Claude Fable 5는 조용히 리더보드에 올라온 게 아니다. 맨 꼭대기에 착지했다.
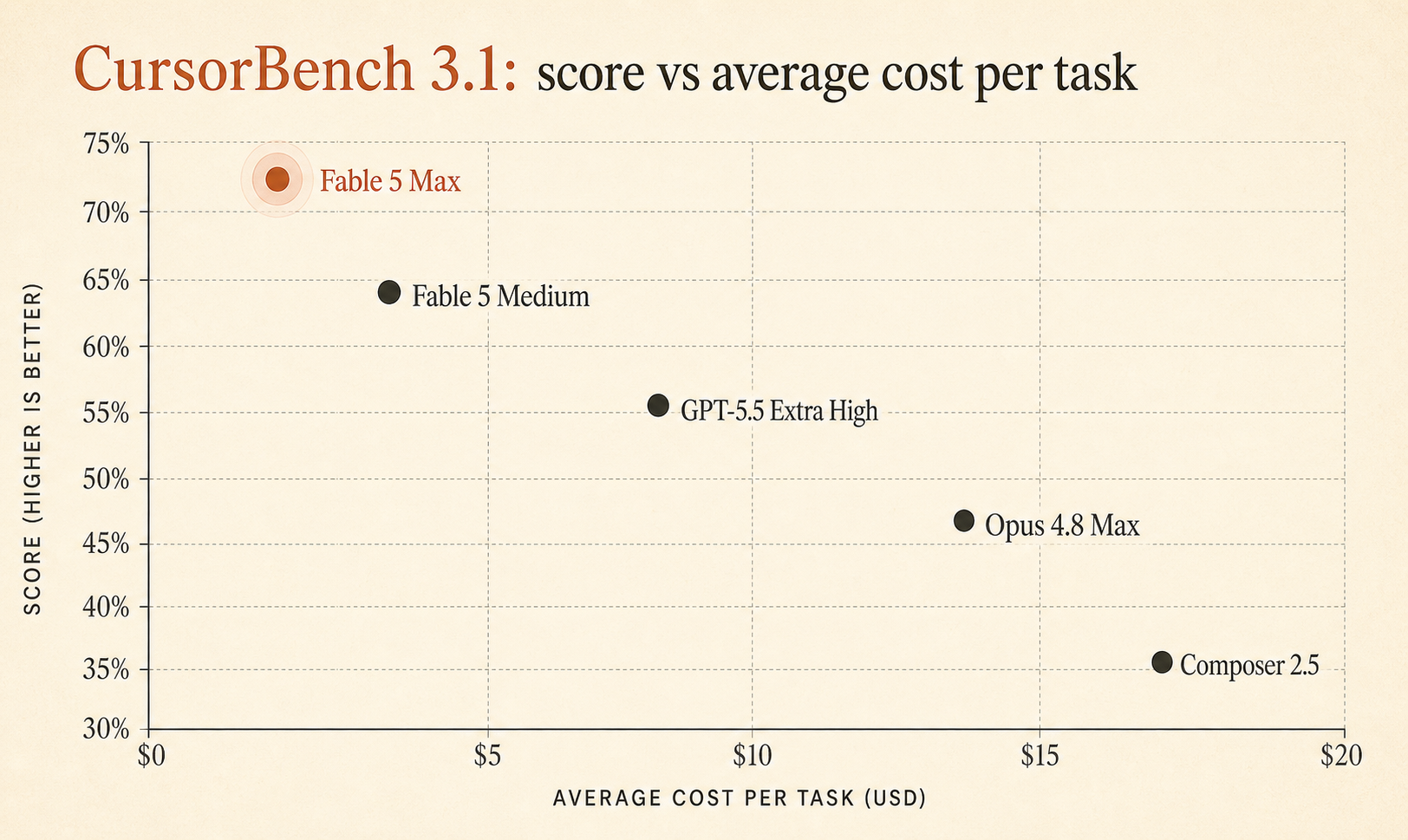
Cursor의 실시간 CursorBench 3.1 페이지는 현재 Fable 5 Max를 72.9%, 작업당 평균 비용 $18.02로 표시한다. GPT-5.5 Extra High의 64.3% / $4.37, Opus 4.8 Max의 63.8% / $7.59보다 앞선다 (Cursor). 장난감 알고리즘 문제가 아니라 실제 Cursor 세션을 바탕으로 만든 벤치마크에서 이 정도 품질 격차는 크다.
비싸기도 하다. 에이전트를 하루 종일 돌린다면 아플 만큼 비싸다.
그래서 지금 Claude Code와 Cursor를 둘러싼 논쟁은 “Fable 5가 좋은가?”가 아니다. 리더보드가 이미 답했다. 더 나은 질문은 이거다. 8~9점 차이의 승리가 2배에서 4배 비싼 청구서를 정당화하는 순간은 언제인가?
내 답은 이렇다. Fable 5는 필요할 때 올려 쓰는 모델이지, 모든 편집에 무작정 켜두는 모델이 아니다. 흥미로운 결과는 Fable 5 Max가 이겼다는 사실만이 아니다. Fable 5 Medium과 Low가 오히려 더 실용적인 이야기일 수 있다는 점이다.
CursorBench 3.1이 실제로 측정하는 것
Cursor는 CursorBench 3.1을 “실제 Cursor 세션에서 나온 모호한 멀티 파일 작업”에 대한 평가라고 설명하며, 점수가 높을수록 좋다고 말한다 (Cursor). 이 표현이 중요하다. 개발자가 코딩 에이전트에 좌절하는 대부분의 순간은 단일 파일 LeetCode식 실패에서 오지 않는다. 지저분한 부분에서 온다.
- repo 구조 이해하기
- 어떤 파일이 중요한지 판단하기
- 경계를 넘나드는 편집 계획하기
- 과도하게 지시하지 않아도 버그 찾아내기
- 없는 문제를 지어내지 않고 코드 리뷰하기
- 끝까지 마칠 만큼 context를 유지하기
CursorBench 3.1은 codebase 이해, bugfinding, planning, code review에 초점을 둔 문제를 추가했고, 일부 편집 작업의 채점 기준도 개선했다 (Cursor). Cursor의 더 긴 벤치마크 글은 공개 벤치마크가 점점 포화되는 상황에서 frontier 모델을 구분하기 위해 이 suite가 만들어졌으며, Cursor가 오프라인 점수와 함께 온라인 제품 신호도 추적한다고 설명한다 (Cursor blog).
그렇다고 완벽하다는 뜻은 아니다. 여전히 한 vendor의 eval이고, 한 제품의 agent harness 안에서, 하나의 작업 분포로 실행된다. Cursor도 작은 점수 차이는 통계적으로 의미가 없을 수 있다고 경고한다 (Cursor). 그러니 0.6점 차이를 성경처럼 받아들일 필요는 없다.
하지만 Fable 5 Max는 0.6점 차이로 이기는 게 아니다. GPT-5.5 Extra High보다 8.6점, Opus 4.8 Max보다 9.1점 앞선다. 진지하게 볼 만큼 큰 차이다.
일상적인 코딩 에이전트 선택에서 중요한 리더보드만 압축하면 이렇다.
| Model / setting | CursorBench 3.1 score | Avg cost / task | Tokens / task | Steps / task |
|---|---|---|---|---|
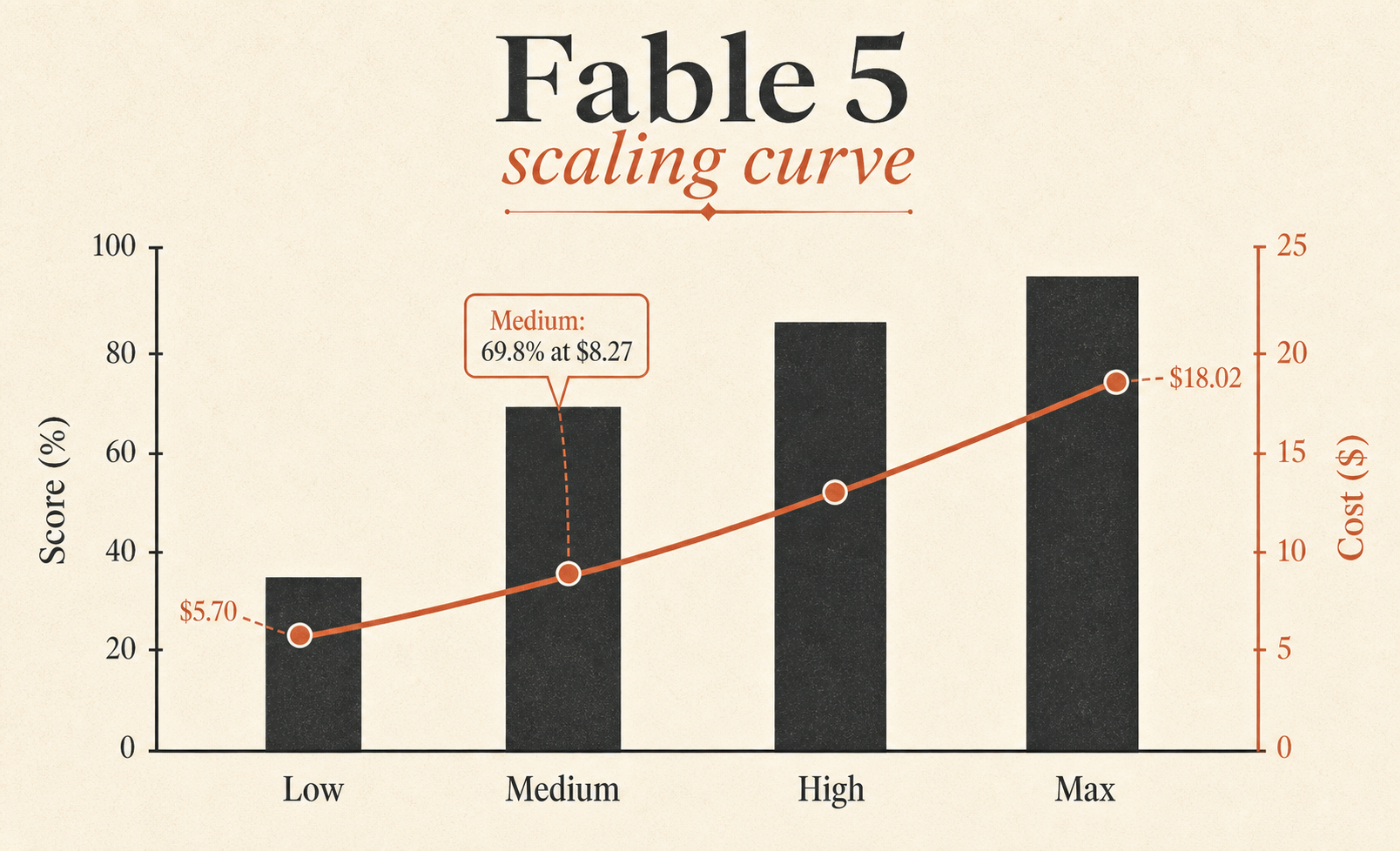
| Fable 5 Max | 72.9% | $18.02 | 63,842 | 76 |
| Fable 5 Extra High | 72.0% | $13.74 | 48,754 | 63 |
| Fable 5 High | 70.6% | $10.81 | 37,173 | 54 |
| Fable 5 Medium | 69.8% | $8.27 | 28,507 | 47 |
| Opus 4.7 Max | 64.8% | $11.02 | 62,989 | 96 |
| GPT-5.5 Extra High | 64.3% | $4.37 | 17,905 | 46 |
| Fable 5 Low | 64.2% | $5.70 | 18,882 | 36 |
| Opus 4.8 Max | 63.8% | $7.59 | 77,370 | 60 |
| Composer 2.5 | 63.2% | $0.55 | 15,152 | 37 |
Cursor는 작업당 평균 비용을 각 model의 공개된 백만 token당 가격에 따라 계산한다고 말한다. input, cache read, cache write, output token을 모두 포함해 각 CursorBench 작업에서 사용한 token에 적용한 뒤, 작업 전체의 평균을 낸다 (Cursor). 이게 맞는 프레임이다. 에이전트 가격은 감으로 매겨지지 않는다. 얼마나 읽고, 다시 쓰고, 재시도하고, 설명하는지로 매겨진다.
승자는 Fable 5다. 가성비 승자는 아니다.
Fable 5 Max는 원점수에서 이긴다. 포장할 필요도 없다.
하지만 달러당 성능으로 보면 잔인하다.
| Model / setting | Score | Cost | Score points per $1 |
|---|---|---|---|
| Fable 5 Max | 72.9% | $18.02 | 4.0 |
| Fable 5 Medium | 69.8% | $8.27 | 8.4 |
| GPT-5.5 Extra High | 64.3% | $4.37 | 14.7 |
| Opus 4.8 Max | 63.8% | $7.59 | 8.4 |
| Composer 2.5 | 63.2% | $0.55 | 114.9 |
마지막 줄 때문에 커뮤니티 논쟁이 뜨겁다. Composer 2.5는 절대 품질에서 Fable 5 Max에 가깝지 않다. 하지만 이 리더보드에서는 GPT-5.5 Extra High와 Opus 4.8 Max에 꽤 가까우면서 비용은 비교가 안 될 만큼 낮다. 일주일에 수백 개의 agent task를 돌린다면, 리더보드 왕관보다 이쪽이 더 중요하다.
한계 비용 계산은 더 분명하다.
Fable 5 Max vs GPT-5.5 Extra High:
+8.6 score points, +$13.65/task
≈ $1.59 per extra score pointOpus 4.8 Max와 비교하면 이렇다.
Fable 5 Max vs Opus 4.8 Max:
+9.1 score points, +$10.43/task
≈ $1.15 per extra score point까다로운 migration 하나라면 $10~$14 추가 비용은 잡음에 가깝다. 모델이 실패 한 번만 줄여도 본전을 뽑는다. 하지만 모든 pull request, dependency bump, lint failure, test repair에 background agent를 돌리는 팀이라면, 그 premium은 예산 정책이 된다.
가장 과소평가된 줄은 Fable 5 Medium이다. 점수는 **69.8%**로 Fable 5 Max보다 겨우 3.1점 낮고, 비용은 $18.02가 아니라 $8.27이다. 다시 말해 Medium은 Max의 벤치마크 점수 약 **96%**를 유지하면서 작업 비용은 Max의 약 **46%**만 쓴다. Fable을 기본값으로 쓰고 싶다면, 뚫어지게 봐야 할 줄은 이쪽이다.
커뮤니티 논쟁의 본질은 Token 소모다
실시간 thread들은 전혀 미묘하지 않다. Cursor subreddit의 출시 thread에서 한 사용자는 Fable 5의 첫인상으로 매우 상세한 reasoning과 야심찬 plan을 보여줬지만, 동시에 “very slow”했고 수요가 폭증하면서 연결 문제도 예상된다고 말했다 (Reddit r/cursor). 리더보드와 맞아떨어진다. Fable 5 Max는 작업당 63,842 tokens, 작업당 76 steps를 쓴다. 가벼운 반사 신경형 모델이 아니다.
CursorBench 결과를 다룬 ClaudeAI thread에서는 반발이 빠르게 나왔다. 한 댓글은 이를 “not a legitimate benchmark”라고 불렀고, 다른 사용자는 곧바로 “fable medium이 더 싸다면 opus를 쓸 이유가 없는 것 아니냐”고 물었다. 이어진 답글은 Composer 2.5가 “very cheap and good”하다고 짚었다 (Reddit r/ClaudeAI). 올바른 분기점이다. benchmark 신뢰, Opus 대체, 싸고 충분히 좋은 대안.
ClaudeCode thread는 운영상의 문제에 더 가까이 갔다. 원문 작성자는 CursorBench에서 Fable 5 Low가 Opus 4.8 Max보다 더 똑똑하고 저렴하다는 점을 짚었고, 댓글들은 작업당 비용과 token 효율에 집중했다. 한 댓글은 노골적으로 말했다. indie developer와 freelancer에게 중요한 benchmark는 작업당 비용과 상대 점수이며, 생산성이 곧 token 소비량으로 평가될지도 모른다고 (Reddit r/ClaudeCode).
표와 비교해 보면 그 주장은 맞다.
Fable 5 Low:
- 64.2%
- $5.70
- 18,882 tokens
Opus 4.8 Max:
- 63.8%
- $7.59
- 77,370 tokens
그러니까 CursorBench 3.1에서 Fable 5 Low는 Opus 4.8 Max보다 살짝 앞서고, 작업당 $1.89 더 싸며, token은 약 76% 적게 쓴다. 작은 각주가 아니다. 제품 결정 사항이다.
Cursor 안에서 여전히 Opus 4.8 Max를 “진지한 Claude” 설정으로 쓰고 있다면, 이 benchmark는 Fable 5 Low와 Medium을 즉시 테스트하라고 말한다. 모든 repo가 Cursor의 작업 조합과 맞아떨어져서가 아니다. 입증 책임이 이동했기 때문이다.
Anthropic의 가격이 스티커 쇼크를 설명한다
Anthropic은 2026년 6월 9일 Claude Fable 5와 Claude Mythos 5를 출시하며, Mythos급 모델을 Opus보다 한 단계 위 tier로 설명했다. Anthropic의 출시 글에서 Fable 5는 일반 릴리스이고, Mythos 5는 제한된 trusted-access 사용을 위해 일부 safeguards를 완화한 같은 underlying model이라고 설명한다 (Anthropic).
API 가격은 단순하고 비싸다. Fable 5와 Mythos 5 모두 input tokens 백만 개당 $10, output tokens 백만 개당 $50이다 (Anthropic). Anthropic은 또한 Fable 5가 Claude API에서 claude-fable-5로 제공되며, subscription-plan access는 capacity가 허락해 연장되지 않는 한 6월 22일까지 일시적으로만 포함된다고 밝혔다 (Anthropic).
이 가격은 agent prompt를 바라보는 방식을 바꾼다.
싼 모델에서는 엉성한 context도 견딜 만하다. 너무 많이 붙여넣고, 너무 넓은 변경을 요청하고, 에이전트가 헤매게 둬도 청구서는 짜증나는 수준이지 버틸 수는 있다. Fable 5 Max급 비용에서는 나쁜 harness 설계가 눈에 보인다. 불필요한 파일, 반복되는 plan, 장황한 tool result, 실패한 patch attempt가 전부 복리로 불어난다.
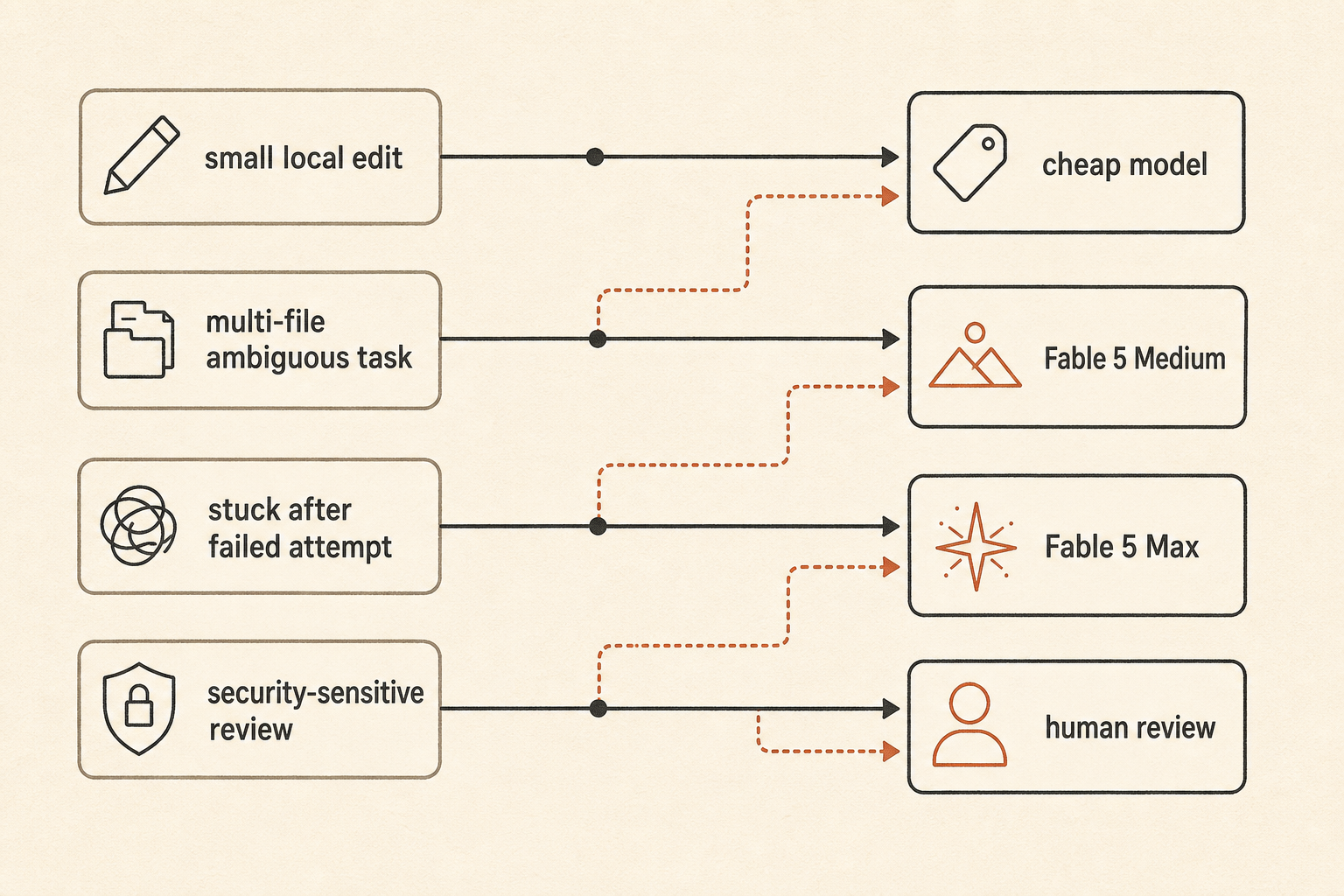
실용적인 routing policy는 이런 모습이다.
default: fast/cheap model for local edits and small bugs
escalate: Fable 5 Medium for ambiguous multi-file work
reserve: Fable 5 Max for high-risk refactors, stuck tasks, and final review
fallback: human review when the agent starts exploring instead of editing“최고 모델을 써라”보다 덜 신나게 들린다. 하지만 팀이 cloud incident처럼 보이는 token 청구서를 보고 잠에서 깨지 않는 방법이기도 하다.
이 벤치마크에는 가용성이라는 별표가 붙는다
현재 진행형의 지저분한 변수가 하나 있다. Fable 5의 출시 주간은 조용히 지나가지 않았다.
6월 12일 Anthropic은 미국 정부가 외국 국적자를 대상으로 Fable 5와 Mythos 5 access를 중단하라는 export-control directive를 내렸다고 밝혔다. 여기에는 외국 국적의 Anthropic employees도 포함된다. Anthropic은 즉시 준수할 수 있는 유일한 방법이 모든 고객에 대해 해당 모델을 비활성화하는 것이라고 말했다 (Anthropic). 회사는 다른 Claude 모델은 영향을 받지 않는다고 했다.
benchmark 해석 측면에서 이것이 CursorBench 결과를 지우지는 않는다. 리더보드는 여전히 Cursor의 agent harness 아래에서 모델 capability를 보여주는 유용한 증거다. 하지만 procurement와 workflow design에서는 availability가 각주가 아니다. capacity, policy, safety gating 때문에 사라질 수 있는 모델에 팀이 표준화한다면, fallback path가 필요하다.
Fable 5 Max를 모든 작업에 연결하지 말아야 할 또 다른 이유다. 좋은 engineering setup은 model-portable하다.
- 한 provider의 quirks에 의존하지 않는 prompts
- 두 번째 모델이 retry할 수 있을 만큼 작은 task boundaries
- public leaderboards만이 아니라 자기 repo에서의 evals
- monthly invoices만이 아니라 task별 cost logs
- 위험한 diffs를 위한 human escalation point
Benchmarks는 어디서 시작할지 알려준다. 무엇을 ship할지는 당신의 repo가 알려준다.
내 생각: Fable 5는 기본 Autocomplete가 아니라 Senior Reviewer처럼 써라
Fable 5 Max는 CursorBench 3.1 1위를 차지할 자격이 있다. 모호한 멀티 파일 Cursor 작업에서 72.9% 점수는 개발자가 신경 써야 할 바로 그런 신호다. GPT-5.5 Extra High와 Opus 4.8 Max를 충분히 큰 차이로 이기기 때문에, 이 결과는 model-selection 습관을 바꿔야 한다.
하지만 잘못된 교훈은 “항상 Max를 써라”다.
올바른 교훈은 더 좁다. 모호성이 병목일 때 Fable 5는 돈을 낼 가치가 있다. Architecture migration, cross-file bug, ownership이 불분명한 failing test suites, 미묘한 review pass, “code를 건드리기 전에 agent가 plan을 세워야 하는” 상황은 잘 맞는다. Routine CRUD edits, 명백한 test fix, formatting cleanup, one-file refactor는 아니다.
이 리더보드에서 실용적인 기본값을 원한다면 이렇게 시작하라.
- Composer 2.5는 싸고 충분히 좋은 routine agent work용.
- GPT-5.5 Extra High는 Fable Max보다 훨씬 낮은 비용으로 강한 점수를 원할 때.
- Fable 5 Medium은 진지한 daily-driver 후보.
- Fable 5 Max는 escalation용이지 background noise가 아니다.
- Opus 4.8 Max는 workflow 안에서 다시 테스트하라. CursorBench 기준으로는 default로 정당화하기 어렵다.
Fable 5의 headline은 72.9%다. engineering lesson은 routing이다.
이 모델들로 이기는 팀은 항상 가장 큰 모델을 고르는 팀이 아닐 것이다. 가장 큰 모델이 언제 싼 선택인지 정확히 아는 팀일 것이다.
Claude Fable 5를 직접 써보고 싶은 독자는 OneHop을 통해 사용할 수 있다: Claude Fable 5 on OneHop, 정가보다 약 30% 낮은 가격의 drop-in endpoint다. 신규 계정은 카드 없이도 $10 free를 받는다.
추가 읽을거리: Claude Fable 5 시작하기.

