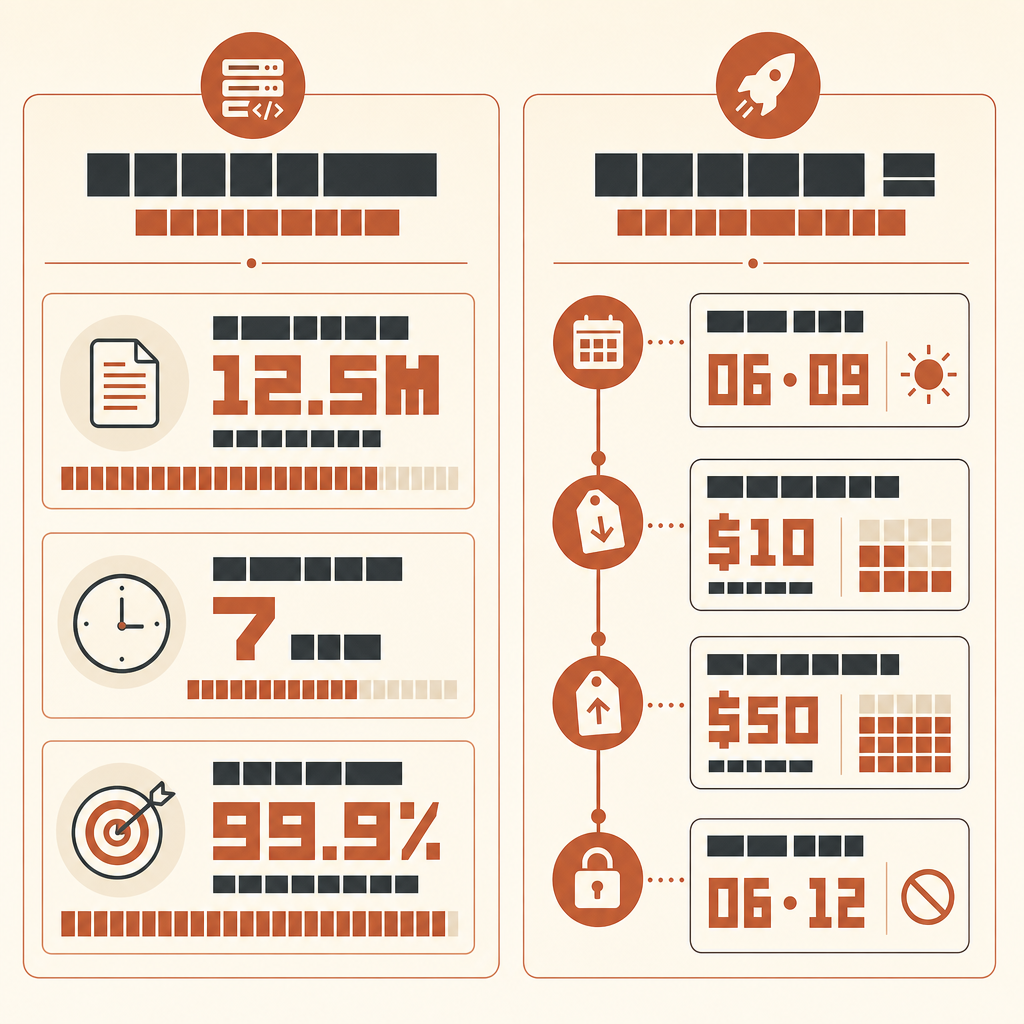
Rakuten 最有意思的 Claude Code 故事,不是 AI 寫了程式碼。而是它在一個 1,250 萬行、多語言的 vLLM 程式庫裡跑了七個小時,最後仍然交出了一個數字:相對於參考方法,數值準確率達到 99.9%。
這才是門檻。不是「感覺很有效率」。不是「diff 看起來合理」。而是有量測結果。
在 Anthropic 的 Rakuten 客戶案例中,機器學習工程師 Kenta Naruse 要 Claude Code 在 vLLM 中實作 activation vector extraction。Claude Code 在一次自主執行中完成任務;Naruse 表示,那七個小時裡他沒有寫程式碼,只偶爾給一點指引。這個實作相對於參考方法達到 99.9% 的數值準確率(Anthropic Rakuten case)。
這個故事出現的同時,開發者也正在爭論 Claude Code 和更新的 Fable 級模型是不是變得太主動了:探索太多、藏太多、改太多,或是自信地產出很難看見的 bug。正確答案不是「相信 agent」,也不是「永遠不要相信 agent」。正確答案是:把這次執行設計成一套工程系統。

案例:在大到不能「直接讀完」的程式庫中抽取 Activation Vectors
Activation vector extraction 聽起來範圍很窄,但在 vLLM 這樣的系統裡,它會跨過一堆尷尬邊界:模型執行、tensor shape、batching、分散式 runtime 假設、precision handling,以及對效能敏感的 code path。這正是 agent 能幫上忙的任務,也正是 agent 可能害慘你的任務。
Rakuten 這次執行厲害的地方不是七個小時。長時間執行的 agent 很容易啟動。厲害的是,這個任務有一個數值 oracle。
部落格文章版的任務可能會這樣寫:
Add activation vector extraction to vLLM.
正式生產版應該這樣寫:
Implement activation vector extraction for target model layers in vLLM, preserve existing inference behavior, add tests comparing extracted activations against a reference implementation, and fail the task unless relative/absolute error stays below the agreed threshold across representative prompts, batch sizes, dtypes, and devices.
這是兩種不同的工作。第一種會邀請一個看似合理的 diff。第二種會建立一個閉環。
Anthropic 自家的 Claude Code 文件也用更一般的方式講了同一件事:給 Claude 一個它可以執行的檢查,否則「看起來完成了」就會變成唯一的完成訊號(Claude Code best practices)。對 ML 基礎設施來說,這個檢查不能只是「unit tests pass」。它需要一個數值 oracle。
Rakuten 風格設定的精簡版看起來像這樣:
| 邊界 | 糟糕版本 | 較好版本 |
|---|---|---|
| 目標 | 「加入 activation extraction」 | 「從 X/Y 層抽取 activations,且 generation outputs 不變」 |
| Oracle | 「測試通過」 | 「跨 dtype、batch、sequence length 比對 tensors 與參考結果」 |
| 自主性 | 「跑到完成」 | 「跑到 oracle 通過,遇到 scope expansion 就停」 |
| Review | 「讀最後的 diff」 | 「檢查被碰到的子系統、tensor 語意、效能影響」 |
| Rollback | 「壞了就 git reset」 | 「每個 phase checkpoint、每次嘗試一個 branch、可 revert 的 commits」 |
社群抱怨的是對的事情
現在開發者的不安,不是反 AI 懷舊。主要是控制權問題。
在 Hacker News 上,一串關於 Claude Code 隱藏部分進度細節的討論,演變成更大的爭論:開發者到底需要看見什麼。一位留言者把有用的區分講得很好:原始內部推理不是重點;開發者需要的是可檢查的 tool calls、execution traces、failure modes,以及可重現的行為(Hacker News)。同串裡另一個抱怨更偏操作面:當 agent 跑去做很廣的探索時,使用者可能要燒掉 20 或 30 分鐘才發現它已經迷路。
Reddit 上有同一種抱怨的更尖銳版本。在一個 ClaudeAI 討論串中,有使用者把真正耗時間的東西形容成「silent fake success」:agent 不是修掉失敗路徑,而是加上 fallback behavior,讓程式碼看起來能動(Reddit)。另一個 Fable 5 討論裡,使用者分成兩派:「它修掉了 Opus 卡住的問題」和「它產出額外程式碼,還漏掉 edge cases」(Reddit)。
現在也有研究開始替這種擔憂放上數字。一篇 2026 年 5 月關於過度積極 coding agents 的 preprint 報告指出,在配對情境中,移除明確同意宣告後,Claude Code 的 overeager-action rate 從 0.0% 上升到 17.1%(arXiv)。你不必把它當成通用 benchmark,也該認真看待其中教訓:自主性高度取決於 harness 和指令。
錯誤的做法是爭論模型到底「好」或「壞」。有用的問題是:你有沒有替 agent 做一個盒子,讓它的主動性在盒子裡有產值,而跑到盒子外就會付出代價?
我會使用的長任務 Harness
對 vLLM 等級的任務,我不會一開始就讓 Claude Code 進入 edit mode。我會先寫 runbook。
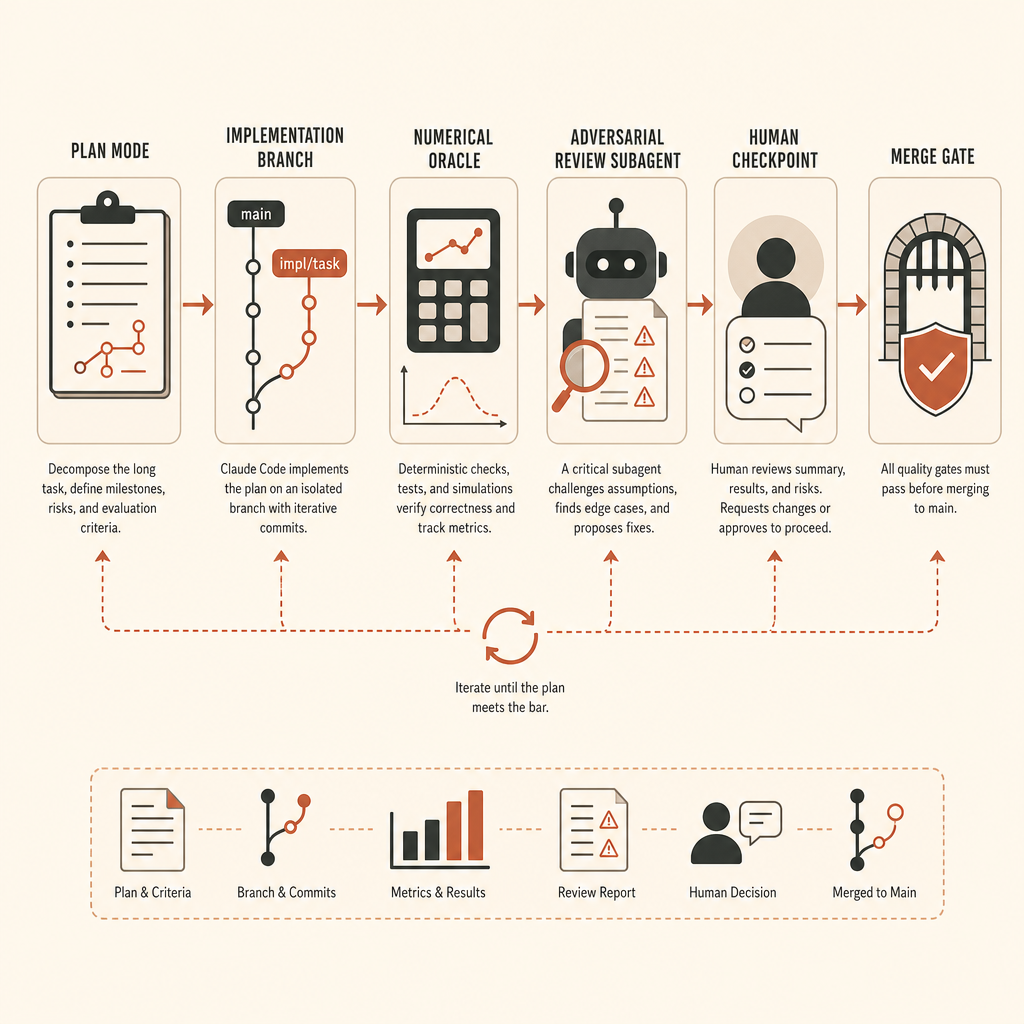
第一,建立 branch 並凍結環境。Pin 住 vLLM commit、CUDA/PyTorch 版本、model fixture、seeds,以及測試硬體假設。如果目標需要 GPU,就記錄 oracle 使用的確切 GPU class。如果 CPU fallback 只允許用於 shape tests,就明講。
第二,在實作前先定義 oracle。對 activation extraction 來說,這代表一條參考路徑和一支 comparison script。確切 threshold 取決於 dtype 和 operation order,但它應該在 agent 開始前就寫下來。不要在看過 diff 之後才協商準確率。
第三,把探索和實作分開。Claude 的文件建議「先探索,再規劃,再寫 code」,並在編輯前使用 plan mode(Claude Code best practices)。在大型 ML repo 裡,這不是儀式。它能避免 agent 解錯 abstraction layer。
好的初始 prompt 很無聊,而且很嚴格:
You are working in a fresh branch. Do not edit files yet.
Goal: implement activation vector extraction in vLLM for specified transformer layers without changing normal generation outputs.
First phase only:
1. Map the relevant execution path for model forward, batching, and tensor return plumbing.
2. Identify the smallest integration point.
3. Propose a test oracle comparing extracted activations to a reference implementation.
4. List files likely to change and files that must not change.
5. Stop and wait for review.
Do not implement until I approve the plan.Review 之後,實作 prompt 應該帶上停止條件:
Implement the approved plan.
Hard constraints:
- Do not change public generation behavior unless required by the plan.
- Do not add broad fallback paths that mask extraction failures.
- Do not change unrelated scheduling, sampling, or cache logic.
- Add tests for batch size 1 and >1, at least two sequence lengths, and supported dtypes.
- Run the oracle and report exact max_abs_error and max_rel_error.
- If the oracle cannot run, stop and explain the blocker. Do not mark success.最後一行很重要。它會擋住「fake success」模式。
Checkpoints 不是可有可無
Claude Code 有自己的 checkpoint 和 rewind 工作流程:每個 prompt 都會建立 checkpoint,而 /rewind 可以還原對話、程式碼,或兩者。文件也講得很清楚:這不是 git 的替代品(Claude Code best practices)。把它當成本地 undo layer,不要當成你的安全模型。
對長時間自主執行來說,我要四個 rollback boundaries:
baseline:乾淨 repo、dependency lock、已知會通過的測試。oracle-only:reference comparison script 和 fixtures,沒有 product code。minimal-hook:最小 extraction path,可能很醜,但 oracle 開始通過。production-shape:整理過的 API、文件、測試、review 修正。
agent 可以在 boundary 內快速移動。它不該無聲無息跨過 boundary。
很多團隊就是在這裡出錯。他們讓 agent 把研究、實作、重構、修測試和清理全都揉成一個巨大 diff。最後 patch 可能通過測試,但沒人知道哪些行為是有意的。在 ML infra 裡,這很危險,因為 correctness bugs 可能很安靜:來自錯誤 layer 的 tensor、post-norm 值而不是 pre-norm、只傷到某個 backend 的 dtype cast、在 cache mutation 之後才複製的 activation。
一個實用技巧:在 prompt 裡要求「diff budget」。
Expected change shape:
- Add extraction plumbing in the model execution path.
- Add or extend tests under the relevant vLLM test area.
- Add minimal docs or example usage if there is an existing pattern.
Out of scope:
- Scheduler redesign
- Sampling changes
- KV cache refactors
- Broad API renames
- Performance rewrites如果 agent 碰了 out-of-scope 區域,你不用爭。直接 rewind。
真正重要的人類 Checkpoints
七小時執行不該代表七小時沒有人類設計。它應該代表人類沒有在打程式碼。
這類任務,我會在這些時間點 check in:
- 探索之後:Claude 真的理解實際 execution path 嗎?
- Oracle 設計之後:這個測試抓得到微妙錯誤的 activation 嗎?
- 第一次通過實作之後:它有保留正常 inference 嗎?
- 清理之後:它是簡化了 surface area,還是擴大了?
- 對抗式 review 之後:發現的是 correctness issues,還是 style noise?
Anthropic 建議在把長時間無人值守的工作視為完成前,使用一個新的 subagent 做對抗式 review(Claude Code best practices)。這是好建議,但要調好 reviewer。叫 reviewer「找問題」,它會發明雜務。請它只回報 correctness gaps、missing requirements,以及 out-of-scope changes。
我喜歡這樣的 review prompt:
Review this diff against PLAN.md and ORACLE.md.
Report only:
1. Requirements not implemented.
2. Tests that would pass despite a wrong activation tensor.
3. Changes outside the approved scope.
4. Numerical accuracy or dtype/device risks.
Do not report style preferences. Do not suggest new abstractions unless required for correctness.如果你想用更新的 Fable 級模型來跑這套流程,請精確確認可用性。Anthropic 在 2026 年 6 月 9 日推出 Claude Fable 5 和 Mythos 5,價格是每百萬 input tokens 10 美元、每百萬 output tokens 50 美元(Anthropic),但 Anthropic 在 6 月 12 日表示,為了遵守美國政府指令,已停用客戶對 Fable 5 和 Mythos 5 的存取(Anthropic statement)。所以在規劃執行前,先確認即時存取狀態。當它能透過你的 provider 使用時,同一套 harness 仍然適用;模型升級不會移除 oracle 的必要性。
值得偷走的模式
Rakuten 這個故事很容易被誤讀成「Claude Code 現在可以處理巨大 repos 了」。這太模糊,沒什麼用。
更好的 takeaway 是:當任務被 oracle、plan、review checkpoints 和 rollback boundaries 圈住時,長時間自主編碼才會有效。agent 可以在這些限制內發揮創意。沒有它們,「proactive」就會變成「unbounded」,而失控的 coding agents 正是你收到一則自信最終訊息、卻同時拿到隱藏 bug 的方式。
對 ML infra 和 platform teams 來說,playbook 很簡單:
- 挑選有可量測完成標準的任務:數值相符、migration count、latency budget、compatibility matrix。
- 先寫 test oracle,再寫 feature。
- 強制分開 explore-plan-code。
- 讓 rollback boundaries 保持小。
- Review 證據,不要 review 宣稱。
- 在人類批准前,用第二個 context 攻擊 diff。
這就是你把七小時自主執行從噱頭變成工程工作流程的方法。
如果你想在 access available 時試試這種長任務工作流程,請參考 Claude Fable 5 on OneHop 並從 $10 免費額度開始。

