Claude Fable 5 did not sneak onto the leaderboard. It landed at the top.
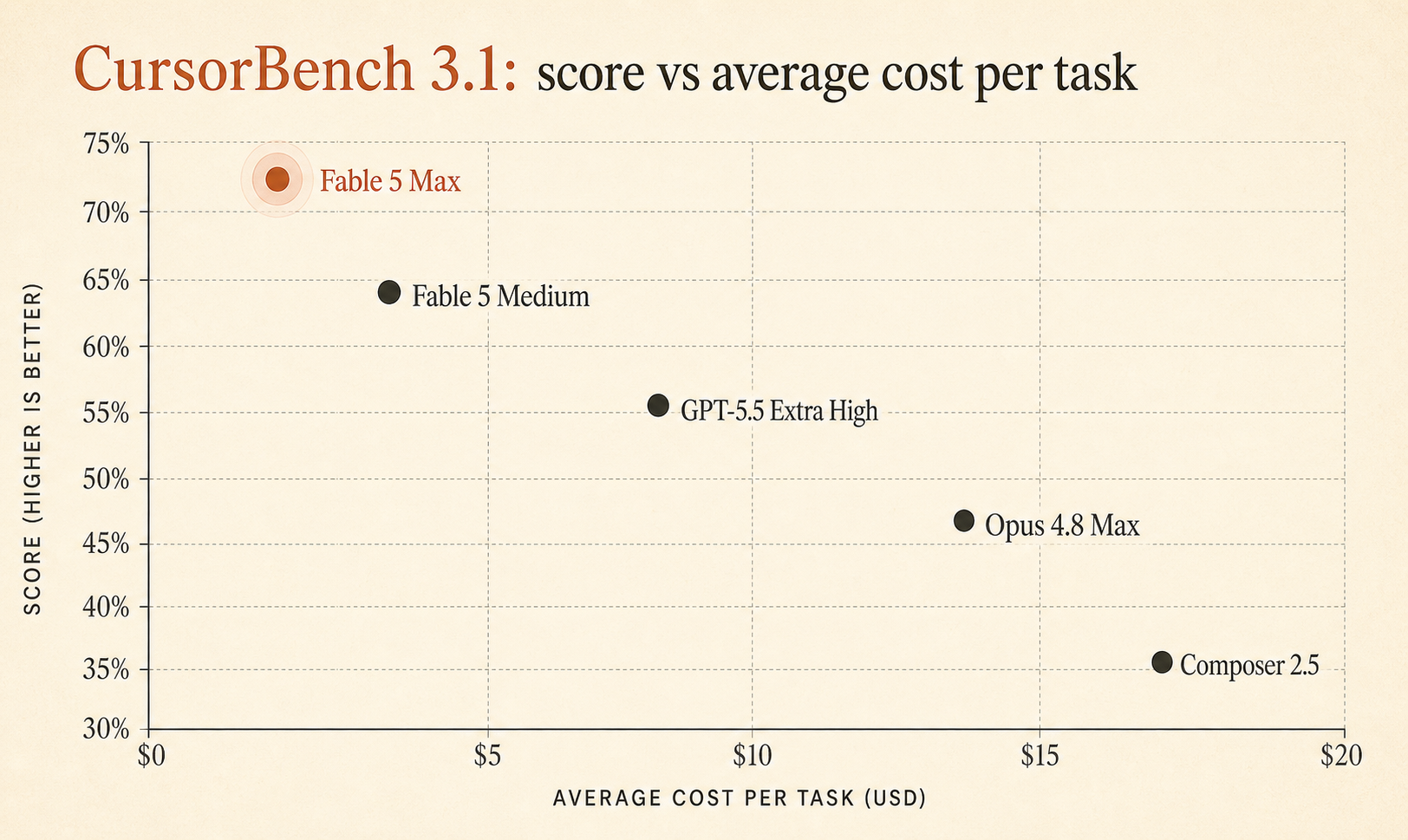
Cursor’s live CursorBench 3.1 page now puts Fable 5 Max at 72.9% with an $18.02 average cost per task, ahead of GPT-5.5 Extra High at 64.3% / $4.37 and Opus 4.8 Max at 63.8% / $7.59 (Cursor). That is a big quality gap on a benchmark built around real Cursor sessions, not toy algorithm puzzles.
It is also expensive. Painfully expensive if you run agents all day.
That is why the current Claude Code and Cursor debate is not “is Fable 5 good?” The leaderboard answers that. The better question is: when does an 8- to 9-point win justify a 2x to 4x bill?
My answer: Fable 5 is the model you escalate to, not the model you blindly leave on for every edit. The interesting result is not just that Fable 5 Max wins. It is that Fable 5 Medium and Low may be the more practical story.
What CursorBench 3.1 Actually Measures
Cursor describes CursorBench 3.1 as an evaluation of “ambiguous, multi-file tasks from real Cursor sessions,” where higher score is better (Cursor). That phrase matters. Most developer frustration with coding agents does not come from single-file LeetCode-style failures. It comes from the messy stuff:
- understanding a repo layout
- deciding which files matter
- planning an edit across boundaries
- finding bugs without being over-directed
- reviewing code without hallucinating a false problem
- keeping context alive long enough to finish
CursorBench 3.1 added problems focused on codebase understanding, bugfinding, planning, and code review, and improved grading criteria for some edit tasks (Cursor). Cursor’s longer benchmark write-up says the suite is meant to separate frontier models where public benchmarks are increasingly saturated, and that Cursor tracks online product signals alongside offline grades (Cursor blog).
That does not make it perfect. It is still one vendor’s eval, run inside one product’s agent harness, with one task distribution. Cursor also warns that small score differences may not be statistically meaningful (Cursor). So no, you should not treat a 0.6-point gap as gospel.
But Fable 5 Max is not winning by 0.6 points. It is ahead of GPT-5.5 Extra High by 8.6 points and Opus 4.8 Max by 9.1 points. That is large enough to take seriously.
Here is the compact leaderboard cut that matters for day-to-day coding-agent choices:
| Model / setting | CursorBench 3.1 score | Avg cost / task | Tokens / task | Steps / task |
|---|---|---|---|---|
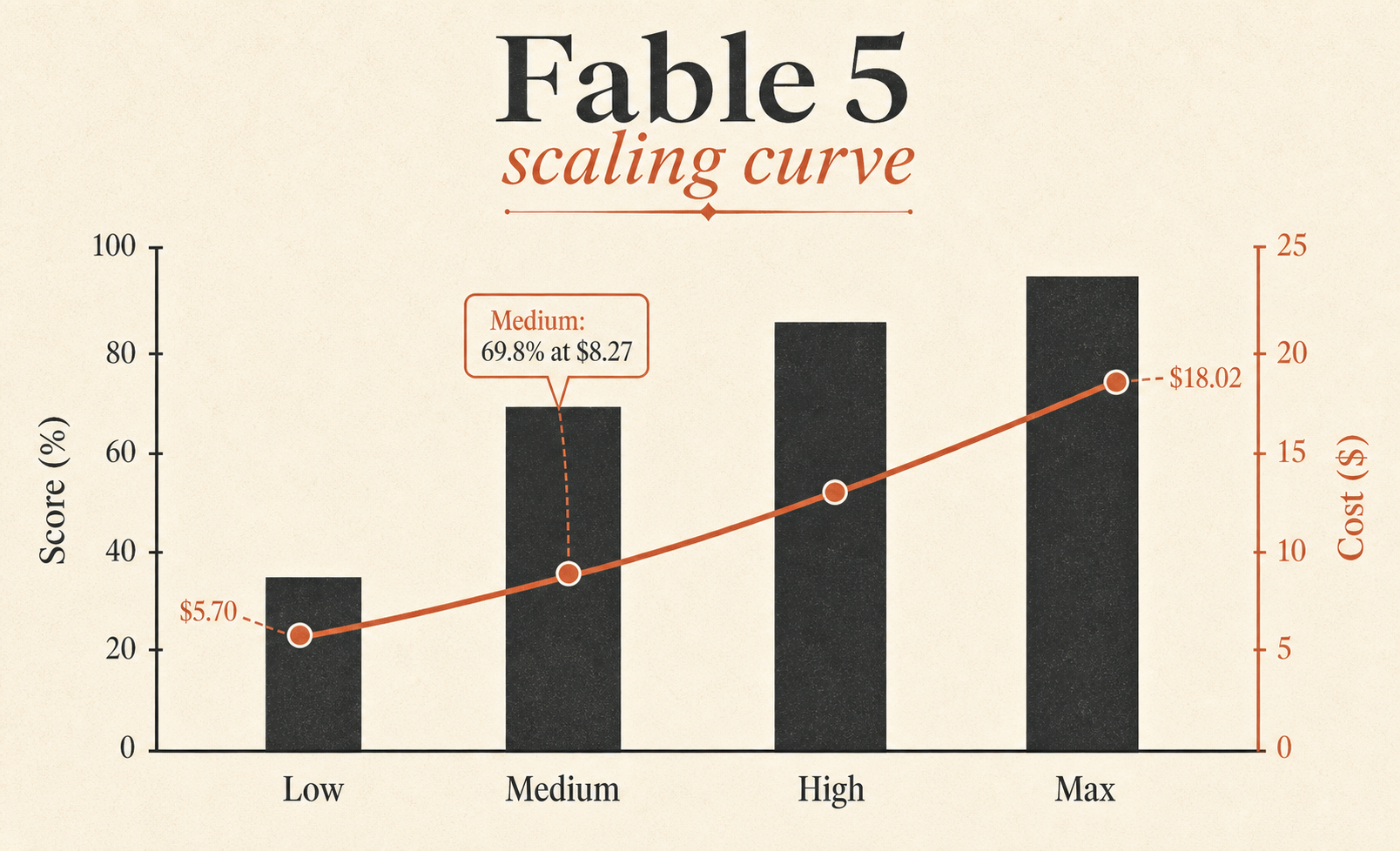
| Fable 5 Max | 72.9% | $18.02 | 63,842 | 76 |
| Fable 5 Extra High | 72.0% | $13.74 | 48,754 | 63 |
| Fable 5 High | 70.6% | $10.81 | 37,173 | 54 |
| Fable 5 Medium | 69.8% | $8.27 | 28,507 | 47 |
| Opus 4.7 Max | 64.8% | $11.02 | 62,989 | 96 |
| GPT-5.5 Extra High | 64.3% | $4.37 | 17,905 | 46 |
| Fable 5 Low | 64.2% | $5.70 | 18,882 | 36 |
| Opus 4.8 Max | 63.8% | $7.59 | 77,370 | 60 |
| Composer 2.5 | 63.2% | $0.55 | 15,152 | 37 |
Cursor says the average cost per task is computed by applying each model’s published per-million-token pricing, including input, cache read, cache write, and output tokens, to the tokens used on each CursorBench task, then averaging across tasks (Cursor). That is the right framing. Agents are not priced by vibes. They are priced by how much they read, rewrite, retry, and explain.
The Winner Is Fable 5. The Value Winner Is Not.
Fable 5 Max wins on raw score. No spin needed.
But the performance-per-dollar view is brutal:
| Model / setting | Score | Cost | Score points per $1 |
|---|---|---|---|
| Fable 5 Max | 72.9% | $18.02 | 4.0 |
| Fable 5 Medium | 69.8% | $8.27 | 8.4 |
| GPT-5.5 Extra High | 64.3% | $4.37 | 14.7 |
| Opus 4.8 Max | 63.8% | $7.59 | 8.4 |
| Composer 2.5 | 63.2% | $0.55 | 114.9 |
That last row is why the community argument is heated. Composer 2.5 is not close to Fable 5 Max in absolute quality, but it is close to GPT-5.5 Extra High and Opus 4.8 Max on this leaderboard while costing pennies by comparison. If you run hundreds of agent tasks per week, that matters more than a leaderboard crown.
The marginal math is clearer:
Fable 5 Max vs GPT-5.5 Extra High:
+8.6 score points, +$13.65/task
≈ $1.59 per extra score pointAgainst Opus 4.8 Max:
Fable 5 Max vs Opus 4.8 Max:
+9.1 score points, +$10.43/task
≈ $1.15 per extra score pointFor one gnarly migration, $10 to $14 extra is noise. If the model saves one failed attempt, it paid for itself. For a team running background agents on every pull request, dependency bump, lint failure, and test repair, that premium becomes budget policy.
The most underrated row is Fable 5 Medium. It scores 69.8%, only 3.1 points behind Fable 5 Max, at $8.27 instead of $18.02. In other words, Medium keeps about 96% of Max’s benchmark score at about 46% of Max’s task cost. If you want a Fable default, that is the row to stare at.
The Community Debate Is Really About Token Burn
The live threads are not subtle. In a Cursor subreddit launch thread, one user’s first impressions were that Fable 5 showed very detailed reasoning and an ambitious plan, but was also “very slow,” with connectivity quirks expected as demand spiked (Reddit r/cursor). That tracks the leaderboard: Fable 5 Max uses 63,842 tokens per task and 76 steps per task. It is not a lightweight reflex model.
In a ClaudeAI thread about the CursorBench result, the pushback came fast: one commenter called it “not a legitimate benchmark,” while another immediately asked whether there was “no reason to use opus then if fable medium is cheaper,” and a reply pointed at Composer 2.5 being “very cheap and good” (Reddit r/ClaudeAI). That is the right split: benchmark trust, Opus displacement, and cheap-good-enough alternatives.
A ClaudeCode thread got even closer to the operational issue. The original post noticed that Fable 5 Low is smarter and cheaper than Opus 4.8 Max on CursorBench, and commenters zeroed in on cost per task and token efficiency. One comment put it plainly: for indie developers and freelancers, cost per task and relative score are the important benchmarks, because productivity may soon be judged by token consumption (Reddit r/ClaudeCode).
That claim checks out against the table.
Fable 5 Low:
- 64.2%
- $5.70
- 18,882 tokens
Opus 4.8 Max:
- 63.8%
- $7.59
- 77,370 tokens
So on CursorBench 3.1, Fable 5 Low is slightly ahead of Opus 4.8 Max, costs $1.89 less per task, and uses about 76% fewer tokens. That is not a tiny footnote. That is a product decision.
If you are still using Opus 4.8 Max as your “serious Claude” setting inside Cursor, the benchmark says you should test Fable 5 Low and Medium immediately. Not because every repo will match Cursor’s task mix. Because the burden of proof has moved.
Anthropic’s Pricing Explains the Sticker Shock
Anthropic launched Claude Fable 5 and Claude Mythos 5 on June 9, 2026, describing Mythos-class models as a tier above Opus. In Anthropic’s launch post, Fable 5 is the general release, while Mythos 5 is the same underlying model with some safeguards lifted for restricted trusted-access use (Anthropic).
The API price is simple and high: $10 per million input tokens and $50 per million output tokens for both Fable 5 and Mythos 5 (Anthropic). Anthropic also said Fable 5 was available through the Claude API as claude-fable-5, and that subscription-plan access was included only temporarily through June 22 unless capacity allowed an extension (Anthropic).
That pricing changes how you should think about agent prompts.
With cheap models, sloppy context is tolerable. You paste too much, ask for too broad a change, let the agent wander, and the bill is annoying but survivable. With Fable 5 Max-class costs, bad harness design becomes visible. Every unnecessary file, repeated plan, verbose tool result, and failed patch attempt compounds.
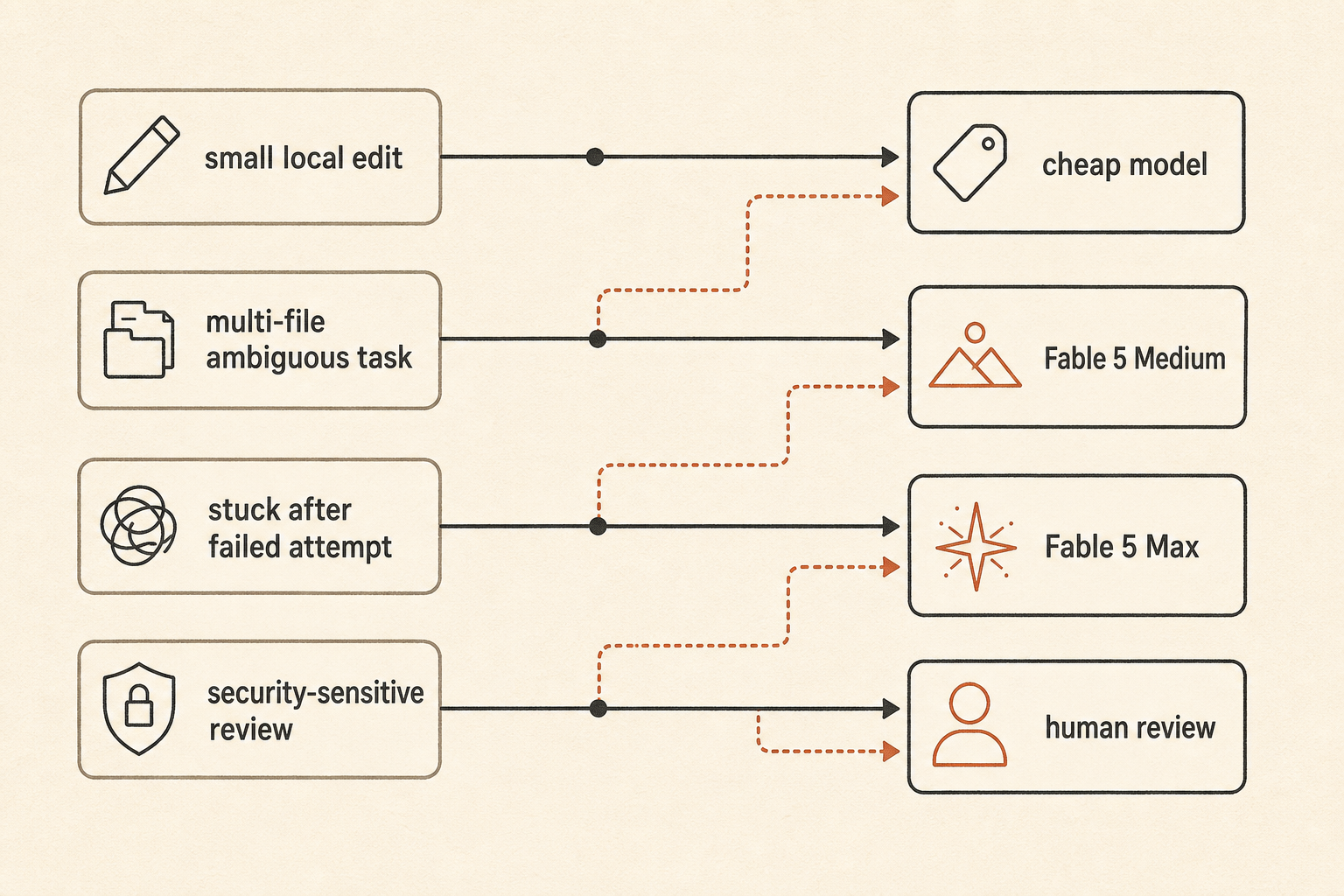
A practical routing policy looks like this:
default: fast/cheap model for local edits and small bugs
escalate: Fable 5 Medium for ambiguous multi-file work
reserve: Fable 5 Max for high-risk refactors, stuck tasks, and final review
fallback: human review when the agent starts exploring instead of editingThat is less exciting than “use the best model.” It is also how teams avoid waking up to a token bill that looks like a cloud incident.
The Benchmark Has an Availability Asterisk
There is one messy current-events wrinkle: Fable 5’s release week did not stay quiet.
On June 12, Anthropic published a statement saying the U.S. government had issued an export-control directive to suspend access to Fable 5 and Mythos 5 by foreign nationals, including foreign-national Anthropic employees; Anthropic said the only immediate way to comply was to disable the models for all customers (Anthropic). The company said other Claude models were not affected.
For benchmark interpretation, this does not erase the CursorBench result. The leaderboard is still useful evidence about model capability under Cursor’s agent harness. But for procurement and workflow design, availability is not a footnote. If your team standardizes on a model that can disappear because of capacity, policy, or safety gating, you need a fallback path.
That is another reason not to wire Fable 5 Max into every task. The best engineering setup is model-portable:
- prompts that do not depend on one provider’s quirks
- small enough task boundaries that a second model can retry
- evals on your own repo, not just public leaderboards
- cost logs per task, not just monthly invoices
- a human escalation point for dangerous diffs
Benchmarks tell you where to start. Your repo tells you what to ship.
My Take: Use Fable 5 Like a Senior Reviewer, Not a Default Autocomplete
Fable 5 Max deserves the top spot on CursorBench 3.1. A 72.9% score on ambiguous, multi-file Cursor tasks is exactly the kind of signal developers should care about. It beats GPT-5.5 Extra High and Opus 4.8 Max by enough that the result should change model-selection habits.
But the wrong lesson is “always use Max.”
The right lesson is narrower: Fable 5 is worth paying for when ambiguity is the bottleneck. Architecture migrations, cross-file bugs, failing test suites with unclear ownership, subtle review passes, and “I need the agent to form a plan before touching code” are good fits. Routine CRUD edits, obvious test fixes, formatting cleanup, and one-file refactors are not.
If you want the practical default from this leaderboard, start with this:
- Composer 2.5 for cheap, good-enough routine agent work.
- GPT-5.5 Extra High when you want a strong score at much lower cost than Fable Max.
- Fable 5 Medium as the serious daily-driver candidate.
- Fable 5 Max for escalation, not background noise.
- Retest Opus 4.8 Max in your workflow; CursorBench makes it hard to justify as the default.
The Fable 5 headline is 72.9%. The engineering lesson is routing.
The teams that win with these models will not be the ones that always pick the biggest model. They will be the ones that know exactly when the biggest model is cheap.
Readers who want to try Claude Fable 5 themselves can use it through OneHop: Claude Fable 5 on OneHop, a drop-in endpoint priced around 30% under list. New accounts get $10 free, no card required.
Further reading: Getting started with Claude Fable 5.

