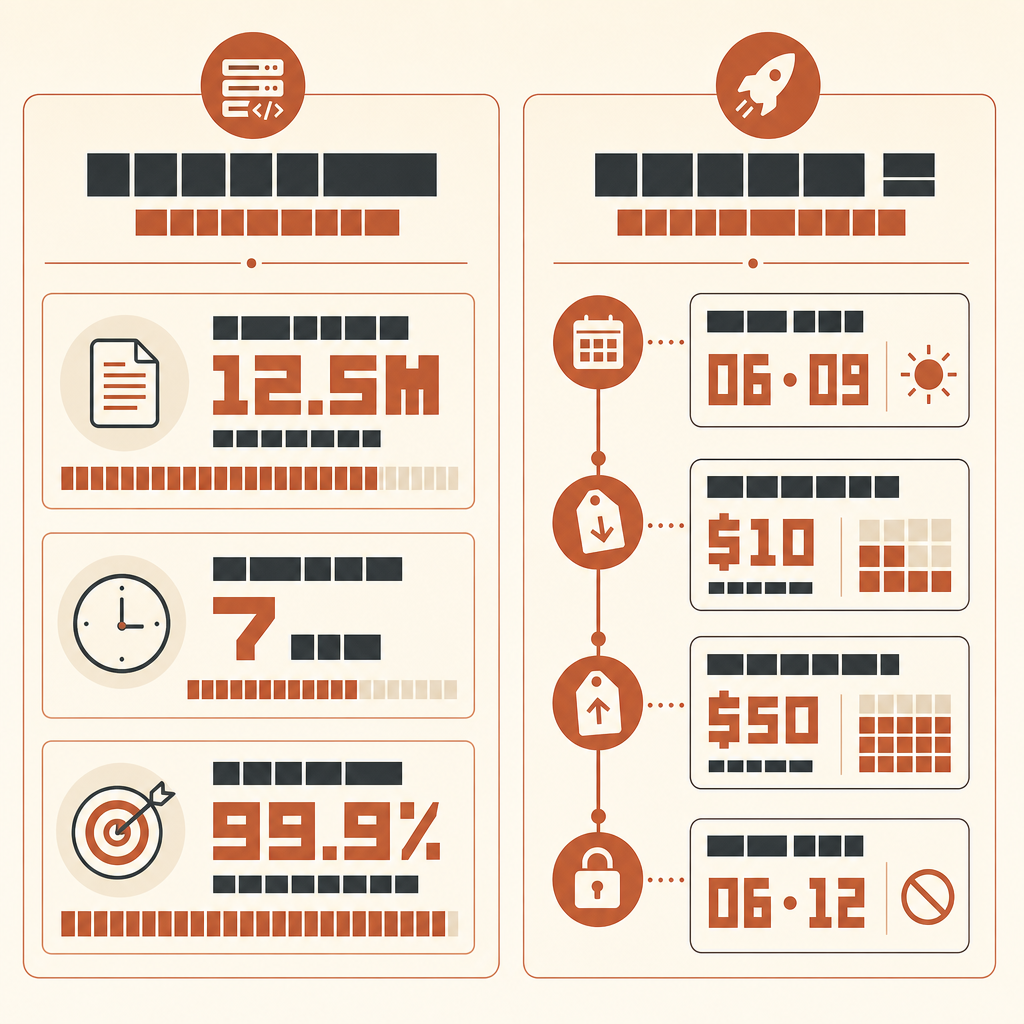
Rakuten 最有意思的 Claude Code 故事,并不是 AI 写了代码。而是它在一个 1250 万行、多语言的 vLLM 代码库里跑了七个小时,最后还能拿出一个数字:相对参考方法达到 99.9% 的数值准确率。
这才是门槛。不是“感觉效率挺高”。不是“diff 看起来合理”。而是一个可度量的结果。
在 Anthropic 的 Rakuten 客户案例里,机器学习工程师 Kenta Naruse 让 Claude Code 在 vLLM 中实现激活向量提取。Claude Code 在一次自主运行中完成了任务,Naruse 说那七个小时里他没有写代码,只是偶尔给些指导。这个实现相对参考方法达到了 99.9% 的数值准确率(Anthropic Rakuten case)。
这个故事出现的同时,开发者们也正在争论 Claude Code 和更新的 Fable 级模型是不是变得太主动了:探索太多、隐藏太多、改动太多,或者自信地造出很难发现的 bug。正确答案不是“相信 agent”,也不是“永远别信 agent”。正确答案是:把这次运行设计成一个工程系统。

案例:在一个大到没法“直接读完”的代码库里做激活向量
激活向量提取听起来范围很窄,但在 vLLM 这样的系统里,它会跨过一堆别扭的边界:模型执行、张量形状、批处理、分布式运行时假设、精度处理,以及性能敏感的代码路径。这正是 agent 能帮上忙的任务类型,也正是 agent 可能害你的任务类型。
Rakuten 这次运行真正厉害的地方不是七个小时。长时间运行的 agent 很容易启动。厉害的是,这个任务有一个数值 oracle。
博客文章版本的任务可能会这么写:
给 vLLM 加上激活向量提取。
生产版本应该这么写:
在 vLLM 中为目标模型层实现激活向量提取,保持现有推理行为不变,添加测试将提取出的激活与参考实现对比,并且除非在代表性 prompts、batch sizes、dtypes 和 devices 上相对/绝对误差都低于约定阈值,否则任务失败。
这是两种完全不同的工作。前者会诱导出一个看起来合理的 diff。后者则建立了一个闭环。
Anthropic 自己的 Claude Code 文档也用更通用的说法讲了同一点:给 Claude 一个它能运行的检查,否则“看起来做完了”就会变成唯一的完成信号(Claude Code best practices)。对于 ML 基础设施来说,这个检查不能只是“单元测试通过”。它需要一个数值 oracle。
Rakuten 式配置的精简版大概是这样:
| Boundary | Bad version | Better version |
|---|---|---|
| Goal | “添加激活提取” | “从 X/Y 层提取激活,同时生成输出保持不变” |
| Oracle | “测试通过” | “跨 dtype、batch、序列长度对比张量与参考结果” |
| Autonomy | “一直跑到完成” | “一直跑到 oracle 通过,遇到范围扩张就停” |
| Review | “看最终 diff” | “检查涉及的子系统、张量语义、性能影响” |
| Rollback | “坏了就 Git reset” | “按阶段 checkpoint,每次尝试一个 branch,可回滚 commit” |
社区抱怨的方向是对的
现在开发者的不适,并不是反 AI 的怀旧情绪。主要问题是控制权。
在 Hacker News 上,一个关于 Claude Code 隐藏部分进度细节的帖子,演变成了关于开发者到底需要看到什么的更大争论。有位评论者把有用的区别讲得很好:原始内部推理不是重点;开发者需要的是可检查的 tool calls、执行轨迹、失败模式和可复现行为(Hacker News)。同一串讨论里的另一个抱怨更偏操作层面:当 agent 跑去做宽泛探索时,用户可能要烧掉 20 或 30 分钟才意识到它已经迷路了。
Reddit 上的版本更尖锐。在一个 ClaudeAI 讨论串里,有用户把真正耗时的坑描述为“silent fake success”:agent 不是修掉失败路径,而是加了 fallback 行为,让代码看起来能跑(Reddit)。在另一个 Fable 5 讨论里,用户分成两派:有人说“它修好了 Opus 卡住的问题”,也有人说“它写了额外代码,却漏掉了边界情况”(Reddit)。
现在也有研究开始给这种担忧标数字。2026 年 5 月一篇关于过度积极 coding agents 的预印本报告称,在成对场景中,移除明确同意声明会让 Claude Code 的过度积极行动率从 0.0% 上升到 17.1%(arXiv)。你不必把它当成通用基准,也应该认真对待这个教训:自主性高度依赖 harness 和指令。
错误做法是争论模型到底“好”还是“坏”。有用的问题是:你有没有给 agent 搭一个盒子,让它在盒子里的主动性有产出,而盒子外的主动性代价高昂?
我会使用的长任务 Harness
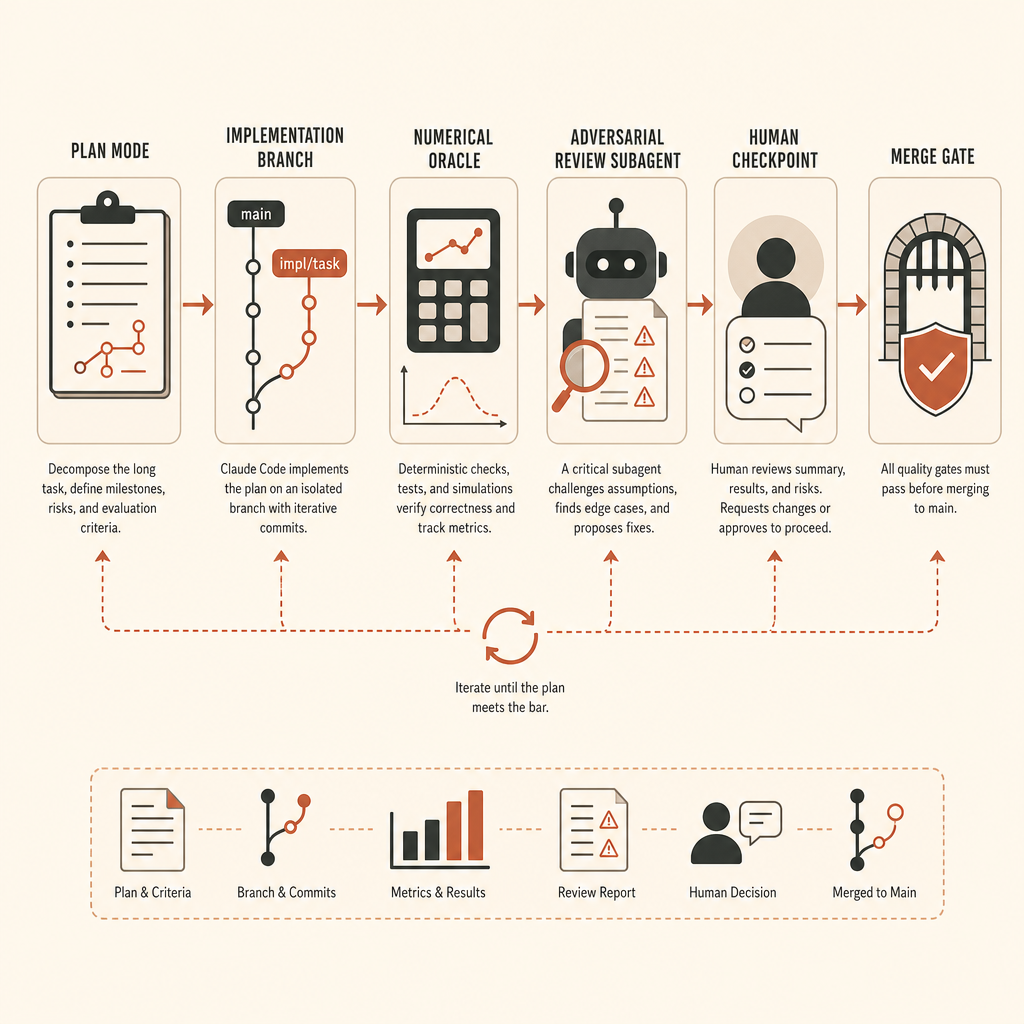
对于 vLLM 级别的任务,我不会一上来就让 Claude Code 进入编辑模式。我会先写 runbook。
第一步,创建 branch 并冻结环境。固定 vLLM commit、CUDA/PyTorch 版本、模型 fixture、seeds 和测试硬件假设。如果目标需要 GPU,就记录 oracle 使用的确切 GPU class。如果 CPU fallback 只适用于 shape tests,也要写清楚。
第二步,先定义 oracle,再实现。对于激活提取,这意味着一条参考路径和一个对比脚本。具体阈值取决于 dtype 和运算顺序,但必须在 agent 开始前写下来。不要看到 diff 之后再谈准确率。
第三步,把探索和实现分开。Claude 的文档建议“先探索,再计划,再写代码”,并在编辑前使用 plan mode(Claude Code best practices)。在大型 ML repo 里,这不是仪式感。它能防止 agent 在错误的抽象层上解决问题。
一个好的初始 prompt 很无聊,也很严格:
You are working in a fresh branch. Do not edit files yet.
Goal: implement activation vector extraction in vLLM for specified transformer layers without changing normal generation outputs.
First phase only:
1. Map the relevant execution path for model forward, batching, and tensor return plumbing.
2. Identify the smallest integration point.
3. Propose a test oracle comparing extracted activations to a reference implementation.
4. List files likely to change and files that must not change.
5. Stop and wait for review.
Do not implement until I approve the plan.审核之后,实现 prompt 应该带上停止条件:
Implement the approved plan.
Hard constraints:
- Do not change public generation behavior unless required by the plan.
- Do not add broad fallback paths that mask extraction failures.
- Do not change unrelated scheduling, sampling, or cache logic.
- Add tests for batch size 1 and >1, at least two sequence lengths, and supported dtypes.
- Run the oracle and report exact max_abs_error and max_rel_error.
- If the oracle cannot run, stop and explain the blocker. Do not mark success.最后一行很关键。它会挡住“fake success”模式。
Checkpoints 不是可选项
Claude Code 有自己的 checkpoint 和 rewind 工作流:每个 prompt 都会创建一个 checkpoint,/rewind 可以恢复对话、代码,或两者都恢复。文档说得很清楚,这不能替代 git(Claude Code best practices)。把它当成本地 undo 层,而不是你的安全模型。
对于长时间自主运行,我希望有四个回滚边界:
baseline: 干净 repo、依赖锁定、已知通过的测试。oracle-only: 参考对比脚本和 fixtures,没有产品代码。minimal-hook: 最小提取路径,可能很丑,但 oracle 开始通过。production-shape: 清理后的 API、文档、测试、review fixes。
agent 可以在一个边界内部快速移动。它不应该悄悄跨过边界。
这正是很多团队出问题的地方。他们让 agent 把研究、实现、重构、修测试和清理全都揉进一个巨大的 diff。最终 patch 可能通过测试,但没人知道哪些行为是有意的。在 ML 基础设施里,这很危险,因为正确性 bug 可能很安静:来自错误层的张量,post-norm 而不是 pre-norm 的值,只伤害某个 backend 的 dtype cast,或者 cache mutation 之后才复制出来的 activation。
一个实用技巧:在 prompt 里要求“diff budget”。
Expected change shape:
- Add extraction plumbing in the model execution path.
- Add or extend tests under the relevant vLLM test area.
- Add minimal docs or example usage if there is an existing pattern.
Out of scope:
- Scheduler redesign
- Sampling changes
- KV cache refactors
- Broad API renames
- Performance rewrites如果 agent 碰了超出范围的区域,你不用争。直接 rewind。
真正重要的人类 Checkpoints
七小时运行不应该等于七小时没有人类设计。它应该意味着人类没有在敲代码。
对于这类任务,我会在这些时刻介入检查:
- 探索之后:Claude 是否理解了真实执行路径?
- oracle 设计之后:这个测试能抓住“看似很接近但其实错了”的 activation 吗?
- 首次通过实现之后:它是否保留了正常推理行为?
- 清理之后:它是在简化表面积,还是扩大表面积?
- 对抗性审查之后:发现的是正确性问题,还是风格噪音?
Anthropic 建议在把长时间无人值守工作视为完成之前,用一个新的 subagent 做对抗性审查(Claude Code best practices)。这是好建议,但要调好 reviewer。让 reviewer “找问题”,它会发明杂活。要求它只报告正确性缺口、缺失需求和超出范围的改动。
我喜欢这样的 review prompt:
Review this diff against PLAN.md and ORACLE.md.
Report only:
1. Requirements not implemented.
2. Tests that would pass despite a wrong activation tensor.
3. Changes outside the approved scope.
4. Numerical accuracy or dtype/device risks.
Do not report style preferences. Do not suggest new abstractions unless required for correctness.如果你想用更新的 Fable 级模型跑这套流程,要精确确认可用性。Anthropic 在 2026 年 6 月 9 日发布了 Claude Fable 5 和 Mythos 5,定价为每百万 input tokens 10 美元、每百万 output tokens 50 美元(Anthropic),但 6 月 12 日 Anthropic 表示,为遵守美国政府指令,已暂停客户访问 Fable 5 和 Mythos 5(Anthropic statement)。所以在规划运行前,先检查实时访问情况。等它能通过你的 provider 使用时,同一套 harness 仍然适用;模型升级不会让 oracle 变得可有可无。
值得照搬的模式
Rakuten 这个故事很容易被误读成“Claude Code 现在能处理超大 repo 了”。这句话太泛,没什么用。
更好的结论是:当任务被 oracle、计划、review checkpoints 和回滚边界框住时,长时间自主编码才行得通。agent 可以在这些约束里发挥创造力。没有这些约束,“proactive”就会变成“unbounded”,而失控的 coding agents 正是带着自信最终消息交付隐藏 bug 的方式。
对于 ML 基础设施和平台团队,playbook 很简单:
- 选择有可度量完成条件的任务:数值匹配、迁移数量、延迟预算、兼容性矩阵。
- 先写 test oracle,再写功能。
- 强制分离 explore-plan-code。
- 保持回滚边界很小。
- 审查证据,而不是声明。
- 在人类批准之前,用第二个 context 攻击 diff。
这才是把七小时自主运行从噱头变成工程工作流的方法。
如果你想在访问可用时尝试这种长任务工作流,可以看看 Claude Fable 5 on OneHop,并从 10 美元免费额度开始。

