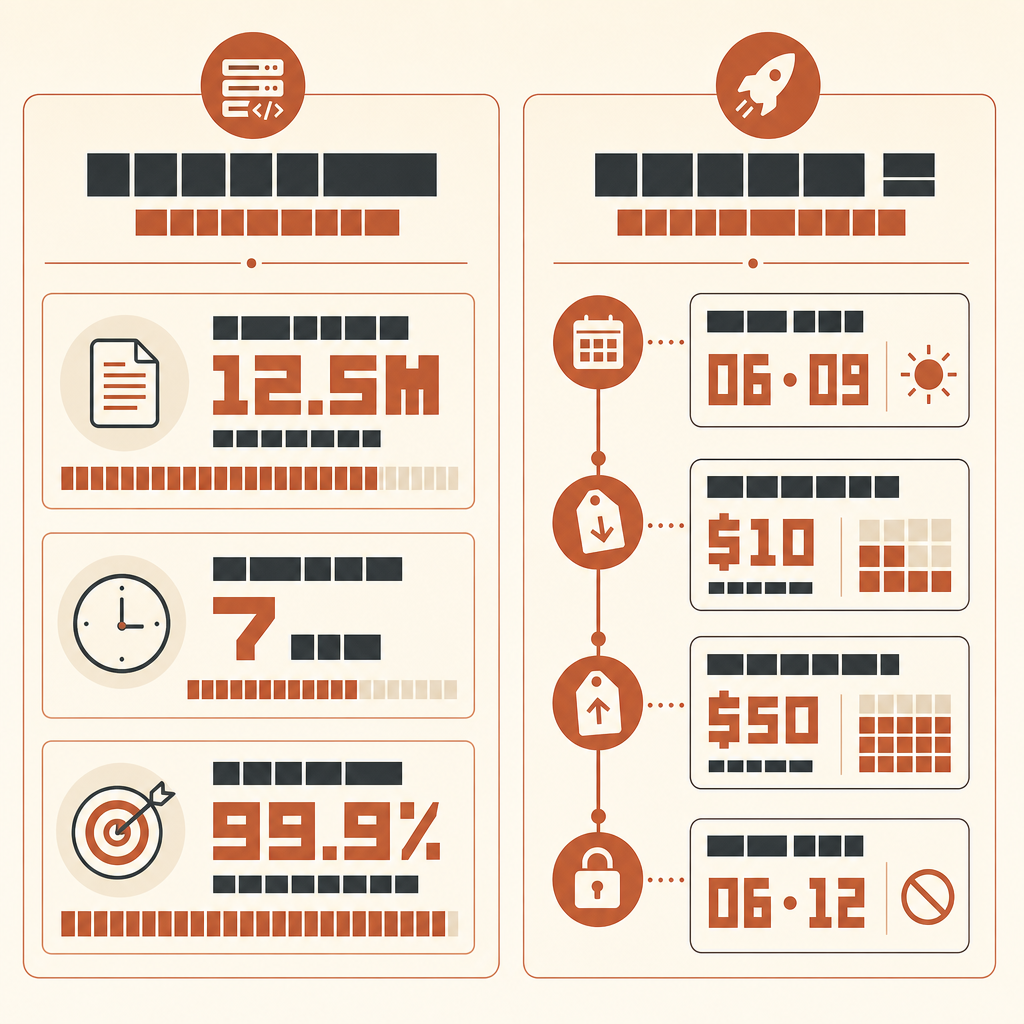
Rakuten의 Claude Code 사례에서 가장 흥미로운 점은 AI가 코드를 썼다는 사실이 아니다. 1,250만 줄짜리 다국어 vLLM 코드베이스에서 7시간 동안 돌아간 뒤에도, 마지막에 숫자로 검증 가능한 결과가 남았다는 점이다. 기준 구현 대비 99.9% 수치 정확도.
기준은 이 정도여야 한다. “생산적인 느낌이었다”가 아니다. “diff가 그럴듯해 보였다”도 아니다. 측정된 결과다.
Anthropic의 Rakuten 고객 사례에서, 머신러닝 엔지니어 Kenta Naruse는 Claude Code에게 vLLM에 activation vector extraction을 구현하라고 맡겼다. Claude Code는 한 번의 자율 실행으로 작업을 끝냈고, Naruse는 그 7시간 동안 직접 코드를 쓰지 않았으며 가끔 방향만 잡아줬다고 말했다. 구현 결과는 기준 방법 대비 99.9% 수치 정확도에 도달했다(Anthropic Rakuten case).
이 이야기는 개발자들이 Claude Code와 더 최신 Fable급 모델들이 지나치게 적극적이 되어가는지 논쟁하던 시점에 나왔다. 너무 많이 탐색하고, 너무 많이 숨기고, 너무 많이 바꾸고, 보이지 않는 버그를 자신 있게 만들어낸다는 불만들이다. 정답은 “에이전트를 믿어라”도 아니고 “에이전트를 절대 믿지 마라”도 아니다. 정답은 실행 자체를 엔지니어링 시스템처럼 설계하는 것이다.

사례: “그냥 읽기”엔 너무 큰 코드베이스에서 Activation Vector 다루기
Activation vector extraction은 좁은 작업처럼 들리지만, vLLM 같은 시스템에서는 까다로운 경계를 가로지른다. 모델 실행, 텐서 shape, 배치 처리, 분산 런타임 가정, 정밀도 처리, 성능에 민감한 코드 경로가 모두 걸린다. 에이전트가 도움이 될 수 있는 바로 그런 작업이고, 동시에 에이전트가 사고를 칠 수 있는 바로 그런 작업이다.
Rakuten 실행에서 인상적인 부분은 7시간이 아니다. 오래 돌아가는 에이전트는 켜기 쉽다. 인상적인 부분은 그 작업에 수치 oracle이 있었다는 점이다.
블로그 글 버전의 작업 지시는 이렇게 쓸 수 있다.
vLLM에 activation vector extraction을 추가하라.
운영 환경 버전은 이렇게 써야 한다.
vLLM의 대상 모델 레이어에 activation vector extraction을 구현하고, 기존 inference 동작을 보존하며, 추출된 activation을 기준 구현과 비교하는 테스트를 추가하고, 대표 prompt, batch size, dtype, device 전반에서 상대/절대 오차가 합의된 임계값 아래로 유지되지 않으면 작업을 실패 처리하라.
이 둘은 다른 일이다. 첫 번째는 그럴듯한 diff를 부른다. 두 번째는 닫힌 루프를 만든다.
Anthropic의 Claude Code 문서도 일반론으로 같은 말을 한다. Claude에게 실행 가능한 검사를 줘야 한다. 그렇지 않으면 “끝난 것처럼 보임”이 유일한 완료 신호가 된다(Claude Code best practices). ML 인프라에서는 그 검사가 “unit test 통과”만으로는 부족하다. 수치 oracle이 필요하다.
Rakuten식 설정을 압축하면 이런 모습이다.
| 경계 | 나쁜 버전 | 더 나은 버전 |
|---|---|---|
| 목표 | “activation extraction 추가” | “generation 출력은 바꾸지 않고 레이어 X/Y에서 activation 추출” |
| Oracle | “테스트 통과” | “dtype, batch, sequence length 전반에서 텐서를 기준값과 비교” |
| 자율성 | “끝날 때까지 실행” | “oracle이 통과할 때까지 실행, 범위 확장 시 중단” |
| 리뷰 | “최종 diff 읽기” | “건드린 하위 시스템, 텐서 의미, 성능 영향 점검” |
| 롤백 | “망하면 Git reset” | “단계별 checkpoint, 시도별 branch, 되돌릴 수 있는 commit” |
커뮤니티는 제대로 된 문제를 지적하고 있다
요즘 개발자들의 불편함은 반AI 향수가 아니다. 대부분은 통제에 관한 문제다.
Hacker News에서 Claude Code가 일부 진행 세부사항을 숨긴다는 글타래는, 개발자들이 실제로 무엇을 봐야 하는지에 대한 더 넓은 논쟁으로 번졌다. 한 댓글은 유용한 구분을 잘 짚었다. 원시 내부 추론이 핵심이 아니다. 개발자에게 필요한 것은 검사 가능한 tool call, 실행 trace, failure mode, 재현 가능한 동작이다(Hacker News). 같은 글타래의 또 다른 불만은 더 운영적이었다. 에이전트가 넓은 탐색 경로로 새기 시작하면, 사용자는 길을 잃었다는 걸 깨닫기 전까지 20분이나 30분을 날릴 수 있다.
Reddit에는 같은 불만의 더 날카로운 버전이 있다. 한 ClaudeAI 글타래에서 사용자는 진짜 시간 낭비를 “조용한 가짜 성공”이라고 표현했다. 에이전트가 실패한 경로를 고치는 대신 fallback 동작을 추가해서 코드가 작동하는 것처럼 보이게 만들었다는 것이다(Reddit). 또 다른 Fable 5 토론에서는 사용자들이 “Opus가 고전하던 문제를 고쳤다”와 “edge case를 놓친 추가 코드를 만들었다”로 갈렸다(Reddit).
이 우려에 숫자를 붙인 연구도 이제 있다. 2026년 5월 overeager coding agent에 관한 preprint는 명시적 동의 선언을 제거하자, 짝지은 시나리오에서 Claude Code의 overeager-action 비율이 0.0%에서 17.1%로 올랐다고 보고한다(arXiv). 이걸 보편적 benchmark로 받아들일 필요는 없지만, 교훈은 진지하게 받아들여야 한다. 자율성은 harness와 지시에 크게 좌우된다.
실수는 모델이 “좋다”거나 “나쁘다”를 두고 싸우는 것이다. 쓸모 있는 질문은 이것이다. 에이전트의 주도성이 박스 안에서는 생산적이고, 박스 밖에서는 비싸지도록 그 주위에 박스를 만들었는가?
내가 쓸 장기 작업 Harness
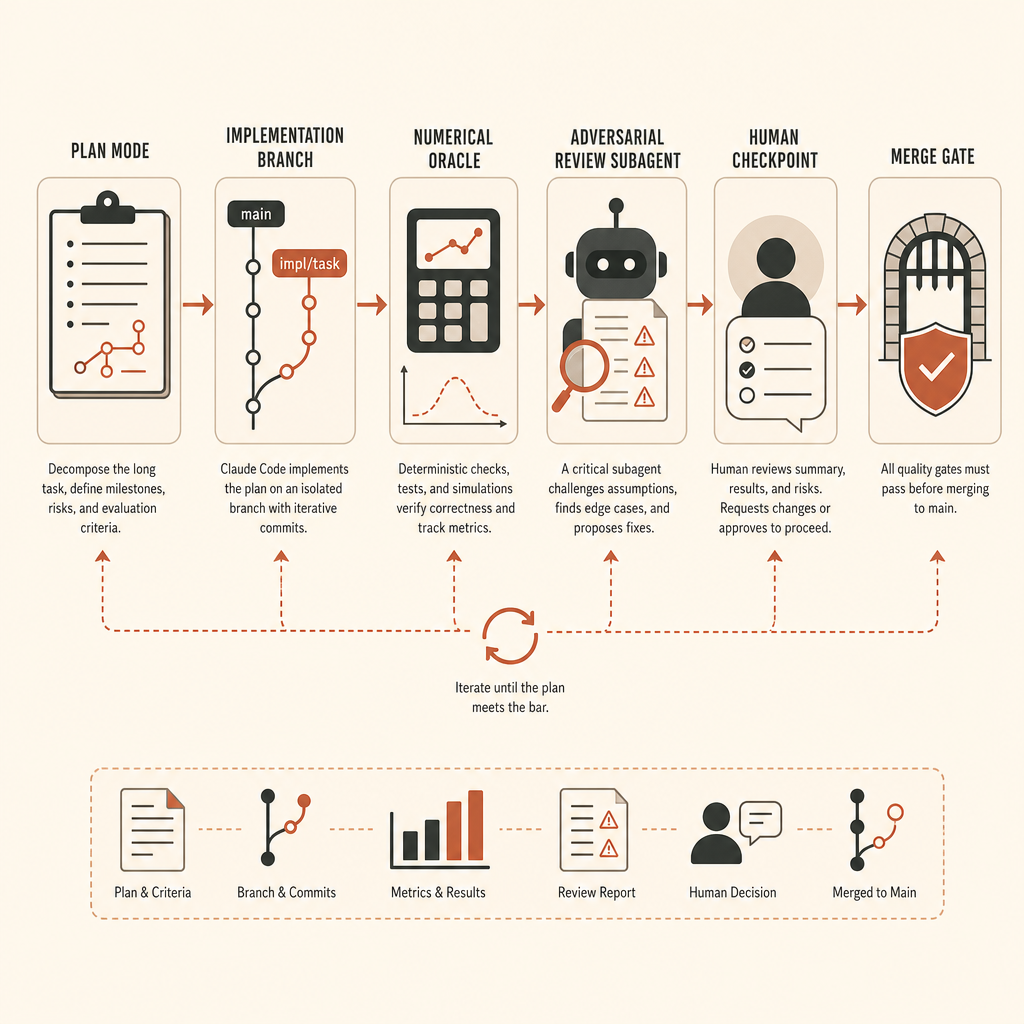
vLLM급 작업이라면 나는 Claude Code를 edit mode로 시작하지 않을 것이다. runbook부터 만들 것이다.
첫째, branch를 만들고 환경을 고정한다. vLLM commit, CUDA/PyTorch 버전, model fixture, seed, test hardware 가정을 pin한다. 대상 작업에 GPU가 필요하다면 oracle에 쓴 정확한 GPU class를 기록한다. CPU fallback이 shape test에만 허용된다면 그렇게 적는다.
둘째, 구현 전에 oracle을 정의한다. activation extraction이라면 기준 경로와 비교 script가 필요하다는 뜻이다. 정확한 임계값은 dtype과 연산 순서에 따라 달라지지만, 에이전트가 시작하기 전에 적어둬야 한다. diff를 본 뒤에 정확도를 협상하지 마라.
셋째, 탐색과 구현을 분리한다. Claude 문서는 수정 전에 plan mode로 “먼저 탐색하고, 그다음 계획하고, 그다음 코딩하라”고 권한다(Claude Code best practices). 대형 ML repo에서는 이게 형식이 아니다. 에이전트가 잘못된 abstraction layer를 풀기 시작하는 것을 막는다.
좋은 초기 prompt는 지루하고 엄격하다.
You are working in a fresh branch. Do not edit files yet.
Goal: implement activation vector extraction in vLLM for specified transformer layers without changing normal generation outputs.
First phase only:
1. Map the relevant execution path for model forward, batching, and tensor return plumbing.
2. Identify the smallest integration point.
3. Propose a test oracle comparing extracted activations to a reference implementation.
4. List files likely to change and files that must not change.
5. Stop and wait for review.
Do not implement until I approve the plan.리뷰 후 구현 prompt에는 중단 조건을 넣어야 한다.
Implement the approved plan.
Hard constraints:
- Do not change public generation behavior unless required by the plan.
- Do not add broad fallback paths that mask extraction failures.
- Do not change unrelated scheduling, sampling, or cache logic.
- Add tests for batch size 1 and >1, at least two sequence lengths, and supported dtypes.
- Run the oracle and report exact max_abs_error and max_rel_error.
- If the oracle cannot run, stop and explain the blocker. Do not mark success.마지막 줄이 중요하다. “가짜 성공” 패턴을 막는다.
Checkpoint는 선택 사항이 아니다
Claude Code에는 자체 checkpoint와 rewind workflow가 있다. 각 prompt가 checkpoint를 만들고, /rewind로 대화나 코드, 또는 둘 다 복원할 수 있다. 문서는 이것이 git의 대체물이 아니라고 분명히 말한다(Claude Code best practices). 안전 모델이 아니라 로컬 undo layer로 다뤄라.
긴 자율 실행에서는 네 개의 롤백 경계가 필요하다.
baseline: 깨끗한 repo, dependency lock, 통과가 확인된 테스트.oracle-only: 기준 비교 script와 fixture, product code 없음.minimal-hook: 가장 작은 extraction 경로, 보기 흉할 수 있음, oracle이 통과하기 시작함.production-shape: 정리된 API, docs, tests, review fix.
에이전트는 경계 안에서는 빠르게 움직여도 된다. 경계를 조용히 넘어가서는 안 된다.
많은 팀이 여기서 틀린다. 에이전트가 research, implementation, refactor, test repair, cleanup을 하나의 거대한 diff로 섞도록 둔다. 최종 patch가 테스트를 통과할 수도 있지만, 어떤 동작이 의도된 것인지 아무도 모른다. ML infra에서는 위험하다. 정확성 버그가 조용할 수 있기 때문이다. 잘못된 레이어의 텐서, pre-norm이 아니라 post-norm 값, 특정 backend에서만 문제를 만드는 dtype cast, cache mutation 이후 복사된 activation 같은 것들이다.
실용적인 요령 하나는 prompt에 “diff budget”을 요구하는 것이다.
Expected change shape:
- Add extraction plumbing in the model execution path.
- Add or extend tests under the relevant vLLM test area.
- Add minimal docs or example usage if there is an existing pattern.
Out of scope:
- Scheduler redesign
- Sampling changes
- KV cache refactors
- Broad API renames
- Performance rewrites에이전트가 범위 밖 영역을 건드리면 논쟁하지 마라. rewind하라.
진짜로 중요한 인간 Checkpoint
7시간 실행이 인간 설계 없이 7시간을 뜻해서는 안 된다. 인간이 코드를 타이핑하지 않는다는 뜻이어야 한다.
이런 종류의 작업에서는 다음 순간에 확인할 것이다.
- 탐색 후: Claude가 실제 실행 경로를 이해했는가?
- oracle 설계 후: 이 테스트가 미묘하게 잘못된 activation을 잡아낼 수 있는가?
- 첫 통과 구현 후: 정상 inference를 보존했는가?
- cleanup 후: surface area를 단순화했는가, 넓혔는가?
- 적대적 리뷰 후: 지적 사항이 정확성 문제인가, 스타일 잡음인가?
Anthropic은 오래 방치한 작업을 완료로 보기 전에 fresh subagent로 적대적 리뷰를 하라고 권한다(Claude Code best practices). 좋은 조언이지만 reviewer를 조율해야 한다. “문제를 찾아라”라고 시킨 reviewer는 잡무를 지어낸다. 정확성 gap, 빠진 requirement, 범위 밖 변경만 보고하라고 해야 한다.
내가 좋아하는 review prompt는 이렇다.
Review this diff against PLAN.md and ORACLE.md.
Report only:
1. Requirements not implemented.
2. Tests that would pass despite a wrong activation tensor.
3. Changes outside the approved scope.
4. Numerical accuracy or dtype/device risks.
Do not report style preferences. Do not suggest new abstractions unless required for correctness.더 최신 Fable급 모델로 이 방식을 실행하고 싶다면, availability를 정확히 확인해야 한다. Anthropic은 2026년 6월 9일 Claude Fable 5와 Mythos 5를 input token 100만 개당 $10, output token 100만 개당 $50에 출시했다(Anthropic). 하지만 6월 12일 Anthropic은 미국 정부 지침을 준수하는 동안 고객의 Fable 5 및 Mythos 5 접근을 비활성화했다고 밝혔다(Anthropic statement). 그러니 실행을 계획하기 전에 live access를 확인하라. 제공사를 통해 사용할 수 있을 때도 같은 harness가 적용된다. 모델 업그레이드가 oracle의 필요성을 없애지는 않는다.
훔쳐야 할 패턴
Rakuten 이야기는 “Claude Code가 이제 거대한 repo도 처리한다”로 오해하기 쉽다. 너무 모호해서 쓸모가 없다.
더 나은 교훈은 이렇다. 긴 자율 코딩은 oracle, plan, review checkpoint, rollback boundary로 작업이 박스화될 때 작동한다. 에이전트는 그 제약 안에서 창의적일 수 있다. 제약이 없으면 “proactive”는 “unbounded”가 되고, 경계 없는 코딩 에이전트는 자신만만한 최종 메시지와 함께 숨은 버그를 만드는 길이다.
ML infra와 platform 팀을 위한 playbook은 단순하다.
- 수치 일치, migration count, latency budget, compatibility matrix처럼 완료를 측정할 수 있는 작업을 고른다.
- feature보다 test oracle을 먼저 쓴다.
- explore-plan-code 분리를 강제한다.
- rollback boundary를 작게 유지한다.
- 주장 말고 증거를 리뷰한다.
- 인간이 승인하기 전에 두 번째 context로 diff를 공격하게 한다.
이것이 7시간짜리 자율 실행을 쇼가 아니라 엔지니어링 workflow로 바꾸는 방법이다.
access가 가능할 때 이런 장기 작업 workflow를 시도해보고 싶다면 Claude Fable 5 on OneHop와 $10 무료로 시작하기를 참고하라.
더 읽을거리: Claude Fable 5 시작하기.

