6 月 12 日之後,路由問題從「哪個前沿模型最好?」變成了「你選的模型突然消失時怎麼辦?」
Anthropic 表示,它在 2026 年 6 月 12 日美東時間下午 5:21 收到美國政府指令,要求暫停外國國民存取 Fable 5 和 Mythos 5。它給出的實務回應很直接:對所有客戶停用這兩個模型,同時保留其他 Anthropic 模型可用(Anthropic)。同一篇文章也說,Anthropic 檢視了所謂越獄依據,發現展示出來的能力其實在其他公開模型上「廣泛可得」,並明確點名 OpenAI 的 GPT-5.5(Anthropic)。
這讓開發者要回答的問題變得異常具體。如果 Fable 5 今天從你的技術棧裡消失,你該路由到 Claude Opus 4.8、改用 GPT-5.5,還是建立供應商路由器,別再把你的 agent 押在單一端點上?
我的答案是:對既有 Claude Code 和 Anthropic API 工作流程,用 Opus 4.8 當預設的 Claude 原生備援;當你需要更強的 terminal-bench 類型程式能力證據,或更貼合 OpenAI 生態系,就用 GPT-5.5;如果工作負載真的重要,就加上路由。如果單一模型故障就能讓你的 agent 停擺,bug 在你的架構裡。
實際離線的是什麼
Anthropic 並沒有說「Claude 掛了」。它說的是 Fable 5 和 Mythos 5 對所有客戶停用,而「所有其他 Anthropic 模型」仍然可用(Anthropic)。這個差別很重要。
Fable 5 是公開的 Mythos 級模型。Mythos 5 則是限制更多的版本。Opus 4.8 仍然在線,Anthropic 將它定位為「為嚴肅程式開發與 AI agents 打造的混合推理模型」,並具備 100 萬 token 的 context window(Anthropic)。
這場爭議也不只是政策秀。Anthropic 6 月 12 日的聲明說,政府關切的是一個狹窄的越獄手法,被用來找出少數已知的輕微漏洞;而 Anthropic 主張,其他公開模型不需要繞過限制,也能發現同類問題(Anthropic)。這就是 GPT-5.5 在這裡有關聯的原因。Anthropic 親自把它列為在爭議能力類別上可比較的模型。
對開發者來說,關鍵事實更簡單:你的 production agent 不在乎存取為什麼消失。它只看得到呼叫失敗、model ID 不見、工作流程降級,以及使用者問你為什麼昨天還能用的工具今天不行。
能力與價格表
下面是冷靜版比較。沒有硬湊的 benchmark 大雜燴,也沒有把感覺偽裝成資料。
| Model | Current role | Input price | Output price | Context | Useful verified capability signals |
|---|---|---|---|---|---|
| Claude Opus 4.8 | Fable 5 無法使用時最佳 Anthropic 備援 | $5 / 1M tokens | $25 / 1M tokens | 1M tokens | Anthropic 表示它是為嚴肅程式開發、agents 和長時間任務打造;可在 Claude API、AWS、Google Cloud 和 Microsoft Foundry 使用(Anthropic) |
| GPT-5.5 | 程式 agents 的強力 OpenAI 替代方案 | $5 / 1M tokens | $30 / 1M tokens | API 中 1M tokens | OpenAI 回報 SWE-Bench Pro Public 58.6%、Terminal-Bench 2.0 82.7%、CyberGym 81.8%、Graphwalks BFS 1M F1 45.4%(OpenAI) |
| Claude Fable 5 | 首選高階 Claude 路徑,目前無法透過 Anthropic 使用 | $10 / 1M tokens list | $50 / 1M tokens list | 1M tokens | 在 6 月 12 日指令後,Anthropic 已對所有客戶停用(Anthropic) |
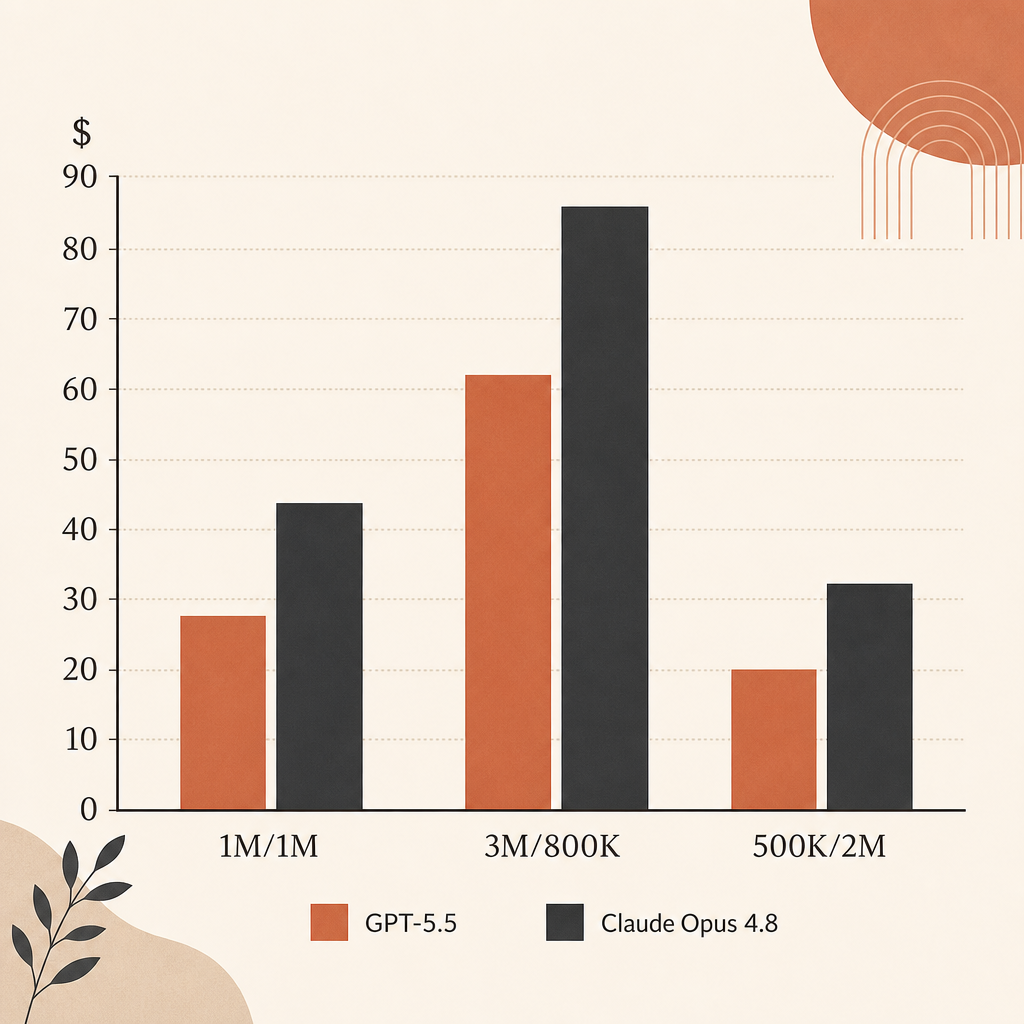
就原始表定價格來看,對 output-heavy 的 agent 執行,Opus 4.8 比 GPT-5.5 便宜。輸入同樣是 $5/M。輸出則是 Opus 4.8 的 $25/M,對上 GPT-5.5 的 $30/M。
幾個實際一點的 agent 帳單:
| Workload | Opus 4.8 | GPT-5.5 | Difference |
|---|---|---|---|
| 1M input, 1M output | $30 | $35 | GPT-5.5 貴 16.7% |
| 3M input, 800K output | $35 | $39 | GPT-5.5 貴 11.4% |
| 500K input, 2M output | $52.50 | $62.50 | GPT-5.5 貴 19.0% |
這不代表 Opus 一定贏。一個能一次完成的模型,可能比一個價格較低但會繞圈、重試、或在碰 repo 之前先寫五頁計畫的模型更便宜。Simon Willison 的 Fable 5 除錯文章底下那串 HN 討論,正好充滿這種分歧:有些開發者喜歡那種「不屈不撓地主動」的行為,另一些人看到的是浪費、token 燃燒,以及為了一個小修正啟動太多自主機械(Hacker News)。
社群爭論說對了什麼
最好的開發者討論不是「Claude 好」對上「OpenAI 好」。重點是控制權。
Simon Willison 6 月 11 日的文章是最清楚的案例。他給 Claude Fable 5 一張截圖,以及一句關於 scrollbar bug 的提示。模型建立本地重現頁面、打開真實瀏覽器、透過 Quartz 使用 macOS window IDs、截圖、注入 JavaScript、跑一個小型 CORS server、測量 shadow DOM,接著在撞到 guardrail 後交棒給 Opus(Simon Willison)。他的成本追蹤器估算,這段 session 若以全價計算大約要 $12.11。
那篇文章底下的 HN 討論有價值,因為它拒絕假共識。一派認為這正是 agentic coding 應有的樣子:使用工具、對照現實驗證、產出 artifacts。另一派認為,為了修一個 CSS scrollbar 而燒錢又開 shell access,是錯誤的抽象,尤其當 agent 不在嚴格 sandbox 裡運作時(Hacker News)。
Reddit 沒那麼整齊,但它抓到了營運面的痛。在 r/ClaudeCode,開發者已經開始嘗試把 Fable 式行為萃取成給 Opus 4.8 的 instruction files,分享 Fable5.md prompts、--append-system-prompt-file 想法,以及「讓 Opus 更主動」的配方(Reddit)。在 r/cybersecurity 和 r/LocalLLaMA,討論轉向平台風險:如果一個前沿 hosted model 能在一夜之間被撤掉,嚴肅團隊是不是該更多依賴本地模型、多供應商路由,或較低階的 hosted fallbacks(Reddit, Reddit)。
很多討論缺少的務實答案是:不要試圖靠「prompt」解決供應商風險。Prompts 可以讓 Opus 行為更像 Fable。它們不能讓一個不可用的模型變可用。
想要 Claude 延續性時用 Opus 4.8
當你的系統已經依賴 Claude 的 tool-use 風格、長 context 行為、Claude Code、Anthropic Messages API 語義,或 prompt caching,就選 Claude Opus 4.8。
Opus 4.8 是干擾最小的備援。Anthropic 自己的 Opus 頁面說,模型可用名稱是 claude-opus-4-8,價格從 $5/M input 和 $25/M output 起,支援最高 90% 的 prompt caching 節省,以及 50% 的 batch processing 節省(Anthropic)。如果你是圍繞 Claude 的 message format、system prompts、tool calls 或 CLAUDE.md 慣例建置,留在 Claude 家族裡能降低遷移風險。
適合用在:
- 大型 codebase review,模型需要掌握大量檔案與慣例。
- 受益於 Claude 謹慎規劃與自我檢查的 agentic workflows。
- 已經使用 Claude Code,並想要低摩擦 Fable 5 備援的團隊。
- GPT-5.5 的 $30/M output 價格開始有感的 output-heavy jobs。
- 能利用 prompt caching 的工作流程。
弱點是 benchmark 清晰度。OpenAI 的 GPT-5.5 頁面提供很多可從文字讀取的 benchmark 數字。Anthropic 的 Opus 4.8 頁面提供定位、價格、context、合作夥伴引用,以及圖片式 benchmark 區塊,但頁面文字中可輕易稽核的數字比較較少。如果你的採購流程需要一張列出具名 benchmark 分數的表,GPT-5.5 比較容易辯護。
但如果問題是「Fable 消失後,我的 Claude agent 現在該呼叫什麼?」,先從 Opus 4.8 開始。
想要證據與 OpenAI 契合度時用 GPT-5.5
當你想要一個具備公開 benchmark 數字的強力程式模型、OpenAI API 相容性,或 Codex 整合,就選 GPT-5.5。
OpenAI 表示,GPT-5.5 對 API 開發者的價格是 $5/M input 和 $30/M output,context window 為 100 萬 tokens(OpenAI)。它公布的程式與工具數字很強:Terminal-Bench 2.0 82.7%、SWE-Bench Pro Public 58.6%、MCP Atlas 75.3%、CyberGym 81.8%(OpenAI)。OpenAI 也把 GPT-5.5 的 cyber 和 bio/chemical 能力在 Preparedness Framework 下歸類為 High,同時表示它沒有達到 Critical cybersecurity capability level(OpenAI)。
適合用在:
- terminal-heavy coding tasks,且 Terminal-Bench 類型表現能對應你的工作負載。
- 交叉檢查 Claude plans,尤其是 security-sensitive 或 migration-heavy changes。
- 已經標準化使用 OpenAI Responses 或 Chat Completions 的團隊。
- 在 agent routers 中,讓 GPT-5.5 擔任 reviewer、critic,或 second-pass verifier。
- 公開數字評測比 Claude workflow continuity 更重要的情境。
缺點是 output-heavy 執行的成本。GPT-5.5 並沒有貴到誇張,但 agent loops 會產生 output。如果你的 agent 會寫很長的 plans、很長的 diffs、很長的 test logs 和很長的 postmortems,那 $5/M 的 output 價差就會浮現。
更好的架構:路由,不要祈禱
這是我真的會上線的選擇指南:
- Claude-native coding agents 預設用 Opus 4.8。
- 對 independent review、terminal-heavy tasks 和 OpenAI-native stacks 路由到 GPT-5.5。
- 保留 Fable 5 路徑,但不要讓 production 卡在它身上。
- 加上 budget caps、sandboxing,以及 per-task model policies。
- 記錄 model、provider、token mix、fallback reason,以及最後的人類 approval。
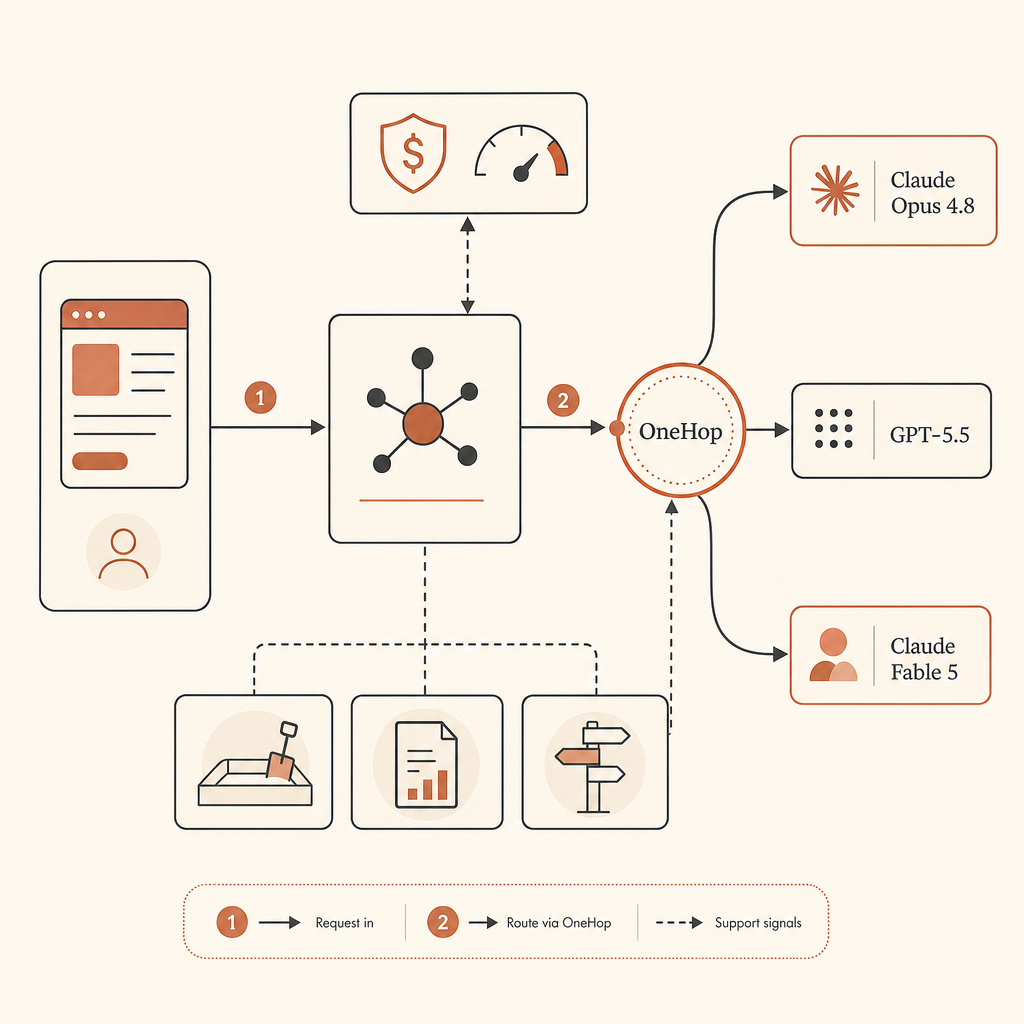
供應商路由器不需要很花俏。先從一個 policy file 開始:
routes:
default_coding: claude-opus-4-8
critical_review: gpt-5.5
long_context_refactor: claude-opus-4-8
security_review: gpt-5.5
limits:
max_usd_per_task: 8
require_approval_over_usd: 3然後在 model call 之前強制執行。重點不是追求完美的自動路由。重點是不要把業務連續性硬編碼到單一 model ID 上。
如果你在可存取時仍然想用 Fable 5,OneHop 是最少摩擦、值得保留在 routing table 裡的路徑。OneHop 將 Claude Fable 5 列為 anthropic/claude-fable-5,顯示官方 $10/M input 與 $50/M output 表定價格,並宣傳折扣價格,以及新帳號免綁卡 $10 免費額度(OneHop)。自然的模式是保持 app 的 provider abstraction 穩定,然後替換 base URL。
對 OpenAI-compatible clients:
from openai import OpenAI
client = OpenAI(
base_url="https://api.onehop.ai/v1",
api_key="ONEHOP_API_KEY",
)
response = client.chat.completions.create(
model="anthropic/claude-fable-5",
messages=[
{"role": "user", "content": "Review this migration plan for hidden failure modes."}
],
)
print(response.choices[0].message.content)當你明確需要 Fable 路由時,使用 Claude Fable 5 on OneHop。如果你要從零開始測試供應商路由,先拿 $10 free。
最後建議刻意無聊。如果 Fable 5 無法使用,不要花一週爭論 Opus 4.8 或 GPT-5.5 哪個個性更好。把 Opus 4.8 放進 Claude fallback slot。把 GPT-5.5 放進 reviewer 和 OpenAI-native slot。Fable 5 可用時,透過 OneHop 保留成 routed option。然後衡量你自己的任務:pass rate、human edits、wall-clock time、token cost,以及 rollback count。
這才是成熟做法。模型粉絲辯論很有趣。Production agents 需要的是退場方案。

