Der 12. Juni hat die Routing-Debatte von „Welches Frontier-Modell ist das beste?“ zu „Was passiert, wenn das Modell, auf das du gesetzt hast, verschwindet?“ verschoben.
Anthropic sagt, man habe am 12. Juni 2026 um 17:21 Uhr ET eine Anweisung der US-Regierung erhalten, den Zugriff auf Fable 5 und Mythos 5 für ausländische Staatsangehörige auszusetzen. Die praktische Antwort war nüchtern: beide Modelle für alle Kunden deaktivieren, während andere Anthropic-Modelle verfügbar bleiben (Anthropic). Im selben Beitrag heißt es, Anthropic habe die gemeldete Jailbreak-Grundlage geprüft und die demonstrierte Fähigkeit als „widely available“ bei anderen öffentlichen Modellen eingestuft, ausdrücklich inklusive OpenAIs GPT-5.5 (Anthropic).
Damit wird die Entwicklerfrage ungewöhnlich konkret. Wenn Fable 5 heute aus deinem Stack verschwunden ist: routest du zu Claude Opus 4.8, wechselst du zu GPT-5.5, oder baust du einen Provider-Router und hörst auf, deinen Agenten auf einen einzigen Endpoint zu verwetten?
Meine Antwort: Nutze Opus 4.8 als Standard-Fallback innerhalb der Claude-Welt für bestehende Claude Code- und Anthropic API-Workflows, nutze GPT-5.5, wenn du stärkere Coding-Evidenz im Terminal-Bench-Stil oder bessere OpenAI-Ökosystem-Passung willst, und baue Routing ein, wenn der Workload wichtig ist. Wenn ein einzelner Modell-Ausfall deinen Agenten stoppen kann, steckt der Bug in deiner Architektur.
Was Tatsächlich Offline Ging
Anthropic hat nicht gesagt: „Claude ist down.“ Es hieß, Fable 5 und Mythos 5 seien für alle Kunden deaktiviert worden, während „all other Anthropic models“ verfügbar bleiben (Anthropic). Dieser Unterschied zählt.
Fable 5 war das öffentliche Modell der Mythos-Klasse. Mythos 5 war die stärker eingeschränkte Version. Opus 4.8 bleibt live, und Anthropic positioniert es als „hybrid reasoning model built for serious coding and AI agents“ mit einem Kontextfenster von 1 Mio. Tokens (Anthropic).
Der Streit ist auch nicht bloß Policy-Theater. Anthropic schreibt in der Erklärung vom 12. Juni, die Sorge der Regierung habe einen engen Jailbreak betroffen, mit dem eine kleine Zahl bereits bekannter kleiner Schwachstellen gefunden wurde; Anthropic argumentiert, andere öffentliche Modelle könnten dieselbe Klasse von Problemen auch ohne Bypass entdecken (Anthropic). Genau deshalb ist GPT-5.5 hier relevant. Anthropic hat es als vergleichbar für die umstrittene Fähigkeitsklasse benannt.
Für Entwickler ist der entscheidende Fakt einfacher: Deinem Produktions-Agenten ist egal, warum der Zugriff verschwunden ist. Er sieht nur fehlgeschlagene Calls, fehlende Modell-IDs, degradierte Workflows und Nutzer, die fragen, warum das Tool von gestern heute nicht mehr funktioniert.
Capability- und Preistabelle
Hier ist der nüchterne Vergleich. Keine erfundene Benchmark-Suppe, keine Vibes, die so tun, als wären sie Daten.
| Model | Current role | Input price | Output price | Context | Useful verified capability signals |
|---|---|---|---|---|---|
| Claude Opus 4.8 | Bester Anthropic-Fallback, wenn Fable 5 nicht verfügbar ist | $5 / 1M tokens | $25 / 1M tokens | 1M tokens | Anthropic sagt, es sei für ernsthaftes Coding, Agenten und lang laufende Aufgaben gebaut; verfügbar in Claude API, AWS, Google Cloud und Microsoft Foundry (Anthropic) |
| GPT-5.5 | Starke OpenAI-Alternative für Coding-Agenten | $5 / 1M tokens | $30 / 1M tokens | 1M tokens in API | OpenAI meldet 58.6% auf SWE-Bench Pro Public, 82.7% auf Terminal-Bench 2.0, 81.8% auf CyberGym und 45.4% auf Graphwalks BFS 1M F1 (OpenAI) |
| Claude Fable 5 | Bevorzugter Claude-Pfad am oberen Ende, aktuell über Anthropic nicht verfügbar | $10 / 1M tokens list | $50 / 1M tokens list | 1M tokens | Von Anthropic nach der Anweisung vom 12. Juni für alle Kunden deaktiviert (Anthropic) |
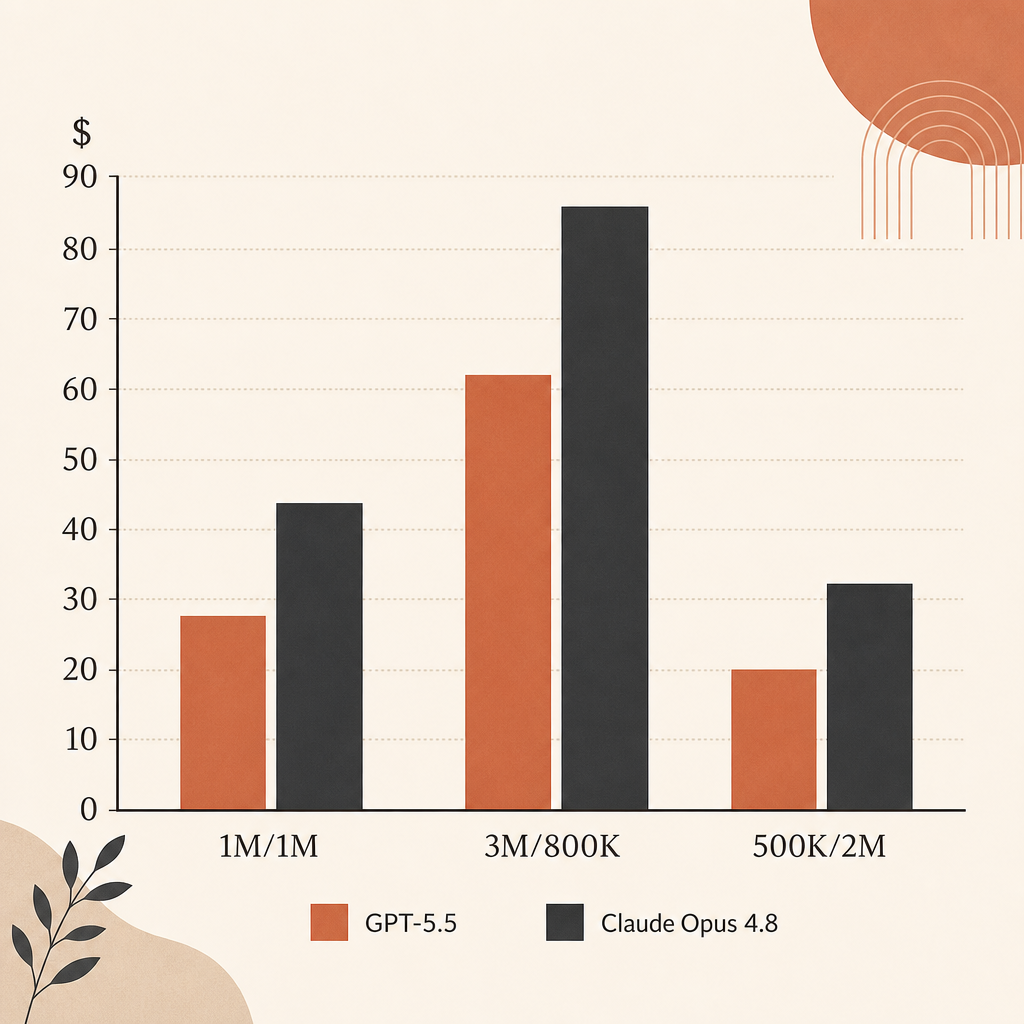
Beim reinen Listenpreis ist Opus 4.8 für output-lastige Agentenläufe günstiger als GPT-5.5. Input liegt mit $5/M gleichauf. Output kostet $25/M bei Opus 4.8 und $30/M bei GPT-5.5.
Ein paar realistische Agenten-Rechnungen:
| Workload | Opus 4.8 | GPT-5.5 | Difference |
|---|---|---|---|
| 1M input, 1M output | $30 | $35 | GPT-5.5 kostet 16.7% mehr |
| 3M input, 800K output | $35 | $39 | GPT-5.5 kostet 11.4% mehr |
| 500K input, 2M output | $52.50 | $62.50 | GPT-5.5 kostet 19.0% mehr |
Das heißt nicht, dass Opus immer gewinnt. Ein Modell, das es in einem Durchlauf schafft, kann günstiger sein als ein billigeres Modell, das schleift, retries macht oder fünf Seiten Plan schreibt, bevor es das Repo anfasst. Der HN-Thread zu Simon Willisons Fable 5-Debugging-Post ist voll von genau dieser Spaltung: Einige Entwickler liebten das „relentlessly proactive“-Verhalten, andere sahen Verschwendung, Token-Burn und zu viel autonome Maschinerie für einen kleinen Fix (Hacker News).
Was die Community-Debatte Richtig Sieht
Die beste Entwicklerdiskussion ist nicht „Claude gut“ gegen „OpenAI gut“. Es geht um Kontrolle.
Simon Willisons Beitrag vom 11. Juni ist das klarste Beispiel. Er gab Claude Fable 5 einen Screenshot und einen Ein-Zeilen-Prompt zu einem Scrollbar-Bug. Das Modell baute lokale Repro-Seiten, öffnete echte Browser, nutzte macOS-Fenster-IDs über Quartz, machte Screenshots, injizierte JavaScript, startete einen kleinen CORS-Server, maß das Shadow DOM und übergab dann an Opus, nachdem es auf eine Guardrail gestoßen war (Simon Willison). Sein Cost Tracker schätzte, dass die Session zum Vollpreis etwa $12.11 gekostet hätte.
Der HN-Thread darunter ist nützlich, weil er den falschen Konsens ablehnt. Ein Lager sagt: Genau so sollte agentisches Coding aussehen — Tools nutzen, gegen die Realität prüfen, Artefakte liefern. Das andere sagt: Dollar und Shell-Zugriff zu verbrennen, um eine CSS-Scrollbar zu fixen, ist die falsche Abstraktion, besonders wenn der Agent außerhalb einer engen Sandbox arbeitet (Hacker News).
Reddit ist weniger aufgeräumt, aber es zeigt den operativen Schmerz. In r/ClaudeCode versuchen Entwickler bereits, Fable-ähnliches Verhalten in Instruction-Files für Opus 4.8 zu destillieren, teilen Fable5.md-Prompts, --append-system-prompt-file-Ideen und Rezepte, um „Opus proaktiver“ zu machen (Reddit). In r/cybersecurity und r/LocalLLaMA verschiebt sich die Debatte zum Plattformrisiko: Wenn ein gehostetes Frontier-Modell über Nacht gezogen werden kann, sollten ernsthafte Teams stärker auf lokale Modelle, Multi-Provider-Routing oder niedrigere gehostete Fallbacks setzen (Reddit, Reddit).
Die praktische Antwort, die in vielen Threads fehlt: Versuche nicht, Provider-Risiko wegzuprompten. Prompts können Opus dazu bringen, sich mehr wie Fable zu verhalten. Sie können ein nicht verfügbares Modell nicht verfügbar machen.
Nutze Opus 4.8, Wenn Du Claude-Kontinuität Willst
Wähle Claude Opus 4.8, wenn dein System bereits von Claudes Tool-Use-Stil, Long-Context-Verhalten, Claude Code, der Semantik der Anthropic Messages API oder Prompt Caching abhängt.
Opus 4.8 ist der am wenigsten störende Fallback. Anthropic schreibt auf der eigenen Opus-Seite, das Modell sei als claude-opus-4-8 verfügbar, starte bei $5/M Input und $25/M Output, unterstütze Prompt-Caching-Ersparnisse von bis zu 90% und Batch-Processing-Ersparnisse von 50% (Anthropic). Wenn du um Claudes Nachrichtenformat, System-Prompts, Tool Calls oder CLAUDE.md-Konventionen herum gebaut hast, reduziert ein Verbleib in der Claude-Familie das Migrationsrisiko.
Nutze es für:
- Reviews großer Codebases, bei denen das Modell viele Dateien und Konventionen im Kopf behalten muss.
- Agentische Workflows, die von Claudes vorsichtiger Planung und Selbstprüfung profitieren.
- Teams, die bereits Claude Code nutzen und einen reibungsarmen Fable 5-Fallback wollen.
- Output-lastige Jobs, bei denen GPT-5.5s Output-Preis von $30/M ins Gewicht fällt.
- Workflows, die Prompt Caching ausnutzen können.
Die Schwäche ist Benchmark-Klarheit. OpenAIs GPT-5.5-Seite liefert viele als Text lesbare Benchmark-Zahlen. Anthropics Opus 4.8-Seite liefert Positionierung, Preise, Kontext, Partnerzitate und einen bildbasierten Benchmark-Abschnitt, aber weniger leicht auditierbare numerische Vergleiche im Seitentext. Wenn dein Procurement-Prozess eine Tabelle mit benannten Benchmark-Scores braucht, ist GPT-5.5 leichter zu verteidigen.
Trotzdem: Wenn die Frage lautet „Was soll mein Claude-Agent jetzt aufrufen, wo Fable weg ist?“, fang mit Opus 4.8 an.
Nutze GPT-5.5, Wenn Du Evidenz und OpenAI-Passung Willst
Wähle GPT-5.5, wenn du ein starkes Coding-Modell mit öffentlichen Benchmark-Zahlen, OpenAI API-Kompatibilität oder Codex-Integration willst.
OpenAI sagt, GPT-5.5 koste für API-Entwickler $5/M Input und $30/M Output, mit einem Kontextfenster von 1 Mio. Tokens (OpenAI). Die veröffentlichten Coding- und Tool-Zahlen sind stark: 82.7% auf Terminal-Bench 2.0, 58.6% auf SWE-Bench Pro Public, 75.3% auf MCP Atlas und 81.8% auf CyberGym (OpenAI). OpenAI stuft außerdem die Cyber- und Bio-/Chemie-Fähigkeiten von GPT-5.5 im Preparedness Framework als High ein, sagt aber, es habe kein Critical-Cybersecurity-Fähigkeitsniveau erreicht (OpenAI).
Nutze es für:
- Terminal-lastige Coding-Aufgaben, bei denen Terminal-Bench-artige Performance zu deinem Workload passt.
- Cross-Checks von Claude-Plänen, besonders bei sicherheitssensiblen oder migrationslastigen Änderungen.
- Teams, die bereits auf OpenAI Responses oder Chat Completions standardisiert sind.
- Agenten-Router, in denen GPT-5.5 als Reviewer, Kritiker oder Second-Pass-Verifier agiert.
- Fälle, in denen öffentliche numerische Evals wichtiger sind als Claude-Workflow-Kontinuität.
Der Nachteil sind die Kosten bei output-lastigen Läufen. GPT-5.5 ist nicht dramatisch teurer, aber Agenten-Loops erzeugen Output. Wenn dein Agent lange Pläne, lange Diffs, lange Testlogs und lange Postmortems schreibt, macht sich der Output-Aufschlag von $5/M bemerkbar.
Die Bessere Architektur: Routen, Nicht Beten
Hier ist die Selection Guide, die ich tatsächlich shippen würde:
- Standardmäßig Opus 4.8 für Claude-native Coding-Agenten.
- Zu GPT-5.5 routen für unabhängige Reviews, terminal-lastige Aufgaben und OpenAI-native Stacks.
- Einen Fable 5-Pfad bereithalten, aber Produktion nicht davon blockieren lassen.
- Budget-Caps, Sandboxing und Modell-Policies pro Task hinzufügen.
- Modell, Provider, Token-Mix, Fallback-Grund und finale menschliche Freigabe loggen.
Ein Provider-Router muss nicht fancy sein. Fang mit einer Policy-Datei an:
routes:
default_coding: claude-opus-4-8
critical_review: gpt-5.5
long_context_refactor: claude-opus-4-8
security_review: gpt-5.5
limits:
max_usd_per_task: 8
require_approval_over_usd: 3Dann erzwingst du sie vor dem Modell-Call. Es geht nicht darum, perfektes automatisches Routing zu jagen. Es geht darum, Business Continuity nicht hart an eine Modell-ID zu binden.
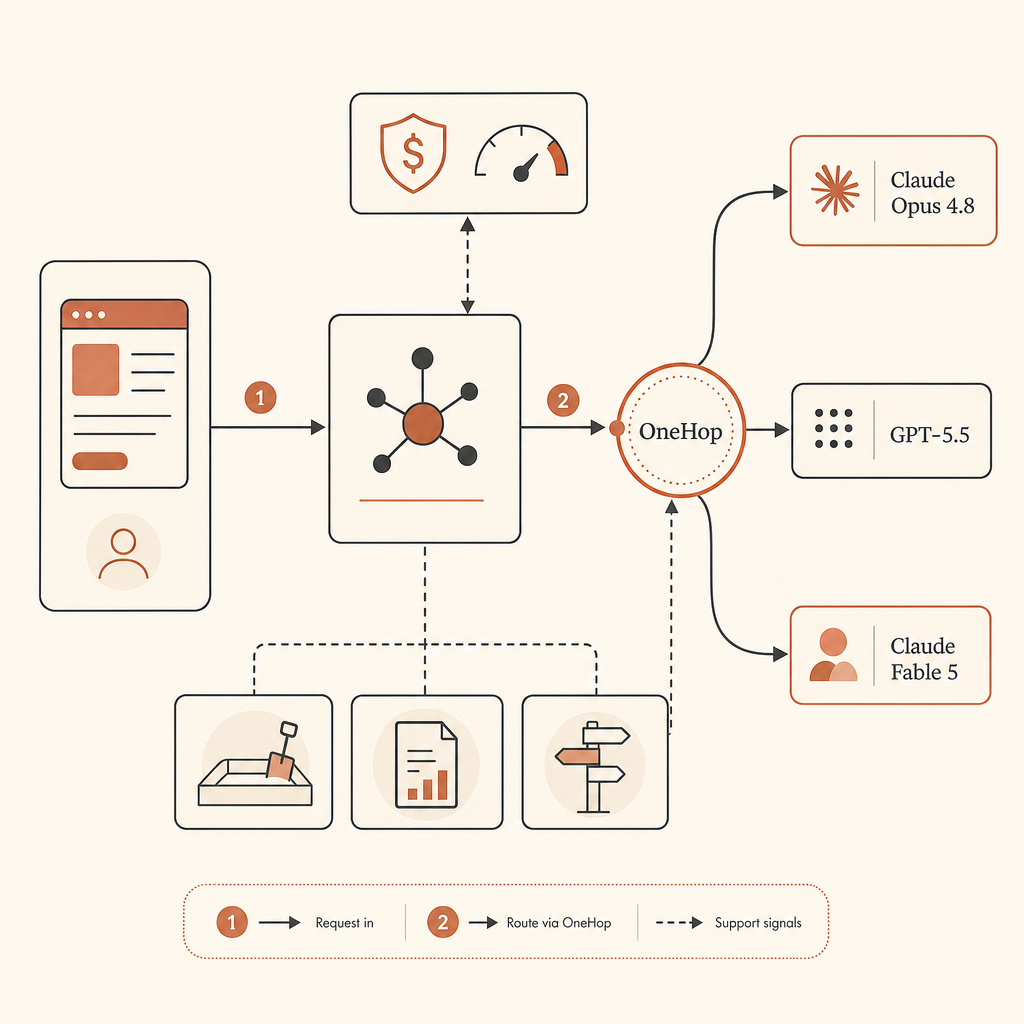
Wenn du Fable 5 weiterhin nutzen willst, sobald Zugriff verfügbar ist, ist OneHop der reibungsärmste Pfad für deine Routing-Tabelle. OneHop listet Claude Fable 5 als anthropic/claude-fable-5, zeigt den offiziellen Listenpreis von $10/M Input und $50/M Output und bewirbt rabattierte Preise plus $10 kostenloses Guthaben für neue Accounts ohne erforderliche Karte (OneHop). Das natürliche Muster ist, die Provider-Abstraktion deiner App stabil zu halten und die base URL zu tauschen.
Für OpenAI-kompatible Clients:
from openai import OpenAI
client = OpenAI(
base_url="https://api.onehop.ai/v1",
api_key="ONEHOP_API_KEY",
)
response = client.chat.completions.create(
model="anthropic/claude-fable-5",
messages=[
{"role": "user", "content": "Review this migration plan for hidden failure modes."}
],
)
print(response.choices[0].message.content)Wenn du gezielt die Fable-Route willst, nutze Claude Fable 5 auf OneHop. Wenn du Provider-Routing von Grund auf testest, starte mit $10 kostenlos.
Die finale Empfehlung ist absichtlich langweilig. Wenn Fable 5 nicht verfügbar ist, verschwende nicht die Woche mit Streit darüber, ob Opus 4.8 oder GPT-5.5 die bessere Persönlichkeit hat. Setz Opus 4.8 in den Claude-Fallback-Slot. Setz GPT-5.5 in den Reviewer- und OpenAI-native-Slot. Halte Fable 5 als geroutete Option über OneHop bereit, wenn es verfügbar ist. Dann miss an deinen eigenen Aufgaben: Erfolgsrate, menschliche Edits, Wall-Clock-Zeit, Token-Kosten und Rollback-Anzahl.
Das ist der erwachsene Move. Model-Fan-Debatten machen Spaß. Produktions-Agenten brauchen einen Exit-Plan.

