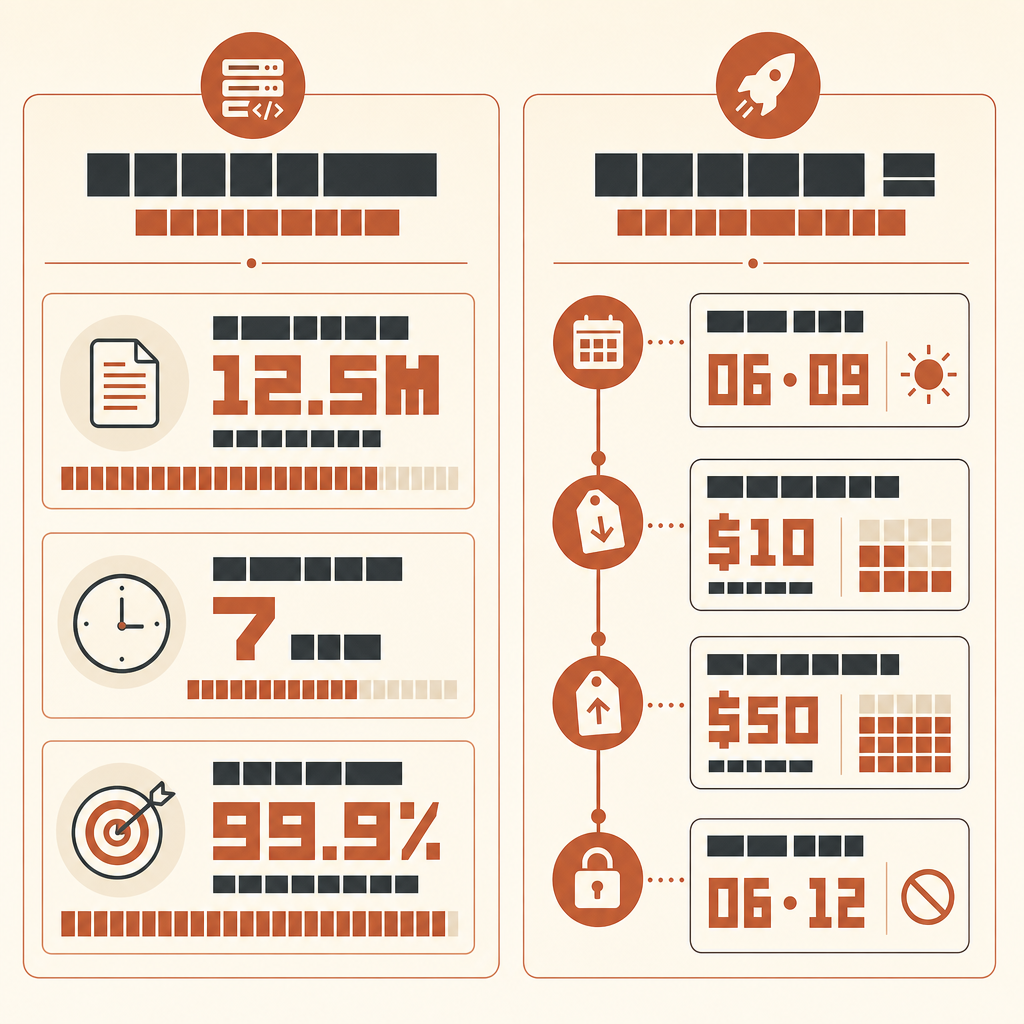
قصة Rakuten الأهم مع Claude Code ليست أن ذكاءً اصطناعيًا كتب كودًا. بل أنه عمل سبع ساعات داخل قاعدة كود vLLM متعددة اللغات تضم 12.5 مليون سطر، ومع ذلك خرج في النهاية برقم واضح: دقة عددية 99.9% مقارنةً بطريقة مرجعية.
هذا هو المعيار. ليس “بدا منتجًا”. وليس “كان الـ diff معقولًا”. بل نتيجة مقاسة.
في دراسة حالة Rakuten لدى Anthropic، طلب مهندس تعلّم الآلة Kenta Naruse من Claude Code تنفيذ استخراج متجهات التفعيل داخل vLLM. أنجز Claude Code المهمة في تشغيل ذاتي واحد، وقال Naruse إنه لم يكتب كودًا خلال تلك الساعات السبع، واكتفى بتوجيهات متقطعة. وصل التنفيذ إلى دقة عددية 99.9% مقارنةً بالطريقة المرجعية (حالة Rakuten لدى Anthropic).
وصلت هذه القصة في الوقت نفسه الذي يتجادل فيه المطورون حول ما إذا كان Claude Code والنماذج الأحدث من فئة Fable أصبحت مبادرة أكثر من اللازم: تستكشف أكثر من اللازم، تخفي أكثر من اللازم، تغيّر أكثر من اللازم، أو تنتج أخطاء بثقة يصعب اكتشافها. الإجابة الصحيحة ليست “ثق بالوكيل” ولا “لا تثق بالوكيل أبدًا”. الإجابة الصحيحة هي أن تصمم التشغيل كمنظومة هندسية.

الحالة: متجهات التفعيل في قاعدة كود أضخم من أن “تقرأها ببساطة”
قد يبدو استخراج متجهات التفعيل مهمة ضيقة، لكنه في نظام مثل vLLM يعبر حدودًا مزعجة: تنفيذ النموذج، أشكال الموترات، التجميع، افتراضات وقت التشغيل الموزّع، التعامل مع الدقة، ومسارات كود حساسة للأداء. وهذا بالضبط نوع المهام التي يمكن أن يساعدك فيها الوكيل، وبالضبط نوع المهام التي يمكن أن يؤذيك فيها.
الجزء المثير للإعجاب في تشغيل Rakuten ليس الساعات السبع. تشغيل وكلاء لفترات طويلة سهل البدء. الجزء المثير للإعجاب هو أن المهمة كان لديها حَكَم عددي.
نسخة تدوينة من هذه المهمة قد تقول:
أضف استخراج متجهات التفعيل إلى vLLM.
أما نسخة إنتاجية فيجب أن تقول:
نفّذ استخراج متجهات التفعيل لطبقات نموذج مستهدفة في vLLM، مع الحفاظ على سلوك الاستدلال الحالي، وأضف اختبارات تقارن التفعيلات المستخرجة بتنفيذ مرجعي، وأفشل المهمة ما لم يبقَ الخطأ النسبي/المطلق دون العتبة المتفق عليها عبر مطالبات تمثيلية، وأحجام دفعات، وأنواع dtypes، وأجهزة مختلفة.
هاتان مهمتان مختلفتان. الأولى تدعو إلى diff يبدو مقنعًا. الثانية تنشئ حلقة مغلقة.
توثيق Claude Code نفسه من Anthropic يقول الشيء نفسه بصيغة عامة: أعطِ Claude فحصًا يمكنه تشغيله، لأن “يبدو منتهيًا” يصبح وإلا إشارة الإكمال الوحيدة (أفضل ممارسات Claude Code). في بنية ML التحتية، لا يمكن أن يكون الفحص مجرد “اختبارات الوحدة نجحت”. يجب أن يكون هناك حَكَم عددي.
نسخة مكثفة من إعداد شبيه بأسلوب Rakuten تبدو هكذا:
| الحد | النسخة السيئة | النسخة الأفضل |
|---|---|---|
| الهدف | “أضف استخراج التفعيلات” | “استخرج التفعيلات من الطبقات X/Y من دون تغيير مخرجات التوليد” |
| الحَكَم | “الاختبارات نجحت” | “قارن الموترات بالمرجع عبر dtype وحجم الدفعة وطول التسلسل” |
| الاستقلالية | “شغّل حتى ينتهي” | “شغّل حتى ينجح الحَكَم، وتوقف عند توسّع النطاق” |
| المراجعة | “اقرأ الـ diff النهائي” | “افحص الأنظمة الفرعية المتأثرة، ودلالات الموترات، وأثر الأداء” |
| التراجع | “Git reset إذا كان سيئًا” | “نقطة حفظ لكل مرحلة، وفرع لكل محاولة، وcommits قابلة للعكس” |
المجتمع يشتكي من الشيء الصحيح
انزعاج المطورين الحالي ليس حنينًا معاديًا للذكاء الاصطناعي. هو في معظمه عن السيطرة.
على Hacker News، تحوّل نقاش عن إخفاء Claude Code لبعض تفاصيل التقدم إلى جدل أوسع حول ما يحتاج المطورون فعليًا إلى رؤيته. صاغ أحد المعلقين التمييز المفيد جيدًا: التفكير الداخلي الخام ليس هو المهم؛ يحتاج المطورون إلى استدعاءات أدوات قابلة للفحص، وآثار تنفيذ، وأنماط فشل، وسلوك قابل لإعادة الإنتاج (Hacker News). شكوى أخرى في الخيط نفسه كانت تشغيلية أكثر: عندما ينطلق الوكيل في مسار استكشاف واسع، قد يحرق المستخدم 20 أو 30 دقيقة قبل أن يدرك أنه تائه.
لدى Reddit النسخة الأشد من الشكوى نفسها. في خيط على ClaudeAI، وصف مستخدم مصرف الوقت الحقيقي بأنه “نجاح مزيف صامت”: جعل الوكيل الكود يبدو وكأنه يعمل عبر إضافة سلوك fallback بدل إصلاح المسار الفاشل (Reddit). وفي نقاش آخر عن Fable 5، انقسم المستخدمون بين “أصلح مشكلات عجز عنها Opus” و“أنتج كودًا زائدًا مع حالات حدية فائتة” (Reddit).
هناك الآن بحث يضع أرقامًا خلف هذا القلق. تشير مسودة بحثية منشورة في مايو 2026 عن وكلاء البرمجة المفرطين في المبادرة إلى أن إزالة تصريح موافقة صريح رفعت معدل الإجراءات المفرطة لدى Claude Code من 0.0% إلى 17.1% في سيناريوهات مزدوجة (arXiv). لا تحتاج إلى اعتبار ذلك معيارًا عالميًا كي تأخذ الدرس بجدية: الاستقلالية تعتمد بشدة على الحاضنة والتعليمات.
الخطأ هو أن نناقش ما إذا كان النموذج “جيدًا” أو “سيئًا”. السؤال المفيد هو: هل بنيت صندوقًا حول الوكيل بحيث تكون مبادرته منتجة داخله ومكلفة خارجه؟
حاضنة المهام الطويلة التي سأستخدمها
لمهمة على مستوى vLLM، لن أبدأ بـ Claude Code في وضع التحرير. سأبدأ بدليل تشغيل.
أولًا، أنشئ فرعًا وثبّت البيئة. ثبّت commit الخاص بـ vLLM، وإصدارات CUDA/PyTorch، ونموذج الاختبار، والبذور، وافتراضات عتاد الاختبار. إذا كان الهدف يحتاج إلى GPUs، سجّل فئة GPU الدقيقة المستخدمة للحَكَم. وإذا كان fallback إلى CPU مقبولًا فقط لاختبارات الشكل، فقل ذلك.
ثانيًا، عرّف الحَكَم قبل التنفيذ. في استخراج التفعيلات، يعني ذلك مسارًا مرجعيًا وسكربت مقارنة. العتبة الدقيقة تعتمد على dtype وترتيب العمليات، لكنها يجب أن تُكتب قبل أن يبدأ الوكيل. لا تفاوض على الدقة بعد رؤية الـ diff.
ثالثًا، افصل الاستكشاف عن التنفيذ. توصي وثائق Claude بـ “استكشف أولًا، ثم خطط، ثم اكتب الكود”، مع استخدام وضع الخطة قبل التعديلات (أفضل ممارسات Claude Code). في مستودع ML كبير، هذا ليس طقسًا شكليًا. إنه يمنع الوكيل من حل طبقة التجريد الخاطئة.
موجه أولي جيد يكون مملًا وصارمًا:
You are working in a fresh branch. Do not edit files yet.
Goal: implement activation vector extraction in vLLM for specified transformer layers without changing normal generation outputs.
First phase only:
1. Map the relevant execution path for model forward, batching, and tensor return plumbing.
2. Identify the smallest integration point.
3. Propose a test oracle comparing extracted activations to a reference implementation.
4. List files likely to change and files that must not change.
5. Stop and wait for review.
Do not implement until I approve the plan.بعد المراجعة، يجب أن يحمل موجه التنفيذ شروط التوقف:
Implement the approved plan.
Hard constraints:
- Do not change public generation behavior unless required by the plan.
- Do not add broad fallback paths that mask extraction failures.
- Do not change unrelated scheduling, sampling, or cache logic.
- Add tests for batch size 1 and >1, at least two sequence lengths, and supported dtypes.
- Run the oracle and report exact max_abs_error and max_rel_error.
- If the oracle cannot run, stop and explain the blocker. Do not mark success.السطر الأخير مهم. إنه يمنع نمط “النجاح المزيف”.
نقاط الحفظ ليست اختيارية
لدى Claude Code سير عمل خاص به لنقاط الحفظ والرجوع: كل موجه ينشئ نقطة حفظ، ويمكن لـ /rewind استعادة المحادثة أو الكود أو كليهما. الوثائق واضحة أن هذا ليس بديلًا عن git (أفضل ممارسات Claude Code). عامله كطبقة تراجع محلية، لا كنموذج الأمان لديك.
في التشغيلات الذاتية الطويلة، أريد أربع حدود للتراجع:
baseline: مستودع نظيف، قفل تبعيات، اختبارات معروفة النجاح.oracle-only: سكربت مقارنة مرجعي وfixtures، بلا كود منتج.minimal-hook: أصغر مسار استخراج، قد يكون قبيحًا، والحَكَم يبدأ بالنجاح.production-shape: API منظّف، توثيق، اختبارات، إصلاحات مراجعة.
يمكن للوكيل أن يتحرك بسرعة داخل الحد الواحد. لا ينبغي أن يعبر حدًا بصمت.
هنا تخطئ فرق كثيرة. تترك الوكيل يجمع البحث، والتنفيذ، وإعادة الهيكلة، وإصلاح الاختبارات، والتنظيف في diff عملاق واحد. قد ينجح التصحيح النهائي في الاختبارات، لكن لا أحد يعرف أي سلوك كان مقصودًا. في بنية ML التحتية، هذا خطر لأن أخطاء الصحة قد تكون صامتة: موتر من الطبقة الخطأ، قيمة بعد التطبيع بدلًا من قبله، تحويل dtype يضر بواجهة خلفية واحدة فقط، تفعيل منسوخ بعد تعديل الكاش.
حيلة عملية: اطلب “ميزانية diff” في الموجه.
Expected change shape:
- Add extraction plumbing in the model execution path.
- Add or extend tests under the relevant vLLM test area.
- Add minimal docs or example usage if there is an existing pattern.
Out of scope:
- Scheduler redesign
- Sampling changes
- KV cache refactors
- Broad API renames
- Performance rewritesإذا لمس الوكيل مناطق خارج النطاق، فلا تجادله. ارجع للخلف.
نقاط التحقق البشرية التي تهم فعلًا
تشغيل سبع ساعات لا ينبغي أن يعني سبع ساعات بلا تصميم بشري. يجب أن يعني أن الإنسان لا يكتب الكود.
في هذا النوع من المهام، سأتحقق في هذه اللحظات:
- بعد الاستكشاف: هل يفهم Claude مسار التنفيذ الحقيقي؟
- بعد تصميم الحَكَم: هل سيمسك هذا الاختبار بتفعيل خاطئ بمهارة؟
- بعد أول تنفيذ ناجح: هل حافظ على الاستدلال العادي؟
- بعد التنظيف: هل بسّط مساحة السطح أم وسّعها؟
- بعد المراجعة العدائية: هل النتائج مشكلات صحة أم ضجيج أسلوبي؟
توصي Anthropic باستخدام subagent جديد للمراجعة العدائية قبل اعتبار العمل الطويل غير المراقب منتهيًا (أفضل ممارسات Claude Code). هذه نصيحة جيدة، لكن اضبط المراجع. مراجع يُطلب منه “العثور على مشكلات” سيخترع أعمالًا. اطلب منه الإبلاغ فقط عن فجوات الصحة، والمتطلبات الناقصة، والتغييرات خارج النطاق.
موجه مراجعة يعجبني:
Review this diff against PLAN.md and ORACLE.md.
Report only:
1. Requirements not implemented.
2. Tests that would pass despite a wrong activation tensor.
3. Changes outside the approved scope.
4. Numerical accuracy or dtype/device risks.
Do not report style preferences. Do not suggest new abstractions unless required for correctness.إذا أردت تشغيل هذا مع نماذج أحدث من فئة Fable، فكن دقيقًا بشأن التوفر. أطلقت Anthropic كلًا من Claude Fable 5 وMythos 5 في 9 يونيو 2026 بسعر 10 دولارات لكل مليون رمز إدخال و50 دولارًا لكل مليون رمز إخراج (Anthropic)، لكن في 12 يونيو قالت Anthropic إنها عطّلت وصول العملاء إلى Fable 5 وMythos 5 أثناء امتثالها لتوجيه من الحكومة الأمريكية (بيان Anthropic). لذلك تحقق من الوصول الحي قبل التخطيط لتشغيل. عندما يكون متاحًا عبر مزودك، تنطبق الحاضنة نفسها؛ ترقية النموذج لا تلغي الحاجة إلى حَكَم.
النمط الذي يستحق السرقة
من السهل إساءة قراءة قصة Rakuten على أنها “Claude Code يستطيع الآن التعامل مع المستودعات الضخمة”. هذا فضفاض أكثر من أن يكون مفيدًا.
الخلاصة الأفضل هي هذه: البرمجة الذاتية الطويلة تنجح عندما تكون المهمة محصورة بحَكَم، وخطة، ونقاط مراجعة، وحدود تراجع. يمكن للوكيل أن يكون مبدعًا داخل هذه القيود. من دونها، تتحول “المبادرة” إلى “انفلات”، ووكلاء البرمجة المنفلتون هم الطريقة التي تحصل بها على أخطاء خفية ورسالة نهائية واثقة.
بالنسبة إلى فرق بنية ML التحتية والمنصات، دليل العمل بسيط:
- اختر مهام ذات إكمال قابل للقياس: تطابق عددي، عدد ترحيلات، ميزانية زمن تأخير، مصفوفة توافق.
- اكتب حَكَم الاختبار قبل الميزة.
- افرض الفصل بين الاستكشاف والتخطيط والبرمجة.
- أبقِ حدود التراجع صغيرة.
- راجع الأدلة، لا الادعاءات.
- استخدم سياقًا ثانيًا لمهاجمة الـ diff قبل أن يباركه البشر.
هكذا تحوّل تشغيلًا ذاتيًا من سبع ساعات من استعراض إلى سير عمل هندسي.
إذا أردت تجربة هذا النمط من سير عمل المهام الطويلة عندما يكون الوصول متاحًا، فراجع Claude Fable 5 على OneHop وابدأ مع 10 دولارات مجانًا.
قراءة إضافية: البدء مع Claude Fable 5.

