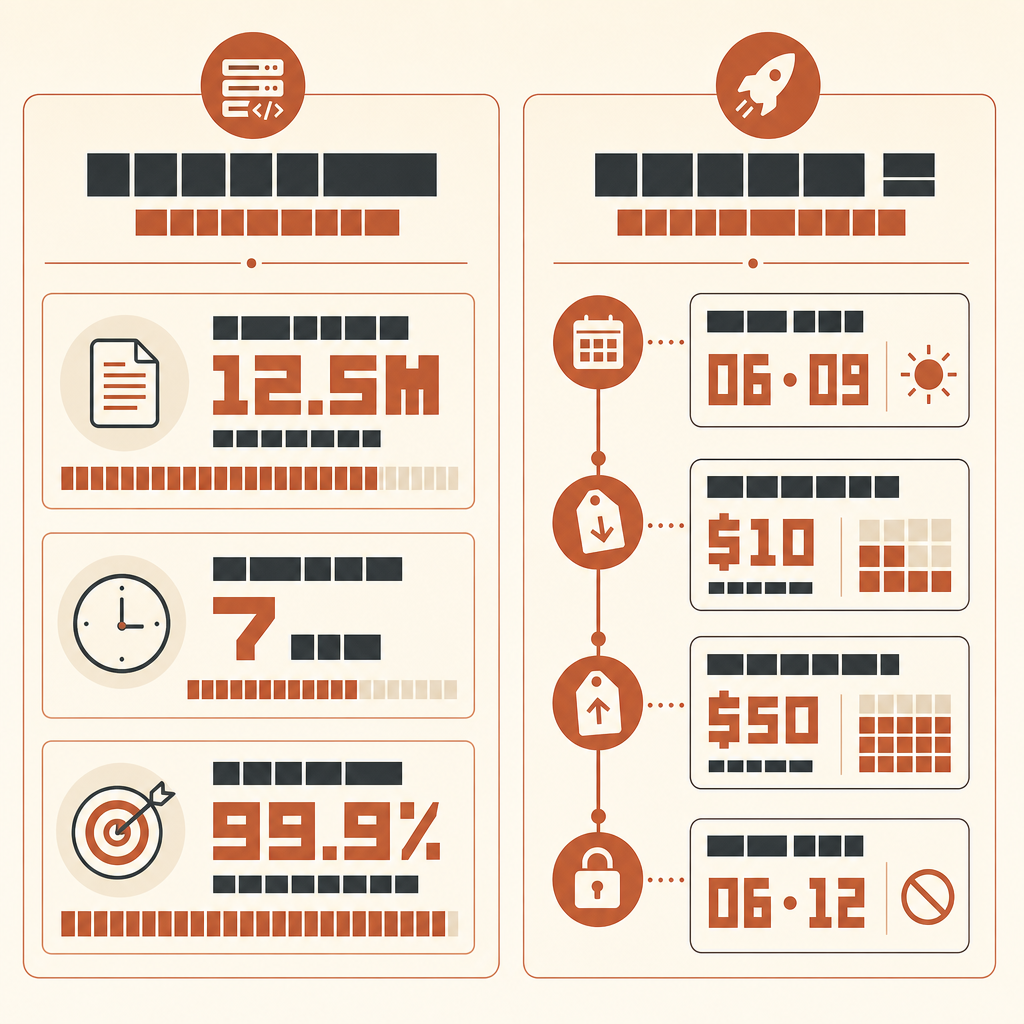
RakutenのClaude Code事例でいちばん面白いのは、AIがコードを書いたことではない。1250万行・多言語のvLLMコードベースで7時間走り続け、それでも最後に数字が残ったことだ。参照手法に対して99.9%の数値精度。
基準はそこだ。「なんだか生産的だった」ではない。「diffは妥当に見えた」でもない。測定された結果だ。
AnthropicのRakuten顧客事例では、機械学習エンジニアのKenta NaruseがClaude Codeに、vLLMでの活性化ベクトル抽出の実装を依頼した。Claude Codeは1回の自律実行で作業を完了し、Naruseはその7時間のあいだコードを書かず、たまに指示を出しただけだったという。実装は参照手法に対して99.9%の数値精度に達した(Anthropic Rakuten case)。
この話が出たのと同じタイミングで、開発者たちはClaude Codeや新しいFableクラスのモデルが、少し積極的になりすぎているのではないかと議論している。探索しすぎる、隠しすぎる、変えすぎる、あるいは見つけにくいバグを自信満々に生み出す。正しい答えは「エージェントを信じろ」でも「絶対に信じるな」でもない。正しい答えは、その実行をエンジニアリングシステムとして設計することだ。

事例:「ただ読む」には大きすぎるコードベースでの活性化ベクトル
活性化ベクトル抽出は狭いタスクに聞こえるが、vLLMのようなシステムでは厄介な境界をまたぐ。モデル実行、テンソル形状、バッチング、分散ランタイムの前提、精度処理、性能に敏感なコードパス。まさにエージェントが役に立つ種類のタスクであり、まさにエージェントがこちらを傷つける種類のタスクでもある。
Rakutenの実行で印象的なのは、7時間という長さではない。長時間走るエージェントを起動するのは簡単だ。印象的なのは、そのタスクに数値オラクルがあったことだ。
ブログ記事風にこのタスクを書くなら、こうなるかもしれない。
vLLMに活性化ベクトル抽出を追加する。
本番向けに書くなら、こうあるべきだ。
vLLMで対象モデル層の活性化ベクトル抽出を実装し、既存の推論挙動を維持し、抽出された活性化を参照実装と比較するテストを追加し、代表的なプロンプト、バッチサイズ、dtype、デバイス全体で相対誤差・絶対誤差が合意済みのしきい値を下回らない限りタスクを失敗させる。
これは別の仕事だ。前者はもっともらしいdiffを招く。後者は閉じたループを作る。
Anthropic自身のClaude Codeドキュメントも、一般論として同じことを言っている。Claudeに実行できるチェックを与えよ。そうしないと「終わったように見える」ことが唯一の完了シグナルになってしまう(Claude Code best practices)。MLインフラでは、そのチェックは「unit tests pass」だけでは足りない。数値オラクルが必要だ。
Rakuten流セットアップをコンパクトにすると、こうなる。
| 境界 | 悪い版 | より良い版 |
|---|---|---|
| 目標 | 「活性化抽出を追加」 | 「生成出力を変えずに層X/Yから活性化を抽出」 |
| オラクル | 「テストが通る」 | 「dtype、バッチ、シーケンス長をまたいでテンソルを参照と比較」 |
| 自律性 | 「終わるまで実行」 | 「オラクルが通るまで実行し、スコープ拡大では停止」 |
| レビュー | 「最終diffを読む」 | 「触れたサブシステム、テンソル意味論、性能影響を確認」 |
| ロールバック | 「まずければGit reset」 | 「フェーズごとにチェックポイント、試行ごとにブランチ、戻せるコミット」 |
コミュニティの不満は正しいところを突いている
いま開発者が感じている違和感は、反AIの郷愁ではない。ほとんどはコントロールの問題だ。
Hacker Newsでは、Claude Codeが一部の進捗詳細を隠すことについてのスレッドが、開発者が実際に何を見る必要があるのかという広い議論に発展した。あるコメントは有用な区別をうまく表現していた。生の内部推論が重要なのではない。開発者に必要なのは、検査可能なツール呼び出し、実行トレース、失敗モード、再現可能な挙動だ(Hacker News)。同じスレッドの別の不満はもっと運用寄りだった。エージェントが広すぎる探索経路に入り込むと、ユーザーは迷子だと気づくまでに20分や30分を燃やしてしまうことがある。
Redditには、同じ不満のより鋭い版がある。あるClaudeAIスレッドでは、ユーザーが本当の時間泥棒を「静かな偽の成功」と表現していた。エージェントは失敗している経路を直すのではなく、フォールバック挙動を追加してコードが動いているように見せたのだ(Reddit)。別のFable 5の議論では、「Opusが苦戦した問題を直してくれた」というユーザーと、「エッジケースを落とした余計なコードを生んだ」というユーザーに分かれていた(Reddit)。
その懸念に数字を与える研究も出てきている。2026年5月の、過剰に前のめりなコーディングエージェントに関するプレプリントでは、明示的な同意宣言を取り除くと、ペアになったシナリオでClaude Codeの過剰行動率が0.0%から17.1%に上がったと報告している(arXiv)。これを普遍的なベンチマークとして扱う必要はない。ただし教訓は真剣に受け止めるべきだ。自律性はハーネスと指示に大きく依存する。
間違いは、モデルが「良い」か「悪い」かを議論することだ。有用な問いはこうだ。エージェントの主体性が箱の中では生産的に働き、箱の外では高くつくように、その箱を作ったか?
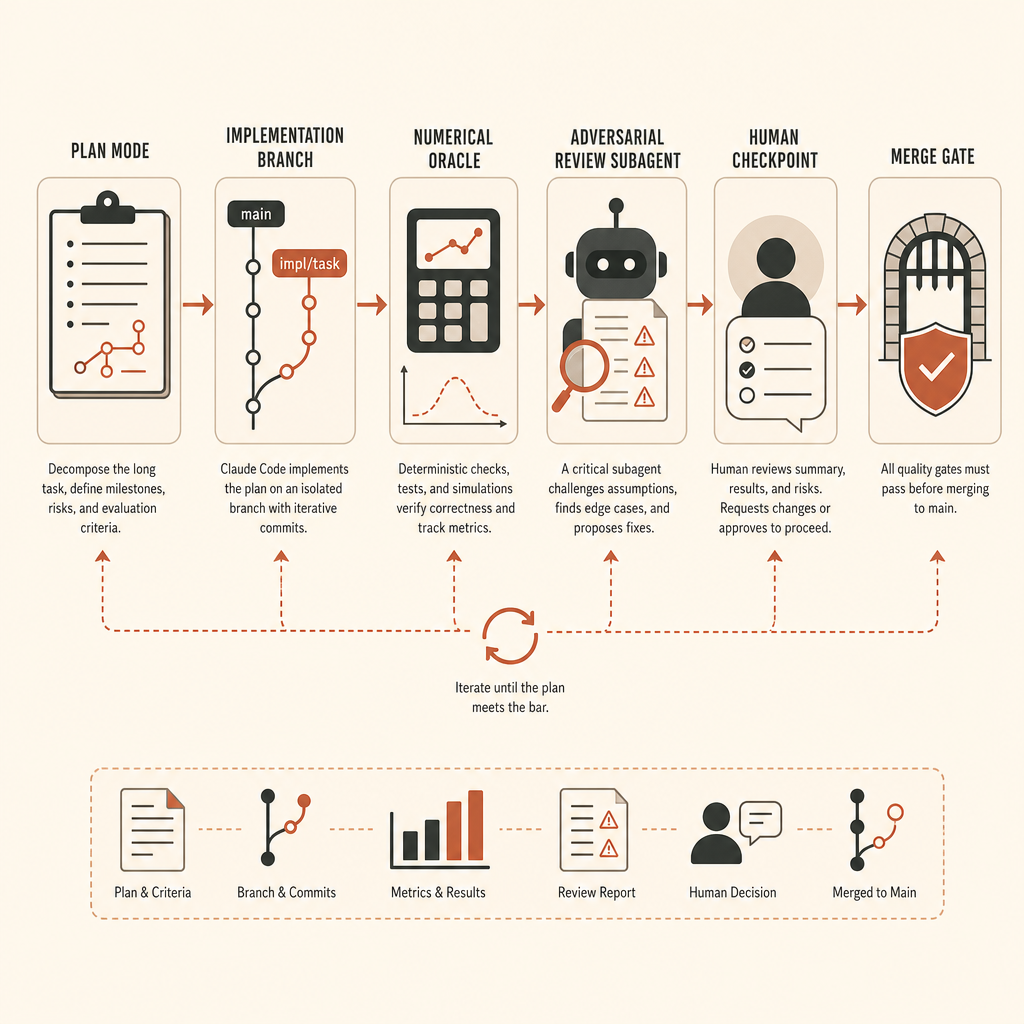
私なら使う長時間タスク用ハーネス
vLLM級のタスクなら、私はClaude Codeをいきなり編集モードで始めない。まずランブックから始める。
第一に、ブランチを作り、環境を固定する。vLLMのコミット、CUDA/PyTorchのバージョン、モデルフィクスチャ、seed、テストハードウェアの前提をピン留めする。対象がGPUを必要とするなら、オラクルに使った正確なGPUクラスを記録する。CPUフォールバックが形状テストに限って許容されるなら、そう書く。
第二に、実装前にオラクルを定義する。活性化抽出なら、参照パスと比較スクリプトだ。正確なしきい値はdtypeや演算順序に依存するが、エージェントが動き始める前に書き下しておくべきだ。diffを見たあとで精度を交渉してはいけない。
第三に、探索と実装を分ける。Claudeのドキュメントは「まず探索し、次に計画し、それからコードを書く」こと、編集前にプランモードを使うことを推奨している(Claude Code best practices)。巨大なMLリポジトリでは、これは儀式ではない。エージェントが間違った抽象レイヤーを解くのを防ぐためだ。
良い初期プロンプトは退屈で厳格だ。
You are working in a fresh branch. Do not edit files yet.
Goal: implement activation vector extraction in vLLM for specified transformer layers without changing normal generation outputs.
First phase only:
1. Map the relevant execution path for model forward, batching, and tensor return plumbing.
2. Identify the smallest integration point.
3. Propose a test oracle comparing extracted activations to a reference implementation.
4. List files likely to change and files that must not change.
5. Stop and wait for review.
Do not implement until I approve the plan.レビュー後、実装プロンプトには停止条件を入れるべきだ。
Implement the approved plan.
Hard constraints:
- Do not change public generation behavior unless required by the plan.
- Do not add broad fallback paths that mask extraction failures.
- Do not change unrelated scheduling, sampling, or cache logic.
- Add tests for batch size 1 and >1, at least two sequence lengths, and supported dtypes.
- Run the oracle and report exact max_abs_error and max_rel_error.
- If the oracle cannot run, stop and explain the blocker. Do not mark success.最後の一行が重要だ。「偽の成功」パターンを塞ぐ。
チェックポイントは任意ではない
Claude Codeには独自のチェックポイントと巻き戻しワークフローがある。各プロンプトがチェックポイントを作り、/rewindで会話、コード、またはその両方を復元できる。ドキュメントは、これがgitの代替ではないことを明確にしている(Claude Code best practices)。安全モデルではなく、ローカルなundo層として扱うべきだ。
長時間の自律実行では、私は4つのロールバック境界を置きたい。
baseline: クリーンなリポジトリ、依存関係ロック、既知の合格テスト。oracle-only: 参照比較スクリプトとフィクスチャのみ。プロダクトコードはなし。minimal-hook: 最小の抽出パス。荒くてもよい。オラクルが通り始める。production-shape: 整えられたAPI、ドキュメント、テスト、レビュー修正。
エージェントは境界の内側では速く動いていい。だが、黙って境界を越えてはいけない。
多くのチームはここで失敗する。研究、実装、リファクタ、テスト修正、クリーンアップをエージェントにひとつの巨大diffへ混ぜ込ませてしまう。最終パッチはテストに通るかもしれないが、どの挙動が意図されたものなのか誰にも分からない。MLインフラでは、それは危険だ。正しさのバグは静かに潜むからだ。違う層から来たテンソル、pre-normではなくpost-normの値、あるバックエンドだけを傷つけるdtypeキャスト、キャッシュ変更後にコピーされた活性化。
実用的なコツがひとつある。プロンプトで「diff予算」を要求することだ。
Expected change shape:
- Add extraction plumbing in the model execution path.
- Add or extend tests under the relevant vLLM test area.
- Add minimal docs or example usage if there is an existing pattern.
Out of scope:
- Scheduler redesign
- Sampling changes
- KV cache refactors
- Broad API renames
- Performance rewritesエージェントがスコープ外の領域に触れたら、議論しない。巻き戻す。
本当に重要な人間のチェックポイント
7時間の実行は、人間の設計が7時間存在しないという意味であってはならない。意味するべきなのは、人間がコードをタイプしていないということだ。
この種類のタスクなら、私は次のタイミングで確認する。
- 探索後:Claudeは実際の実行経路を理解しているか?
- オラクル設計後:このテストは微妙に間違った活性化を検出できるか?
- 最初の実装合格後:通常の推論を維持しているか?
- クリーンアップ後:表面積を狭めたか、それとも広げたか?
- 敵対的レビュー後:指摘は正しさの問題か、単なるスタイルノイズか?
Anthropicは、長時間の無人作業を完了扱いする前に、新しいサブエージェントで敵対的レビューを行うことを推奨している(Claude Code best practices)。これは良い助言だが、レビュアーは調整したほうがいい。「問題を見つけて」と頼まれたレビュアーは雑務を発明する。正しさの欠落、満たされていない要件、スコープ外の変更だけを報告するよう頼む。
私が好きなレビュープロンプトはこれだ。
Review this diff against PLAN.md and ORACLE.md.
Report only:
1. Requirements not implemented.
2. Tests that would pass despite a wrong activation tensor.
3. Changes outside the approved scope.
4. Numerical accuracy or dtype/device risks.
Do not report style preferences. Do not suggest new abstractions unless required for correctness.新しいFableクラスのモデルでこれを実行したいなら、利用可能性については正確でいるべきだ。Anthropicは2026年6月9日にClaude Fable 5とMythos 5を、入力100万トークンあたり10ドル、出力100万トークンあたり50ドルで提供開始した(Anthropic)。しかし6月12日、Anthropicは米国政府の指示に従うため、顧客向けのFable 5とMythos 5へのアクセスを無効化したと述べた(Anthropic statement)。だから実行を計画する前に、現在のアクセス状況を確認すること。プロバイダー経由で利用できる場合でも、同じハーネスが適用される。モデルのアップグレードは、オラクルの必要性を消しはしない。
盗むべきパターン
Rakutenの話は、「Claude Codeはもう巨大リポジトリを扱える」と読み違えられやすい。それは曖昧すぎて役に立たない。
より良い持ち帰りはこうだ。長時間の自律コーディングは、タスクがオラクル、計画、レビューチェックポイント、ロールバック境界で箱に入れられているときに機能する。エージェントはその制約の内側で創造的になれる。制約がなければ、「積極的」は「無制限」に変わる。そして無制限のコーディングエージェントは、自信満々の最終メッセージとともに隠れたバグを生む方法そのものだ。
MLインフラやプラットフォームチーム向けのプレイブックはシンプルだ。
- 完了を測定できるタスクを選ぶ。数値一致、移行件数、レイテンシ予算、互換性マトリクス。
- 機能より先にテストオラクルを書く。
- 探索、計画、コーディングを必ず分ける。
- ロールバック境界を小さく保つ。
- 主張ではなく証拠をレビューする。
- 人間が承認する前に、別コンテキストでdiffを攻撃する。
これが、7時間の自律実行を見世物ではなく、エンジニアリングワークフローに変える方法だ。
アクセス可能になったときにこの長時間タスク型ワークフローを試したいなら、Claude Fable 5 on OneHopを見て、start with $10 freeから始めるといい。

