لم يتسلل Claude Fable 5 إلى لوحة الصدارة خلسة. بل هبط مباشرة في القمة.
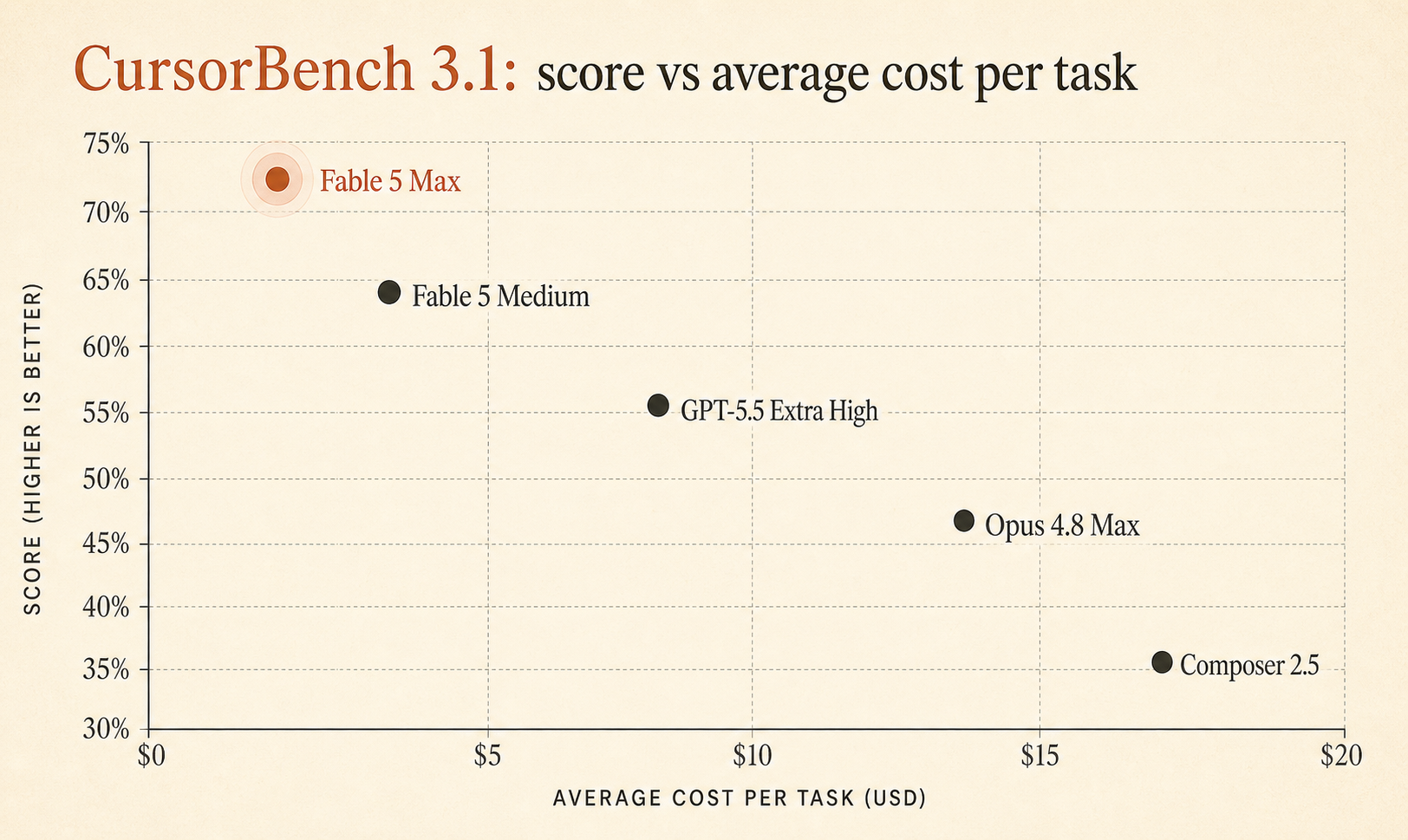
صفحة CursorBench 3.1 الحية لدى Cursor تضع الآن Fable 5 Max عند 72.9% مع متوسط تكلفة $18.02 لكل مهمة، متقدمًا على GPT-5.5 Extra High عند 64.3% / $4.37 و Opus 4.8 Max عند 63.8% / $7.59 (Cursor). هذه فجوة جودة كبيرة في اختبار مبني على جلسات Cursor حقيقية، لا على ألغاز خوارزميات مدرسية.
وهو مكلف أيضًا. مكلف بشكل مؤلم إذا كنت تشغّل الوكلاء طوال اليوم.
لهذا فإن جدل Claude Code وCursor الحالي ليس: “هل Fable 5 جيد؟” لوحة الصدارة أجابت عن ذلك. السؤال الأفضل هو: متى يبرر فوز بفارق 8 إلى 9 نقاط فاتورة أعلى بمرتين إلى أربع مرات؟
إجابتي: Fable 5 هو النموذج الذي تصعّد إليه، لا النموذج الذي تتركه يعمل عشوائيًا على كل تعديل. النتيجة المثيرة ليست فقط أن Fable 5 Max يفوز. بل أن Fable 5 Medium وLow قد يكونان القصة الأكثر عملية.
ما الذي يقيسه CursorBench 3.1 فعلًا
تصف Cursor اختبار CursorBench 3.1 بأنه تقييم لـ “مهام غامضة متعددة الملفات من جلسات Cursor حقيقية”، حيث تعني الدرجة الأعلى أداء أفضل (Cursor). هذه العبارة مهمة. معظم إحباط المطورين من وكلاء البرمجة لا يأتي من إخفاقات LeetCode أحادية الملف. بل يأتي من الفوضى الحقيقية:
- فهم بنية المستودع
- تحديد الملفات المهمة
- التخطيط لتعديل يعبر حدود الملفات
- العثور على الأخطاء من دون توجيه زائد
- مراجعة الكود من دون اختلاق مشكلة وهمية
- الحفاظ على السياق فترة كافية لإنهاء العمل
أضاف CursorBench 3.1 مسائل تركّز على فهم قواعد الكود، واكتشاف الأخطاء، والتخطيط، ومراجعة الكود، وحسّن معايير التقييم لبعض مهام التحرير (Cursor). وتقول تدوينة Cursor الأطول عن الاختبار إن الحزمة صُممت للتمييز بين نماذج frontier في وقت أصبحت فيه الاختبارات العامة مشبعة أكثر فأكثر، وإن Cursor يتابع إشارات المنتج الحية إلى جانب الدرجات غير المتصلة (Cursor blog).
هذا لا يجعله مثاليًا. ما زال تقييمًا من بائع واحد، داخل حاضنة وكيل لمنتج واحد، وبتوزيع مهام واحد. وتحذر Cursor أيضًا من أن الفروق الصغيرة في الدرجات قد لا تكون ذات دلالة إحصائية (Cursor). لذلك لا، لا ينبغي أن تعامل فارق 0.6 نقطة كأنه وحي.
لكن Fable 5 Max لا يفوز بفارق 0.6 نقطة. إنه يتقدم على GPT-5.5 Extra High بـ 8.6 نقاط وعلى Opus 4.8 Max بـ 9.1 نقاط. هذا فارق كبير بما يكفي لأخذه بجدية.
إليك القصاصة المختصرة من لوحة الصدارة التي تهم اختيارات وكلاء البرمجة اليومية:
| النموذج / الإعداد | درجة CursorBench 3.1 | متوسط التكلفة / المهمة | الرموز / المهمة | الخطوات / المهمة |
|---|---|---|---|---|
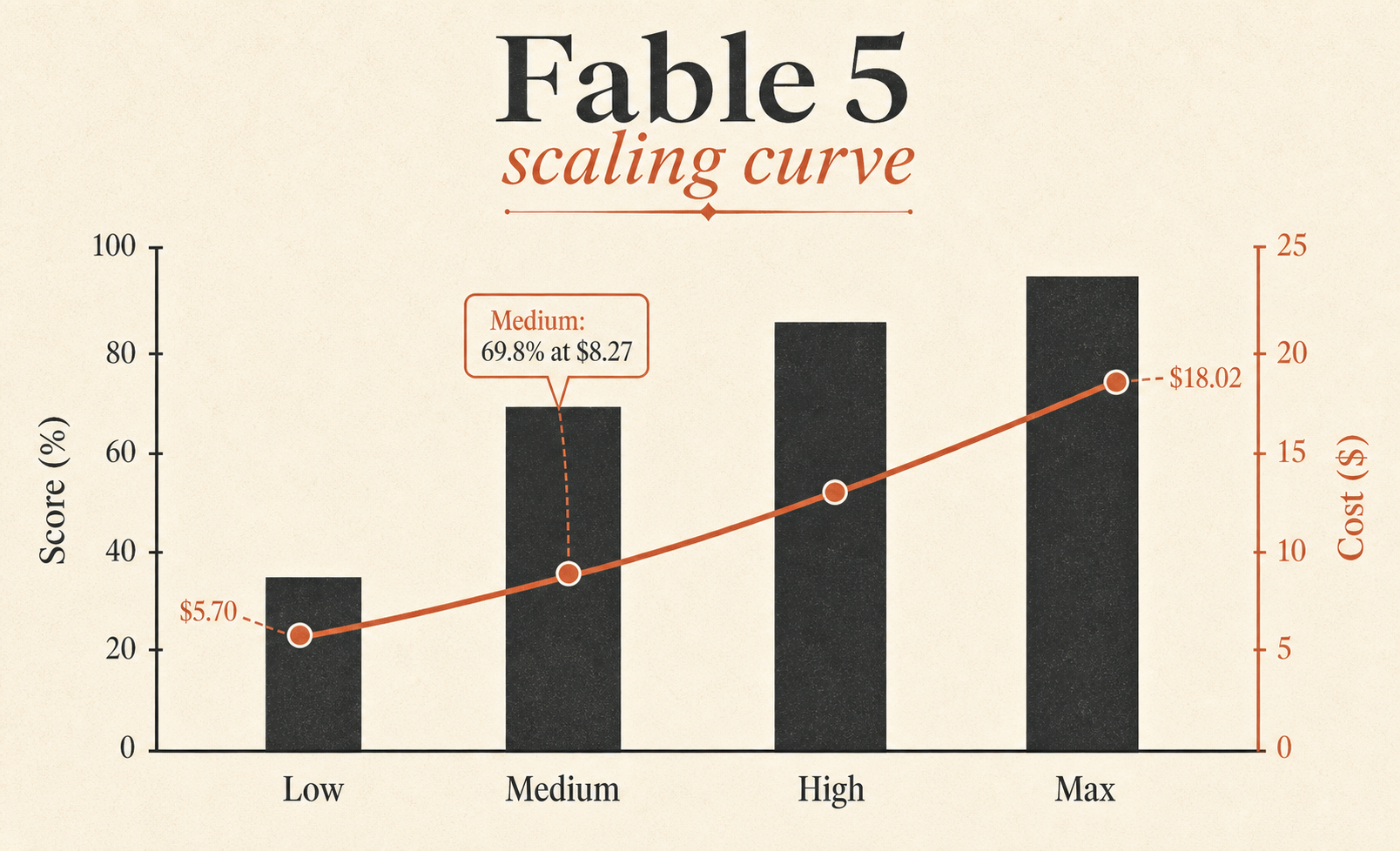
| Fable 5 Max | 72.9% | $18.02 | 63,842 | 76 |
| Fable 5 Extra High | 72.0% | $13.74 | 48,754 | 63 |
| Fable 5 High | 70.6% | $10.81 | 37,173 | 54 |
| Fable 5 Medium | 69.8% | $8.27 | 28,507 | 47 |
| Opus 4.7 Max | 64.8% | $11.02 | 62,989 | 96 |
| GPT-5.5 Extra High | 64.3% | $4.37 | 17,905 | 46 |
| Fable 5 Low | 64.2% | $5.70 | 18,882 | 36 |
| Opus 4.8 Max | 63.8% | $7.59 | 77,370 | 60 |
| Composer 2.5 | 63.2% | $0.55 | 15,152 | 37 |
تقول Cursor إن متوسط التكلفة لكل مهمة يُحسب بتطبيق أسعار كل نموذج المنشورة لكل مليون رمز، بما في ذلك رموز الإدخال وقراءة الكاش وكتابة الكاش والإخراج، على الرموز المستخدمة في كل مهمة من CursorBench، ثم حساب المتوسط عبر المهام (Cursor). هذا هو الإطار الصحيح. الوكلاء لا تُسعّر بالمزاج. تُسعّر بقدر ما تقرأ، وتعيد الكتابة، وتحاول مرة أخرى، وتشرح.
الفائز هو Fable 5. لكن الفائز بالقيمة ليس هو.
يفوز Fable 5 Max في الدرجة الخام. لا يحتاج الأمر إلى تدوير.
لكن منظور الأداء مقابل الدولار قاسٍ:
| النموذج / الإعداد | الدرجة | التكلفة | نقاط الدرجة لكل $1 |
|---|---|---|---|
| Fable 5 Max | 72.9% | $18.02 | 4.0 |
| Fable 5 Medium | 69.8% | $8.27 | 8.4 |
| GPT-5.5 Extra High | 64.3% | $4.37 | 14.7 |
| Opus 4.8 Max | 63.8% | $7.59 | 8.4 |
| Composer 2.5 | 63.2% | $0.55 | 114.9 |
الصف الأخير هو سبب سخونة نقاش المجتمع. Composer 2.5 ليس قريبًا من Fable 5 Max في الجودة المطلقة، لكنه قريب من GPT-5.5 Extra High وOpus 4.8 Max على هذه اللوحة، بينما يكلف قروشًا بالمقارنة. إذا كنت تشغّل مئات مهام الوكلاء أسبوعيًا، فهذا أهم من تاج لوحة الصدارة.
الحساب الهامشي أوضح:
Fable 5 Max vs GPT-5.5 Extra High:
+8.6 score points, +$13.65/task
≈ $1.59 per extra score pointمقابل Opus 4.8 Max:
Fable 5 Max vs Opus 4.8 Max:
+9.1 score points, +$10.43/task
≈ $1.15 per extra score pointبالنسبة إلى ترحيل معقد واحد، زيادة $10 إلى $14 ضجيج لا يُذكر. إذا أنقذك النموذج من محاولة فاشلة واحدة، فقد دفع ثمنه. أما لفريق يشغّل وكلاء خلفية على كل pull request، وترقية اعتماديات، وفشل lint، وإصلاح اختبار، فهذه الزيادة تتحول إلى سياسة ميزانية.
أكثر صف مظلوم هو Fable 5 Medium. يسجل 69.8%، أي أقل من Fable 5 Max بـ 3.1 نقاط فقط، مقابل $8.27 بدلًا من $18.02. بمعنى آخر، يحتفظ Medium بنحو 96% من درجة Max في الاختبار عند نحو 46% من تكلفة مهمة Max. إذا أردت Fable كنموذج افتراضي، فهذا هو الصف الذي يستحق التحديق.
جدل المجتمع هو في الحقيقة عن حرق الرموز
النقاشات الحية ليست مواربة. في موضوع إطلاق على subreddit الخاص بـ Cursor، كانت الانطباعات الأولى لأحد المستخدمين أن Fable 5 أظهر تفكيرًا مفصلًا جدًا وخطة طموحة، لكنه كان أيضًا “بطيئًا جدًا”، مع غرائب اتصال متوقعة مع ارتفاع الطلب (Reddit r/cursor). وهذا ينسجم مع لوحة الصدارة: يستخدم Fable 5 Max 63,842 رمزًا لكل مهمة و 76 خطوة لكل مهمة. إنه ليس نموذج رد فعل خفيف الوزن.
في نقاش على ClaudeAI حول نتيجة CursorBench، جاء الاعتراض سريعًا: وصفه أحد المعلقين بأنه “ليس اختبارًا شرعيًا”، بينما سأل آخر فورًا إن كان “لا يوجد سبب لاستخدام opus إذن إذا كان fable medium أرخص”، وأشار رد إلى أن Composer 2.5 “رخيص جدًا وجيد” (Reddit r/ClaudeAI). هذا هو الانقسام الصحيح: الثقة في الاختبار، إزاحة Opus، وبدائل رخيصة جيدة بما يكفي.
اقترب نقاش على ClaudeCode أكثر من المسألة التشغيلية. لاحظ المنشور الأصلي أن Fable 5 Low أذكى وأرخص من Opus 4.8 Max على CursorBench، وركز المعلقون على تكلفة المهمة وكفاءة الرموز. قال أحد التعليقات الأمر بصراحة: بالنسبة إلى المطورين المستقلين والعاملين الحرين، تكلفة المهمة والدرجة النسبية هما المعياران المهمان، لأن الإنتاجية قد تُقاس قريبًا باستهلاك الرموز (Reddit r/ClaudeCode).
هذا الادعاء يصمد أمام الجدول.
Fable 5 Low:
- 64.2%
- $5.70
- 18,882 رمزًا
Opus 4.8 Max:
- 63.8%
- $7.59
- 77,370 رمزًا
إذًا على CursorBench 3.1، يتقدم Fable 5 Low قليلًا على Opus 4.8 Max، ويكلف $1.89 أقل لكل مهمة، ويستخدم نحو 76% رموزًا أقل. هذه ليست ملاحظة هامشية صغيرة. هذا قرار منتج.
إذا كنت ما زلت تستخدم Opus 4.8 Max كإعداد “Claude الجاد” داخل Cursor، فالاختبار يقول إن عليك تجربة Fable 5 Low وMedium فورًا. ليس لأن كل مستودع سيطابق مزيج مهام Cursor. بل لأن عبء الإثبات انتقل.
تسعير Anthropic يفسر صدمة السعر
أطلقت Anthropic نموذجَي Claude Fable 5 وClaude Mythos 5 في 9 يونيو 2026، ووصفت نماذج فئة Mythos بأنها طبقة أعلى من Opus. في منشور الإطلاق لدى Anthropic، Fable 5 هو الإصدار العام، بينما Mythos 5 هو النموذج الأساسي نفسه مع رفع بعض القيود الوقائية لاستخدام محدود موثوق الوصول (Anthropic).
سعر API بسيط ومرتفع: $10 لكل مليون رمز إدخال و$50 لكل مليون رمز إخراج لكل من Fable 5 وMythos 5 (Anthropic). وقالت Anthropic أيضًا إن Fable 5 متاح عبر Claude API باسم claude-fable-5، وإن الوصول ضمن خطط الاشتراك كان مشمولًا مؤقتًا فقط حتى 22 يونيو ما لم تسمح السعة بالتمديد (Anthropic).
هذا التسعير يغيّر طريقة تفكيرك في مطالبات الوكلاء.
مع النماذج الرخيصة، يكون السياق الفوضوي مقبولًا. تلصق أكثر من اللازم، وتطلب تغييرًا واسعًا جدًا، وتترك الوكيل يتجول، فتكون الفاتورة مزعجة لكنها محتملة. مع تكاليف من فئة Fable 5 Max، يصبح تصميم الحاضنة السيئ مرئيًا. كل ملف غير ضروري، وخطة مكررة، ونتيجة أداة مطولة، ومحاولة patch فاشلة، يتراكم فوق الآخر.
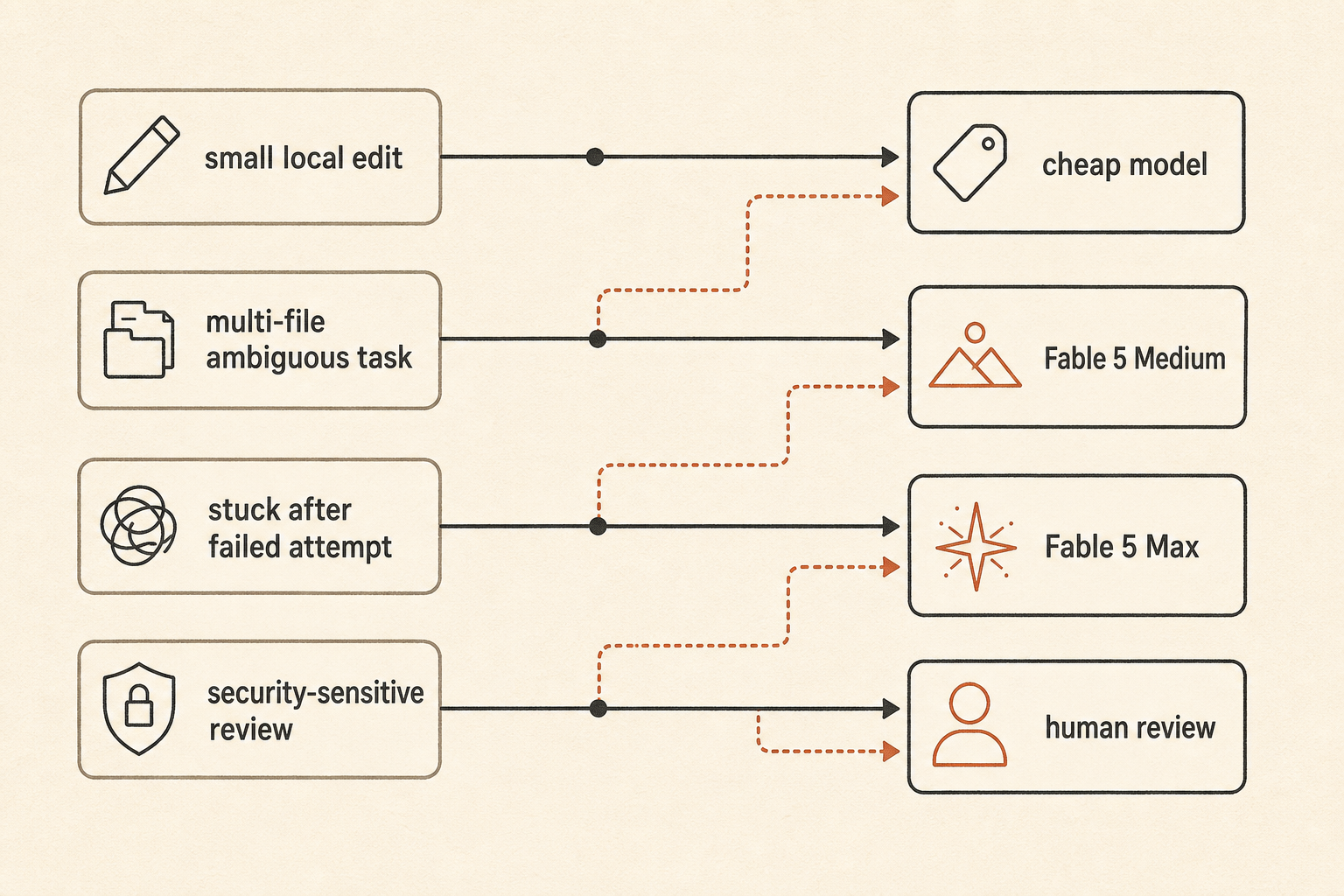
سياسة توجيه عملية تبدو هكذا:
default: fast/cheap model for local edits and small bugs
escalate: Fable 5 Medium for ambiguous multi-file work
reserve: Fable 5 Max for high-risk refactors, stuck tasks, and final review
fallback: human review when the agent starts exploring instead of editingهذا أقل إثارة من “استخدم أفضل نموذج”. وهو أيضًا الطريقة التي تتجنب بها الفرق الاستيقاظ على فاتورة رموز تبدو كحادث سحابي.
للاختبار نجمة تخص التوفر
هناك تعقيد راهن فوضوي واحد: أسبوع إطلاق Fable 5 لم يبق هادئًا.
في 12 يونيو، نشرت Anthropic بيانًا قالت فيه إن الحكومة الأمريكية أصدرت توجيهًا لضوابط التصدير يعلّق الوصول إلى Fable 5 وMythos 5 من قِبل الرعايا الأجانب، بما في ذلك موظفو Anthropic من الرعايا الأجانب؛ وقالت Anthropic إن الطريقة الفورية الوحيدة للامتثال كانت تعطيل النموذجين لكل العملاء (Anthropic). وقالت الشركة إن نماذج Claude الأخرى لم تتأثر.
بالنسبة إلى تفسير الاختبار، هذا لا يمحو نتيجة CursorBench. ما زالت لوحة الصدارة دليلًا مفيدًا على قدرة النموذج تحت حاضنة وكيل Cursor. لكن بالنسبة إلى الشراء وتصميم سير العمل، التوفر ليس هامشًا صغيرًا. إذا وحّد فريقك عمله على نموذج قد يختفي بسبب السعة أو السياسة أو بوابات السلامة، فأنت تحتاج إلى مسار بديل.
هذا سبب آخر لعدم توصيل Fable 5 Max بكل مهمة. أفضل إعداد هندسي هو إعداد قابل لنقل النماذج:
- مطالبات لا تعتمد على غرائب مزود واحد
- حدود مهام صغيرة بما يكفي كي يعيد نموذج ثانٍ المحاولة
- تقييمات على مستودعك أنت، لا على لوحات صدارة عامة فقط
- سجلات تكلفة لكل مهمة، لا فواتير شهرية فقط
- نقطة تصعيد بشرية للتغييرات الخطرة
تخبرك الاختبارات من أين تبدأ. ويخبرك مستودعك بما تشحنه.
رأيي: استخدم Fable 5 كمراجع خبير، لا كإكمال تلقائي افتراضي
يستحق Fable 5 Max المركز الأول على CursorBench 3.1. درجة 72.9% في مهام Cursor غامضة متعددة الملفات هي بالضبط نوع الإشارة التي ينبغي أن يهتم بها المطورون. إنه يتفوق على GPT-5.5 Extra High وOpus 4.8 Max بما يكفي لتغيير عادات اختيار النماذج.
لكن الدرس الخاطئ هو: “استخدم Max دائمًا.”
الدرس الصحيح أضيق: يستحق Fable 5 الدفع عندما يكون الغموض هو عنق الزجاجة. ترحيلات المعمارية، والأخطاء العابرة للملفات، وحِزم الاختبارات الفاشلة ذات الملكية غير الواضحة، ومراجعات الكود الدقيقة، وحالات “أحتاج الوكيل أن يشكّل خطة قبل لمس الكود” كلها تناسبه. أما تعديلات CRUD الروتينية، وإصلاحات الاختبارات الواضحة، وتنظيف التنسيق، وإعادة هيكلة ملف واحد، فلا.
إذا أردت الخيار الافتراضي العملي من لوحة الصدارة هذه، فابدأ بهذا:
- Composer 2.5 لعمل الوكلاء الروتيني الرخيص والجيد بما يكفي.
- GPT-5.5 Extra High عندما تريد درجة قوية بتكلفة أقل بكثير من Fable Max.
- Fable 5 Medium كمرشح جاد للاستخدام اليومي.
- Fable 5 Max للتصعيد، لا كضجيج خلفي.
- أعد اختبار Opus 4.8 Max في سير عملك؛ يجعل CursorBench تبريره كخيار افتراضي صعبًا.
عنوان Fable 5 هو 72.9%. الدرس الهندسي هو التوجيه.
الفرق التي ستفوز بهذه النماذج لن تكون تلك التي تختار دائمًا أكبر نموذج. بل تلك التي تعرف بالضبط متى يكون أكبر نموذج رخيصًا.
يمكن للقراء الذين يريدون تجربة Claude Fable 5 بأنفسهم استخدامه عبر OneHop: Claude Fable 5 on OneHop، نقطة نهاية drop-in بسعر أقل بنحو 30% من السعر الرسمي. الحسابات الجديدة تحصل على $10 مجانية، من دون بطاقة.
قراءة إضافية: بدء استخدام Claude Fable 5.

