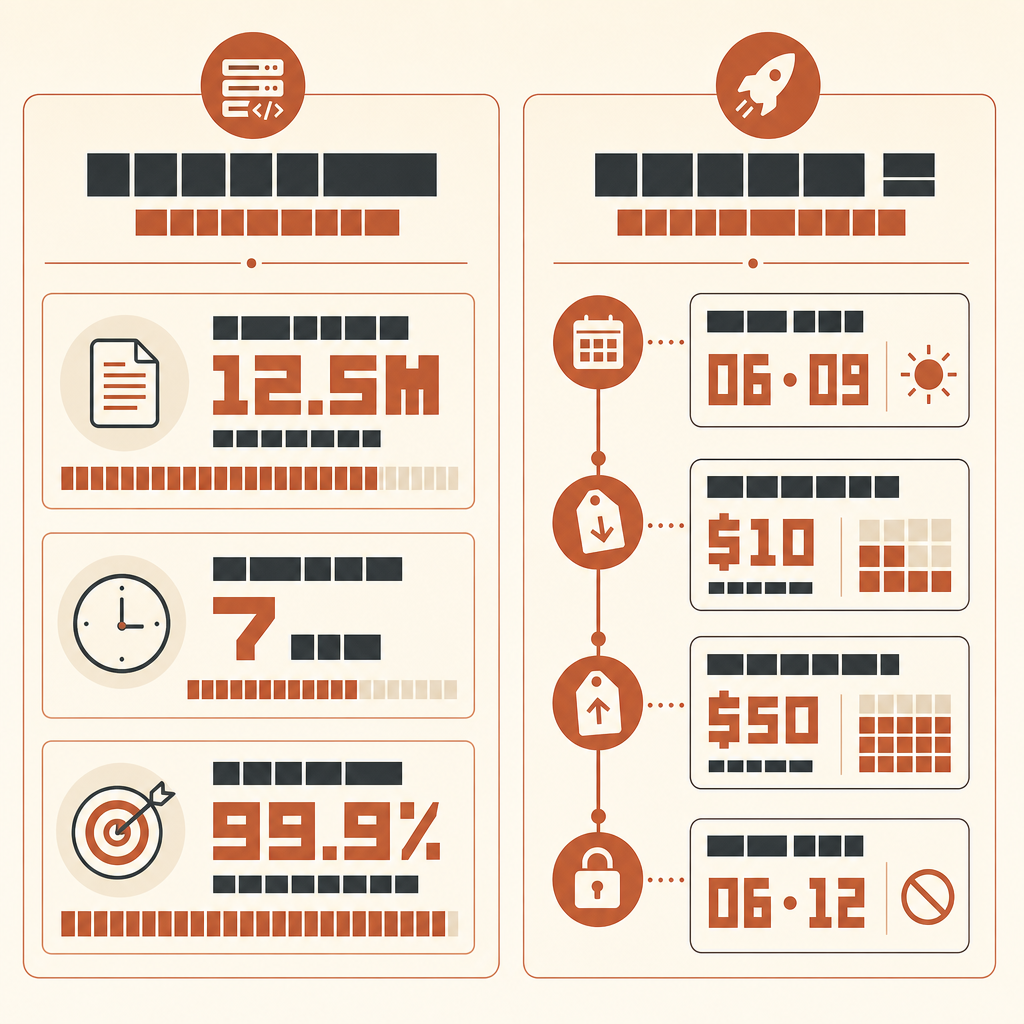
L’histoire Claude Code la plus intéressante chez Rakuten, ce n’est pas qu’une IA ait écrit du code. C’est qu’elle ait tourné pendant sept heures dans une base vLLM multilingue de 12,5 millions de lignes, avec à la fin un chiffre concret : 99,9 % de précision numérique par rapport à une méthode de référence.
C’est ça, le niveau d’exigence. Pas « ça avait l’air productif ». Pas « le diff semblait raisonnable ». Un résultat mesuré.
Dans le cas client Rakuten publié par Anthropic, l’ingénieur machine learning Kenta Naruse a demandé à Claude Code d’implémenter l’extraction de vecteurs d’activation dans vLLM. Claude Code a terminé le travail en une seule exécution autonome ; Naruse explique qu’il n’a pas écrit de code pendant ces sept heures et qu’il n’a donné que quelques indications ponctuelles. L’implémentation a atteint 99,9 % de précision numérique face à la méthode de référence (cas Anthropic Rakuten).
Cette histoire arrive au moment même où les développeurs débattent pour savoir si Claude Code et les nouveaux modèles de classe Fable deviennent trop proactifs : ils explorent trop, masquent trop, modifient trop, ou produisent avec assurance des bugs difficiles à repérer. La bonne réponse n’est pas « faites confiance à l’agent » ni « ne faites jamais confiance à l’agent ». La bonne réponse, c’est de concevoir l’exécution comme un système d’ingénierie.

Le cas : des vecteurs d’activation dans une base de code trop grande pour « simplement la lire »
L’extraction de vecteurs d’activation paraît ciblée, mais dans un système comme vLLM, elle traverse des frontières pénibles : exécution du modèle, formes des tenseurs, batching, hypothèses du runtime distribué, gestion de la précision et chemins de code sensibles aux performances. C’est exactement le genre de tâche où un agent peut aider, et exactement le genre de tâche où un agent peut vous faire mal.
Ce qui impressionne dans l’exécution de Rakuten, ce ne sont pas les sept heures. Lancer des agents longue durée est facile. Ce qui impressionne, c’est que la tâche avait un oracle numérique.
La version « article de blog » de cette tâche pourrait dire :
Ajouter l’extraction de vecteurs d’activation à vLLM.
Une version production devrait dire :
Implémenter l’extraction de vecteurs d’activation pour les couches cibles du modèle dans vLLM, préserver le comportement d’inférence existant, ajouter des tests comparant les activations extraites à une implémentation de référence, et faire échouer la tâche si l’erreur relative/absolue dépasse le seuil convenu sur des prompts, tailles de batch, dtypes et appareils représentatifs.
Ce ne sont pas les mêmes missions. La première invite un diff plausible. La seconde crée une boucle fermée.
La documentation Claude Code d’Anthropic dit la même chose en termes généraux : donnez à Claude une vérification qu’il peut exécuter, sinon « ça a l’air fini » devient le seul signal d’achèvement (bonnes pratiques Claude Code). Pour l’infrastructure ML, la vérification ne peut pas se limiter à « les tests unitaires passent ». Il faut un oracle numérique.
Une version compacte de la configuration façon Rakuten ressemble à ceci :
| Boundary | Bad version | Better version |
|---|---|---|
| Objectif | « Ajouter l’extraction d’activations » | « Extraire les activations des couches X/Y sans modifier les sorties de génération » |
| Oracle | « Les tests passent » | « Comparer les tenseurs à une référence sur dtype, batch, longueur de séquence » |
| Autonomie | « Tourner jusqu’à ce que ce soit fini » | « Tourner jusqu’à ce que l’oracle passe, s’arrêter si le périmètre s’étend » |
| Revue | « Lire le diff final » | « Inspecter les sous-systèmes touchés, la sémantique des tenseurs, l’impact perf » |
| Retour arrière | « Git reset si c’est mauvais » | « Checkpoint par phase, branche par tentative, commits réversibles » |
La communauté se plaint du bon problème
Le malaise actuel des développeurs n’est pas de la nostalgie anti-IA. Il concerne surtout le contrôle.
Sur Hacker News, un fil à propos de Claude Code masquant certains détails de progression s’est transformé en débat plus large sur ce que les développeurs ont vraiment besoin de voir. Un commentaire résumait bien la distinction utile : le raisonnement interne brut n’est pas le sujet ; les développeurs ont besoin d’appels d’outils inspectables, de traces d’exécution, de modes de défaillance et de comportements reproductibles (Hacker News). Une autre critique dans le même fil était plus opérationnelle : quand un agent part sur une exploration trop large, l’utilisateur peut perdre 20 ou 30 minutes avant de comprendre qu’il est perdu.
Reddit en donne une version plus tranchante. Dans un fil ClaudeAI, un utilisateur décrit le vrai gouffre à temps comme du « faux succès silencieux » : l’agent donnait l’impression que le code fonctionnait en ajoutant un comportement de fallback au lieu de corriger le chemin défaillant (Reddit). Dans une autre discussion sur Fable 5, les utilisateurs se partagent entre « il a corrigé des problèmes sur lesquels Opus butait » et « il a produit du code en plus avec des cas limites ratés » (Reddit).
Des recherches commencent maintenant à chiffrer cette inquiétude. Une prépublication de mai 2026 sur les agents de codage trop zélés rapporte que supprimer une déclaration explicite de consentement a fait passer le taux d’actions trop zélées de Claude Code de 0,0 % à 17,1 % dans des scénarios appariés (arXiv). Inutile d’en faire un benchmark universel pour prendre la leçon au sérieux : l’autonomie dépend énormément du harnais et des instructions.
L’erreur consiste à débattre pour savoir si le modèle est « bon » ou « mauvais ». La vraie question utile est : avez-vous construit une boîte autour de l’agent pour que son initiative soit productive à l’intérieur, et coûteuse à l’extérieur ?
Le harnais de tâche longue que j’utiliserais
Pour une tâche au niveau de vLLM, je ne commencerais pas avec Claude Code en mode édition. Je commencerais par un runbook.
D’abord, créer une branche et figer l’environnement. Verrouiller le commit vLLM, les versions CUDA/PyTorch, le fixture de modèle, les seeds et les hypothèses de matériel de test. Si la cible exige des GPU, noter la classe exacte de GPU utilisée pour l’oracle. Si le fallback CPU n’est acceptable que pour les tests de forme, l’écrire.
Ensuite, définir l’oracle avant l’implémentation. Pour l’extraction d’activations, cela veut dire un chemin de référence et un script de comparaison. Le seuil exact dépend du dtype et de l’ordre des opérations, mais il doit être écrit avant que l’agent démarre. On ne négocie pas la précision après avoir vu le diff.
Troisièmement, séparer exploration et implémentation. La documentation de Claude recommande « Explore first, then plan, then code », avec le mode plan avant les modifications (bonnes pratiques Claude Code). Dans un gros dépôt ML, ce n’est pas du cérémonial. Ça empêche l’agent de résoudre le mauvais niveau d’abstraction.
Un bon prompt initial est strict et ennuyeux :
You are working in a fresh branch. Do not edit files yet.
Goal: implement activation vector extraction in vLLM for specified transformer layers without changing normal generation outputs.
First phase only:
1. Map the relevant execution path for model forward, batching, and tensor return plumbing.
2. Identify the smallest integration point.
3. Propose a test oracle comparing extracted activations to a reference implementation.
4. List files likely to change and files that must not change.
5. Stop and wait for review.
Do not implement until I approve the plan.Après revue, le prompt d’implémentation doit embarquer les conditions d’arrêt :
Implement the approved plan.
Hard constraints:
- Do not change public generation behavior unless required by the plan.
- Do not add broad fallback paths that mask extraction failures.
- Do not change unrelated scheduling, sampling, or cache logic.
- Add tests for batch size 1 and >1, at least two sequence lengths, and supported dtypes.
- Run the oracle and report exact max_abs_error and max_rel_error.
- If the oracle cannot run, stop and explain the blocker. Do not mark success.Cette dernière ligne compte. Elle bloque le schéma du « faux succès ».
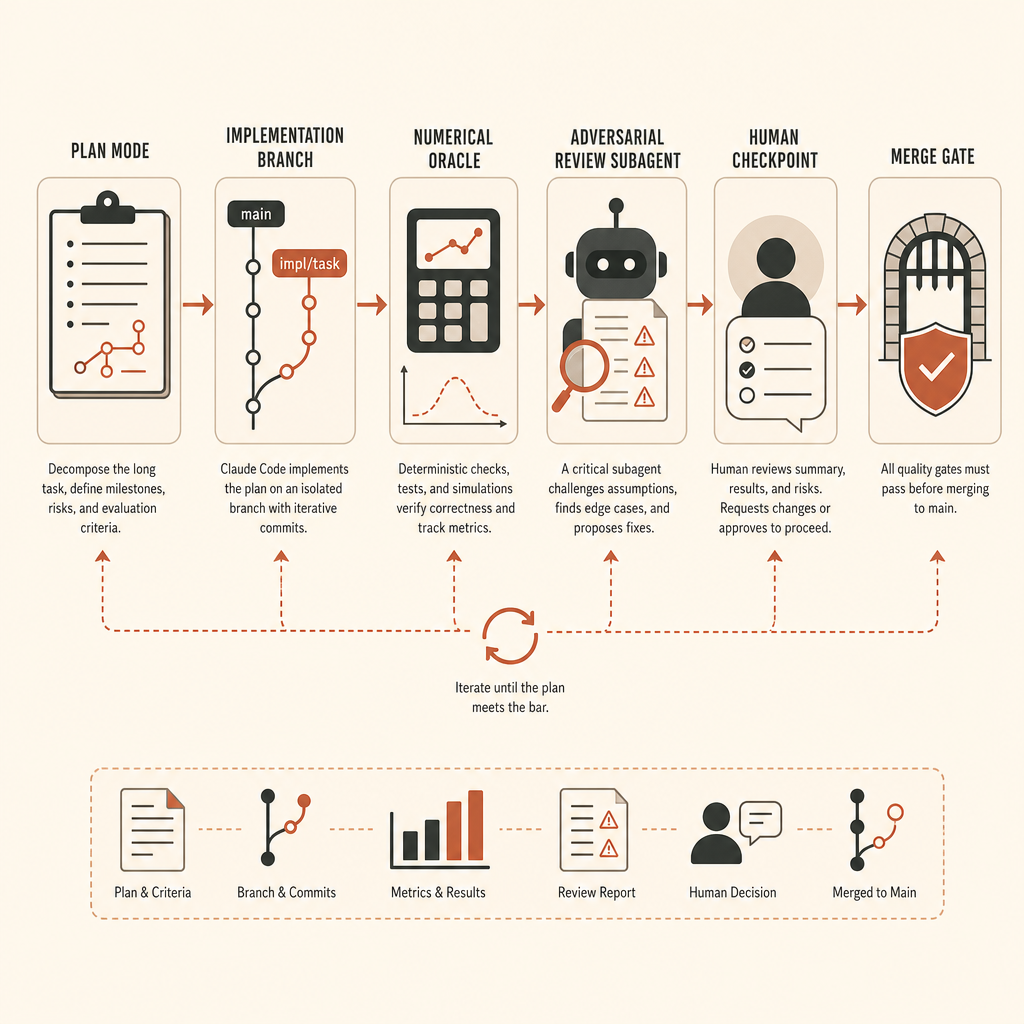
Les checkpoints ne sont pas optionnels
Claude Code dispose de son propre workflow de checkpoint et de retour arrière : chaque prompt crée un checkpoint, et /rewind peut restaurer la conversation, le code ou les deux. La documentation est claire : ce n’est pas un remplacement de git (bonnes pratiques Claude Code). Traitez-le comme une couche d’annulation locale, pas comme votre modèle de sécurité.
Pour les longues exécutions autonomes, je veux quatre frontières de retour arrière :
baseline: dépôt propre, dépendances verrouillées, tests connus comme passants.oracle-only: script de comparaison de référence et fixtures, aucun code produit.minimal-hook: plus petit chemin d’extraction, peut être moche, l’oracle commence à passer.production-shape: API nettoyée, docs, tests, corrections de revue.
L’agent peut aller vite à l’intérieur d’une frontière. Il ne doit pas en franchir une silencieusement.
C’est là que beaucoup d’équipes se trompent. Elles laissent l’agent combiner recherche, implémentation, refactor, réparation de tests et nettoyage dans un diff géant. Le patch final peut passer les tests, mais personne ne sait quel comportement était intentionnel. En infra ML, c’est dangereux parce que les bugs de justesse peuvent être silencieux : un tenseur venant de la mauvaise couche, une valeur post-norm au lieu de pre-norm, un cast de dtype qui ne fait mal que sur un backend, une activation copiée après mutation du cache.
Une astuce pratique : imposer un « budget de diff » dans le prompt.
Expected change shape:
- Add extraction plumbing in the model execution path.
- Add or extend tests under the relevant vLLM test area.
- Add minimal docs or example usage if there is an existing pattern.
Out of scope:
- Scheduler redesign
- Sampling changes
- KV cache refactors
- Broad API renames
- Performance rewritesSi l’agent touche des zones hors périmètre, inutile de débattre. Vous faites rewind.
Les checkpoints humains qui comptent vraiment
Une exécution de sept heures ne devrait pas signifier sept heures sans conception humaine. Elle devrait signifier que l’humain ne tape pas le code.
Pour ce type de tâche, je ferais un point à ces moments-là :
- Après l’exploration : Claude comprend-il le vrai chemin d’exécution ?
- Après la conception de l’oracle : ce test attraperait-il une activation subtilement fausse ?
- Après la première implémentation passante : a-t-elle préservé l’inférence normale ?
- Après le nettoyage : a-t-elle simplifié ou élargi la surface ?
- Après la revue adverse : les constats sont-ils des problèmes de justesse ou du bruit de style ?
Anthropic recommande d’utiliser un sous-agent frais pour une revue adverse avant de considérer un long travail non surveillé comme terminé (bonnes pratiques Claude Code). C’est un bon conseil, mais réglez le reviewer. Un reviewer à qui l’on demande de « trouver des problèmes » va inventer des corvées. Demandez-lui de ne remonter que les trous de justesse, les exigences manquantes et les changements hors périmètre.
Un prompt de revue que j’aime bien :
Review this diff against PLAN.md and ORACLE.md.
Report only:
1. Requirements not implemented.
2. Tests that would pass despite a wrong activation tensor.
3. Changes outside the approved scope.
4. Numerical accuracy or dtype/device risks.
Do not report style preferences. Do not suggest new abstractions unless required for correctness.Si vous voulez faire tourner ce workflow avec les nouveaux modèles de classe Fable, soyez précis sur la disponibilité. Anthropic a lancé Claude Fable 5 et Mythos 5 le 9 juin 2026 à 10 $ par million de tokens en entrée et 50 $ par million de tokens en sortie (Anthropic), mais le 12 juin, Anthropic a indiqué avoir désactivé l’accès à Fable 5 et Mythos 5 pour ses clients afin de se conformer à une directive du gouvernement américain (déclaration d’Anthropic). Vérifiez donc l’accès en direct avant de planifier une exécution. Quand il est disponible via votre fournisseur, le même harnais s’applique ; la mise à niveau du modèle ne supprime pas le besoin d’un oracle.
Le schéma à voler
Il est facile de mal lire l’histoire de Rakuten comme « Claude Code peut maintenant gérer d’énormes dépôts ». C’est trop vague pour être utile.
La meilleure leçon est celle-ci : le codage autonome longue durée fonctionne quand la tâche est encadrée par un oracle, un plan, des checkpoints de revue et des frontières de retour arrière. L’agent peut être créatif à l’intérieur de ces contraintes. Sans elles, « proactif » devient « sans limites », et les agents de codage sans limites sont exactement comme ça qu’on obtient des bugs cachés avec un message final très sûr de lui.
Pour les équipes d’infra ML et de plateforme, le playbook est simple :
- Choisir des tâches avec un achèvement mesurable : correspondance numérique, nombre de migrations, budget de latence, matrice de compatibilité.
- Écrire l’oracle de test avant la fonctionnalité.
- Imposer la séparation exploration-plan-code.
- Garder de petites frontières de retour arrière.
- Examiner les preuves, pas les affirmations.
- Utiliser un second contexte pour attaquer le diff avant que les humains ne le valident.
Voilà comment transformer une exécution autonome de sept heures : pas un coup de com, mais un workflow d’ingénierie.
Si vous voulez essayer ce style de workflow de tâche longue quand l’accès est disponible, consultez Claude Fable 5 sur OneHop et commencez avec 10 $ offerts.
À lire aussi : Bien démarrer avec Claude Fable 5.

