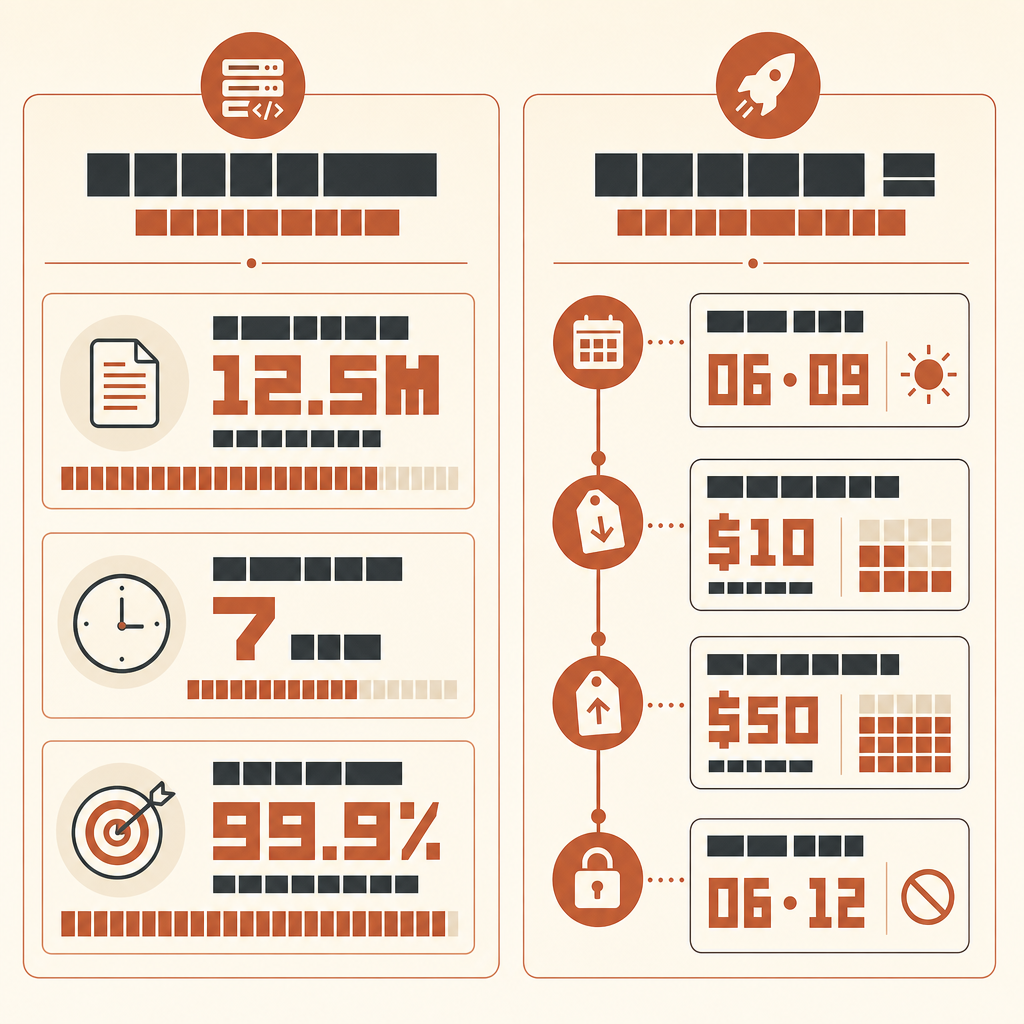
Самая интересная история Rakuten про Claude Code не в том, что AI написал код. А в том, что он семь часов работал в 12,5-миллионной, многоязычной кодовой базе vLLM — и в конце всё равно выдал измеримый результат: 99,9% численной точности относительно эталонного метода.
Вот где планка. Не «кажется, было продуктивно». Не «diff выглядит разумно». А измеренный результат.
В клиентском кейсе Anthropic о Rakuten инженер машинного обучения Kenta Naruse попросил Claude Code реализовать извлечение векторов активаций в vLLM. Claude Code завершил задачу за один автономный прогон; Naruse сказал, что за эти семь часов сам не писал код, а только время от времени давал подсказки. Реализация достигла 99,9% численной точности по сравнению с эталонным методом (Anthropic Rakuten case).
Эта история вышла как раз в момент, когда разработчики спорят, не становятся ли Claude Code и новые модели класса Fable слишком инициативными: слишком много исследуют, слишком много скрывают, слишком много меняют или уверенно производят баги, которые трудно заметить. Правильный ответ — не «доверяйте агенту» и не «никогда не доверяйте агенту». Правильный ответ — проектировать прогон как инженерную систему.

Кейс: векторы активаций в кодовой базе, которую нельзя «просто прочитать»
Извлечение векторов активаций звучит узко, но в системе вроде vLLM оно пересекает неудобные границы: выполнение модели, формы тензоров, батчинг, допущения распределённого runtime, обработку точности и чувствительные к производительности участки кода. Это ровно тот тип задач, где агент может помочь, и ровно тот тип задач, где агент может навредить.
Впечатляет в прогоне Rakuten не семь часов. Долго работающих агентов легко запустить. Впечатляет то, что у задачи был численный оракул.
Версия этой задачи для блог-поста могла бы звучать так:
Добавить извлечение векторов активаций в vLLM.
Продакшен-версия должна звучать так:
Реализовать извлечение векторов активаций для целевых слоёв модели в vLLM, сохранить существующее поведение inference, добавить тесты, сравнивающие извлечённые активации с эталонной реализацией, и считать задачу проваленной, если относительная/абсолютная ошибка превышает согласованный порог на репрезентативных промптах, размерах батча, dtypes и устройствах.
Это разные задачи. Первая приглашает к правдоподобному diff. Вторая создаёт замкнутый контур проверки.
Собственная документация Anthropic по Claude Code формулирует ту же мысль в общем виде: дайте Claude проверку, которую он может запустить, потому что иначе «выглядит готовым» становится единственным сигналом завершения (Claude Code best practices). Для ML-инфраструктуры проверка не может быть только «unit tests pass». Нужен численный оракул.
Компактная версия настройки в стиле Rakuten выглядит так:
| Boundary | Bad version | Better version |
|---|---|---|
| Цель | «Добавить извлечение активаций» | «Извлекать активации из слоёв X/Y без изменения выходов генерации» |
| Оракул | «Тесты проходят» | «Сравнивать тензоры с эталоном по dtype, batch, sequence length» |
| Автономность | «Работай, пока не закончишь» | «Работай, пока не пройдёт оракул; остановись при расширении scope» |
| Ревью | «Прочитать финальный diff» | «Проверить затронутые подсистемы, семантику тензоров, влияние на perf» |
| Откат | «Git reset, если плохо» | «Checkpoint на фазу, branch на попытку, revertable commits» |
Сообщество жалуется ровно на то, на что надо
Текущий дискомфорт разработчиков — это не ностальгия по миру без AI. В основном это вопрос контроля.
На Hacker News тред о том, что Claude Code скрывал часть деталей прогресса, превратился в более широкий спор о том, что разработчикам на самом деле нужно видеть. Один комментатор хорошо сформулировал полезное различие: сырое внутреннее рассуждение не главное; разработчикам нужны проверяемые tool calls, execution traces, failure modes и воспроизводимое поведение (Hacker News). Другая претензия в том же треде была более операционной: когда агент уходит в широкое исследование, пользователь может потерять 20 или 30 минут, прежде чем поймёт, что тот заблудился.
На Reddit та же претензия звучит резче. В одном треде ClaudeAI пользователь описал главный пожиратель времени как «silent fake success»: агент сделал вид, что код работает, добавив fallback-поведение вместо исправления падающего пути (Reddit). В другой дискуссии о Fable 5 пользователи разделились между «он починил проблемы, с которыми мучился Opus» и «он сгенерировал лишний код с пропущенными edge cases» (Reddit).
Теперь есть и исследования с цифрами по этой проблеме. В препринте за май 2026 года об чрезмерно ретивых coding agents сообщается, что удаление явного требования согласия подняло у Claude Code частоту чрезмерно инициативных действий с 0,0% до 17,1% в парных сценариях (arXiv). Не нужно считать это универсальным benchmark, чтобы всерьёз отнестись к выводу: автономность очень сильно зависит от harness и инструкций.
Ошибка — спорить, «хорошая» модель или «плохая». Полезный вопрос другой: построили ли вы вокруг агента коробку, в которой его инициатива продуктивна внутри границ и дорого обходится за их пределами?
Harness для длинных задач, который использовал бы я
Для задачи уровня vLLM я бы не начинал с Claude Code в режиме редактирования. Я бы начал с runbook.
Сначала создайте branch и зафиксируйте окружение. Закрепите commit vLLM, версии CUDA/PyTorch, model fixture, seeds и предположения о тестовом железе. Если цель требует GPU, запишите точный класс GPU, на котором используется оракул. Если CPU fallback допустим только для shape tests, так и напишите.
Во-вторых, определите оракул до реализации. Для извлечения активаций это означает эталонный путь и скрипт сравнения. Точный порог зависит от dtype и порядка операций, но он должен быть записан до старта агента. Не торгуйтесь о точности после того, как увидели diff.
В-третьих, отделите исследование от реализации. Документация Claude рекомендует «Explore first, then plan, then code», используя plan mode до правок (Claude Code best practices). В большом ML-репозитории это не церемония. Это мешает агенту решать задачу на неправильном уровне абстракции.
Хороший начальный prompt скучный и строгий:
You are working in a fresh branch. Do not edit files yet.
Goal: implement activation vector extraction in vLLM for specified transformer layers without changing normal generation outputs.
First phase only:
1. Map the relevant execution path for model forward, batching, and tensor return plumbing.
2. Identify the smallest integration point.
3. Propose a test oracle comparing extracted activations to a reference implementation.
4. List files likely to change and files that must not change.
5. Stop and wait for review.
Do not implement until I approve the plan.После ревью prompt на реализацию должен нести условия остановки:
Implement the approved plan.
Hard constraints:
- Do not change public generation behavior unless required by the plan.
- Do not add broad fallback paths that mask extraction failures.
- Do not change unrelated scheduling, sampling, or cache logic.
- Add tests for batch size 1 and >1, at least two sequence lengths, and supported dtypes.
- Run the oracle and report exact max_abs_error and max_rel_error.
- If the oracle cannot run, stop and explain the blocker. Do not mark success.Последняя строка важна. Она блокирует паттерн «fake success».
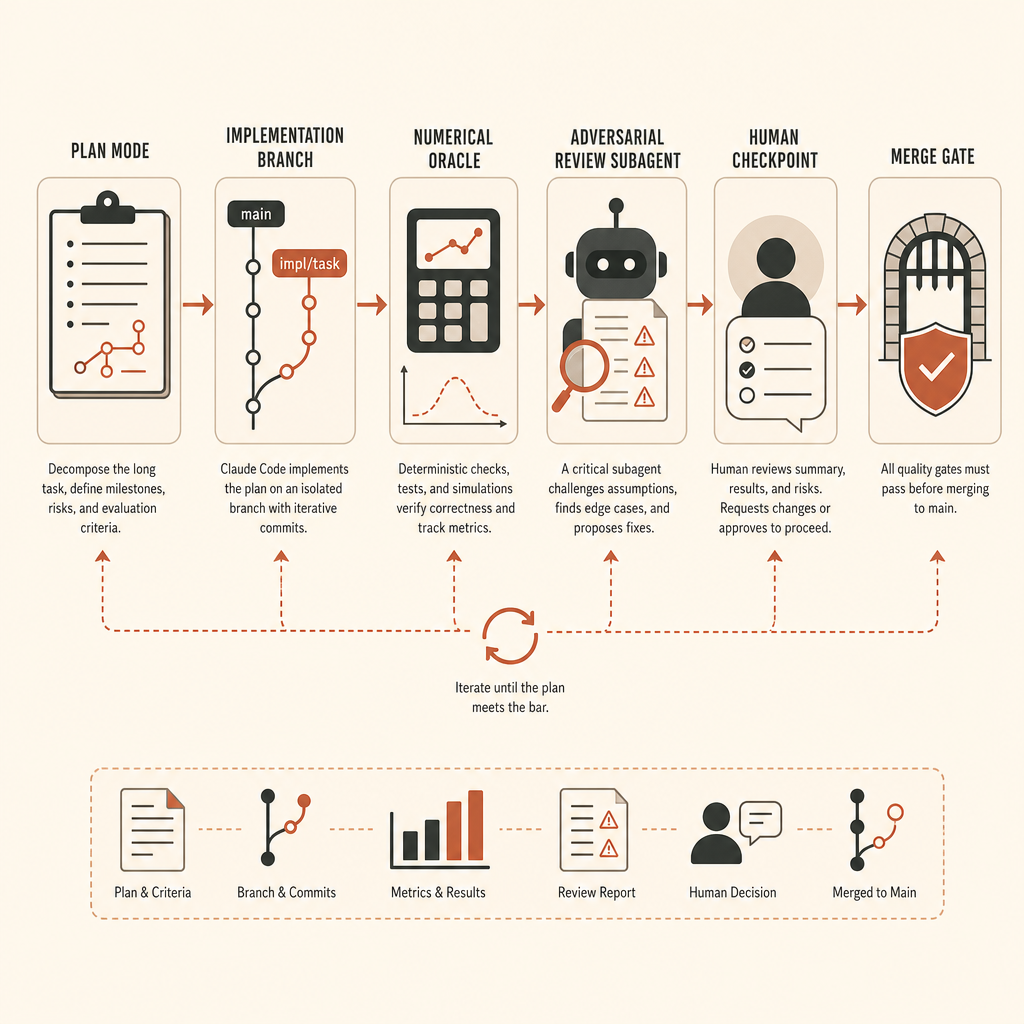
Checkpoints не опциональны
У Claude Code есть собственный workflow checkpoint и rewind: каждый prompt создаёт checkpoint, а /rewind может восстановить conversation, code или и то и другое. Документация прямо говорит, что это не замена git (Claude Code best practices). Относитесь к этому как к локальному слою undo, а не как к вашей модели безопасности.
Для длинных автономных прогонов мне нужны четыре границы отката:
baseline: чистый repo, dependency lock, известные проходящие tests.oracle-only: reference comparison script и fixtures, без product code.minimal-hook: минимальный путь извлечения, возможно некрасивый, оракул начинает проходить.production-shape: вычищенный API, docs, tests, review fixes.
Агент может быстро двигаться внутри границы. Он не должен тихо пересекать её.
Вот где многие команды ошибаются. Они позволяют агенту смешать research, implementation, refactor, test repair и cleanup в один гигантский diff. Финальный patch может проходить tests, но никто не знает, какое поведение было намеренным. В ML-инфраструктуре это опасно, потому что баги корректности могут быть тихими: тензор не из того слоя, post-norm значение вместо pre-norm, dtype cast, который ломает только один backend, активация, скопированная после мутации cache.
Один практичный приём: требуйте в prompt «diff budget».
Expected change shape:
- Add extraction plumbing in the model execution path.
- Add or extend tests under the relevant vLLM test area.
- Add minimal docs or example usage if there is an existing pattern.
Out of scope:
- Scheduler redesign
- Sampling changes
- KV cache refactors
- Broad API renames
- Performance rewritesЕсли агент трогает out-of-scope области, вы не спорите. Вы делаете rewind.
Человеческие checkpoints, которые действительно важны
Семичасовой прогон не должен означать семь часов без человеческого дизайна. Он должен означать, что человек не печатает код.
Для задач такого класса я бы проверялся в эти моменты:
- После исследования: Claude понял настоящий execution path?
- После дизайна оракула: этот тест поймает тонко неверную активацию?
- После первой проходящей реализации: нормальный inference сохранился?
- После cleanup: он упростил surface area или расширил её?
- После adversarial review: находки — это проблемы корректности или style noise?
Anthropic рекомендует использовать свежий subagent для adversarial review, прежде чем считать длинную unattended работу завершённой (Claude Code best practices). Это хороший совет, но reviewer надо настроить. Reviewer, которого попросили «find problems», начнёт выдумывать дела. Попросите сообщать только correctness gaps, missing requirements и out-of-scope changes.
Мне нравится такой prompt для ревью:
Review this diff against PLAN.md and ORACLE.md.
Report only:
1. Requirements not implemented.
2. Tests that would pass despite a wrong activation tensor.
3. Changes outside the approved scope.
4. Numerical accuracy or dtype/device risks.
Do not report style preferences. Do not suggest new abstractions unless required for correctness.Если хотите запускать это с новыми моделями класса Fable, будьте точны насчёт доступности. Anthropic запустила Claude Fable 5 и Mythos 5 9 июня 2026 года по цене $10 за миллион input tokens и $50 за миллион output tokens (Anthropic), но 12 июня Anthropic сообщила, что отключила доступ клиентов к Fable 5 и Mythos 5, выполняя директиву правительства США (Anthropic statement). Так что проверяйте live access перед планированием прогона. Когда модель доступна через вашего провайдера, применяется тот же harness; upgrade модели не отменяет необходимости в оракуле.
Паттерн, который стоит украсть
Историю Rakuten легко неверно прочитать как «Claude Code теперь справляется с огромными repo». Это слишком расплывчато, чтобы быть полезным.
Лучший вывод такой: длинное автономное кодирование работает, когда задача ограничена оракулом, планом, review checkpoints и границами отката. Агент может быть креативным внутри этих ограничений. Без них «proactive» превращается в «unbounded», а unbounded coding agents — это способ получить скрытые баги с уверенным финальным сообщением.
Для ML-инфраструктурных и platform teams playbook простой:
- Выбирайте задачи с измеримым завершением: numerical match, migration count, latency budget, compatibility matrix.
- Пишите test oracle до feature.
- Жёстко разделяйте explore-plan-code.
- Держите rollback boundaries маленькими.
- Ревьюйте evidence, а не claims.
- Используйте второй context, чтобы атаковать diff до того, как люди его одобрят.
Так семичасовой автономный прогон превращается из трюка в инженерный workflow.
Если хотите попробовать такой long-task workflow, когда доступ будет открыт, смотрите Claude Fable 5 on OneHop и start with $10 free.
Дополнительно: Getting started with Claude Fable 5.

