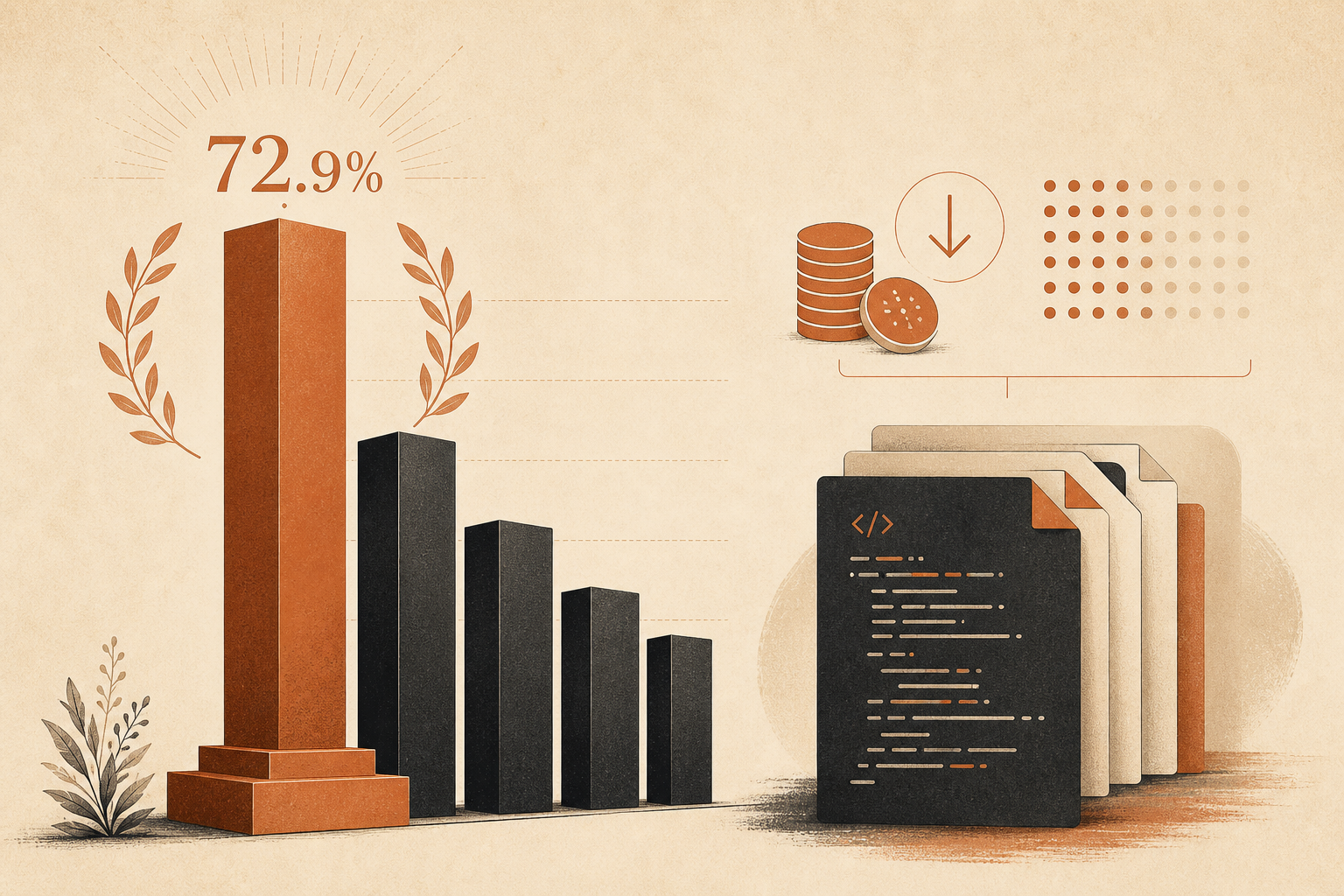
Claude Fable 5 não entrou de fininho no ranking. Ele pousou direto no topo.
A página ao vivo do CursorBench 3.1 da Cursor agora coloca o Fable 5 Max em 72,9% com um custo médio de US$ 18,02 por tarefa, à frente do GPT-5.5 Extra High com 64,3% / US$ 4,37 e do Opus 4.8 Max com 63,8% / US$ 7,59 (Cursor). É uma diferença grande de qualidade em um benchmark construído em cima de sessões reais no Cursor, não de quebra-cabeças algorítmicos de brinquedo.
Também é caro. Dolorosamente caro se você roda agentes o dia inteiro.
É por isso que o debate atual sobre Claude Code e Cursor não é “Fable 5 é bom?” O ranking já respondeu isso. A pergunta melhor é: quando uma vantagem de 8 a 9 pontos justifica uma conta 2x a 4x maior?
Minha resposta: Fable 5 é o modelo para o qual você escala, não o modelo que deixa ligado no automático para toda edição. O resultado interessante não é só o Fable 5 Max vencer. É que Fable 5 Medium e Low talvez sejam a história mais prática.
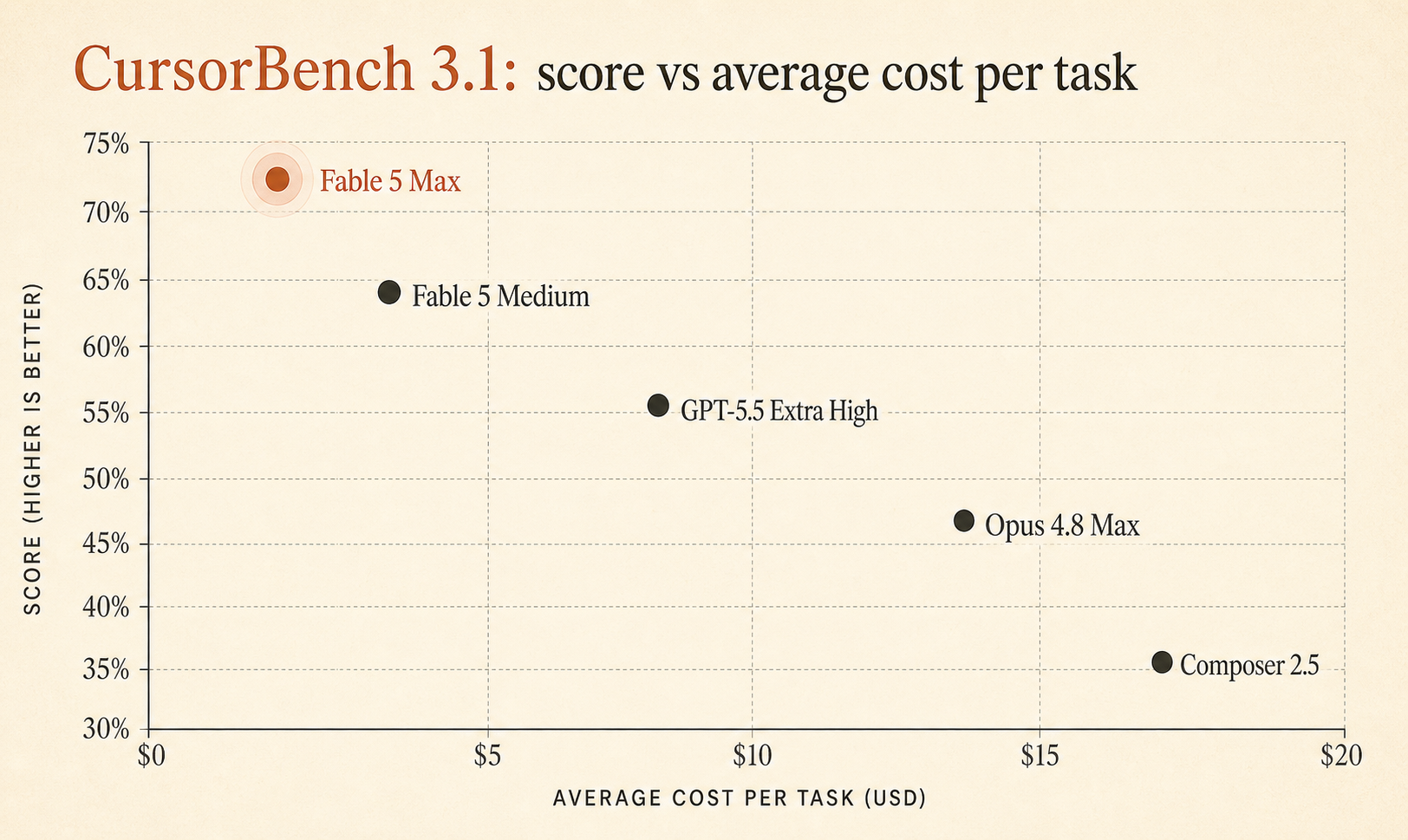
O Que o CursorBench 3.1 Realmente Mede
A Cursor descreve o CursorBench 3.1 como uma avaliação de “tarefas ambíguas, com múltiplos arquivos, vindas de sessões reais no Cursor”, em que uma pontuação maior é melhor (Cursor). Essa frase importa. A maior parte da frustração de desenvolvedores com agentes de programação não vem de falhas em estilo LeetCode de arquivo único. Vem da bagunça real:
- entender a estrutura de um repositório
- decidir quais arquivos importam
- planejar uma edição que atravessa fronteiras
- encontrar bugs sem receber direção demais
- revisar código sem alucinar um problema falso
- manter contexto vivo tempo suficiente para terminar
O CursorBench 3.1 adicionou problemas focados em compreensão de base de código, descoberta de bugs, planejamento e revisão de código, além de melhorar os critérios de avaliação para algumas tarefas de edição (Cursor). O texto mais longo da Cursor sobre o benchmark diz que a suíte foi feita para separar modelos de fronteira em um momento em que benchmarks públicos estão cada vez mais saturados, e que a Cursor acompanha sinais de produto online junto com notas offline (Cursor blog).
Isso não o torna perfeito. Ainda é a avaliação de um fornecedor, rodada dentro do harness de agente de um produto, com uma distribuição específica de tarefas. A Cursor também avisa que pequenas diferenças de pontuação podem não ser estatisticamente significativas (Cursor). Então, não, você não deve tratar uma diferença de 0,6 ponto como verdade sagrada.
Mas o Fable 5 Max não está vencendo por 0,6 ponto. Ele está à frente do GPT-5.5 Extra High por 8,6 pontos e do Opus 4.8 Max por 9,1 pontos. É grande o bastante para levar a sério.
Aqui está o recorte compacto do ranking que importa para escolhas do dia a dia em agentes de programação:
| Modelo / configuração | Pontuação no CursorBench 3.1 | Custo méd. / tarefa | Tokens / tarefa | Etapas / tarefa |
|---|---|---|---|---|
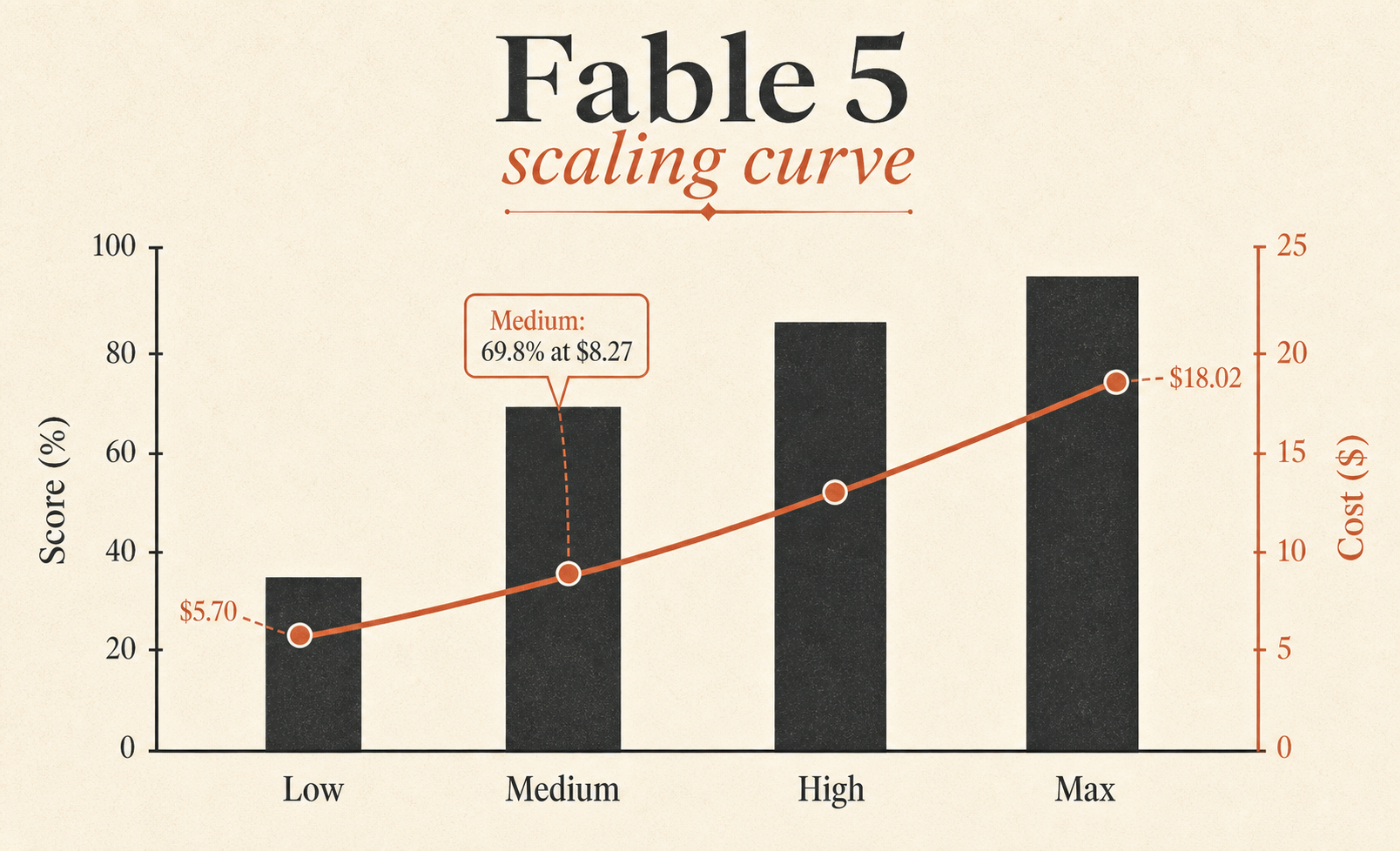
| Fable 5 Max | 72.9% | $18.02 | 63,842 | 76 |
| Fable 5 Extra High | 72.0% | $13.74 | 48,754 | 63 |
| Fable 5 High | 70.6% | $10.81 | 37,173 | 54 |
| Fable 5 Medium | 69.8% | $8.27 | 28,507 | 47 |
| Opus 4.7 Max | 64.8% | $11.02 | 62,989 | 96 |
| GPT-5.5 Extra High | 64.3% | $4.37 | 17,905 | 46 |
| Fable 5 Low | 64.2% | $5.70 | 18,882 | 36 |
| Opus 4.8 Max | 63.8% | $7.59 | 77,370 | 60 |
| Composer 2.5 | 63.2% | $0.55 | 15,152 | 37 |
A Cursor diz que o custo médio por tarefa é calculado aplicando o preço publicado de cada modelo por milhão de tokens, incluindo tokens de entrada, leitura de cache, escrita de cache e saída, aos tokens usados em cada tarefa do CursorBench, e depois tirando a média entre as tarefas (Cursor). Esse é o enquadramento certo. Agentes não são precificados por sensação. São precificados pelo quanto leem, reescrevem, tentam de novo e explicam.
O Vencedor É Fable 5. O Vencedor em Valor, Não.
Fable 5 Max vence em pontuação bruta. Sem malabarismo.
Mas a visão de desempenho por dólar é brutal:
| Modelo / configuração | Pontuação | Custo | Pontos de pontuação por US$ 1 |
|---|---|---|---|
| Fable 5 Max | 72.9% | $18.02 | 4.0 |
| Fable 5 Medium | 69.8% | $8.27 | 8.4 |
| GPT-5.5 Extra High | 64.3% | $4.37 | 14.7 |
| Opus 4.8 Max | 63.8% | $7.59 | 8.4 |
| Composer 2.5 | 63.2% | $0.55 | 114.9 |
A última linha é o motivo de a discussão na comunidade estar pegando fogo. Composer 2.5 não chega perto do Fable 5 Max em qualidade absoluta, mas fica próximo do GPT-5.5 Extra High e do Opus 4.8 Max nesse ranking custando centavos em comparação. Se você roda centenas de tarefas de agente por semana, isso importa mais do que a coroa do ranking.
A conta marginal é mais clara:
Fable 5 Max vs GPT-5.5 Extra High:
+8.6 score points, +$13.65/task
≈ $1.59 per extra score pointContra o Opus 4.8 Max:
Fable 5 Max vs Opus 4.8 Max:
+9.1 score points, +$10.43/task
≈ $1.15 per extra score pointPara uma migração cabeluda, US$ 10 a US$ 14 a mais é ruído. Se o modelo evita uma tentativa fracassada, ele se pagou. Para uma equipe rodando agentes em segundo plano em todo pull request, atualização de dependência, falha de lint e conserto de teste, esse adicional vira política de orçamento.
A linha mais subestimada é Fable 5 Medium. Ele marca 69,8%, apenas 3,1 pontos atrás do Fable 5 Max, por US$ 8,27 em vez de US$ 18,02. Em outras palavras, o Medium mantém cerca de 96% da pontuação de benchmark do Max por cerca de 46% do custo por tarefa do Max. Se você quer um Fable como padrão, é para essa linha que deve olhar.
O Debate da Comunidade É Mesmo Sobre Queima de Tokens
As threads ao vivo não são sutis. Em uma thread de lançamento no subreddit do Cursor, as primeiras impressões de um usuário foram que o Fable 5 mostrava raciocínio muito detalhado e um plano ambicioso, mas também era “muito lento”, com estranhezas de conectividade esperadas conforme a demanda disparava (Reddit r/cursor). Isso bate com o ranking: Fable 5 Max usa 63.842 tokens por tarefa e 76 etapas por tarefa. Não é um modelo reflexo e leve.
Em uma thread do ClaudeAI sobre o resultado no CursorBench, a reação veio rápido: um comentarista chamou de “não é um benchmark legítimo”, enquanto outro perguntou imediatamente se não havia “nenhuma razão para usar opus então se fable medium é mais barato”, e uma resposta apontou para o Composer 2.5 como “muito barato e bom” (Reddit r/ClaudeAI). Esse é o corte certo: confiança no benchmark, deslocamento do Opus e alternativas baratas-boas-o-suficiente.
Uma thread do ClaudeCode chegou ainda mais perto da questão operacional. O post original notou que Fable 5 Low é mais inteligente e mais barato que Opus 4.8 Max no CursorBench, e os comentários se concentraram em custo por tarefa e eficiência de tokens. Um comentário resumiu bem: para desenvolvedores independentes e freelancers, custo por tarefa e pontuação relativa são os benchmarks importantes, porque produtividade em breve pode ser julgada pelo consumo de tokens (Reddit r/ClaudeCode).
Essa afirmação fecha com a tabela.
Fable 5 Low:
- 64.2%
- $5.70
- 18,882 tokens
Opus 4.8 Max:
- 63.8%
- $7.59
- 77,370 tokens
Então, no CursorBench 3.1, Fable 5 Low fica ligeiramente à frente do Opus 4.8 Max, custa US$ 1,89 a menos por tarefa e usa cerca de 76% menos tokens. Isso não é uma notinha de rodapé. É uma decisão de produto.
Se você ainda usa Opus 4.8 Max como sua configuração “Claude sério” dentro do Cursor, o benchmark diz que você deve testar Fable 5 Low e Medium imediatamente. Não porque todo repositório vá bater com o mix de tarefas da Cursor. Mas porque o ônus da prova mudou de lado.
O Preço da Anthropic Explica o Susto
A Anthropic lançou Claude Fable 5 e Claude Mythos 5 em 9 de junho de 2026, descrevendo modelos da classe Mythos como um nível acima do Opus. No post de lançamento da Anthropic, Fable 5 é o lançamento geral, enquanto Mythos 5 é o mesmo modelo subjacente com algumas salvaguardas removidas para uso restrito com acesso confiável (Anthropic).
O preço da API é simples e alto: US$ 10 por milhão de tokens de entrada e US$ 50 por milhão de tokens de saída tanto para Fable 5 quanto para Mythos 5 (Anthropic). A Anthropic também disse que Fable 5 estava disponível pela Claude API como claude-fable-5, e que o acesso por planos de assinatura seria incluído apenas temporariamente até 22 de junho, a menos que a capacidade permitisse uma extensão (Anthropic).
Esse preço muda como você deve pensar sobre prompts de agentes.
Com modelos baratos, contexto relaxado é tolerável. Você cola coisa demais, pede uma mudança ampla demais, deixa o agente vagar, e a conta é irritante, mas administrável. Com custos no nível do Fable 5 Max, um harness mal desenhado fica visível. Cada arquivo desnecessário, plano repetido, resultado de ferramenta verboso e tentativa de patch fracassada se acumula.
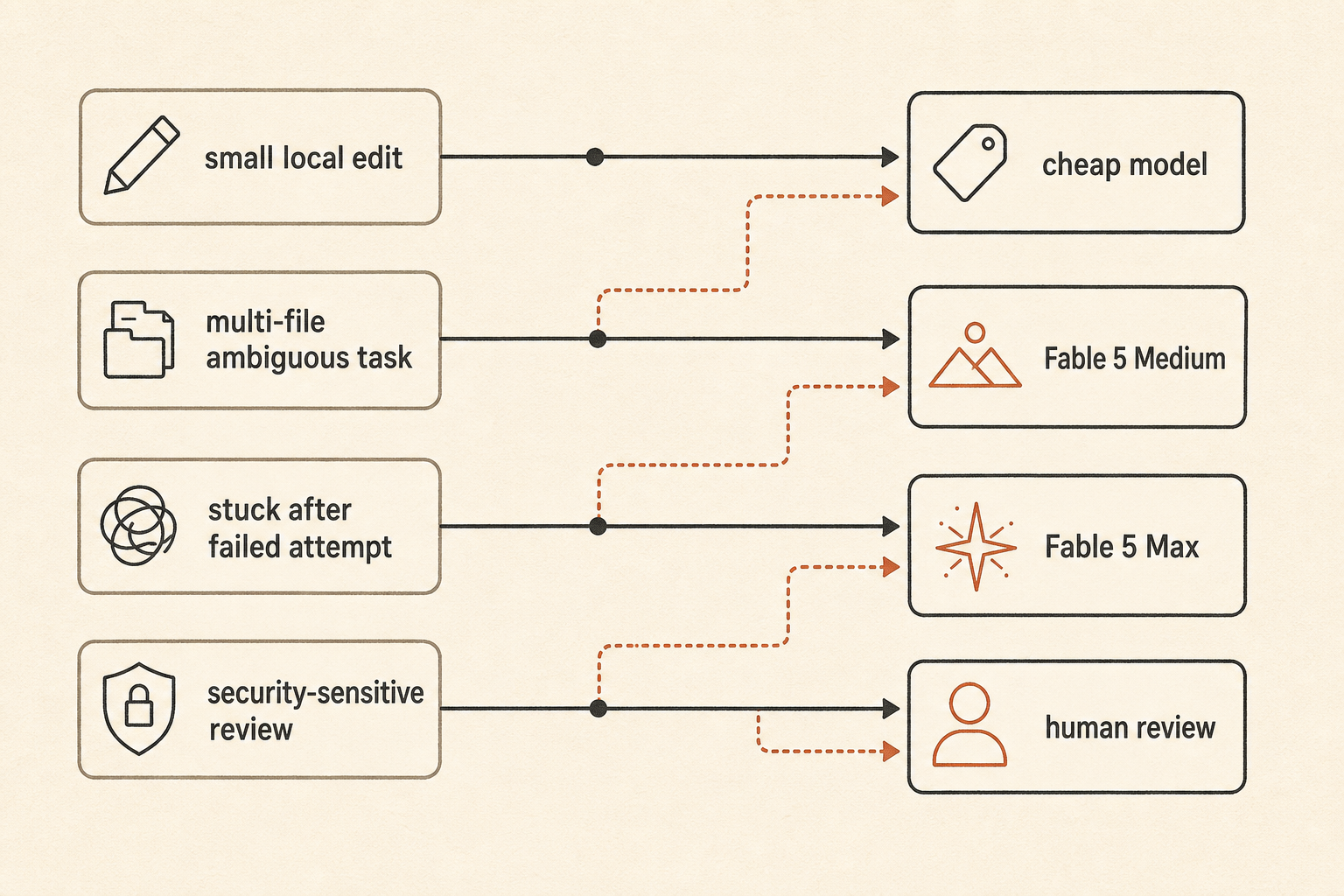
Uma política prática de roteamento fica assim:
default: fast/cheap model for local edits and small bugs
escalate: Fable 5 Medium for ambiguous multi-file work
reserve: Fable 5 Max for high-risk refactors, stuck tasks, and final review
fallback: human review when the agent starts exploring instead of editingIsso é menos empolgante do que “use o melhor modelo”. Também é assim que equipes evitam acordar com uma conta de tokens parecida com um incidente de cloud.
O Benchmark Tem um Asterisco de Disponibilidade
Há uma complicação de atualidade: a semana de lançamento do Fable 5 não ficou tranquila.
Em 12 de junho, a Anthropic publicou uma declaração dizendo que o governo dos EUA havia emitido uma diretriz de controle de exportação para suspender o acesso ao Fable 5 e ao Mythos 5 por estrangeiros, incluindo funcionários estrangeiros da Anthropic; a Anthropic disse que a única forma imediata de cumprir a diretriz era desativar os modelos para todos os clientes (Anthropic). A empresa disse que outros modelos Claude não foram afetados.
Para interpretar o benchmark, isso não apaga o resultado do CursorBench. O ranking continua sendo uma evidência útil sobre a capacidade do modelo no harness de agente da Cursor. Mas, para compras e desenho de workflow, disponibilidade não é nota de rodapé. Se sua equipe padroniza em um modelo que pode desaparecer por capacidade, política ou filtros de segurança, você precisa de um caminho de fallback.
Esse é mais um motivo para não ligar o Fable 5 Max em toda tarefa. A melhor configuração de engenharia é portável entre modelos:
- prompts que não dependem das manias de um provedor
- limites de tarefa pequenos o suficiente para um segundo modelo tentar de novo
- avaliações no seu próprio repositório, não só em rankings públicos
- logs de custo por tarefa, não só faturas mensais
- um ponto de escalação humana para diffs perigosos
Benchmarks dizem por onde começar. Seu repositório diz o que mandar para produção.
Minha Leitura: Use Fable 5 Como um Revisor Sênior, Não Como Autocomplete Padrão
Fable 5 Max merece o topo do CursorBench 3.1. Uma pontuação de 72,9% em tarefas ambíguas, com múltiplos arquivos, no Cursor é exatamente o tipo de sinal com que desenvolvedores deveriam se importar. Ele vence GPT-5.5 Extra High e Opus 4.8 Max por margem suficiente para mudar hábitos de seleção de modelos.
Mas a lição errada é “use sempre o Max”.
A lição certa é mais estreita: vale a pena pagar pelo Fable 5 quando a ambiguidade é o gargalo. Migrações de arquitetura, bugs entre arquivos, suítes de teste quebradas sem dono claro, revisões sutis e “preciso que o agente forme um plano antes de tocar no código” são bons encaixes. Edições CRUD rotineiras, correções óbvias de teste, limpeza de formatação e refatorações de um arquivo só, não.
Se você quer o padrão prático a partir deste ranking, comece assim:
- Composer 2.5 para trabalho rotineiro de agente barato e bom o suficiente.
- GPT-5.5 Extra High quando quiser uma pontuação forte por custo muito menor que o Fable Max.
- Fable 5 Medium como candidato sério a modelo de uso diário.
- Fable 5 Max para escalação, não para ruído de fundo.
- Teste novamente o Opus 4.8 Max no seu workflow; o CursorBench torna difícil justificá-lo como padrão.
A manchete do Fable 5 é 72,9%. A lição de engenharia é roteamento.
As equipes que vencerem com esses modelos não serão as que sempre escolhem o maior modelo. Serão as que sabem exatamente quando o maior modelo sai barato.
Leitores que quiserem testar Claude Fable 5 podem usá-lo pela OneHop: Claude Fable 5 on OneHop, um endpoint drop-in com preço cerca de 30% abaixo da tabela. Novas contas recebem $10 free, sem cartão.
Leitura complementar: Getting started with Claude Fable 5.

