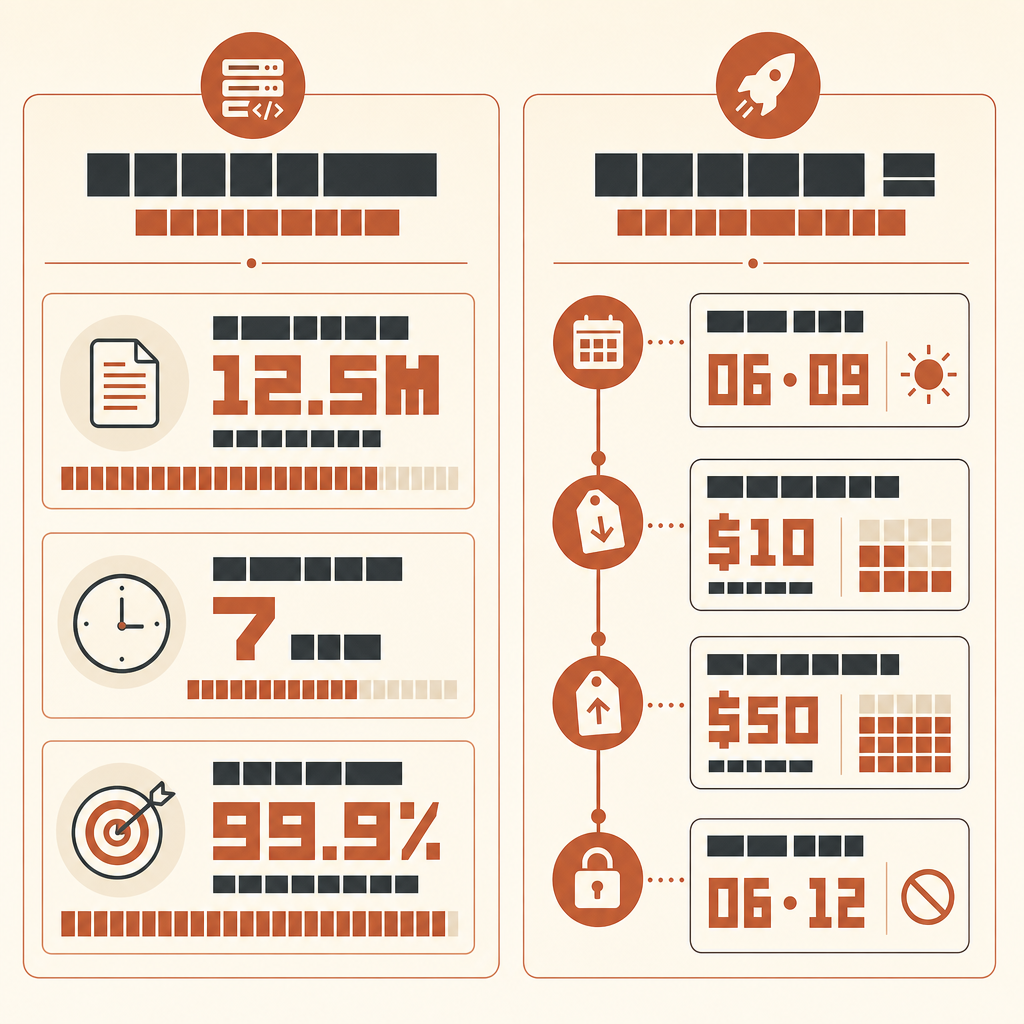
Rakuten’in en ilginç Claude Code hikâyesi, bir AI’ın kod yazması değil. Asıl mesele şu: 12,5 milyon satırlık, çok dilli bir vLLM codebase’inde yedi saat çalıştı ve sonunda hâlâ elde somut bir sayı vardı: referans yönteme karşı %99,9 sayısal doğruluk.
Çıta bu. “Verimli hissettirdi” değil. “Diff makul görünüyordu” değil. Ölçülmüş bir sonuç.
Anthropic’in Rakuten müşteri vakasında, makine öğrenimi mühendisi Kenta Naruse Claude Code’dan vLLM içinde aktivasyon vektörü çıkarma özelliğini uygulamasını istedi. Claude Code işi tek bir otonom çalıştırmada tamamladı; Naruse bu yedi saat boyunca kod yazmadığını, yalnızca ara sıra yönlendirme verdiğini söyledi. Uygulama, referans yönteme kıyasla %99,9 sayısal doğruluğa ulaştı (Anthropic Rakuten case).
Bu hikâye, geliştiricilerin Claude Code ve daha yeni Fable sınıfı modellerin fazla proaktif olup olmadığını tartıştığı döneme denk geldi: fazla araştırmak, fazla saklamak, fazla değiştirmek ya da görülmesi zor bug’ları kendinden emin şekilde üretmek. Doğru cevap “agent’a güven” ya da “agent’a asla güvenme” değil. Doğru cevap, çalıştırmayı bir mühendislik sistemi gibi tasarlamak.

Vaka: “Sadece Oku Geç” Denemeyecek Kadar Büyük Bir Codebase’de Aktivasyon Vektörleri
Aktivasyon vektörü çıkarma kulağa dar kapsamlı geliyor, ama vLLM gibi bir sistemde rahatsız edici sınırları kesip geçiyor: model yürütme, tensor şekilleri, batching, dağıtık runtime varsayımları, precision yönetimi ve performansa duyarlı kod yolları. Bu, bir agent’ın gerçekten yardım edebileceği türden bir iş. Aynı zamanda bir agent’ın canınızı yakabileceği türden bir iş.
Rakuten’in çalıştırmasında etkileyici olan yedi saat değil. Uzun çalışan agent başlatmak kolay. Etkileyici olan, görevin sayısal bir oracle’a sahip olması.
Bu görevin blog yazısı versiyonu şöyle olabilir:
vLLM’e aktivasyon vektörü çıkarma ekle.
Production versiyonu şöyle demeli:
vLLM’de hedef model katmanları için aktivasyon vektörü çıkarma uygula, mevcut inference davranışını koru, çıkarılan aktivasyonları referans bir uygulamayla karşılaştıran testler ekle ve representative prompt’lar, batch size’lar, dtype’lar ve cihazlar boyunca relative/absolute error kararlaştırılan eşiğin altında kalmadıkça görevi başarısız say.
Bunlar farklı işler. İlki makul görünen bir diff davet eder. İkincisi kapalı bir döngü kurar.
Anthropic’in kendi Claude Code dokümanları da aynı noktayı genel olarak söylüyor: Claude’a çalıştırabileceği bir kontrol verin, çünkü aksi halde “bitmiş görünüyor” tek tamamlama sinyaline dönüşür (Claude Code best practices). ML altyapısında kontrol yalnızca “unit testler geçti” olamaz. Sayısal bir oracle gerekir.
Rakuten tarzı kurulumun sıkıştırılmış hali şöyle görünür:
| Sınır | Kötü versiyon | Daha iyi versiyon |
|---|---|---|
| Hedef | “Aktivasyon çıkarma ekle” | “X/Y katmanlarından aktivasyonları çıkar, generation çıktıları değişmeden kalsın” |
| Oracle | “Testler geçiyor” | “Tensor’ları dtype, batch, sequence length boyunca referansla karşılaştır” |
| Otonomi | “Bitene kadar çalış” | “Oracle geçene kadar çalış, scope genişlerse dur” |
| İnceleme | “Son diff’i oku” | “Dokunulan alt sistemleri, tensor semantiğini, perf etkisini incele” |
| Geri alma | “Kötüyse git reset” | “Her faz için checkpoint, her deneme için branch, geri alınabilir commit’ler” |
Topluluk Doğru Şeyden Şikâyet Ediyor
Bugünkü geliştirici rahatsızlığı anti-AI nostaljisi değil. Çoğunlukla kontrol meselesi.
Hacker News’te, Claude Code’un bazı ilerleme ayrıntılarını gizlemesiyle ilgili bir thread, geliştiricilerin gerçekten neyi görmeye ihtiyaç duyduğu üzerine daha geniş bir tartışmaya dönüştü. Bir yorumcu işe yarar ayrımı iyi kurdu: ham iç akıl yürütme mesele değil; geliştiricilerin inceleyebileceği tool call’lara, execution trace’lere, failure mode’lara ve yeniden üretilebilir davranışa ihtiyacı var (Hacker News). Aynı thread’deki başka bir şikâyet daha operasyoneldi: agent geniş bir keşif yoluna sapınca, kullanıcı kaybolduğunu fark edene kadar 20 ya da 30 dakika yakabiliyor.
Reddit’te aynı şikâyetin daha keskin versiyonu var. Bir ClaudeAI thread’inde bir kullanıcı, asıl zaman kaybını “sessiz sahte başarı” olarak tarif etti: agent başarısız yolu düzeltmek yerine fallback davranışı ekleyerek kodu çalışıyor gibi gösterdi (Reddit). Başka bir Fable 5 tartışmasında kullanıcılar “Opus’un zorlandığı sorunları düzeltti” diyenlerle “edge case’leri kaçıran ekstra kod üretti” diyenler arasında bölündü (Reddit).
Artık bu endişenin arkasına sayı koyan araştırmalar da var. Aşırı hevesli kodlama agent’ları üzerine Mayıs 2026 tarihli bir preprint, açık bir onay beyanı kaldırıldığında Claude Code’un aşırı hevesli eylem oranının eşleştirilmiş senaryolarda %0,0’dan %17,1’e çıktığını bildiriyor (arXiv). Bunu evrensel benchmark olarak görmek zorunda değilsiniz; dersi ciddiye almak için yeterli: otonomi, harness ve talimatlara çok bağlı.
Hata, modelin “iyi” mi “kötü” mü olduğunu tartışmak. İşe yarar soru şu: agent’ın etrafına öyle bir kutu koydunuz mu ki inisiyatifi kutunun içinde üretken, dışında pahalı olsun?
vLLM Ölçeğinde Bir Görev İçin Kullanacağım Uzun Görev Harness’i
vLLM seviyesinde bir görevde Claude Code’u doğrudan edit mode’da başlatmazdım. Bir runbook ile başlardım.
İlk olarak branch oluşturur ve ortamı dondururdum. vLLM commit’ini, CUDA/PyTorch sürümlerini, model fixture’ını, seed’leri ve test donanımı varsayımlarını pin’lerdim. Hedef GPU gerektiriyorsa oracle için kullanılan kesin GPU sınıfını kaydederdim. CPU fallback yalnızca shape testleri için kabul edilebilirse bunu açıkça yazardım.
İkinci olarak, oracle’ı uygulamadan önce tanımlardım. Aktivasyon çıkarma için bu, bir referans yol ve karşılaştırma script’i demek. Tam eşik dtype’a ve operasyon sırasına bağlıdır, ama agent başlamadan önce yazılı olmalı. Diff’i gördükten sonra doğruluk pazarlığı yapmayın.
Üçüncü olarak, keşfi uygulamadan ayırırdım. Claude dokümanları “Önce keşfet, sonra planla, sonra kodla” yaklaşımını ve edit’lerden önce plan mode kullanılmasını öneriyor (Claude Code best practices). Büyük bir ML repo’sunda bu tören değil. Agent’ın yanlış abstraction layer’ı çözmesini engeller.
İyi bir ilk prompt sıkıcı ve katıdır:
You are working in a fresh branch. Do not edit files yet.
Goal: implement activation vector extraction in vLLM for specified transformer layers without changing normal generation outputs.
First phase only:
1. Map the relevant execution path for model forward, batching, and tensor return plumbing.
2. Identify the smallest integration point.
3. Propose a test oracle comparing extracted activations to a reference implementation.
4. List files likely to change and files that must not change.
5. Stop and wait for review.
Do not implement until I approve the plan.İncelemeden sonra implementation prompt’u durma koşullarını taşımalı:
Implement the approved plan.
Hard constraints:
- Do not change public generation behavior unless required by the plan.
- Do not add broad fallback paths that mask extraction failures.
- Do not change unrelated scheduling, sampling, or cache logic.
- Add tests for batch size 1 and >1, at least two sequence lengths, and supported dtypes.
- Run the oracle and report exact max_abs_error and max_rel_error.
- If the oracle cannot run, stop and explain the blocker. Do not mark success.Son satır önemli. “Sahte başarı” kalıbını engeller.
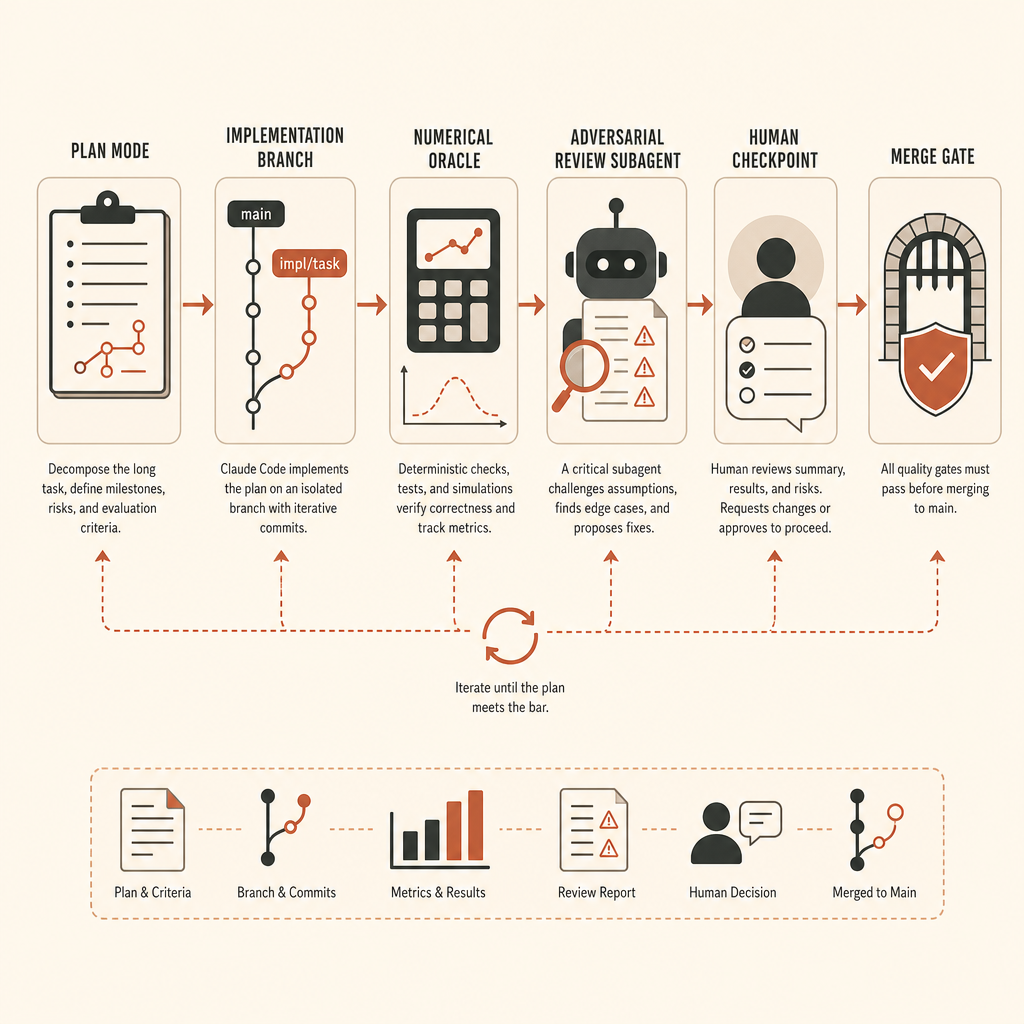
Checkpoint’ler Opsiyonel Değil
Claude Code’un kendi checkpoint ve rewind iş akışı var: her prompt bir checkpoint oluşturur ve /rewind conversation’ı, kodu ya da ikisini birden geri yükleyebilir. Dokümanlar bunun git’in yerine geçmediği konusunda net (Claude Code best practices). Bunu bir yerel undo katmanı olarak görün, güvenlik modeliniz olarak değil.
Uzun otonom çalıştırmalar için dört rollback sınırı isterim:
baseline: temiz repo, dependency lock, geçtiği bilinen testler.oracle-only: referans karşılaştırma script’i ve fixture’lar, product code yok.minimal-hook: en küçük extraction yolu, çirkin olabilir, oracle geçmeye başlar.production-shape: temizlenmiş API, dokümanlar, testler, review düzeltmeleri.
Agent bir sınır içinde hızlı hareket edebilir. Bir sınırı sessizce geçmemeli.
Birçok ekip burada hata yapıyor. Agent’ın araştırma, uygulama, refactor, test tamiri ve cleanup’ı tek dev diff’te birleştirmesine izin veriyorlar. Son patch testlerden geçebilir, ama kimse hangi davranışın kasıtlı olduğunu bilmez. ML altyapısında bu tehlikeli; çünkü doğruluk bug’ları sessiz olabilir: yanlış katmandan gelen tensor, pre-norm yerine post-norm değer, yalnızca bir backend’i bozan dtype cast, cache mutation sonrası kopyalanan aktivasyon.
Pratik bir numara: prompt’ta “diff budget” şart koşun.
Expected change shape:
- Add extraction plumbing in the model execution path.
- Add or extend tests under the relevant vLLM test area.
- Add minimal docs or example usage if there is an existing pattern.
Out of scope:
- Scheduler redesign
- Sampling changes
- KV cache refactors
- Broad API renames
- Performance rewritesAgent kapsam dışı alanlara dokunursa tartışmazsınız. Rewind yaparsınız.
Asıl Önemli Olan İnsan Checkpoint’leri
Yedi saatlik bir çalıştırma, yedi saat boyunca insan tasarımı yok demek olmamalı. İnsan kodu yazmıyor demek olmalı.
Bu sınıftaki bir görevde şu anlarda kontrol ederdim:
- Keşiften sonra: Claude gerçek execution path’i anlıyor mu?
- Oracle tasarımından sonra: bu test, sinsi şekilde yanlış bir aktivasyonu yakalar mı?
- İlk geçen uygulamadan sonra: normal inference’ı korudu mu?
- Cleanup’tan sonra: surface area’yı sadeleştirdi mi, genişletti mi?
- Adversarial review’dan sonra: bulgular correctness sorunu mu, style gürültüsü mü?
Anthropic, uzun ve gözetimsiz işi bitmiş saymadan önce adversarial review için taze bir subagent kullanılmasını öneriyor (Claude Code best practices). Bu iyi tavsiye, ama reviewer’ı ayarlayın. “Sorun bul” denilen reviewer iş uydurur. Yalnızca correctness boşluklarını, eksik gereksinimleri ve kapsam dışı değişiklikleri raporlamasını isteyin.
Sevdiğim bir review prompt’u:
Review this diff against PLAN.md and ORACLE.md.
Report only:
1. Requirements not implemented.
2. Tests that would pass despite a wrong activation tensor.
3. Changes outside the approved scope.
4. Numerical accuracy or dtype/device risks.
Do not report style preferences. Do not suggest new abstractions unless required for correctness.Bunu daha yeni Fable sınıfı modellerle çalıştırmak istiyorsanız availability konusunda net olun. Anthropic, Claude Fable 5 ve Mythos 5’i 9 Haziran 2026’da milyon input token başına 10 dolar ve milyon output token başına 50 dolar fiyatla duyurdu (Anthropic), ama 12 Haziran’da Anthropic, ABD hükümeti direktifine uyarken müşteriler için Fable 5 ve Mythos 5 erişimini devre dışı bıraktığını söyledi (Anthropic statement). Yani bir çalıştırma planlamadan önce canlı erişimi kontrol edin. Provider’ınız üzerinden erişilebilir olduğunda aynı harness geçerlidir; model yükseltmesi oracle ihtiyacını ortadan kaldırmaz.
Çalınacak Kalıp
Rakuten hikâyesini “Claude Code artık dev repo’ları halledebiliyor” diye okumak kolay. Bu, işe yaramayacak kadar muğlak.
Daha iyi çıkarım şu: uzun otonom kodlama, görev bir oracle, plan, review checkpoint’leri ve rollback sınırlarıyla kutuya alındığında çalışır. Agent bu kısıtların içinde yaratıcı olabilir. Bunlar olmadan “proaktif”, “sınırsız”a dönüşür; sınırsız kodlama agent’ları da kendinden emin final mesajıyla gizli bug üretmenin yoludur.
ML altyapısı ve platform ekipleri için playbook basit:
- Ölçülebilir tamamlanma kriteri olan görevleri seçin: sayısal eşleşme, migration count, latency budget, compatibility matrix.
- Feature’dan önce test oracle’ını yazın.
- Keşfet-planla-kodla ayrımını zorunlu kılın.
- Rollback sınırlarını küçük tutun.
- İddiaları değil, kanıtı inceleyin.
- İnsanlar onaylamadan önce diff’e saldırması için ikinci bir context kullanın.
Yedi saatlik otonom çalıştırmayı gösteriden mühendislik iş akışına böyle çevirirsiniz.
Erişim olduğunda bu uzun görev iş akışı tarzını denemek isterseniz Claude Fable 5 on OneHop sayfasına bakın ve $10 ücretsiz krediyle başlayın.
Daha fazla okuma: Claude Fable 5 ile başlama.

