench 结果的 ClaudeAI 讨论串里,反对意见来得很快:一位评论者称它“不是合法的基准”,另一位马上问,如果 fable medium 更便宜,那是不是“就没有理由用 opus 了”,还有回复指出 Composer 2.5 “非常便宜而且好用”(Reddit r/ClaudeAI)。这正是核心分歧:基准可信度、Opus 是否被取代,以及便宜且够好的替代品。
ClaudeCode 的讨论串更接近实际运营问题。原帖注意到,在 CursorBench 上,Fable 5 Low 比 Opus 4.8 Max 更聪明且更便宜,评论者则把焦点放在每任务成本和 token 效率上。有条评论说得很直白:对独立开发者和自由职业者来说,每任务成本和相对分数才是重要基准,因为生产力很快可能会按 token 消耗来评判(Reddit r/ClaudeCode)。
这个说法和表格对得上。
Fable 5 Low:
- 64.2%
- $5.70
- 18,882 tokens
Opus 4.8 Max:
- 63.8%
- $7.59
- 77,370 tokens
所以在 CursorBench 3.1 上,Fable 5 Low 略微领先 Opus 4.8 Max,每个任务少花 $1.89,并且少用约 76% 的 tokens。这不是微不足道的脚注。这是产品决策。
如果你在 Cursor 里仍然把 Opus 4.8 Max 当作“严肃 Claude”设置,这个基准说明你应该立刻测试 Fable 5 Low 和 Medium。不是因为每个仓库都会匹配 Cursor 的任务组合。而是因为举证责任已经变了。
Anthropic 的定价解释了为什么价格这么刺眼
Anthropic 于 2026 年 6 月 9 日发布 Claude Fable 5 和 Claude Mythos 5,并将 Mythos 级模型描述为高于 Opus 的一个层级。在 Anthropic 的发布文章中,Fable 5 是通用发布版本,而 Mythos 5 是同一底层模型,但为受限的可信访问用途解除了一些防护(Anthropic)。
API 价格简单而高昂:Fable 5 和 Mythos 5 都是每百万输入 token $10、每百万输出 token $50(Anthropic)。Anthropic 还表示,Fable 5 可通过 Claude API 以 claude-fable-5 使用,而订阅计划访问只会临时包含到 6 月 22 日,除非容量允许延长(Anthropic)。
这个定价会改变你思考代理提示词的方式。
用便宜模型时,粗糙的上下文还能忍。你粘贴太多内容,要求太宽泛的修改,让代理到处游荡,账单虽然烦人但还扛得住。到了 Fable 5 Max 级别的成本,糟糕的 harness 设计就会被放大。每个不必要的文件、重复的计划、冗长的工具结果和失败的 patch 尝试都会叠加。
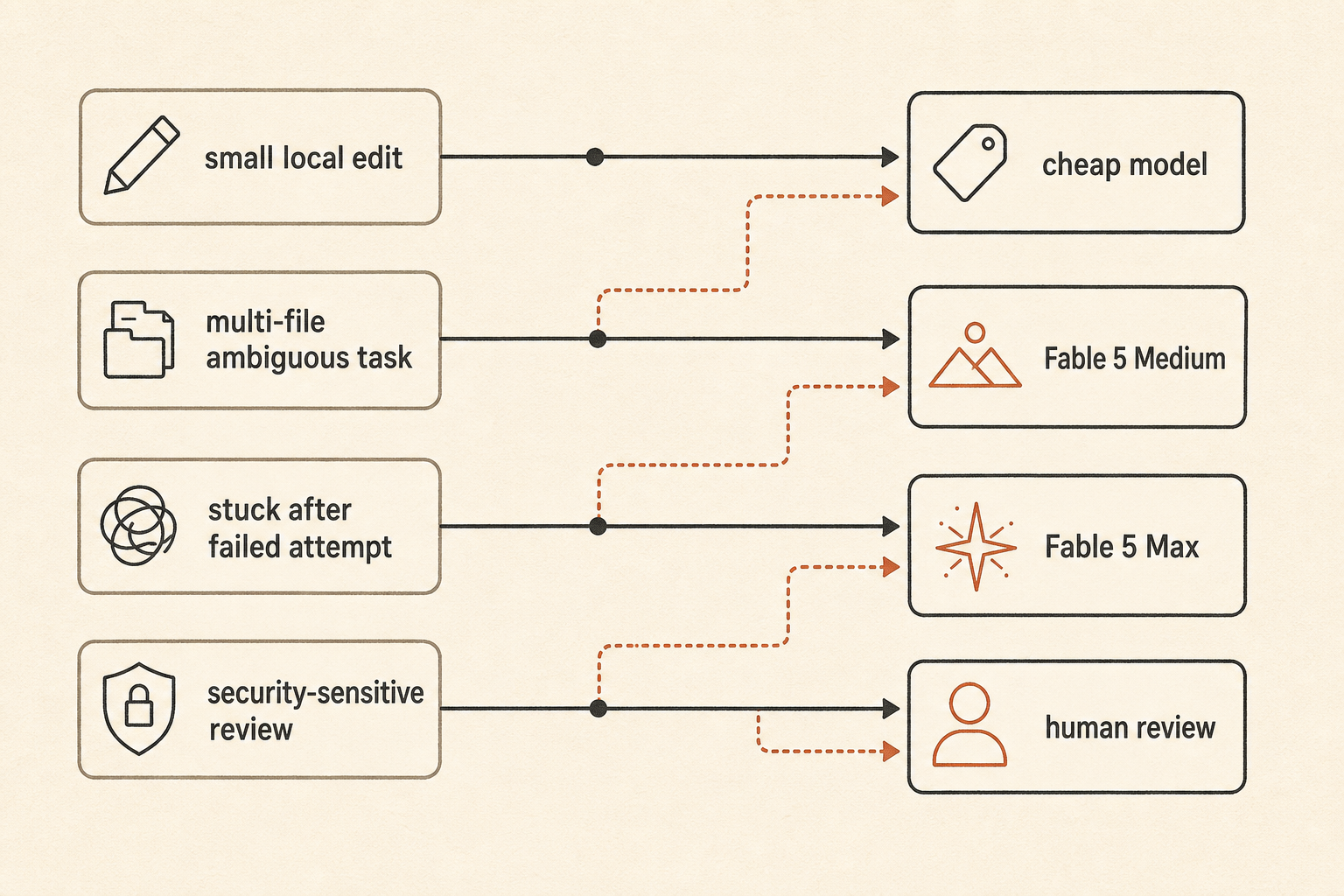
一个实用的路由策略大概是这样:
default: fast/cheap model for local edits and small bugs
escalate: Fable 5 Medium for ambiguous multi-file work
reserve: Fable 5 Max for high-risk refactors, stuck tasks, and final review
fallback: human review when the agent starts exploring instead of editing这不如“使用最好的模型”听起来刺激。但这才是团队避免一觉醒来看到像云事故一样的 token 账单的方法。
这个基准有一个可用性星号
还有一个混乱的时事变量:Fable 5 的发布周并不平静。
6 月 12 日,Anthropic 发布声明称,美国政府发布了一项出口管制指令,要求暂停外国国民访问 Fable 5 和 Mythos 5,包括拥有外国国籍的 Anthropic 员工;Anthropic 表示,立即合规的唯一方式是对所有客户禁用这些模型(Anthropic)。公司称其他 Claude 模型不受影响。
对基准解读来说,这不会抹掉 CursorBench 的结果。榜单仍然是关于模型在 Cursor 代理框架下能力的有用证据。但对采购和工作流设计来说,可用性不是脚注。如果你的团队把标准流程押在一个可能因为容量、政策或安全门控而消失的模型上,你就需要一条回退路径。
这也是不要把 Fable 5 Max 接进每个任务的另一个理由。最好的工程设置应该是模型可移植的:
- 不依赖某一家提供商怪癖的 prompts
- 足够小的任务边界,让第二个模型可以重试
- 在你自己的仓库上做 evals,而不只是看公开榜单
- 按任务记录成本,而不只是看月度账单
- 对危险 diff 设置人工升级点
基准告诉你从哪里开始。你的仓库告诉你该交付什么。
我的看法:把 Fable 5 当高级审查者用,而不是默认自动补全
Fable 5 Max 配得上 CursorBench 3.1 的第一名。在模糊、多文件 Cursor 任务上拿到 72.9% 的分数,正是开发者应该关心的信号。它领先 GPT-5.5 Extra High 和 Opus 4.8 Max 的幅度足以改变模型选择习惯。
但错误的教训是“永远用 Max”。
正确的教训更窄:当模糊性才是瓶颈时,Fable 5 值得付费。架构迁移、跨文件 bug、归属不清的失败测试套件、细微的审查环节,以及“我需要代理先形成计划再碰代码”的任务,都很适合。常规 CRUD 编辑、明显的测试修复、格式清理和单文件重构则不适合。
如果你想从这个榜单里找一个实用默认方案,可以从这里开始:
- Composer 2.5 用于便宜、够用的常规代理工作。
- GPT-5.5 Extra High 用于在远低于 Fable Max 成本的情况下获得强分数。
- Fable 5 Medium 作为严肃日常主力候选。
- Fable 5 Max 用于升级处理,而不是后台噪音。
- Retest Opus 4.8 Max 在你的工作流里重新测试;CursorBench 让它很难继续作为默认选择被合理化。
Fable 5 的标题数字是 72.9%。工程上的教训是路由。
真正用好这些模型的团队,不会是那些永远选择最大模型的团队。会是那些清楚知道最大模型什么时候反而便宜的团队。
想亲自试用 Claude Fable 5 的读者,可以通过 OneHop 使用它:Claude Fable 5 on OneHop,这是一个可直接替换的 endpoint,价格约比标价低 30%。新账号可获得 $10 free,无需银行卡。
延伸阅读:Claude Fable 5 入门.

