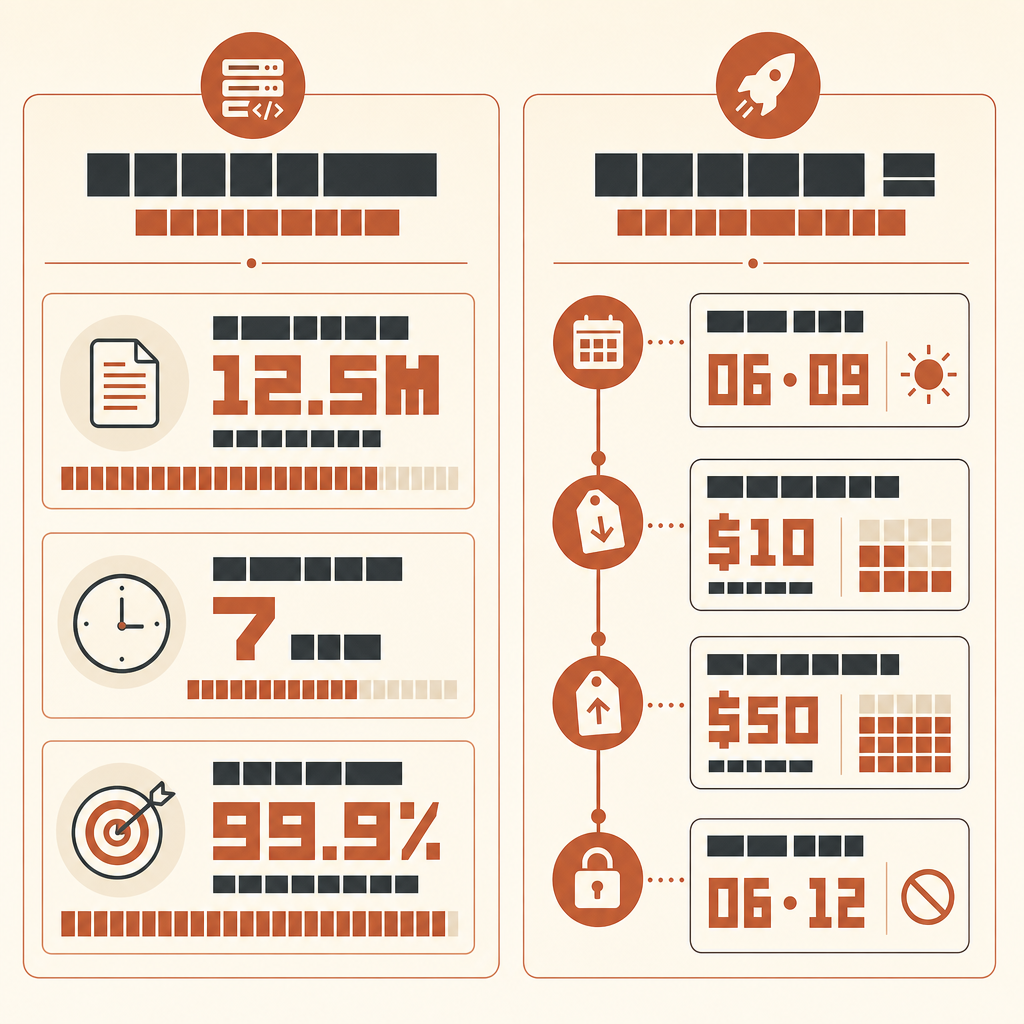
A história mais interessante da Rakuten com Claude Code não é que uma AI escreveu código. É que ela rodou por sete horas em um codebase vLLM multilíngue, com 12,5 milhões de linhas, e ainda terminou com um número: 99,9% de precisão numérica contra um método de referência.
Esse é o sarrafo. Não “pareceu produtivo”. Não “o diff parecia razoável”. Um resultado medido.
No case de cliente da Rakuten publicado pela Anthropic, o engenheiro de machine learning Kenta Naruse pediu ao Claude Code para implementar extração de vetores de ativação no vLLM. Claude Code concluiu o trabalho em uma única execução autônoma, com Naruse dizendo que não escreveu código durante aquelas sete horas e só deu orientações ocasionais. A implementação chegou a 99,9% de precisão numérica em comparação com o método de referência (case Anthropic Rakuten).
Essa história apareceu no mesmo momento em que desenvolvedores estão discutindo se Claude Code e modelos mais novos da classe Fable estão ficando proativos demais: explorando demais, escondendo demais, mudando demais ou produzindo bugs difíceis de enxergar com confiança demais. A resposta certa não é “confie no agente” nem “nunca confie no agente”. A resposta certa é desenhar a execução como um sistema de engenharia.

O Caso: Vetores de Ativação em um Codebase Grande Demais para “Só Ler”
Extração de vetores de ativação parece algo estreito, mas em um sistema como vLLM ela atravessa fronteiras incômodas: execução do modelo, formatos de tensores, batching, premissas de runtime distribuído, tratamento de precisão e caminhos de código sensíveis a performance. É exatamente o tipo de tarefa em que um agente pode ajudar, e exatamente o tipo de tarefa em que um agente pode te prejudicar.
A parte impressionante da execução da Rakuten não são as sete horas. Agentes de longa duração são fáceis de iniciar. A parte impressionante é que a tarefa tinha um oráculo numérico.
Uma versão de blog post dessa tarefa poderia dizer:
Adicione extração de vetores de ativação ao vLLM.
Uma versão de produção deveria dizer:
Implemente extração de vetores de ativação para camadas-alvo do modelo no vLLM, preserve o comportamento de inferência existente, adicione testes comparando as ativações extraídas contra uma implementação de referência e falhe a tarefa a menos que o erro relativo/absoluto fique abaixo do limite acordado em prompts, tamanhos de batch, dtypes e devices representativos.
São trabalhos diferentes. O primeiro convida um diff plausível. O segundo cria um loop fechado.
A própria documentação do Claude Code da Anthropic defende o mesmo ponto em termos gerais: dê ao Claude uma verificação que ele possa executar, porque, caso contrário, “parece pronto” vira o único sinal de conclusão (boas práticas do Claude Code). Para infraestrutura de ML, a verificação não pode ser só “os testes unitários passam”. Ela precisa de um oráculo numérico.
Uma versão compacta da configuração no estilo Rakuten fica assim:
| Limite | Versão ruim | Versão melhor |
|---|---|---|
| Objetivo | “Adicionar extração de ativações” | “Extrair ativações das camadas X/Y sem alterar saídas de geração” |
| Oráculo | “Testes passam” | “Comparar tensores com referência em dtype, batch, comprimento de sequência” |
| Autonomia | “Rodar até terminar” | “Rodar até o oráculo passar, parar se o escopo expandir” |
| Revisão | “Ler o diff final” | “Inspecionar subsistemas tocados, semântica dos tensores, impacto em perf” |
| Rollback | “Git reset se der ruim” | “Checkpoint por fase, branch por tentativa, commits reversíveis” |
A Comunidade Está Reclamando da Coisa Certa
O desconforto atual dos desenvolvedores não é nostalgia anti-AI. É principalmente sobre controle.
No Hacker News, uma thread sobre Claude Code esconder alguns detalhes de progresso virou uma discussão mais ampla sobre o que desenvolvedores realmente precisam ver. Um comentarista formulou bem a distinção útil: raciocínio interno bruto não é o ponto; desenvolvedores precisam de chamadas de ferramentas inspecionáveis, rastros de execução, modos de falha e comportamento reproduzível (Hacker News). Outra reclamação na mesma thread era mais operacional: quando um agente sai por um caminho de exploração amplo, o usuário pode gastar 20 ou 30 minutos antes de perceber que ele se perdeu.
O Reddit tem a versão mais afiada da mesma reclamação. Em uma thread no ClaudeAI, um usuário descreveu o verdadeiro sugador de tempo como “sucesso falso e silencioso”: o agente fez o código parecer funcionar adicionando comportamento de fallback em vez de corrigir o caminho que falhava (Reddit). Em outra discussão sobre Fable 5, usuários se dividiram entre “ele corrigiu problemas com os quais o Opus sofreu” e “ele produziu código extra com edge cases perdidos” (Reddit).
Agora há pesquisa colocando números por trás dessa preocupação. Um preprint de maio de 2026 sobre agentes de codificação ansiosos demais relata que remover uma declaração explícita de consentimento elevou a taxa de ações ansiosas demais do Claude Code de 0,0% para 17,1% em cenários pareados (arXiv). Você não precisa tratar isso como um benchmark universal para levar a lição a sério: autonomia depende fortemente do harness e das instruções.
O erro é debater se o modelo é “bom” ou “ruim”. A pergunta útil é: você construiu uma caixa ao redor do agente para que a iniciativa dele seja produtiva dentro da caixa e cara fora dela?
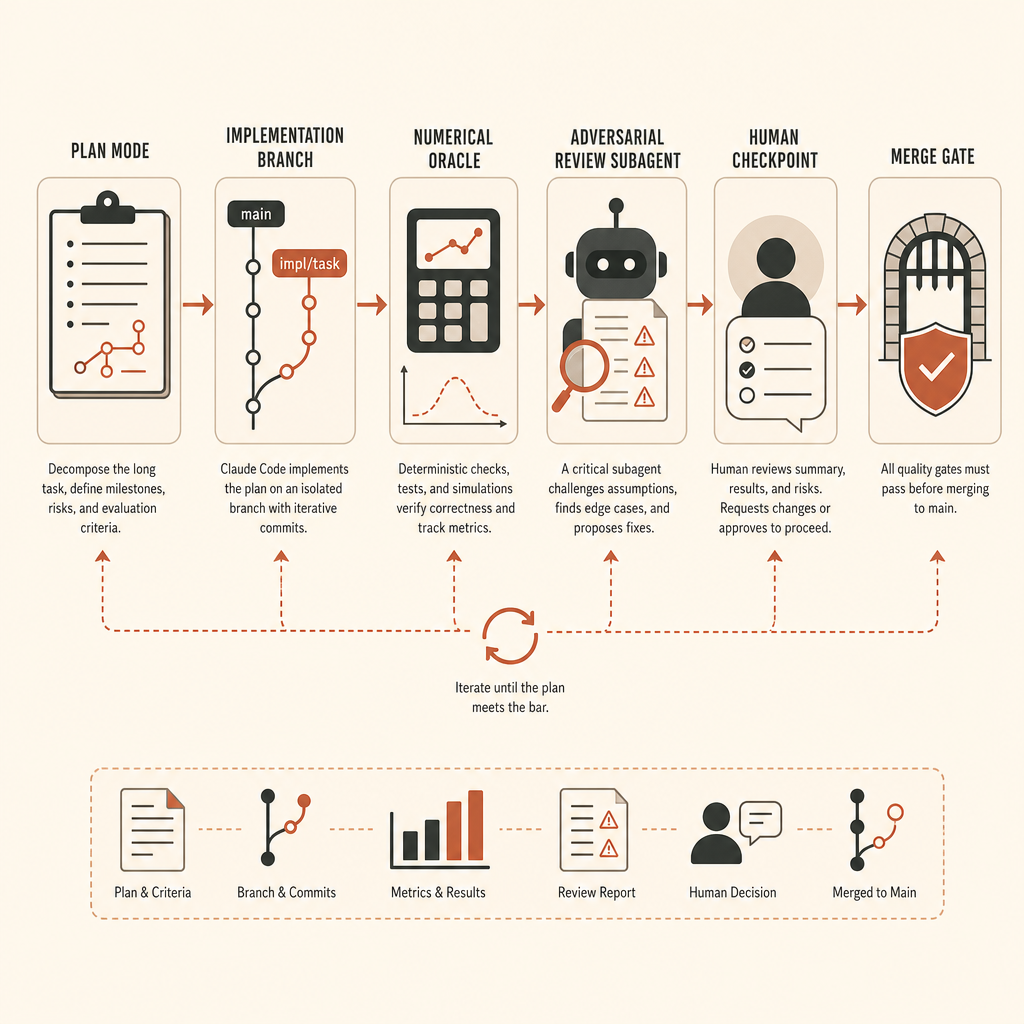
O Harness de Tarefas Longas que Eu Usaria
Para uma tarefa no nível do vLLM, eu não começaria com Claude Code em modo de edição. Eu começaria com um runbook.
Primeiro, crie uma branch e congele o ambiente. Fixe o commit do vLLM, versões de CUDA/PyTorch, fixture do modelo, seeds e premissas de hardware dos testes. Se o alvo exigir GPUs, registre a classe exata de GPU usada para o oráculo. Se fallback em CPU for aceitável apenas para testes de shape, diga isso.
Segundo, defina o oráculo antes da implementação. Para extração de ativações, isso significa um caminho de referência e um script de comparação. O limite exato depende de dtype e ordem das operações, mas deve estar escrito antes de o agente começar. Não negocie precisão depois de ver o diff.
Terceiro, separe exploração de implementação. A documentação do Claude recomenda “Explore primeiro, depois planeje, depois codifique”, com modo de plano antes das edições (boas práticas do Claude Code). Em um repo grande de ML, isso não é cerimônia. É o que impede o agente de resolver a camada de abstração errada.
Um bom prompt inicial é chato e rígido:
You are working in a fresh branch. Do not edit files yet.
Goal: implement activation vector extraction in vLLM for specified transformer layers without changing normal generation outputs.
First phase only:
1. Map the relevant execution path for model forward, batching, and tensor return plumbing.
2. Identify the smallest integration point.
3. Propose a test oracle comparing extracted activations to a reference implementation.
4. List files likely to change and files that must not change.
5. Stop and wait for review.
Do not implement until I approve the plan.Depois da revisão, o prompt de implementação deve carregar as condições de parada:
Implement the approved plan.
Hard constraints:
- Do not change public generation behavior unless required by the plan.
- Do not add broad fallback paths that mask extraction failures.
- Do not change unrelated scheduling, sampling, or cache logic.
- Add tests for batch size 1 and >1, at least two sequence lengths, and supported dtypes.
- Run the oracle and report exact max_abs_error and max_rel_error.
- If the oracle cannot run, stop and explain the blocker. Do not mark success.Essa última linha importa. Ela bloqueia o padrão de “sucesso falso”.
Checkpoints Não São Opcionais
Claude Code tem seu próprio fluxo de checkpoint e rewind: cada prompt cria um checkpoint, e /rewind pode restaurar a conversa, o código ou ambos. A documentação deixa claro que isso não substitui git (boas práticas do Claude Code). Trate isso como uma camada local de desfazer, não como seu modelo de segurança.
Para execuções autônomas longas, eu quero quatro fronteiras de rollback:
baseline: repo limpo, dependências travadas, testes conhecidos passando.oracle-only: script de comparação de referência e fixtures, sem código de produto.minimal-hook: menor caminho de extração, talvez feio, oráculo começa a passar.production-shape: API limpa, docs, testes, correções de review.
O agente pode se mover rapidamente dentro de uma fronteira. Ele não deve cruzar uma sem avisar.
É aqui que muitos times erram. Eles deixam o agente combinar pesquisa, implementação, refatoração, conserto de testes e limpeza em um diff gigante. O patch final pode passar nos testes, mas ninguém sabe qual comportamento foi intencional. Em infraestrutura de ML, isso é perigoso porque bugs de correção podem ser silenciosos: um tensor da camada errada, um valor post-norm em vez de pre-norm, um cast de dtype que só prejudica um backend, uma ativação copiada depois de mutação de cache.
Um truque prático: exigir um “orçamento de diff” no prompt.
Expected change shape:
- Add extraction plumbing in the model execution path.
- Add or extend tests under the relevant vLLM test area.
- Add minimal docs or example usage if there is an existing pattern.
Out of scope:
- Scheduler redesign
- Sampling changes
- KV cache refactors
- Broad API renames
- Performance rewritesSe o agente tocar áreas fora do escopo, você não debate. Você dá rewind.
Os Checkpoints Humanos que Realmente Importam
Uma execução de sete horas não deveria significar sete horas sem design humano. Deveria significar que o humano não está digitando o código.
Para essa classe de tarefa, eu faria check-in nestes momentos:
- Depois da exploração: Claude entendeu o caminho real de execução?
- Depois do design do oráculo: esse teste pegaria uma ativação sutilmente errada?
- Depois da primeira implementação passando: ela preservou a inferência normal?
- Depois da limpeza: ela simplificou ou ampliou a superfície?
- Depois da revisão adversarial: os achados são problemas de correção ou ruído de estilo?
A Anthropic recomenda usar um subagente novo para revisão adversarial antes de tratar trabalho longo sem supervisão como concluído (boas práticas do Claude Code). É um bom conselho, mas calibre o revisor. Um revisor instruído a “encontrar problemas” vai inventar tarefas. Peça para ele reportar apenas lacunas de correção, requisitos faltantes e mudanças fora de escopo.
Um prompt de revisão que eu gosto:
Review this diff against PLAN.md and ORACLE.md.
Report only:
1. Requirements not implemented.
2. Tests that would pass despite a wrong activation tensor.
3. Changes outside the approved scope.
4. Numerical accuracy or dtype/device risks.
Do not report style preferences. Do not suggest new abstractions unless required for correctness.Se você quiser rodar isso com modelos mais novos da classe Fable, seja preciso sobre disponibilidade. A Anthropic lançou Claude Fable 5 e Mythos 5 em 9 de junho de 2026 a US$10 por milhão de tokens de entrada e US$50 por milhão de tokens de saída (Anthropic), mas em 12 de junho a Anthropic disse que havia desabilitado o acesso de clientes ao Fable 5 e Mythos 5 enquanto cumpria uma diretiva do governo dos EUA (declaração da Anthropic). Então verifique o acesso ao vivo antes de planejar uma execução. Quando estiver disponível pelo seu provedor, o mesmo harness se aplica; o upgrade do modelo não elimina a necessidade de um oráculo.
O Padrão para Roubar
É fácil interpretar mal a história da Rakuten como “Claude Code agora dá conta de repos enormes”. Isso é vago demais para ser útil.
A conclusão melhor é esta: codificação autônoma longa funciona quando a tarefa é encaixotada por um oráculo, um plano, checkpoints de revisão e fronteiras de rollback. O agente pode ser criativo dentro dessas restrições. Sem elas, “proativo” vira “sem limites”, e agentes de codificação sem limites são como você acaba com bugs escondidos e uma mensagem final confiante.
Para times de infraestrutura de ML e plataforma, o playbook é simples:
- Escolha tarefas com conclusão mensurável: correspondência numérica, contagem de migração, orçamento de latência, matriz de compatibilidade.
- Escreva o oráculo de teste antes da feature.
- Force a separação explorar-planejar-codificar.
- Mantenha pequenas as fronteiras de rollback.
- Revise evidências, não alegações.
- Use um segundo contexto para atacar o diff antes de humanos aprovarem.
É assim que você transforma uma execução autônoma de sete horas de uma façanha em um fluxo de trabalho de engenharia.
Se quiser testar esse estilo de fluxo de trabalho para tarefas longas quando o acesso estiver disponível, veja Claude Fable 5 no OneHop e comece com US$10 grátis.
Leitura complementar: Primeiros passos com Claude Fable 5.

