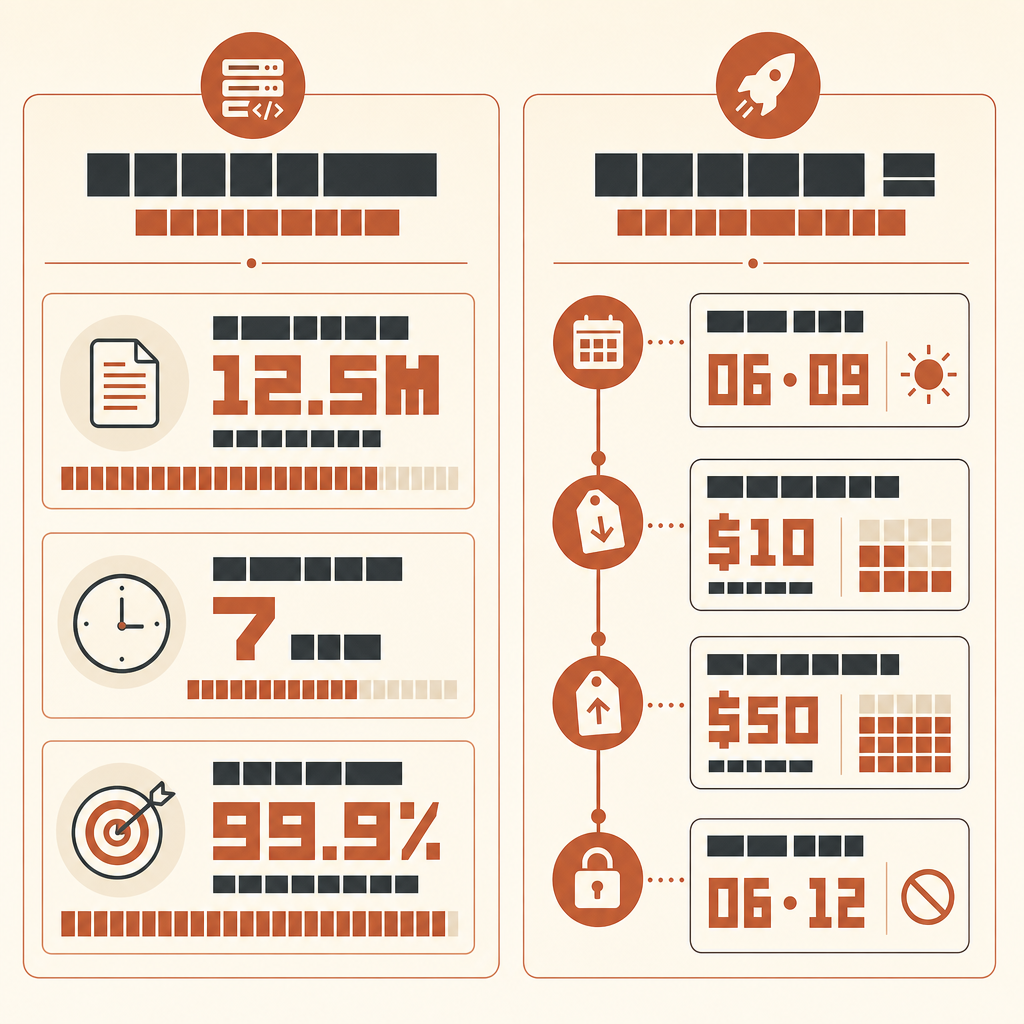
La historia más interesante de Rakuten con Claude Code no es que una IA escribiera código. Es que estuvo siete horas trabajando en una base de código vLLM de 12,5 millones de líneas y varios lenguajes, y aun así terminó con un número al final: 99,9% de precisión numérica frente a un método de referencia.
Ese es el listón. No “parecía productivo”. No “el diff tenía buena pinta”. Un resultado medido.
En el caso de cliente de Rakuten publicado por Anthropic, el ingeniero de machine learning Kenta Naruse pidió a Claude Code que implementara la extracción de vectores de activación en vLLM. Claude Code completó el trabajo en una sola ejecución autónoma, y Naruse dijo que no escribió código durante esas siete horas y que solo dio orientación ocasional. La implementación alcanzó un 99,9% de precisión numérica frente al método de referencia (caso de Rakuten de Anthropic).
Esa historia llegó justo cuando los desarrolladores discuten si Claude Code y los nuevos modelos de clase Fable se están volviendo demasiado proactivos: exploran demasiado, ocultan demasiado, cambian demasiado o generan bugs con demasiada seguridad y difíciles de detectar. La respuesta correcta no es “confía en el agente” ni “no confíes nunca en el agente”. La respuesta correcta es diseñar la ejecución como un sistema de ingeniería.

El caso: vectores de activación en una base de código demasiado grande para “leerla sin más”
La extracción de vectores de activación suena acotada, pero en un sistema como vLLM cruza fronteras incómodas: ejecución del modelo, formas de tensores, batching, supuestos del runtime distribuido, manejo de precisión y rutas de código sensibles al rendimiento. Es exactamente el tipo de tarea en la que un agente puede ayudar, y exactamente el tipo de tarea en la que un agente puede hacer daño.
Lo impresionante de la ejecución de Rakuten no son las siete horas. Poner en marcha agentes de larga duración es fácil. Lo impresionante es que la tarea tenía un oráculo numérico.
La versión de blog de esta tarea podría decir:
Añade extracción de vectores de activación a vLLM.
Una versión de producción debería decir:
Implementa extracción de vectores de activación para capas objetivo del modelo en vLLM, conserva el comportamiento de inferencia existente, añade pruebas que comparen las activaciones extraídas con una implementación de referencia y falla la tarea salvo que el error relativo/absoluto se mantenga por debajo del umbral acordado en prompts, tamaños de batch, dtypes y dispositivos representativos.
Son trabajos distintos. El primero invita a un diff plausible. El segundo crea un bucle cerrado.
La propia documentación de Claude Code de Anthropic dice lo mismo en términos generales: dale a Claude una comprobación que pueda ejecutar, porque si no “parece terminado” se convierte en la única señal de finalización (buenas prácticas de Claude Code). Para infraestructura de ML, la comprobación no puede ser solo “pasan los tests unitarios”. Necesita un oráculo numérico.
Una versión compacta del enfoque estilo Rakuten se ve así:
| Límite | Mala versión | Mejor versión |
|---|---|---|
| Objetivo | “Añadir extracción de activaciones” | “Extraer activaciones de las capas X/Y sin cambiar las salidas de generación” |
| Oráculo | “Pasan los tests” | “Comparar tensores con una referencia según dtype, batch y longitud de secuencia” |
| Autonomía | “Ejecutar hasta terminar” | “Ejecutar hasta que pase el oráculo, parar si se amplía el alcance” |
| Revisión | “Leer el diff final” | “Inspeccionar subsistemas tocados, semántica de tensores e impacto en rendimiento” |
| Rollback | “Git reset si sale mal” | “Checkpoint por fase, rama por intento, commits reversibles” |
La comunidad se queja de lo correcto
La incomodidad actual de los desarrolladores no es nostalgia anti-IA. Es, sobre todo, una cuestión de control.
En Hacker News, un hilo sobre Claude Code ocultando algunos detalles de progreso se convirtió en una discusión más amplia sobre lo que los desarrolladores realmente necesitan ver. Un comentarista formuló bien la distinción útil: el razonamiento interno bruto no es lo importante; los desarrolladores necesitan llamadas a herramientas inspeccionables, trazas de ejecución, modos de fallo y comportamiento reproducible (Hacker News). Otra queja en el mismo hilo era más operativa: cuando un agente se va por una ruta de exploración demasiado amplia, el usuario puede quemar 20 o 30 minutos antes de darse cuenta de que está perdido.
Reddit tiene la versión más afilada de la misma queja. En un hilo de ClaudeAI, un usuario describió el verdadero sumidero de tiempo como “éxito falso y silencioso”: el agente hacía que el código pareciera funcionar añadiendo comportamiento de fallback en lugar de arreglar la ruta que fallaba (Reddit). En otra discusión sobre Fable 5, los usuarios se dividían entre “arregló problemas con los que Opus sufría” y “produjo código extra con casos límite pasados por alto” (Reddit).
Ya hay investigación que pone números a esa preocupación. Un preprint de mayo de 2026 sobre agentes de codificación demasiado ansiosos informa de que eliminar una declaración explícita de consentimiento elevó la tasa de acciones excesivamente proactivas de Claude Code del 0,0% al 17,1% en escenarios emparejados (arXiv). No tienes que tratarlo como un benchmark universal para tomarte en serio la lección: la autonomía depende muchísimo del arnés y de las instrucciones.
El error es debatir si el modelo es “bueno” o “malo”. La pregunta útil es: ¿construiste una caja alrededor del agente para que su iniciativa sea productiva dentro de la caja y cara fuera de ella?
El arnés de tareas largas que yo usaría
Para una tarea al nivel de vLLM, no empezaría con Claude Code en modo edición. Empezaría con un runbook.
Primero, crea una rama y congela el entorno. Fija el commit de vLLM, las versiones de CUDA/PyTorch, el fixture del modelo, las semillas y los supuestos de hardware de test. Si el objetivo requiere GPU, registra la clase exacta de GPU usada para el oráculo. Si el fallback a CPU solo es aceptable para pruebas de forma, dilo.
Segundo, define el oráculo antes de implementar. Para la extracción de activaciones, eso significa una ruta de referencia y un script de comparación. El umbral exacto depende del dtype y del orden de las operaciones, pero debe quedar escrito antes de que empiece el agente. No negocies la precisión después de ver el diff.
Tercero, separa la exploración de la implementación. La documentación de Claude recomienda “explorar primero, luego planificar y después codificar”, usando el modo plan antes de editar (buenas prácticas de Claude Code). En un repositorio grande de ML, esto no es ceremonia. Evita que el agente resuelva la capa de abstracción equivocada.
Un buen prompt inicial es aburrido y estricto:
You are working in a fresh branch. Do not edit files yet.
Goal: implement activation vector extraction in vLLM for specified transformer layers without changing normal generation outputs.
First phase only:
1. Map the relevant execution path for model forward, batching, and tensor return plumbing.
2. Identify the smallest integration point.
3. Propose a test oracle comparing extracted activations to a reference implementation.
4. List files likely to change and files that must not change.
5. Stop and wait for review.
Do not implement until I approve the plan.Tras la revisión, el prompt de implementación debe llevar las condiciones de parada:
Implement the approved plan.
Hard constraints:
- Do not change public generation behavior unless required by the plan.
- Do not add broad fallback paths that mask extraction failures.
- Do not change unrelated scheduling, sampling, or cache logic.
- Add tests for batch size 1 and >1, at least two sequence lengths, and supported dtypes.
- Run the oracle and report exact max_abs_error and max_rel_error.
- If the oracle cannot run, stop and explain the blocker. Do not mark success.Esa última línea importa. Bloquea el patrón de “éxito falso”.
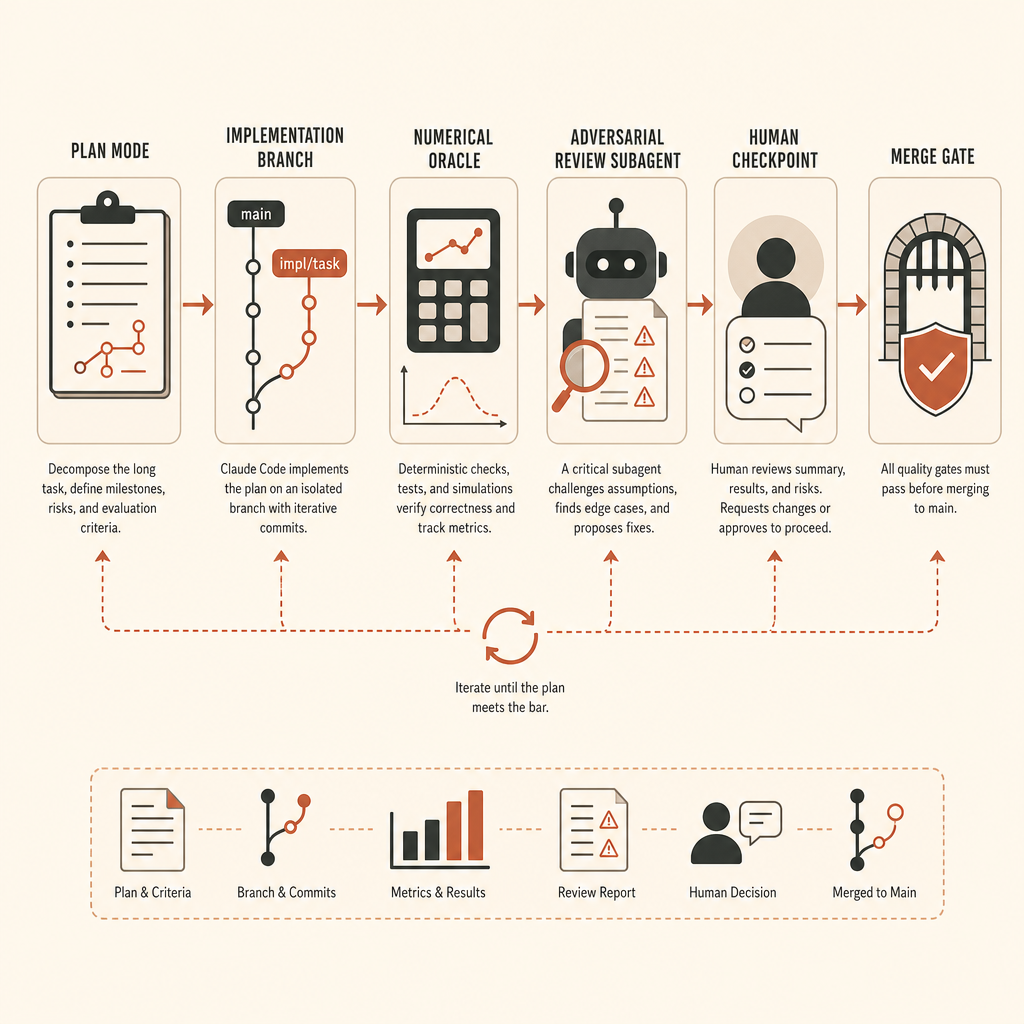
Los checkpoints no son opcionales
Claude Code tiene su propio flujo de checkpoints y retroceso: cada prompt crea un checkpoint, y /rewind puede restaurar la conversación, el código o ambas cosas. La documentación deja claro que esto no sustituye a git (buenas prácticas de Claude Code). Trátalo como una capa local de deshacer, no como tu modelo de seguridad.
Para ejecuciones autónomas largas, quiero cuatro límites de rollback:
baseline: repositorio limpio, dependencias bloqueadas, tests conocidos pasando.oracle-only: script de comparación de referencia y fixtures, sin código de producto.minimal-hook: la ruta de extracción más pequeña, quizá fea, el oráculo empieza a pasar.production-shape: API limpia, documentación, tests, arreglos de revisión.
El agente puede moverse rápido dentro de un límite. No debería cruzar uno en silencio.
Aquí es donde muchos equipos se equivocan. Dejan que el agente combine investigación, implementación, refactor, reparación de tests y limpieza en un diff gigante. El parche final puede pasar los tests, pero nadie sabe qué comportamiento fue intencional. En infraestructura de ML, eso es peligroso porque los bugs de corrección pueden ser silenciosos: un tensor de la capa equivocada, un valor post-norm en lugar de pre-norm, un cast de dtype que solo perjudica a un backend, una activación copiada después de una mutación de caché.
Un truco práctico: exige un “presupuesto de diff” en el prompt.
Expected change shape:
- Add extraction plumbing in the model execution path.
- Add or extend tests under the relevant vLLM test area.
- Add minimal docs or example usage if there is an existing pattern.
Out of scope:
- Scheduler redesign
- Sampling changes
- KV cache refactors
- Broad API renames
- Performance rewritesSi el agente toca áreas fuera de alcance, no discutes. Rebobinas.
Los checkpoints humanos que de verdad importan
Una ejecución de siete horas no debería significar siete horas sin diseño humano. Debería significar que el humano no está tecleando el código.
Para esta clase de tarea, yo haría check-in en estos momentos:
- Después de la exploración: ¿Claude entiende la ruta de ejecución real?
- Después del diseño del oráculo: ¿esta prueba detectaría una activación sutilmente equivocada?
- Después de la primera implementación que pasa: ¿conservó la inferencia normal?
- Después de la limpieza: ¿simplificó o amplió la superficie?
- Después de la revisión adversarial: ¿los hallazgos son problemas de corrección o ruido de estilo?
Anthropic recomienda usar un subagente nuevo para revisión adversarial antes de dar por terminado trabajo largo sin supervisión (buenas prácticas de Claude Code). Es un buen consejo, pero ajusta el revisor. Un revisor al que le pides “encuentra problemas” inventará tareas. Pídele que informe solo de brechas de corrección, requisitos faltantes y cambios fuera de alcance.
Un prompt de revisión que me gusta:
Review this diff against PLAN.md and ORACLE.md.
Report only:
1. Requirements not implemented.
2. Tests that would pass despite a wrong activation tensor.
3. Changes outside the approved scope.
4. Numerical accuracy or dtype/device risks.
Do not report style preferences. Do not suggest new abstractions unless required for correctness.Si quieres ejecutar esto con modelos más nuevos de clase Fable, sé preciso sobre la disponibilidad. Anthropic lanzó Claude Fable 5 y Mythos 5 el 9 de junio de 2026 a 10 dólares por millón de tokens de entrada y 50 dólares por millón de tokens de salida (Anthropic), pero el 12 de junio Anthropic dijo que había deshabilitado el acceso de clientes a Fable 5 y Mythos 5 mientras cumplía una directiva del gobierno de EE. UU. (comunicado de Anthropic). Así que comprueba el acceso en vivo antes de planificar una ejecución. Cuando esté disponible a través de tu proveedor, se aplica el mismo arnés; la mejora del modelo no elimina la necesidad de un oráculo.
El patrón que merece la pena robar
Es fácil leer mal la historia de Rakuten como “Claude Code ya puede con repositorios enormes”. Eso es demasiado vago para ser útil.
La mejor conclusión es esta: la codificación autónoma de larga duración funciona cuando la tarea está encajonada por un oráculo, un plan, checkpoints de revisión y límites de rollback. El agente puede ser creativo dentro de esas restricciones. Sin ellas, “proactivo” se convierte en “sin límites”, y los agentes de codificación sin límites son la forma de acabar con bugs ocultos y un mensaje final lleno de seguridad.
Para equipos de infraestructura de ML y plataformas, el playbook es simple:
- Elige tareas con finalización medible: coincidencia numérica, recuento de migración, presupuesto de latencia, matriz de compatibilidad.
- Escribe el oráculo de test antes de la funcionalidad.
- Fuerza la separación explorar-planificar-codificar.
- Mantén pequeños los límites de rollback.
- Revisa evidencias, no afirmaciones.
- Usa un segundo contexto para atacar el diff antes de que los humanos lo aprueben.
Así es como conviertes una ejecución autónoma de siete horas de una demostración llamativa en un flujo de trabajo de ingeniería.
Si quieres probar este estilo de flujo de trabajo para tareas largas cuando el acceso esté disponible, consulta Claude Fable 5 en OneHop y empieza con 10 dólares gratis.
Lectura adicional: Primeros pasos con Claude Fable 5.

