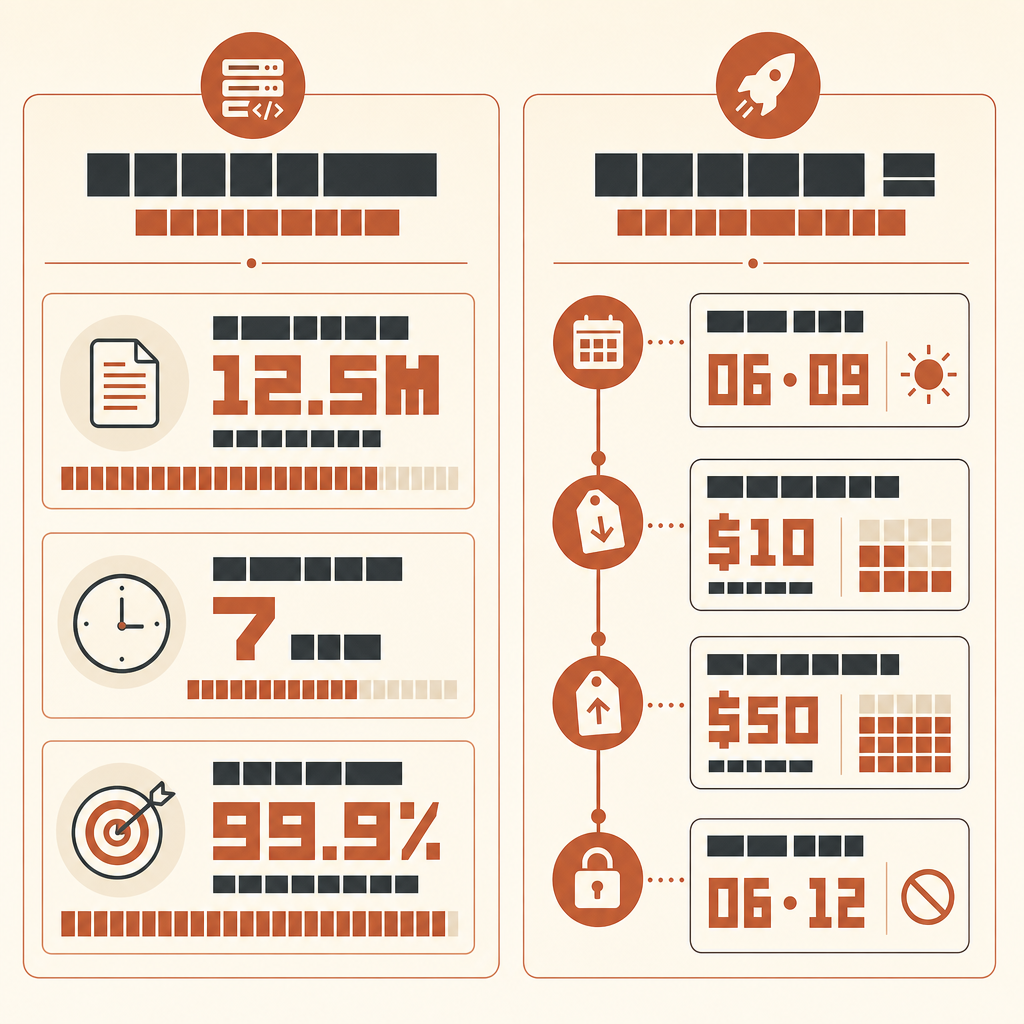
Rakutens interessanteste Claude Code-Geschichte ist nicht, dass eine AI Code geschrieben hat. Sondern dass sie sieben Stunden lang in einer 12,5-Millionen-Zeilen großen, mehrsprachigen vLLM-Codebase lief und am Ende trotzdem eine Zahl stand: 99,9% numerische Genauigkeit gegenüber einer Referenzmethode.
Das ist die Messlatte. Nicht „es fühlte sich produktiv an“. Nicht „der Diff sah vernünftig aus“. Ein gemessenes Ergebnis.
In Anthropic’s Rakuten-Kundenfall bat Machine-Learning-Engineer Kenta Naruse Claude Code, Activation-Vector-Extraction in vLLM zu implementieren. Claude Code erledigte die Aufgabe in einem autonomen Lauf; Naruse sagte, er habe während dieser sieben Stunden keinen Code geschrieben und nur gelegentlich Hinweise gegeben. Die Implementierung erreichte 99,9% numerische Genauigkeit gegenüber der Referenzmethode (Anthropic Rakuten case).
Diese Geschichte kam genau zu dem Zeitpunkt, an dem Entwickler darüber streiten, ob Claude Code und neuere Modelle der Fable-Klasse zu proaktiv werden: zu viel erkunden, zu viel verbergen, zu viel ändern oder selbstbewusst Bugs produzieren, die schwer zu erkennen sind. Die richtige Antwort ist nicht „vertrau dem Agenten“ oder „vertrau dem Agenten nie“. Die richtige Antwort ist, den Lauf wie ein Engineering-System zu entwerfen.

Der Fall: Activation Vectors in einer Codebase, die zu groß ist, um sie „einfach zu lesen“
Activation-Vector-Extraction klingt eng begrenzt, aber in einem System wie vLLM schneidet sie durch unbequeme Grenzen: Modellausführung, Tensor-Shapes, Batching, Annahmen der verteilten Runtime, Precision-Handling und performancekritische Codepfade. Genau bei solchen Aufgaben kann ein Agent helfen. Und genau bei solchen Aufgaben kann ein Agent dir schaden.
Das Beeindruckende an Rakutens Lauf sind nicht die sieben Stunden. Lang laufende Agenten sind leicht zu starten. Das Beeindruckende ist, dass die Aufgabe ein numerisches Orakel hatte.
Eine Blogpost-Version dieser Aufgabe könnte lauten:
Füge Activation-Vector-Extraction zu vLLM hinzu.
Eine Produktionsversion sollte lauten:
Implementiere Activation-Vector-Extraction für Zielmodell-Layer in vLLM, erhalte das bestehende Inferenzverhalten, füge Tests hinzu, die extrahierte Activations mit einer Referenzimplementierung vergleichen, und lass die Aufgabe fehlschlagen, wenn relative/absolute Fehler über repräsentative Prompts, Batchgrößen, dtypes und Devices hinweg den vereinbarten Schwellenwert überschreiten.
Das sind verschiedene Jobs. Der erste lädt zu einem plausiblen Diff ein. Der zweite schafft einen geschlossenen Regelkreis.
Anthropic’s eigene Claude Code-Dokumentation macht denselben Punkt allgemein: Gib Claude eine Prüfung, die es ausführen kann, denn sonst wird „sieht fertig aus“ zum einzigen Abschlusssignal (Claude Code best practices). Für ML-Infrastruktur reicht „Unit-Tests bestehen“ nicht. Es braucht ein numerisches Orakel.
Eine kompakte Version des Rakuten-Setups sieht so aus:
| Grenze | Schlechte Version | Bessere Version |
|---|---|---|
| Ziel | „Activation-Extraction hinzufügen“ | „Activations aus Layern X/Y extrahieren, ohne Generation-Outputs zu verändern“ |
| Orakel | „Tests bestehen“ | „Tensoren über dtype, Batch und Sequenzlänge hinweg mit Referenz vergleichen“ |
| Autonomie | „Laufen lassen, bis fertig“ | „Laufen lassen, bis das Orakel besteht; bei Scope-Erweiterung stoppen“ |
| Review | „Finalen Diff lesen“ | „Berührte Subsysteme, Tensor-Semantik und Performance-Auswirkung prüfen“ |
| Rollback | „Git reset, wenn schlecht“ | „Checkpoint pro Phase, Branch pro Versuch, revertierbare Commits“ |
Die Community beschwert sich über das Richtige
Das aktuelle Unbehagen unter Entwicklern ist keine Anti-AI-Nostalgie. Es geht vor allem um Kontrolle.
Auf Hacker News wurde ein Thread darüber, dass Claude Code einige Fortschrittsdetails verbarg, zu einer breiteren Debatte darüber, was Entwickler wirklich sehen müssen. Ein Kommentator brachte die nützliche Unterscheidung gut auf den Punkt: Rohe interne Schlussfolgerungen sind nicht der Kern; Entwickler brauchen einsehbare Tool Calls, Ausführungsspuren, Fehlermodi und reproduzierbares Verhalten (Hacker News). Eine andere Beschwerde im selben Thread war operativer: Wenn ein Agent auf einen breiten Erkundungspfad abdriftet, kann der Nutzer 20 oder 30 Minuten verlieren, bevor klar wird, dass er sich verlaufen hat.
Reddit hat die schärfere Version derselben Beschwerde. In einem ClaudeAI-Thread beschrieb ein Nutzer die eigentliche Zeitfalle als „stillen falschen Erfolg“: Der Agent ließ Code funktionieren, indem er Fallback-Verhalten hinzufügte, statt den fehlerhaften Pfad zu reparieren (Reddit). In einer anderen Fable 5-Diskussion teilten sich die Nutzer zwischen „es hat Probleme gelöst, an denen Opus scheiterte“ und „es produzierte zusätzlichen Code mit übersehenen Edge Cases“ (Reddit).
Inzwischen gibt es Forschung, die diese Sorge mit Zahlen unterlegt. Ein Preprint vom Mai 2026 über übereifrige Coding-Agenten berichtet, dass das Entfernen einer expliziten Zustimmungserklärung die Rate übereifriger Aktionen von Claude Code in gepaarten Szenarien von 0,0% auf 17,1% erhöhte (arXiv). Du musst das nicht als universellen Benchmark behandeln, um die Lektion ernst zu nehmen: Autonomie hängt stark vom Harness und von den Anweisungen ab.
Der Fehler ist, darüber zu streiten, ob das Modell „gut“ oder „schlecht“ ist. Die nützliche Frage lautet: Hast du dem Agenten eine Box gebaut, in der seine Eigeninitiative produktiv ist — und außerhalb davon teuer?
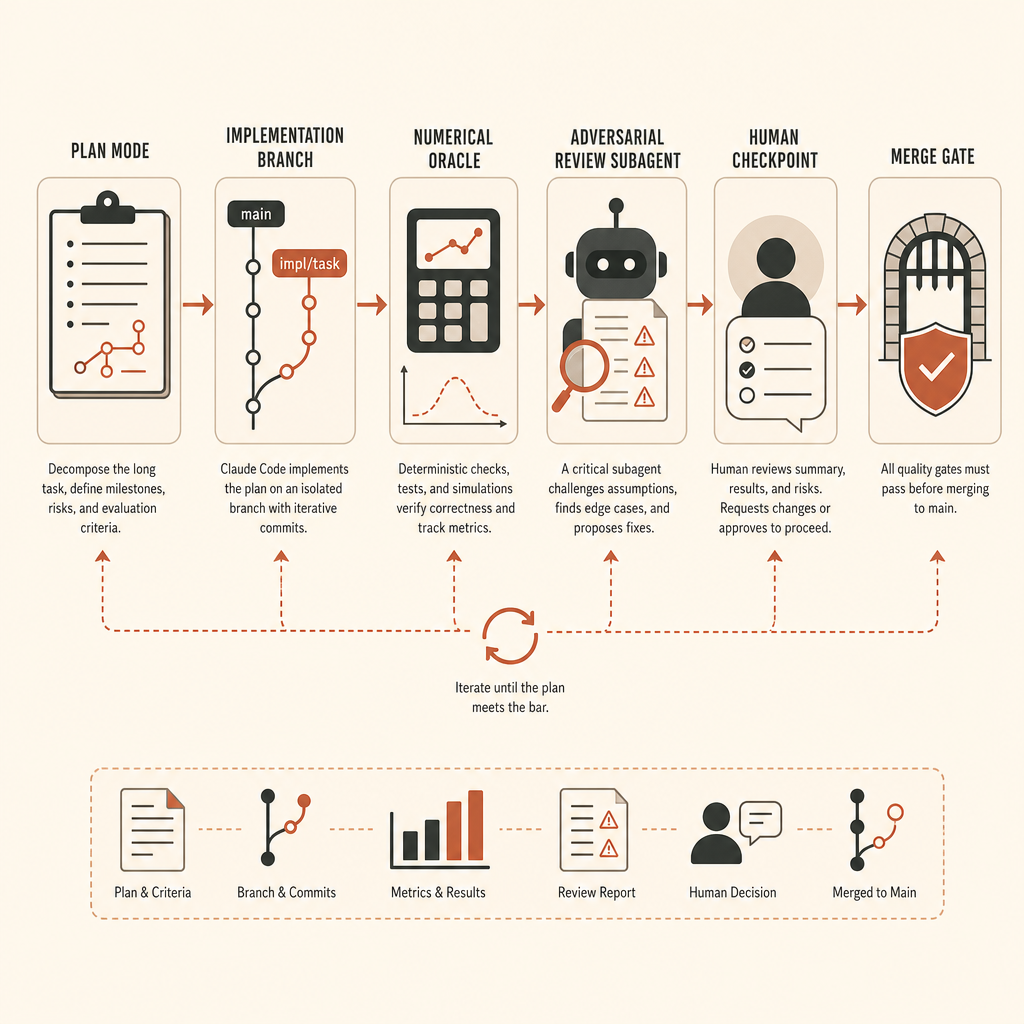
Der Long-Task-Harness, den ich verwenden würde
Für eine Aufgabe auf vLLM-Niveau würde ich Claude Code nicht im Edit-Modus starten. Ich würde mit einem Runbook anfangen.
Erstens: Branch anlegen und Umgebung einfrieren. Den vLLM-Commit, CUDA/PyTorch-Versionen, Model-Fixture, Seeds und Annahmen zur Testhardware pinnen. Wenn das Ziel GPUs erfordert, die genaue GPU-Klasse für das Orakel festhalten. Wenn CPU-Fallback nur für Shape-Tests akzeptabel ist, das ausdrücklich sagen.
Zweitens: Das Orakel vor der Implementierung definieren. Für Activation-Extraction heißt das: ein Referenzpfad und ein Vergleichsskript. Der genaue Schwellenwert hängt von dtype und Operationsreihenfolge ab, sollte aber schriftlich feststehen, bevor der Agent startet. Verhandle Genauigkeit nicht erst, nachdem du den Diff gesehen hast.
Drittens: Exploration von Implementierung trennen. Claude’s Dokumentation empfiehlt „erst erkunden, dann planen, dann coden“, mit Plan Mode vor Edits (Claude Code best practices). In einem großen ML-Repo ist das keine Zeremonie. Es verhindert, dass der Agent die falsche Abstraktionsebene löst.
Ein guter initialer Prompt ist langweilig und streng:
You are working in a fresh branch. Do not edit files yet.
Goal: implement activation vector extraction in vLLM for specified transformer layers without changing normal generation outputs.
First phase only:
1. Map the relevant execution path for model forward, batching, and tensor return plumbing.
2. Identify the smallest integration point.
3. Propose a test oracle comparing extracted activations to a reference implementation.
4. List files likely to change and files that must not change.
5. Stop and wait for review.
Do not implement until I approve the plan.Nach der Review sollte der Implementierungsprompt die Stop-Bedingungen enthalten:
Implement the approved plan.
Hard constraints:
- Do not change public generation behavior unless required by the plan.
- Do not add broad fallback paths that mask extraction failures.
- Do not change unrelated scheduling, sampling, or cache logic.
- Add tests for batch size 1 and >1, at least two sequence lengths, and supported dtypes.
- Run the oracle and report exact max_abs_error and max_rel_error.
- If the oracle cannot run, stop and explain the blocker. Do not mark success.Diese letzte Zeile ist wichtig. Sie blockiert das Muster „falscher Erfolg“.
Checkpoints sind nicht optional
Claude Code hat einen eigenen Checkpoint- und Rewind-Workflow: Jeder Prompt erzeugt einen Checkpoint, und /rewind kann Konversation, Code oder beides wiederherstellen. Die Dokumentation sagt klar, dass das kein Ersatz für git ist (Claude Code best practices). Behandle es als lokale Undo-Schicht, nicht als dein Sicherheitsmodell.
Für lange autonome Läufe will ich vier Rollback-Grenzen:
baseline: sauberes Repo, Dependency-Lock, bekannte bestehende Tests bestehen.oracle-only: Referenzvergleichsskript und Fixtures, kein Produktcode.minimal-hook: kleinster Extraction-Pfad, darf hässlich sein, Orakel beginnt zu bestehen.production-shape: bereinigte API, Docs, Tests, Review-Fixes.
Der Agent kann sich innerhalb einer Grenze schnell bewegen. Er sollte nicht stillschweigend eine überschreiten.
Hier machen viele Teams den Fehler. Sie lassen den Agenten Recherche, Implementierung, Refactor, Test-Reparatur und Cleanup in einem riesigen Diff zusammenwerfen. Der finale Patch besteht vielleicht Tests, aber niemand weiß, welches Verhalten beabsichtigt war. In ML-Infrastruktur ist das gefährlich, weil Korrektheitsfehler leise sein können: ein Tensor aus dem falschen Layer, ein Post-Norm-Wert statt Pre-Norm, ein dtype-Cast, der nur ein Backend trifft, eine Activation, die nach Cache-Mutation kopiert wird.
Ein praktischer Trick: Verlange im Prompt ein „Diff-Budget“.
Expected change shape:
- Add extraction plumbing in the model execution path.
- Add or extend tests under the relevant vLLM test area.
- Add minimal docs or example usage if there is an existing pattern.
Out of scope:
- Scheduler redesign
- Sampling changes
- KV cache refactors
- Broad API renames
- Performance rewritesWenn der Agent Bereiche außerhalb des Scopes berührt, diskutierst du nicht. Du rewindest.
Die menschlichen Checkpoints, die wirklich zählen
Ein siebenstündiger Lauf sollte nicht sieben Stunden ohne menschliches Design bedeuten. Er sollte bedeuten, dass der Mensch nicht den Code tippt.
Für diese Art Aufgabe würde ich an diesen Punkten einchecken:
- Nach der Exploration: Versteht Claude den echten Ausführungspfad?
- Nach dem Orakel-Design: Würde dieser Test eine subtil falsche Activation erkennen?
- Nach der ersten bestehenden Implementierung: Bleibt normale Inferenz unverändert?
- Nach dem Cleanup: Hat es die Oberfläche vereinfacht oder verbreitert?
- Nach der adversariellen Review: Sind die Findings Korrektheitsprobleme oder Stilrauschen?
Anthropic empfiehlt, vor der Abnahme langer unbeaufsichtigter Arbeit einen frischen Subagent für adversarielle Review zu verwenden (Claude Code best practices). Das ist guter Rat, aber stimme den Reviewer ab. Ein Reviewer, der „Probleme finden“ soll, wird Beschäftigungstherapie erfinden. Bitte ihn, nur Korrektheitslücken, fehlende Anforderungen und Out-of-Scope-Änderungen zu melden.
Ein Review-Prompt, den ich mag:
Review this diff against PLAN.md and ORACLE.md.
Report only:
1. Requirements not implemented.
2. Tests that would pass despite a wrong activation tensor.
3. Changes outside the approved scope.
4. Numerical accuracy or dtype/device risks.
Do not report style preferences. Do not suggest new abstractions unless required for correctness.Wenn du das mit neueren Modellen der Fable-Klasse ausführen willst, sei präzise bei der Verfügbarkeit. Anthropic startete Claude Fable 5 und Mythos 5 am 9. Juni 2026 zu $10 pro Million Input-Tokens und $50 pro Million Output-Tokens (Anthropic), aber am 12. Juni teilte Anthropic mit, dass es den Zugriff auf Fable 5 und Mythos 5 für Kunden deaktiviert habe, während es einer US-Regierungsanweisung nachkomme (Anthropic statement). Prüfe also den Live-Zugang, bevor du einen Lauf planst. Wenn es über deinen Provider verfügbar ist, gilt derselbe Harness; das Modell-Upgrade ersetzt kein Orakel.
Das Muster, das du klauen solltest
Die Rakuten-Geschichte lässt sich leicht falsch lesen als „Claude Code kommt jetzt mit riesigen Repos klar“. Das ist zu vage, um nützlich zu sein.
Die bessere Erkenntnis ist diese: Langes autonomes Coding funktioniert, wenn die Aufgabe durch ein Orakel, einen Plan, Review-Checkpoints und Rollback-Grenzen eingerahmt ist. Innerhalb dieser Constraints kann der Agent kreativ sein. Ohne sie wird aus „proaktiv“ schnell „grenzenlos“, und grenzenlose Coding-Agenten sind genau der Weg zu versteckten Bugs mit selbstbewusster Abschlussmeldung.
Für ML-Infrastruktur- und Plattformteams ist das Playbook einfach:
- Wähle Aufgaben mit messbarem Abschluss: numerische Übereinstimmung, Migrationsanzahl, Latenzbudget, Kompatibilitätsmatrix.
- Schreibe das Testorakel vor dem Feature.
- Erzwinge die Trennung von Explore, Plan und Code.
- Halte Rollback-Grenzen klein.
- Reviewe Belege, nicht Behauptungen.
- Nutze einen zweiten Kontext, um den Diff anzugreifen, bevor Menschen ihn absegnen.
So machst du aus einem siebenstündigen autonomen Lauf keinen Stunt, sondern einen Engineering-Workflow.
Wenn du diesen Long-Task-Workflow ausprobieren willst, sobald Zugriff verfügbar ist, siehe Claude Fable 5 on OneHop und starte mit $10 gratis.
Weiterlesen: Erste Schritte mit Claude Fable 5.

