Claude Fable 5は、こっそりリーダーボードに入り込んだわけではない。いきなり頂点に着地した。
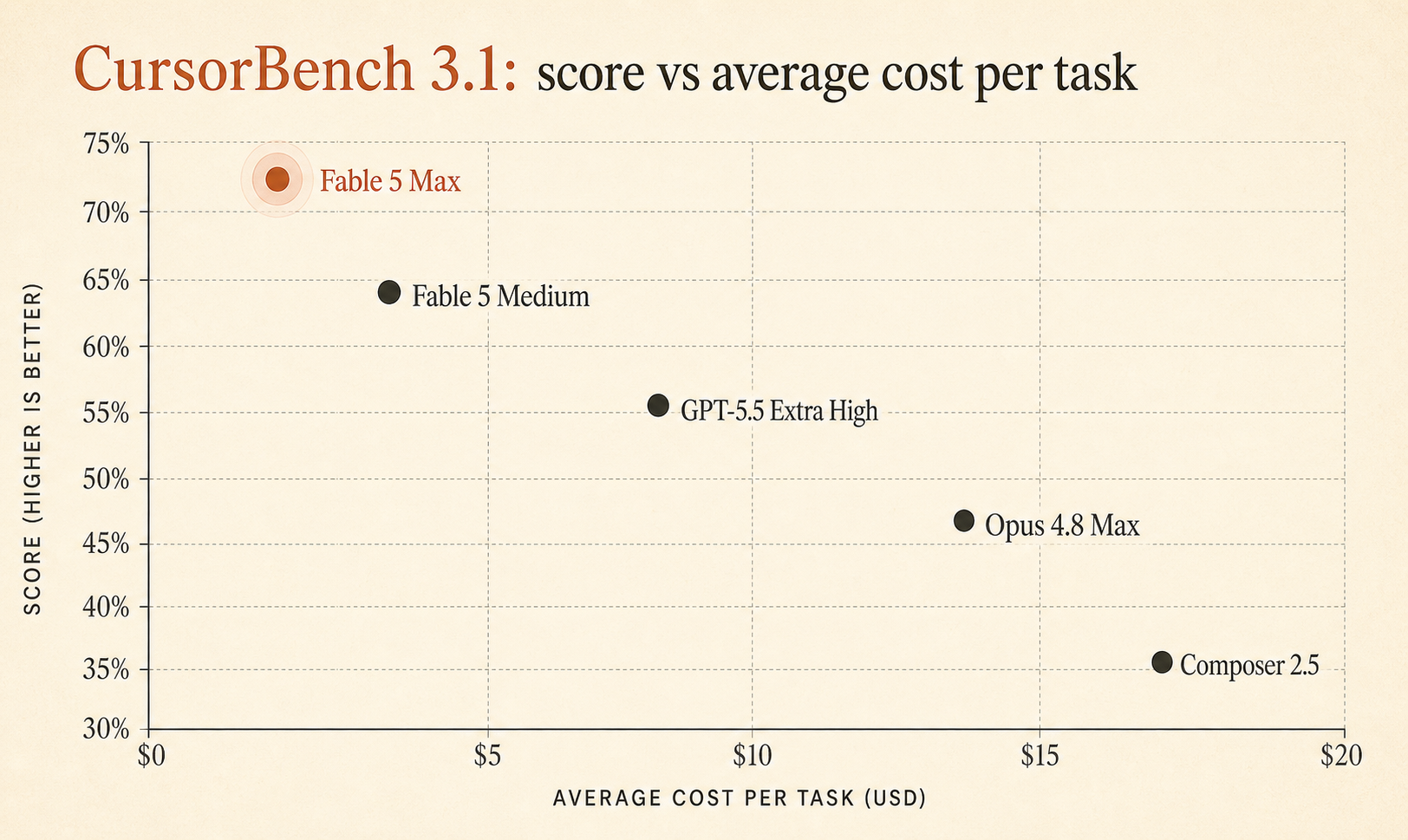
Cursorのライブ版CursorBench 3.1ページでは、いま Fable 5 Maxが72.9%、タスクあたり平均コスト$18.02 と表示されている。これは GPT-5.5 Extra Highの64.3% / $4.37、Opus 4.8 Maxの63.8% / $7.59 を上回る (Cursor)。おもちゃのアルゴリズム問題ではなく、実際のCursorセッションをもとにしたベンチマークで、この品質差はかなり大きい。
同時に、高い。エージェントを一日中回すなら、痛いほど高い。
だから、いまのClaude CodeとCursorをめぐる議論は「Fable 5は良いのか?」ではない。リーダーボードがそこには答えている。もっと大事な問いはこうだ。8〜9ポイントの勝利は、いつ2倍から4倍の請求額に見合うのか?
私の答えはこうだ。Fable 5はエスカレーション先にするモデルであって、すべての編集で何も考えずに常時オンにするモデルではない。面白いのは、Fable 5 Maxが勝ったことだけではない。Fable 5 MediumとLowのほうが、実用面では本命かもしれない ということだ。
CursorBench 3.1が実際に測っているもの
CursorはCursorBench 3.1を、「実際のCursorセッションから取った、曖昧な複数ファイルタスク」の評価だと説明している。スコアは高いほど良い (Cursor)。この一文は重要だ。開発者がコーディングエージェントに苛立つのは、単一ファイルのLeetCode風問題で失敗するからではない。面倒なのは、もっと泥臭い部分だ。
- リポジトリ構成を理解する
- どのファイルが重要か判断する
- 境界をまたいだ編集を計画する
- 細かく指示されなくてもバグを見つける
- 存在しない問題をでっち上げずにコードレビューする
- 完了まで文脈を保ち続ける
CursorBench 3.1では、コードベース理解、バグ発見、計画、コードレビュー に焦点を当てた問題が追加され、一部の編集タスクでは採点基準も改善された (Cursor)。Cursorのより長いベンチマーク解説によれば、このスイートは公開ベンチマークが飽和しつつある中でフロンティアモデルを切り分けるためのもので、Cursorはオフラインの評価点だけでなくオンラインのプロダクト指標も追っているという (Cursor blog)。
だからといって完璧ではない。これはあくまで、ひとつのベンダーの評価であり、ひとつのプロダクトのエージェントハーネス上で、ひとつのタスク分布に対して実行されたものだ。Cursor自身も、小さなスコア差には統計的な意味がない可能性があると注意している (Cursor)。だから、0.6ポイント差を福音のように扱うべきではない。
しかしFable 5 Maxは0.6ポイント差で勝っているわけではない。GPT-5.5 Extra Highに 8.6ポイント、Opus 4.8 Maxに 9.1ポイント 差をつけている。これは真面目に受け止めるべき大きさだ。
日々のコーディングエージェント選びで重要な部分だけを切り出したリーダーボードはこうなる。
| Model / setting | CursorBench 3.1 score | Avg cost / task | Tokens / task | Steps / task |
|---|---|---|---|---|
| Fable 5 Max | 72.9% | $18.02 | 63,842 | 76 |
| Fable 5 Extra High | 72.0% | $13.74 | 48,754 | 63 |
| Fable 5 High | 70.6% | $10.81 | 37,173 | 54 |
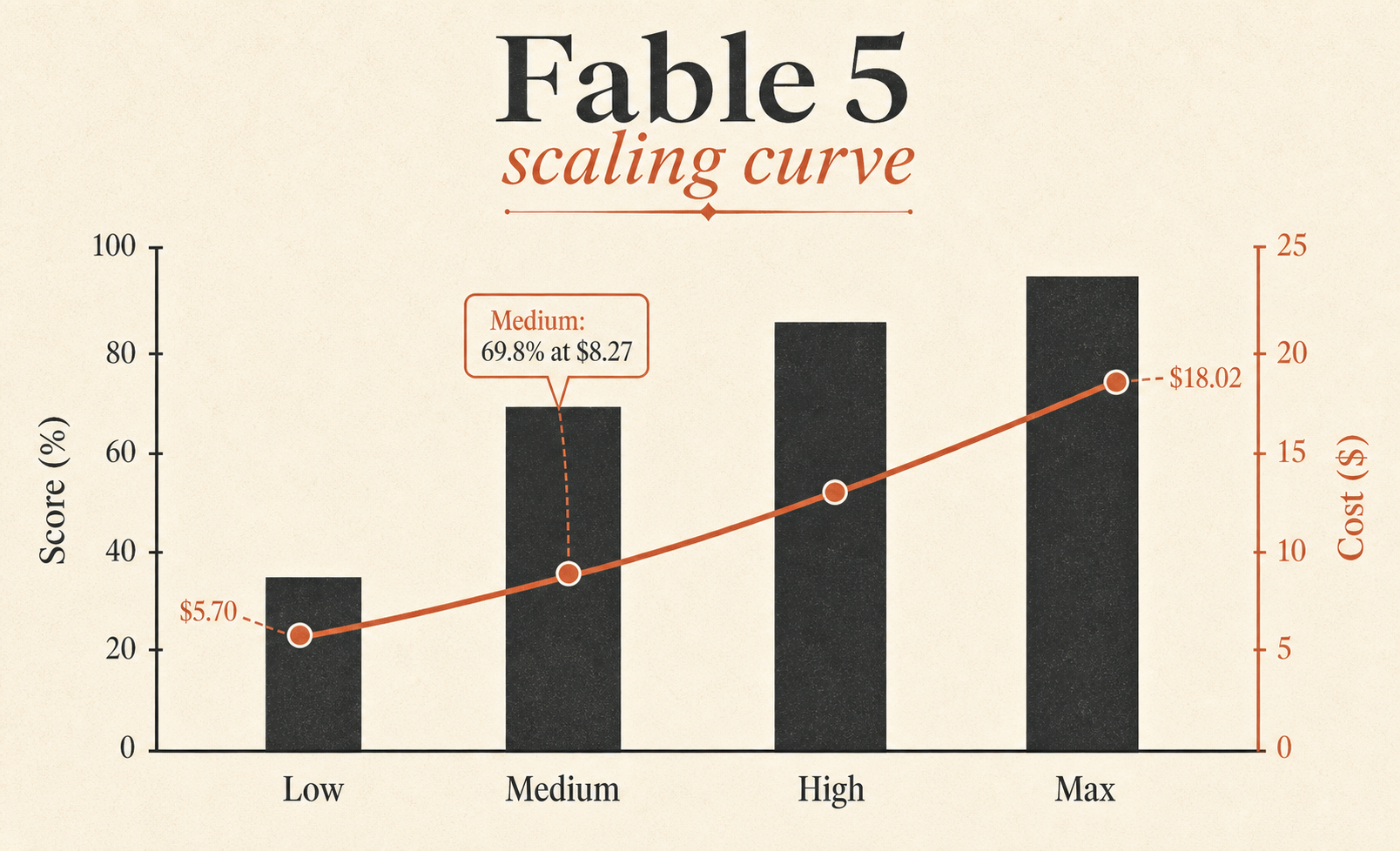
| Fable 5 Medium | 69.8% | $8.27 | 28,507 | 47 |
| Opus 4.7 Max | 64.8% | $11.02 | 62,989 | 96 |
| GPT-5.5 Extra High | 64.3% | $4.37 | 17,905 | 46 |
| Fable 5 Low | 64.2% | $5.70 | 18,882 | 36 |
| Opus 4.8 Max | 63.8% | $7.59 | 77,370 | 60 |
| Composer 2.5 | 63.2% | $0.55 | 15,152 | 37 |
Cursorによれば、タスクあたり平均コストは、各モデルの公表されている100万トークンあたり価格を、各CursorBenchタスクで使われたトークンに適用して計算している。そこには入力、キャッシュ読み取り、キャッシュ書き込み、出力トークンが含まれ、そのうえでタスク全体の平均を取っている (Cursor)。この捉え方は正しい。エージェントの価格は雰囲気で決まらない。どれだけ読み、書き直し、リトライし、説明するかで決まる。
勝者はFable 5。価値の勝者は違う。
Fable 5 Maxは素のスコアで勝っている。そこに言い訳はいらない。
だが、性能対価格で見ると残酷だ。
| Model / setting | Score | Cost | Score points per $1 |
|---|---|---|---|
| Fable 5 Max | 72.9% | $18.02 | 4.0 |
| Fable 5 Medium | 69.8% | $8.27 | 8.4 |
| GPT-5.5 Extra High | 64.3% | $4.37 | 14.7 |
| Opus 4.8 Max | 63.8% | $7.59 | 8.4 |
| Composer 2.5 | 63.2% | $0.55 | 114.9 |
最後の行こそ、コミュニティの議論が熱くなる理由だ。Composer 2.5は絶対的な品質ではFable 5 Maxに近くない。しかしこのリーダーボード上では、GPT-5.5 Extra HighやOpus 4.8 Maxに近い位置にいながら、コストは比較にならないほど安い。週に何百ものエージェントタスクを回すなら、リーダーボードの王冠よりそちらのほうが重要になる。
限界的な計算はもっとわかりやすい。
Fable 5 Max vs GPT-5.5 Extra High:
+8.6 score points, +$13.65/task
≈ $1.59 per extra score pointOpus 4.8 Maxと比べるとこうだ。
Fable 5 Max vs Opus 4.8 Max:
+9.1 score points, +$10.43/task
≈ $1.15 per extra score point厄介な移行作業を一度やるだけなら、追加の$10〜$14は誤差だ。失敗を一回防いでくれるなら、それだけで元が取れる。だが、すべてのプルリクエスト、依存関係更新、lint失敗、テスト修復でバックグラウンドエージェントを回すチームにとって、その上乗せは予算方針になる。
もっとも過小評価されている行は Fable 5 Medium だ。スコアは 69.8%。Fable 5 Maxからわずか3.1ポイント差で、コストは $18.02 ではなく $8.27。つまりMediumは、Maxのベンチマークスコアの約 96% を、Maxのタスクコストの約 46% で維持している。Fableをデフォルトにしたいなら、凝視すべきはこの行だ。
コミュニティの議論の本質はトークン消費だ
ライブスレッドは遠慮がない。Cursor subredditのローンチスレッドでは、あるユーザーの第一印象として、Fable 5は非常に詳細な推論と野心的な計画を示した一方で、「とても遅い」とされ、需要急増に伴う接続まわりの癖も予想されていた (Reddit r/cursor)。これはリーダーボードとも一致する。Fable 5 Maxは タスクあたり63,842トークン、タスクあたり76ステップ を使う。軽量な反射神経型モデルではない。
CursorBenchの結果を扱ったClaudeAIスレッドでは、反発もすぐに来た。あるコメントはこれを「正当なベンチマークではない」と呼び、別のユーザーはすぐに「fable mediumのほうが安いならopusを使う理由はないのでは」と問い、返信ではComposer 2.5が「とても安くて良い」と指摘されていた (Reddit r/ClaudeAI)。これは正しい分岐だ。ベンチマークへの信頼、Opusの置き換え、そして安くて十分な代替案。
ClaudeCodeスレッドでは、さらに運用上の問題に近づいていた。元投稿は、CursorBench上で Fable 5 LowがOpus 4.8 Maxより賢く、かつ安い ことに注目し、コメント欄ではタスクあたりコストとトークン効率に議論が集中した。あるコメントは端的にこう述べていた。インディー開発者やフリーランサーにとって重要なベンチマークは、タスクあたりコストと相対スコアであり、近いうちに生産性はトークン消費で評価されるようになるかもしれない、と (Reddit r/ClaudeCode)。
この主張は表と照らし合わせても筋が通る。
Fable 5 Low:
- 64.2%
- $5.70
- 18,882 tokens
Opus 4.8 Max:
- 63.8%
- $7.59
- 77,370 tokens
つまりCursorBench 3.1上では、Fable 5 LowはOpus 4.8 Maxをわずかに上回り、タスクあたり$1.89安く、使用トークンは約 76%少ない。これは小さな脚注ではない。プロダクト判断そのものだ。
Cursor内で、いまもOpus 4.8 Maxを「本気のClaude」設定として使っているなら、このベンチマークはFable 5 LowとMediumをすぐ試すべきだと言っている。すべてのリポジトリがCursorのタスク分布に合うからではない。立証責任が移ったからだ。
Anthropicの価格がステッカーショックを説明している
Anthropicは2026年6月9日にClaude Fable 5とClaude Mythos 5を発表し、MythosクラスのモデルをOpusの一段上の階層だと説明した。Anthropicのローンチ記事では、Fable 5が一般提供版であり、Mythos 5は同じ基盤モデルから一部のセーフガードを外した、制限付きの信頼アクセス用途向けモデルとされている (Anthropic)。
API価格は単純で、そして高い。Fable 5とMythos 5はいずれも、入力100万トークンあたり$10、出力100万トークンあたり$50 だ (Anthropic)。Anthropicはまた、Fable 5がClaude APIで claude-fable-5 として利用可能であり、サブスクリプションプランでのアクセスは、容量に余裕があって延長されない限り、6月22日までの一時的な提供に限られるとも述べている (Anthropic)。
この価格設定は、エージェントへのプロンプトの考え方を変える。
安いモデルなら、雑なコンテキストも許容できる。貼りすぎ、広すぎる変更依頼、エージェントの迷走を放置。それでも請求額は鬱陶しい程度で済む。Fable 5 Max級のコストになると、悪いハーネス設計が目に見える。不要なファイル、繰り返される計画、冗長なツール結果、失敗したパッチ試行、そのすべてが積み上がる。
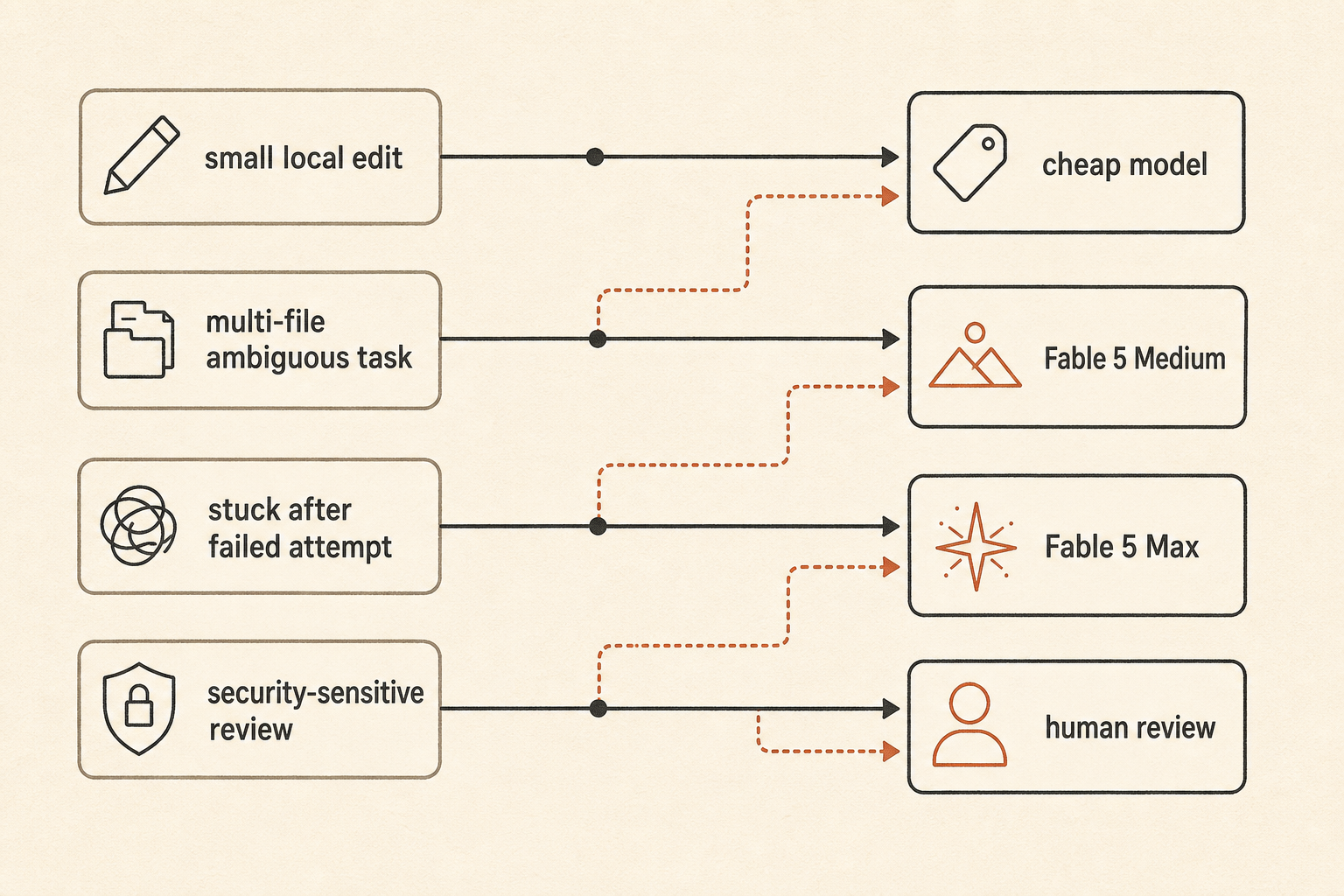
実用的なルーティング方針はこうなる。
default: fast/cheap model for local edits and small bugs
escalate: Fable 5 Medium for ambiguous multi-file work
reserve: Fable 5 Max for high-risk refactors, stuck tasks, and final review
fallback: human review when the agent starts exploring instead of editing「最高のモデルを使え」よりは地味だ。だが、トークン請求がクラウド障害みたいな額になって目を覚ますのを避けるには、チームはこうするしかない。
このベンチマークには可用性の注釈がある
現在進行形の厄介な点がひとつある。Fable 5のリリース週は、静かなままでは終わらなかった。
6月12日、Anthropicは声明を出し、米国政府が輸出管理指令を発行し、外国籍のAnthropic従業員を含む外国籍者によるFable 5とMythos 5へのアクセスを停止するよう求めたと述べた。Anthropicは、即座に準拠する唯一の方法は全顧客に対してこれらのモデルを無効化することだったとしている (Anthropic)。同社によれば、他のClaudeモデルには影響はない。
ベンチマークの解釈としては、これはCursorBenchの結果を消し去るものではない。リーダーボードは、Cursorのエージェントハーネス下でのモデル能力について、なお有用な証拠だ。だが調達やワークフロー設計では、可用性は脚注ではない。容量、政策、安全性ゲートのせいで消える可能性のあるモデルにチームが標準化するなら、フォールバック経路が必要になる。
これも、Fable 5 Maxをすべてのタスクに組み込むべきではない理由のひとつだ。優れたエンジニアリング環境は、モデルに対してポータブルである。
- 特定プロバイダーの癖に依存しないプロンプト
- 2つ目のモデルが再試行できる程度に小さいタスク境界
- 公開リーダーボードだけでなく、自分たちのリポジトリでの評価
- 月次請求書だけでなく、タスクごとのコストログ
- 危険な差分に対する人間のエスカレーション地点
ベンチマークは、どこから始めるべきかを教えてくれる。何を出荷すべきかは、自分のリポジトリが教えてくれる。
私の見方:Fable 5はデフォルトのオートコンプリートではなく、シニアレビュアーのように使う
Fable 5 MaxがCursorBench 3.1のトップに立つのは当然だ。曖昧な複数ファイルのCursorタスクで72.9%というスコアは、開発者が気にすべき種類のシグナルそのものだ。GPT-5.5 Extra HighとOpus 4.8 Maxを十分な差で上回っており、モデル選択の習慣を変えるべき結果だ。
だが、間違った教訓は「常にMaxを使え」だ。
正しい教訓はもっと狭い。Fable 5にお金を払う価値があるのは、曖昧さがボトルネックになっているとき だ。アーキテクチャ移行、複数ファイルにまたがるバグ、責任範囲が曖昧な失敗テスト群、微妙なレビュー、そして「コードに触る前にエージェントに計画を立ててほしい」場面には向いている。日常的なCRUD編集、明らかなテスト修正、フォーマット整理、単一ファイルのリファクタリングには向いていない。
このリーダーボードから実用的なデフォルトを選ぶなら、まずはこうだ。
- Composer 2.5 は、安くて十分な日常のエージェント作業に。
- GPT-5.5 Extra High は、Fable Maxよりずっと低コストで強いスコアが欲しいときに。
- Fable 5 Medium は、本気の日常運用候補として。
- Fable 5 Max は、エスカレーション用であって、バックグラウンドノイズではない。
- Opus 4.8 Maxを再検証 すべきだ。CursorBenchを見る限り、デフォルトとして正当化するのは難しい。
Fable 5の見出しは72.9%だ。エンジニアリング上の教訓はルーティングである。
これらのモデルで勝つチームは、常にいちばん大きなモデルを選ぶチームではない。いちばん大きなモデルがいつ安くつくのかを、正確に知っているチームだ。
Claude Fable 5を自分で試したい読者は、OneHop経由で利用できる:Claude Fable 5 on OneHop。差し替え可能なエンドポイントで、定価より約30%安い。新規アカウントには $10 free が付く。カード不要。
Further reading: Claude Fable 5を始める.

