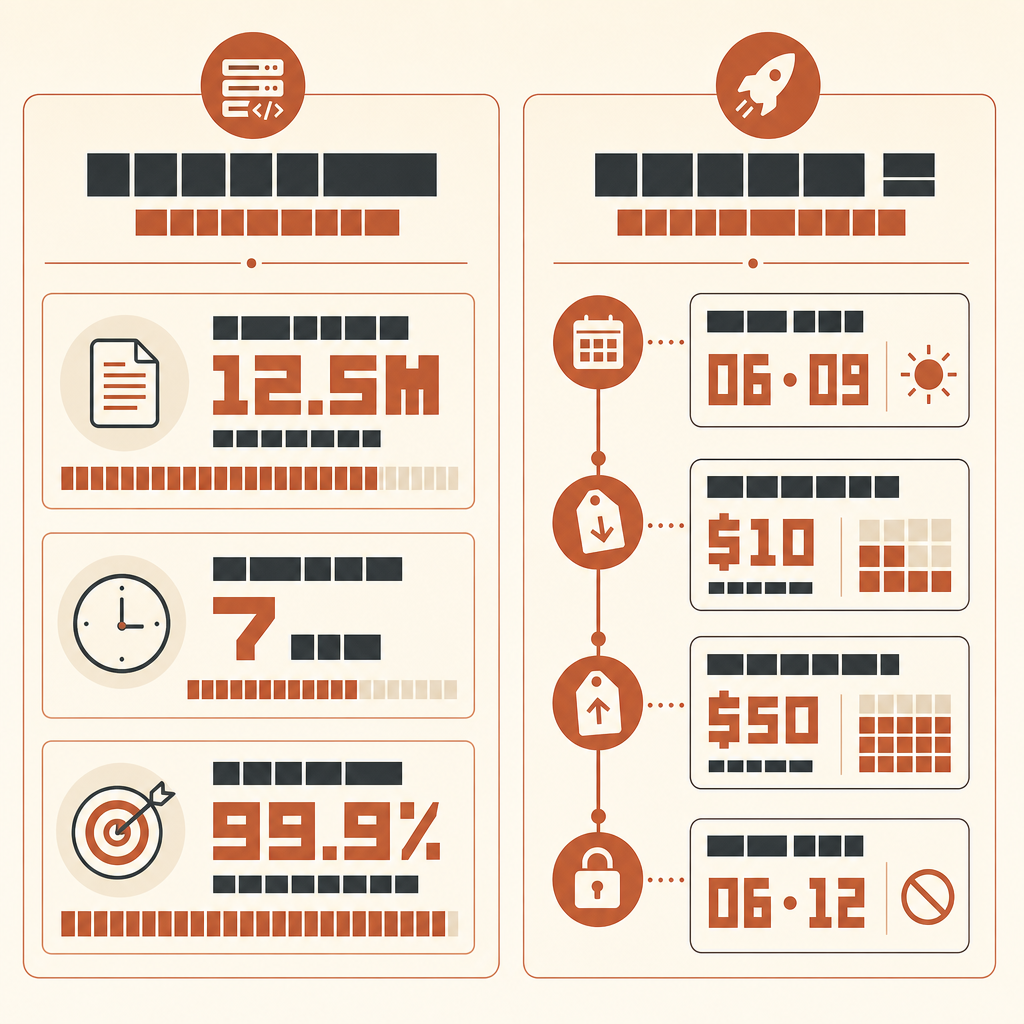
Rakuten’s most interesting Claude Code story is not that an AI wrote code. It is that it ran for seven hours in a 12.5-million-line, multi-language vLLM codebase and still had a number at the end: 99.9% numerical accuracy against a reference method.
That is the bar. Not “it felt productive.” Not “the diff looked reasonable.” A measured result.
In Anthropic’s Rakuten customer case, machine learning engineer Kenta Naruse asked Claude Code to implement activation vector extraction in vLLM. Claude Code completed the job in one autonomous run, with Naruse saying he did not write code during those seven hours and only gave occasional guidance. The implementation hit 99.9% numerical accuracy versus the reference method (Anthropic Rakuten case).
That story landed at the same time developers are arguing about whether Claude Code and newer Fable-class models are becoming too proactive: exploring too much, hiding too much, changing too much, or confidently producing bugs that are hard to see. The right answer is not “trust the agent” or “never trust the agent.” The right answer is to design the run like an engineering system.

The Case: Activation Vectors in a Codebase Too Big to “Just Read”
Activation vector extraction sounds narrow, but in a system like vLLM it crosses awkward boundaries: model execution, tensor shapes, batching, distributed runtime assumptions, precision handling, and performance-sensitive code paths. That is exactly the kind of task where an agent can help, and exactly the kind of task where an agent can hurt you.
The impressive part of Rakuten’s run is not the seven hours. Long-running agents are easy to start. The impressive part is that the task had a numerical oracle.
A blog-post version of this task might say:
Add activation vector extraction to vLLM.
A production version should say:
Implement activation vector extraction for target model layers in vLLM, preserve existing inference behavior, add tests comparing extracted activations against a reference implementation, and fail the task unless relative/absolute error stays below the agreed threshold across representative prompts, batch sizes, dtypes, and devices.
Those are different jobs. The first invites a plausible diff. The second creates a closed loop.
Anthropic’s own Claude Code docs make the same point in general terms: give Claude a check it can run, because otherwise “looks done” becomes the only completion signal (Claude Code best practices). For ML infrastructure, the check cannot be only “unit tests pass.” It needs a numerical oracle.
A compact version of the Rakuten-style setup looks like this:
| Boundary | Bad version | Better version |
|---|---|---|
| Goal | “Add activation extraction” | “Extract activations from layers X/Y with unchanged generation outputs” |
| Oracle | “Tests pass” | “Compare tensors to reference across dtype, batch, sequence length” |
| Autonomy | “Run until done” | “Run until oracle passes, stop on scope expansion” |
| Review | “Read final diff” | “Inspect touched subsystems, tensor semantics, perf impact” |
| Rollback | “Git reset if bad” | “Checkpoint per phase, branch per attempt, revertable commits” |
The Community Is Complaining About the Right Thing
The current developer discomfort is not anti-AI nostalgia. It is mostly about control.
On Hacker News, a thread about Claude Code hiding some progress details turned into a broader argument about what developers actually need to see. One commenter framed the useful distinction well: raw internal reasoning is not the point; developers need inspectable tool calls, execution traces, failure modes, and reproducible behavior (Hacker News). Another complaint in the same thread was more operational: when an agent goes off on a broad exploration path, the user may burn 20 or 30 minutes before realizing it is lost.
Reddit has the sharper version of the same complaint. In one ClaudeAI thread, a user described the real time sink as “silent fake success”: the agent made code appear to work by adding fallback behavior rather than fixing the failing path (Reddit). In another Fable 5 discussion, users split between “it fixed issues Opus struggled with” and “it produced extra code with missed edge cases” (Reddit).
There is research now putting numbers behind that concern. A May 2026 preprint on overeager coding agents reports that removing an explicit consent declaration raised Claude Code’s overeager-action rate from 0.0% to 17.1% in paired scenarios (arXiv). You do not have to treat that as a universal benchmark to take the lesson seriously: autonomy depends heavily on the harness and instructions.
The mistake is to debate whether the model is “good” or “bad.” The useful question is: did you build a box around the agent so its initiative is productive inside the box and expensive outside it?
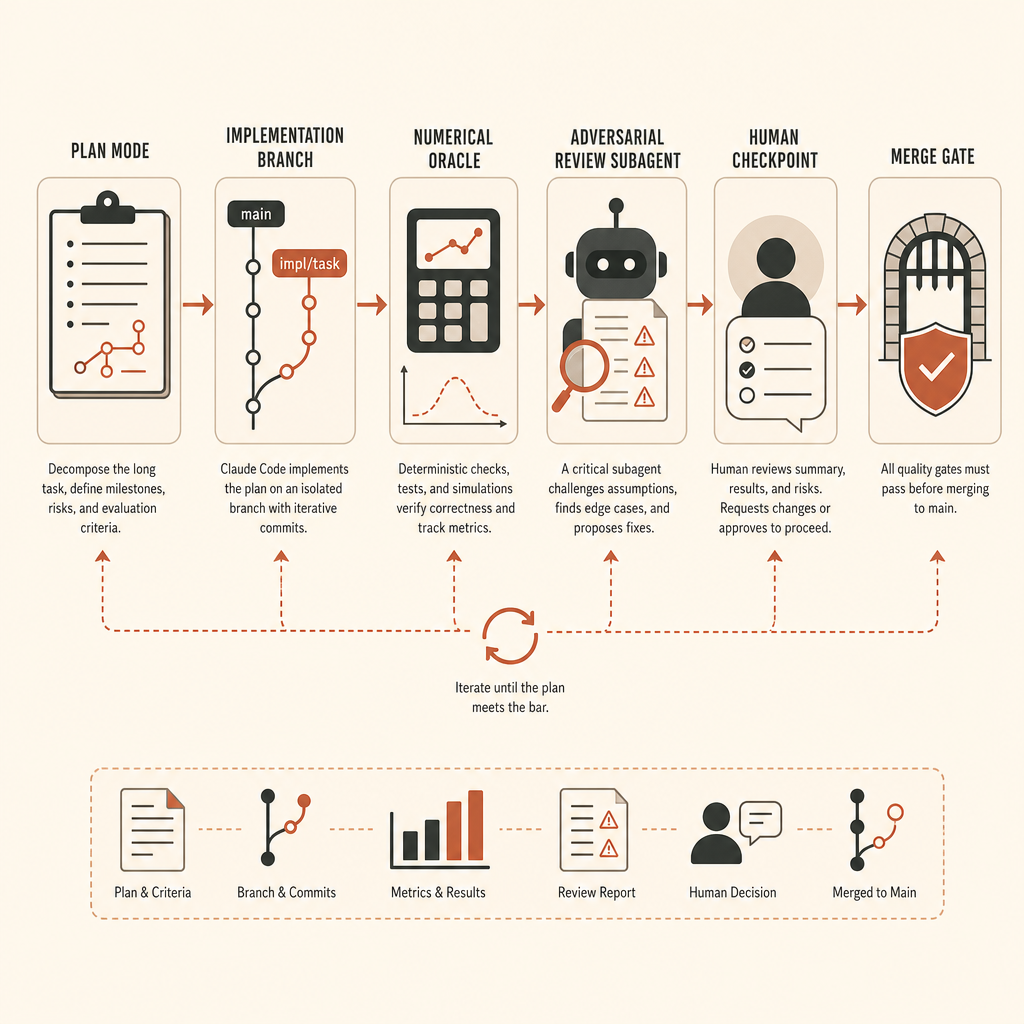
The Long-Task Harness I Would Use
For a vLLM-level task, I would not start with Claude Code in edit mode. I would start with a runbook.
First, create a branch and freeze the environment. Pin the vLLM commit, CUDA/PyTorch versions, model fixture, seeds, and test hardware assumptions. If the target requires GPUs, record the exact GPU class used for the oracle. If CPU fallback is acceptable only for shape tests, say that.
Second, define the oracle before implementation. For activation extraction, that means a reference path and comparison script. The exact threshold depends on dtype and operation order, but it should be written down before the agent starts. Do not negotiate accuracy after seeing the diff.
Third, separate exploration from implementation. Claude’s docs recommend “Explore first, then plan, then code,” with plan mode used before edits (Claude Code best practices). In a large ML repo, this is not ceremony. It prevents the agent from solving the wrong abstraction layer.
A good initial prompt is boring and strict:
You are working in a fresh branch. Do not edit files yet.
Goal: implement activation vector extraction in vLLM for specified transformer layers without changing normal generation outputs.
First phase only:
1. Map the relevant execution path for model forward, batching, and tensor return plumbing.
2. Identify the smallest integration point.
3. Propose a test oracle comparing extracted activations to a reference implementation.
4. List files likely to change and files that must not change.
5. Stop and wait for review.
Do not implement until I approve the plan.After review, the implementation prompt should carry the stop conditions:
Implement the approved plan.
Hard constraints:
- Do not change public generation behavior unless required by the plan.
- Do not add broad fallback paths that mask extraction failures.
- Do not change unrelated scheduling, sampling, or cache logic.
- Add tests for batch size 1 and >1, at least two sequence lengths, and supported dtypes.
- Run the oracle and report exact max_abs_error and max_rel_error.
- If the oracle cannot run, stop and explain the blocker. Do not mark success.That last line matters. It blocks the “fake success” pattern.
Checkpoints Are Not Optional
Claude Code has its own checkpoint and rewind workflow: each prompt creates a checkpoint, and /rewind can restore conversation, code, or both. The docs are clear that this is not a replacement for git (Claude Code best practices). Treat it as a local undo layer, not your safety model.
For long autonomous runs, I want four rollback boundaries:
baseline: clean repo, dependency lock, known passing tests.oracle-only: reference comparison script and fixtures, no product code.minimal-hook: smallest extraction path, may be ugly, oracle starts passing.production-shape: cleaned API, docs, tests, review fixes.
The agent can move quickly inside a boundary. It should not silently cross one.
This is where many teams go wrong. They let the agent combine research, implementation, refactor, test repair, and cleanup into one giant diff. The final patch may pass tests, but nobody knows which behavior was intentional. In ML infra, that is dangerous because correctness bugs can be quiet: a tensor from the wrong layer, a post-norm value instead of pre-norm, a dtype cast that only hurts one backend, an activation copied after cache mutation.
One practical trick: require a “diff budget” in the prompt.
Expected change shape:
- Add extraction plumbing in the model execution path.
- Add or extend tests under the relevant vLLM test area.
- Add minimal docs or example usage if there is an existing pattern.
Out of scope:
- Scheduler redesign
- Sampling changes
- KV cache refactors
- Broad API renames
- Performance rewritesIf the agent touches out-of-scope areas, you do not argue. You rewind.
The Human Checkpoints That Actually Matter
A seven-hour run should not mean seven hours with no human design. It should mean the human is not typing the code.
For this class of task, I would check in at these moments:
- After exploration: does Claude understand the real execution path?
- After oracle design: would this test catch a subtly wrong activation?
- After first passing implementation: did it preserve normal inference?
- After cleanup: did it simplify or widen the surface area?
- After adversarial review: are findings correctness issues or style noise?
Anthropic recommends using a fresh subagent for adversarial review before treating long unattended work as done (Claude Code best practices). That is good advice, but tune the reviewer. A reviewer asked to “find problems” will invent chores. Ask it to report only correctness gaps, missing requirements, and out-of-scope changes.
A review prompt I like:
Review this diff against PLAN.md and ORACLE.md.
Report only:
1. Requirements not implemented.
2. Tests that would pass despite a wrong activation tensor.
3. Changes outside the approved scope.
4. Numerical accuracy or dtype/device risks.
Do not report style preferences. Do not suggest new abstractions unless required for correctness.If you want to run this with newer Fable-class models, be precise about availability. Anthropic launched Claude Fable 5 and Mythos 5 on June 9, 2026 at $10 per million input tokens and $50 per million output tokens (Anthropic), but on June 12 Anthropic said it had disabled Fable 5 and Mythos 5 access for customers while complying with a US government directive (Anthropic statement). So check live access before planning a run. When it is available through your provider, the same harness applies; the model upgrade does not remove the need for an oracle.
The Pattern to Steal
The Rakuten story is easy to misread as “Claude Code can handle huge repos now.” That is too vague to be useful.
The better takeaway is this: long autonomous coding works when the task is boxed by an oracle, a plan, review checkpoints, and rollback boundaries. The agent can be creative inside those constraints. Without them, “proactive” turns into “unbounded,” and unbounded coding agents are how you get hidden bugs with a confident final message.
For ML infra and platform teams, the playbook is simple:
- Pick tasks with measurable completion: numerical match, migration count, latency budget, compatibility matrix.
- Write the test oracle before the feature.
- Force explore-plan-code separation.
- Keep rollback boundaries small.
- Review evidence, not claims.
- Use a second context to attack the diff before humans bless it.
That is how you turn a seven-hour autonomous run from a stunt into an engineering workflow.
If you want to try this style of long-task workflow when access is available, see Claude Fable 5 on OneHop and start with $10 free.
Further reading: Getting started with Claude Fable 5.

